







python爬虫实现音乐下载
音乐下载功能模块
# !/usr/bin/env python
# -*- coding:UTF-8 -*-
#
# @Version : 1.0
# @Time : 2021/5/19 14:55
# @Author : 吴壬杰
# @File : 音乐_MongoDB.py
# from pymongo import *
from pymongo import MongoClient
import pandas as pd
import requests
import random
import json
import os
# 音乐下载
def kuWoDownLoad():
search_music = input("请输入作者或者歌曲名:")
weheader = [
[
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'],
['Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2'],
['Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0']]
kk_header = [i for i in random.choice(weheader)]
# print(kk_header[0])
# 请求头(一定要有'User-Agent','Referer','csrf','Cookie')
header = {
'User-Agent': str(kk_header),
# 'Host': 'www.kuwo.cn',
'Referer': 'http://www.kuwo.cn/',
'csrf': 'D32I86ILA88',
'Cookie': '_ga=GA1.2.1490969665.1620831748; _gid=GA1.2.1678093837.1620831748; _gat=1; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1620831749; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1620831749; kw_token=D32I86ILA88'}
try:
for i in range(167):
# 首页URL
url = "http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={}&pn={}&rn=30" \
"&httpsStatus=1&reqId=30709280-b333-11eb-9d41-ad2a15a69fbf".format(search_music, i)
# 发送请求获取首页面
response = requests.get(url, headers=header, timeout=30).json()
# 获取data下面的list内容
list_response = response['data']['list']
# 获取页数
# list_response2 = response['data']['total']
if int(response["data"]["total"]) % 30 > 0:
i = int(response["data"]["total"]) // 30 + 1
else:
i = int(response["data"]["total"]) // 30
print("一共{}页,正在爬取数据。。。。。。".format(i))
# 循环获取对应内容
for info in list_response:
# 歌曲名
music_name = info['name']
# rid
music_rid = info['rid']
# 作者
music_artist = info['artist']
# 作者图像
music_Image = info['pic']
# 专辑
music_album = info['album']
# 专辑发布时间
music_releaseDate = info['releaseDate']
# 歌曲时长
music_songTimeMinutes = info['songTimeMinutes']
# 专辑简介
# if info['albuminfo'] == None:
# info['albuminfo'] = "空值"
# music_albuminfo = info['albuminfo']
# else:
# continue
# print(music_Image)
# 下载音乐(with open()会自动调用关闭文件,所以无需f.close())
with open(os.path.expanduser("~") + '\\Desktop\\music\\' + "{}.mp3".format(music_name), 'wb') as f:
# 下载的每一首歌的URL(使用的都是统一的,rid不同)
music_api = 'http://www.kuwo.cn/url?format=mp3&rid={}&response=url&type=convert_url3&br=128kmp3' \
'&from=web&t=1620883237037&httpsStatus=1&reqId=f32a4ce1-b3aa-11eb-8486-6142833c02da'.format(music_rid)
# 将具体下载歌的response转为字典
music_play_url = requests.get(music_api, headers=header).json()
# 通过真正的URL,以二进制的形式获取
music_data = requests.get(music_play_url['url']).content
# print(music_data)
# 音乐信息内容(字典形式)
music_info_data = {
"music_name": music_name,
"music_artist": music_artist,
'music_Image': music_Image,
"music_album": music_album,
"music_releaseDate": music_releaseDate,
# "music_albuminfo": music_albuminfo,
"songTimeMinutes": music_songTimeMinutes,
"music_data": music_data,
"music_rid": music_rid
}
# 以二进制形式写入文件
f.write(music_data)
# json.dump()用于将dict类型的数据转成str,并写入到json文件中。下面两种方法都可以将数据写入json文件
# data = json.dumps(music_info_data)
# print(type(music_play_url))
# print(type(music_data))
print("下载成功:" + music_name)
# 写入MongoDB库
write_into_image(music_Image, header)
write_into_mongo(Connecting_mongo(), music_info_data)
print("写入数据库成功~")
# 关掉break将会循环获取整个页面的音乐
break
# 关掉break将会循环获取整个页面的音乐(两个不可缺一)
break
except requests.HTTPError:
print("连接异常!")
