






序
最近在断断续续地学习project reactor,或许是因为reactor编程和传统编程思维差异较大的缘故,感觉在学习的时候比较吃力,只能翻翻官方文档和github做一些练习,不过2个月下来总算也是能用reactor写项目了~
本菜鸡在学习过程的过程中,发现网上的project reactor教程、博客,多以讲述api和展示简单的示例代码为主,因此本文打算从一个简易的excel批处理项目入手,对实战部分做一个补充,从项目代码来加深对project reactor的学习。阅读文章需要了解project reactor和netty的基本知识和用法,请先学习这两个库~
https://projectreactor.io/
https://netty.io/
技术栈: spring webflux + r2dbc + redission+ xxl-job
由于部分功能实现简单,在reactor上的使用别的章节也已经提到,所以这里只讲解核心功能
讲解功能
- 订阅未完成任务
- excel导出
- excel导入
- sdk模块编写
未讲解功能
- 任务模板新增
- 任务的创建
- easy-excel的使用
- 飞书通知
项目功能
项目功能比较简单:
- 上传excel,通过定时任务将excel中的数据传输给对应的业务服务,支持每行调用或者批次调用
- 设置、提交任务,将业务数据拉取下来,导出为excel文件
任务的编写采用自定义注解的方式:
以excel导出为例,使用方只需要引入sdk代码,在类上加上自定义注解,继承抽象父类,就完成了入口代码的编写。
@ExcelExport("testExcelTask")
@Component
@Slf4j
public class TestExcelExportHandler extends BaseExcelExportHandler<TestResp, TestReq> {
// execute code
@Override
public List<List<String>> getExcelHeaders(TestReq param){
//... 获取excel表头
}
@Override
public List<TestResp> getExportData(Integer pageNo, TestReq param) {
//...获取export数据
}
}
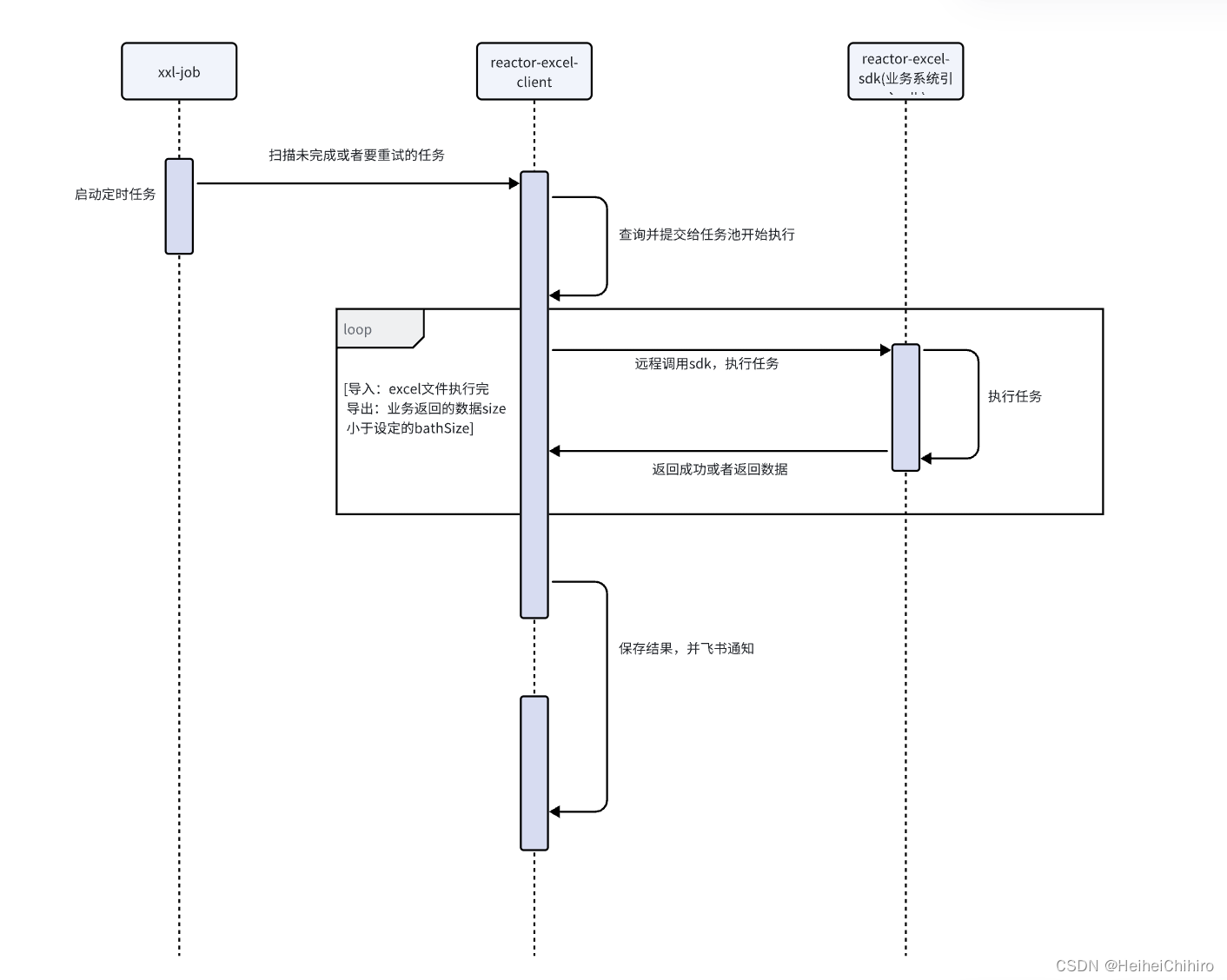
流程图
表结构
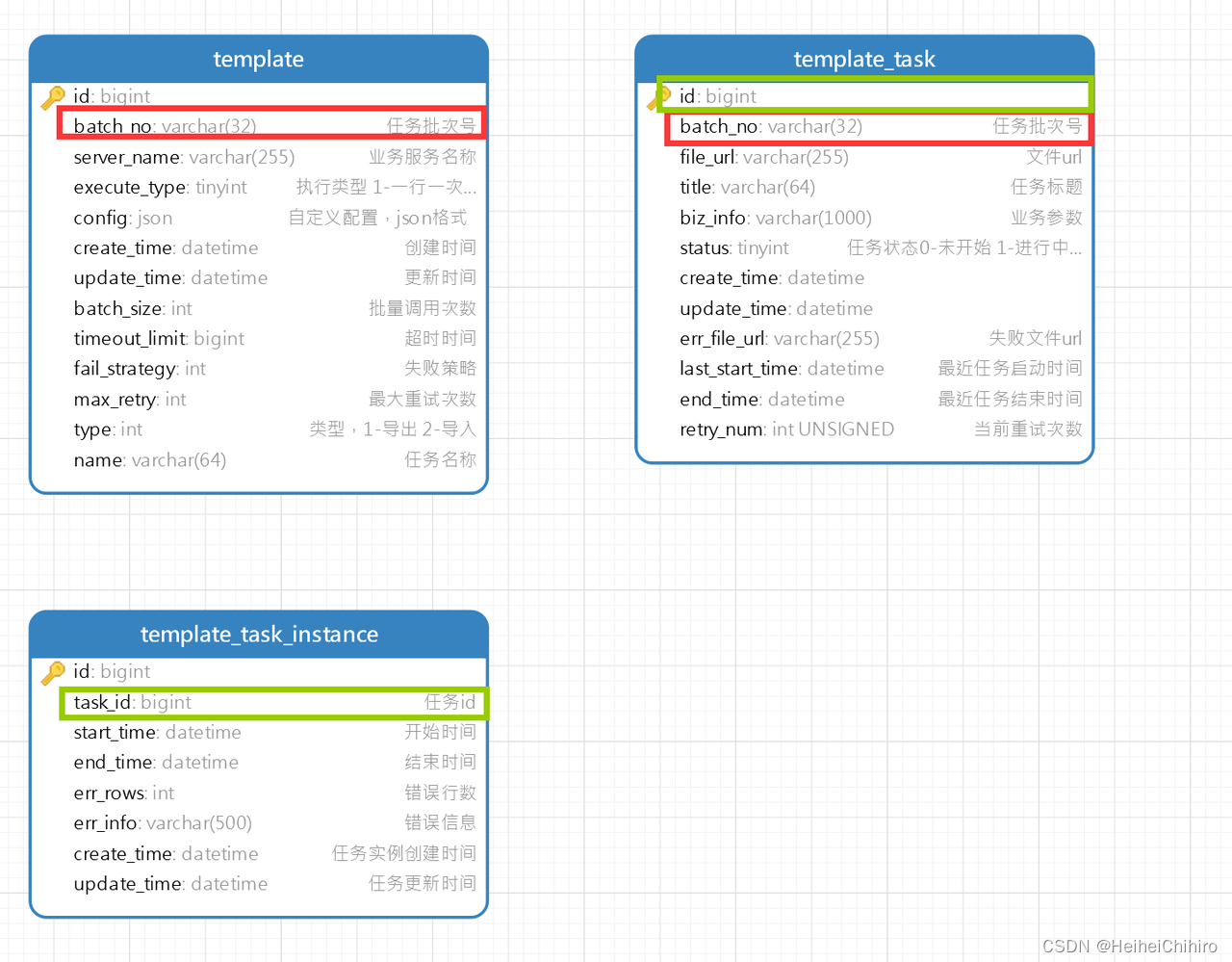
- template 任务模板表
template 是任务的基本配置
当我们想新建一个任务类型时,就需要在Template中,新建一条数据。
比如我想新建一个"新增商品明细导出"任务,那么我就要通过接口在Template中添加记录,里面包含
任务批次号、请求的服务名称、任务类型、超时时间、失败策略… - template_task 任务实例表
template_task表示的是创建的任务实例,当你在下午决定创建一个导出"上月新增商品"的商品明细导出任务时,template_task表中就会创建了一条记录,它的batch_no字段和template表中的batch_no字段相同