'''
def _connect_mongo(host, port, username, password, db):
""" 指定帐户和密码建立连接 """
if username and password:
mongo_uri = 'mongodb://%s:%s@%s:%s/%s' % (username, password, host, port, db)
conn = MongoClient(mongo_uri)
else:
"""无用户和密码连接"""
conn = MongoClient(host, port)
return conn[db]
def read_mongo(db, collection, query={}, host='localhost', port=27017, username=None, password=None, no_id=True):
""" 从Mongo读取并存储到DataFrame """
# 连接MongoDB
db = _connect_mongo(host=host, port=port, username=username, password=password, db=db)
# 对特定(query)的数据库和集合进行查询
new_data = db[collection].find(query)
# 读取数据并构造DataFrame
df = pd.DataFrame(list(new_data))
# 删除MongoDB中主键_id
# if no_id:
# del df['_id']
# return df
'''
def write_into_image(music_Image, header):
# 在第一次发送请求的时候就获取了图片连接 music_Image
response_jpg = requests.get(url=music_Image, headers=header, timeout=30)
# 下载图片(with open()会自动调用关闭文件,所以无需f.close())
with open(os.path.expanduser("~") + '\\Desktop\\image\\' + "{}.jpg".format(34), 'wb') as f:
# 以二进制形式写入文件
f.write(response_jpg.content)
print("保存图片成功!")
# 写入MongoDB
def write_into_mongo(db, data):
'''
@params: data,将数据封装为字典,然后将其写入到MongoDB数据库中
'''
print("正在插入数据")
try:
'''
# 连接MongoDB数据库
# Client = MongoClient()
# 查询数据库名
# db_list = Client.list_database_names()
# print(db_list)
# 打开或创建名为data的collection,collection相当于关系型数据库中的数据库
# 在MongoDB中,collection是文档的集合
# db = Client.data
# 或者使用类似引用字典值的方式打开或创建collection
# db = Client['data']
# 授权
# db.authenticate(name='lu',password='123456',source='admin')
# info = db['NBA']
'''
# table = db.persons
table = db['kuwo_down'] # 指定集合collection
# 插入单个document
table.insert_one(data)
# 插入多个document
# table.insert_many(data)
# 搜索所有数据
# for person in table.find():
# print(person)
# print('--------------')
# 输出persons中的文档总数
print('总数', '=', table.estimated_document_count())
except Exception as e:
print(e)
def Connecting_mongo():
# 连接MongoDB数据库
Client = MongoClient('localhost', 27017)
# 打开或创建名为db的collection,collection相当于关系型数据库中的数据库
# 在MongoDB中,collection是文档的集合
# db = Client['db']
db = Client.db
# table = db.persons
# table = db['kuwo_down'] # 指定集合collection
return db
# 删除功能
def Delete(db):
table = db['kuwo_down'] # 指定集合collection
name = input("请输入删除歌曲名:")
table.distinct("music_name")
list_music_name = table.distinct("music_name")
if name in list_music_name:
# 删除单个document
table.delete_one({"music_name": name})
else:
print("删除的歌曲不存在哦~")
# 删除多个document
# table.delete_many({"music_name": name})
# 空字典将删除所有document
# table.delete_many({})
# 删除集合
# table.drop()
# 更新功能
def Update(db):
table = db['kuwo_down'] # 指定集合collection