template_task.batch_no = template.batch_no - template_task_instance 任务执行实例表
template_task_instance 是任务执行的实例。由于任务实例创建之后,可能会执行多次,需要template_task_instance表记录每次执行的结果
template_task_instance .task_id == template_task .id
因此它们之间的关系是
1个任务模板:N个任务
1个任务:N个任务执行实例
项目结构
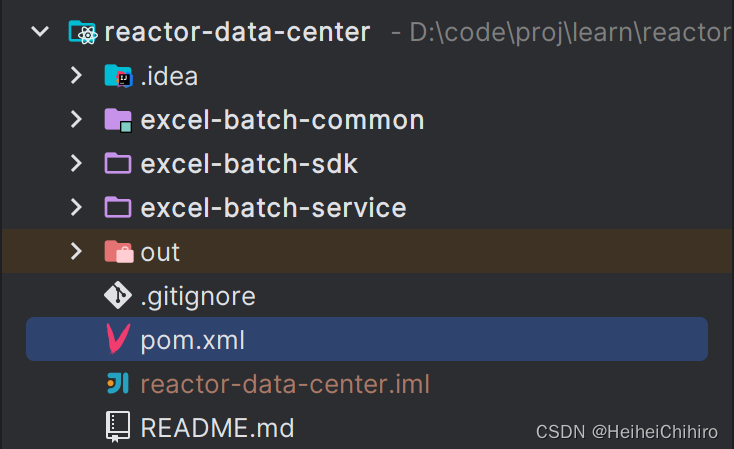
excel-batch-common: common包,里面是一些共同的类
excel-batch-sdk: sdk包,由业务服务引入此依赖
excel-batch-service:excel服务本身,作为通信双方中的客户端请求业务服务
代码
咱们先从excel-batch-service开始,捋一下从查询未开始的任务,到结束任务执行的流程,看看reactor在里面是怎么用的
excel-batch-service
获取未完成的任务

逻辑讲解: 通过xxljob广播任务查询未未开始的任务,将这些任务交给订阅者去执行
getUnComplete()返回的是Flux,也就是未完成任务的数据流。这里我用了switchIfEmpty()方法去打日志,而不是在subscribe中:当机器没有需要执行的未完成的任务时,getUnComplete()返回的是Flux.empty(),也就是不包含任何元素的flux,而subscribe中的方法在没有元素到达的时候,是不会触发执行的,因此需要在switchIfEmpty里打印日志(在getUnComplete里也行)
注意:subscribe中的代码不执行,不代表subscribe不会订阅元素
getUnComplete方法的写法
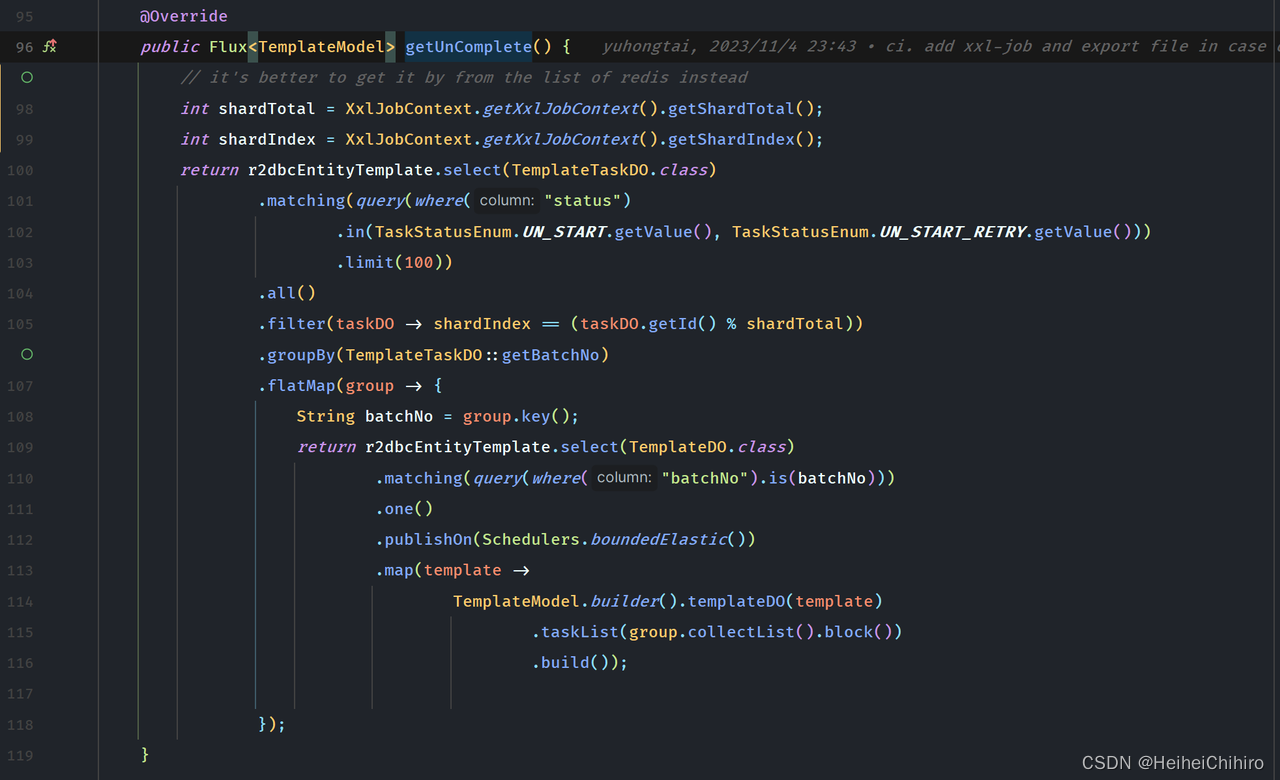
逻辑讲解: 依据xxl-job的分片参数,获取hash到的的未执行任务,通过batchNo分组并包装成model对象,然后返回
注意: 由于是要保持project reactor的范式,因此所有的技术栈都要使用project reactor版本,因此这里的使用r2dbc代替jdbc和mybatis,其具体的使用需要翻阅其使用手册
- 用r2dbc将未完成或者需要重试的任务查询出来,限制一次性查询100个任务
- 过滤id,只取机器所属分片(取余)的任务进行执行
- 使用groupby()将任务按照batchNo进行分组,得到的是一个<batchNo, List>的结构
- 在flatMap中对分完组的group做处理
flatMap可以简单理解为将元素A映射成元素B,它和map有以下区别:
- flatMap返回的是Publisher对象,而map返回的是元素本身,