old_name = input("请输入更改项名称:")
old_value = input("请输入更改项值:")
old_value_one = {old_name: old_value}
new_name = input("请输入更改项名称:")
new_value = input("请输入更改项值:")
new_value_one = {new_name: new_value}
# 更改第一条匹配
table.update_one(old_value_one, new_value_one)
# 更改所有匹配
# table.update_many(old_value_one, new_value_one)
# 查询功能
def Read(db):
table = db['kuwo_down'] # 指定集合collection
music_name = input("请输入查找的歌曲名:")
# 搜索table文档中的第一条子文档,相当于关系型数据库中的记录
# print(table.find_one())
# print(table.find_one(music_name))
# 搜索table集合中的所有文档
# print(table.find({"music_name": music_name}))
if music_name in table.distinct("music_name"):
print("歌曲已存在~~~")
else:
print("不存在此歌曲~~~")
# 显示指定条数
# print(table.find().limit(1))
# print(table.distinct("music_name"))
# 增删改查
def create_Read_Update_Delete(num):
# 如果字符串只包含数字则返回 True,否则返回 False。
if num == '':
print("什么都不想对我说吗~~~Giao\n直接用回车回避我吗~~~Giao")
# 如果字符串中只包含数字字符,则返回 True,否则返回 False。
elif num.isnumeric():
# print("有")
if int(num) == 1:
kuWoDownLoad()
elif int(num) == 2:
Delete(Connecting_mongo())
elif int(num) == 3:
Update(Connecting_mongo())
elif int(num) == 4:
Read(Connecting_mongo())
else:
print("你连1234都不记得,更何况是我\n走了,这次罚你,再也见不到我!")
# 如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False。
elif num.isalpha():
print("请不要输入字母!")
else:
print("格式错误!")
# 数据获取
def huoqu_shuju(db):
table = db['kuwo_down'] # 指定集合collection
# 方法一
# 获取music_name,直接从MongoDB去重查询获得
# new_data = table.distinct("music_name")
# 方法二
# 读取或者加载数据
data = pd.DataFrame(list(table.find())) # data为'str'类型
# data = pd.DataFrame(table.find()) # data为'str'类型
# 选择需要显示的字段
new_data = data[['music_name', 'music_artist']]
# 方法不全
# data = table.find()
# for new_data in data:
# print(new_data.keys())
# print(new_data.values())
# print(new_data.items())
# break
# 打印输出
print(new_data)
if __name__ == "__main__":
# os.path.expanduser("~"), 'Desktop') 把path中包含的"~"和"~user"转换成用户目录
# os.path.join() 把目录和文件名合成一个路径
# os.path.exists() 路径存在则返回True,路径损坏返回False
if not os.path.exists(os.path.join(os.path.expanduser("~") + '\\Desktop\\music')):
os.mkdir(os.path.join(os.path.expanduser("~") + '\\Desktop\\music'))
if not os.path.exists(os.path.join(os.path.expanduser("~") + '\\Desktop\\image')):
os.mkdir(os.path.join(os.path.expanduser("~") + '\\Desktop\\image'))
num = input("下载(99%可不一定没爱过呀!):1\n删除(即使在舍不得,也得走啦!):2\n更新(没有了你,我会开始新生活!):3\n查询(来过,你可不一定,找得到我!):4\n请输入:")
# 选择对应需求功能
create_Read_Update_Delete(num)
# 展现数据
huoqu_shuju(Connecting_mongo())
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,Python自动化测试学习等教程。带你从零基础系统性的学好Python!