- flatMap是将上游的元素转化为内部Publisher(inner publisher),在转化过程中,并不要求转换前后的元素一一对应,比如上游过来4个元素[1,2,3,4],经过flatMap可以有[1,2,3,4,5,8,9]。以通过账号查询消费记录为例,上游发送了3个账号,我们在flatMap中需要查询3个账号最近3天的消费记录,由于每个账号最近3天的消费记录数是不确定的,因此经过flatMap之后,理论上可能会得到由0->∞个消费记录组成的flux流。而map则要求转换后的元素和输入元素1:1对应(empty元素也可以),如果使用的是map,则为了完整的消费记录能够返回,属于同一个账号下的消费记录需要被聚合到一个对象中,以保证其1:1的关系
- 通过r2dbc,查询该task所属的任务template信息,并通过之前按batchNo分好的group,将一个group下的任务成装成TemplateModel,即未完成的任务按照所属任务模板分组封装返回。
- 返回结果(一个Flux对象),return在第100行。
注意: reactor风格的代码中存在着大量的链式调用,因此返回字符return和最后的真正要返回的结果在代码行数上可能隔了十万八千里,里面还有各种嵌套…
执行任务
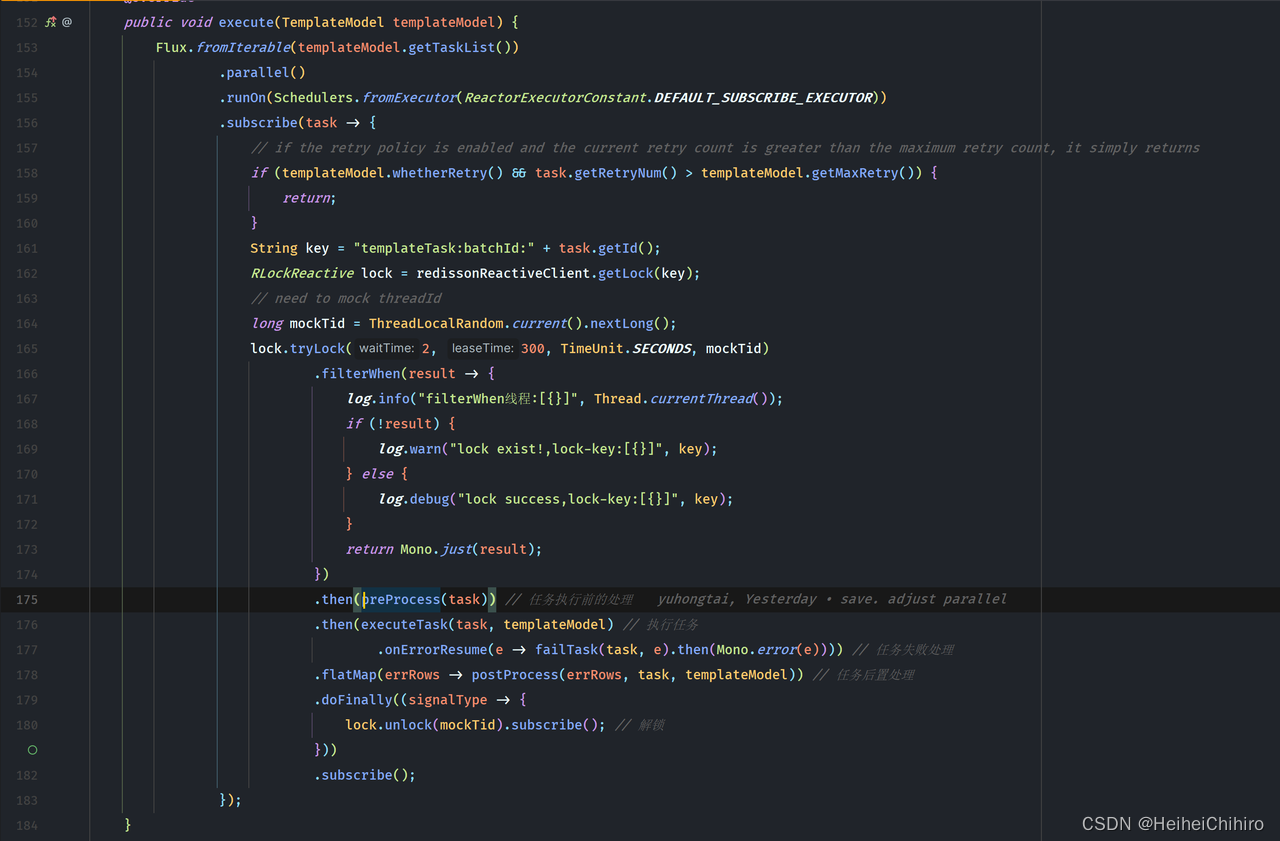
逻辑讲解: 将任务交给调度池并行执行,用reactive Redission为每一个任务加上redis锁,依次执行 前置处理、执行任务、任务后置处理,最后unlock redis锁
- 153行 将templateModel中的task包装成flux
- 154行 使用parallel以及runOn指定后续所有操作所在的调度池,使得不同的task可以并行执行
关于三种线程调度指定方式的区别
- runOn
指定后续操作符执行所在的调度池,对之前的操作符无影响。runOn主要和parallel配合使用,设定parallel之后,flux的元素会被分割成几组group,每组group由runOn指定的调度池内的线程执行。若不使用parallel,则和publishOn无异- publishOn
指定后续操作符执行所在的调度池,对之前的操作符无影响(无并行)- subscribeOn
指定整个流所执行的默认调度池,其位置所在不会对整个流造成影响,当遇到runOn和publishOn才会切换到指定的调度池
- 164行 随机手动生成一个线程id(实际上就是一个随机数),作为redission加锁的线程id,对任务进行加锁,防止重复执行。为什么这里要手动指定线程id呢?因为在reactor编程中,操作符跑在哪个线程上是不确定的,使用的中间件大概率会调用runOn这类指定调度器的方法,这就导致了加锁和解锁不是一个线程,解锁失败。在上面的代码中,redisson ReactiveClient就在网络IO部分指定了新的调度器。因此我们最好在reactor场景下手动指定线程id,除非你可以确定你所使用的中间件没有修改调度池
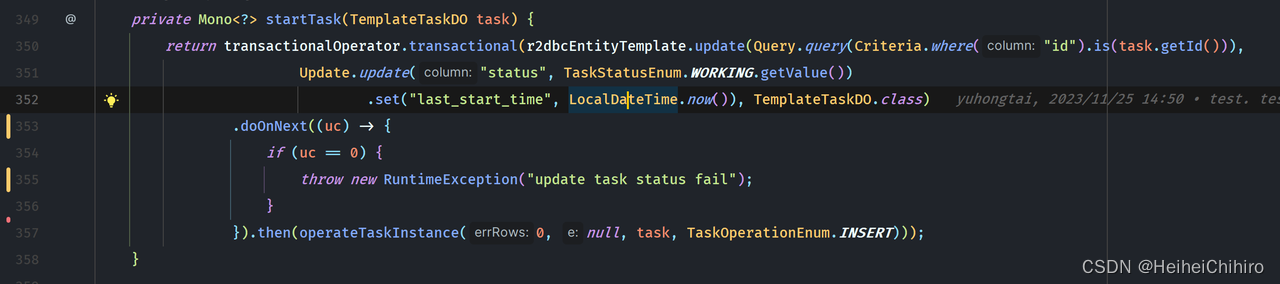
- 175行 执行任务开始前的一系列准备操作,具体代码如下,就是修改任务状态,插入任务实例。注意这里的doOnNext,可以在doOnNext中判断mysql更新的返回值,决定是否要抛出异常中断执行。