👉[[CSDN大礼包:《python安装包&全套学习资料》免费分享]](安全链接,放心点击)
一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
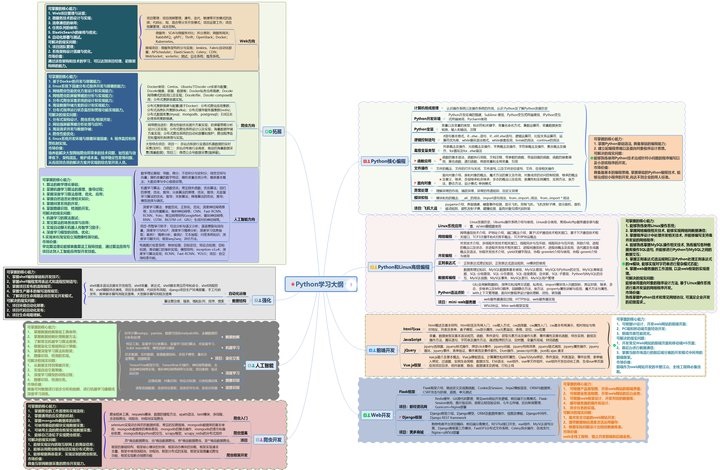
二、Python必备开发工具

三、入门学习视频
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、python副业兼职与全职路线
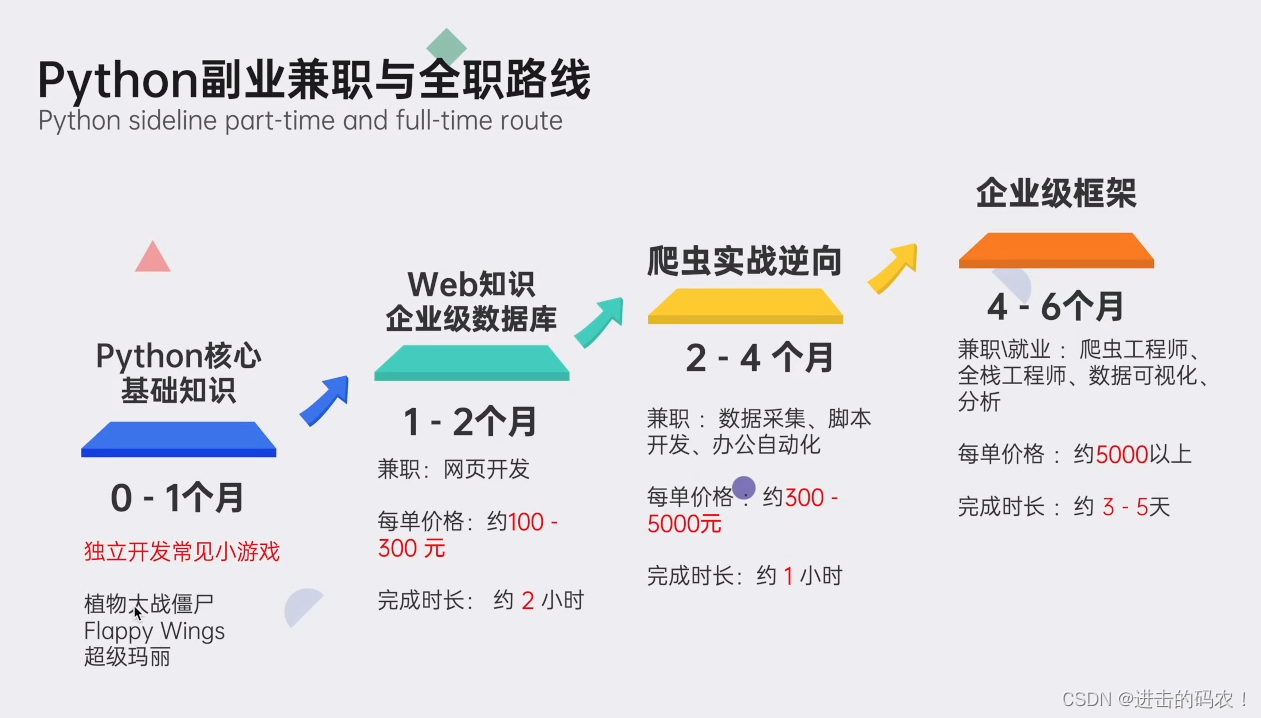
上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取
👉[[CSDN大礼包:《python安装包&全套学习资料》免费分享]](安全链接,放心点击)
















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