- 176行 执行任务实例(具体如何执行且看后文),177行的onErrorResume则是对上游执行过程中抛出的异常做处理。在onErrorResume中,可以选择继续抛出异常或者内部消化(不中断流)。failTask方法中的内容是在数据库事务内重新设置任务状态,并更新当前重试次数,写法和上面的startTask类似,这里就不展开讲了。
注意: 代码中用了不少的then作为流之间的衔接、接下来我要先谈谈then在其中发挥的作用,以及别的流衔接操作符
我们一般使用的流衔接操作符如下
1. then
将两个流拼接在一起,但本质上还是两个流
合并前
[1,2,3]
[4,5]
合并后
[[1,2,3][4,5]]
2. concatWith
将两个流合并在一起,保证顺序
合并前
[1,2,3]
[4,5]
合并后
[1,2,3,4,5]
3. zipWith
zipWith会将合并的两个元素一一对应,变成一个k-v对
合并前
[1,2,3,4]
[5,6,7,8]
合并后
[(1,5),(2,6),(3,7),(4,8)]
4. mergeWith
合并前
[1,2,3,4]
[5,6,7,8]
合并后
2,3,5,1,4,8,7,6
哪个元素先到,哪个元素就在前面
进入前文176行 executeTask方法中,从这里开始是具体的调用执行代码,前面的是执行的大致步骤
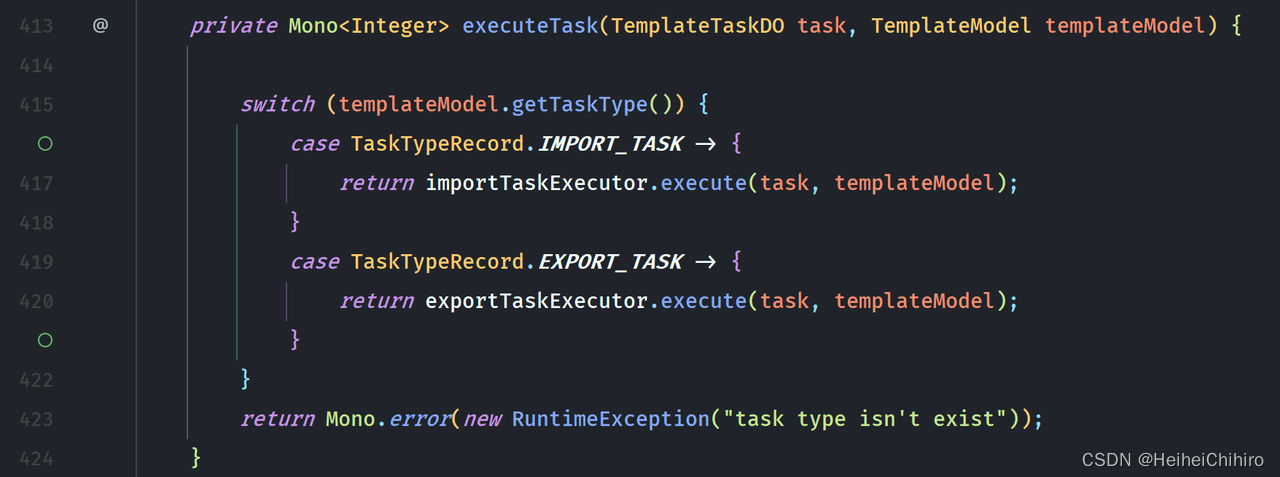
逻辑解释: 通过template的任务类型判断是导出任务还是导入任务,然后进入不同的执行器之中
excel导入
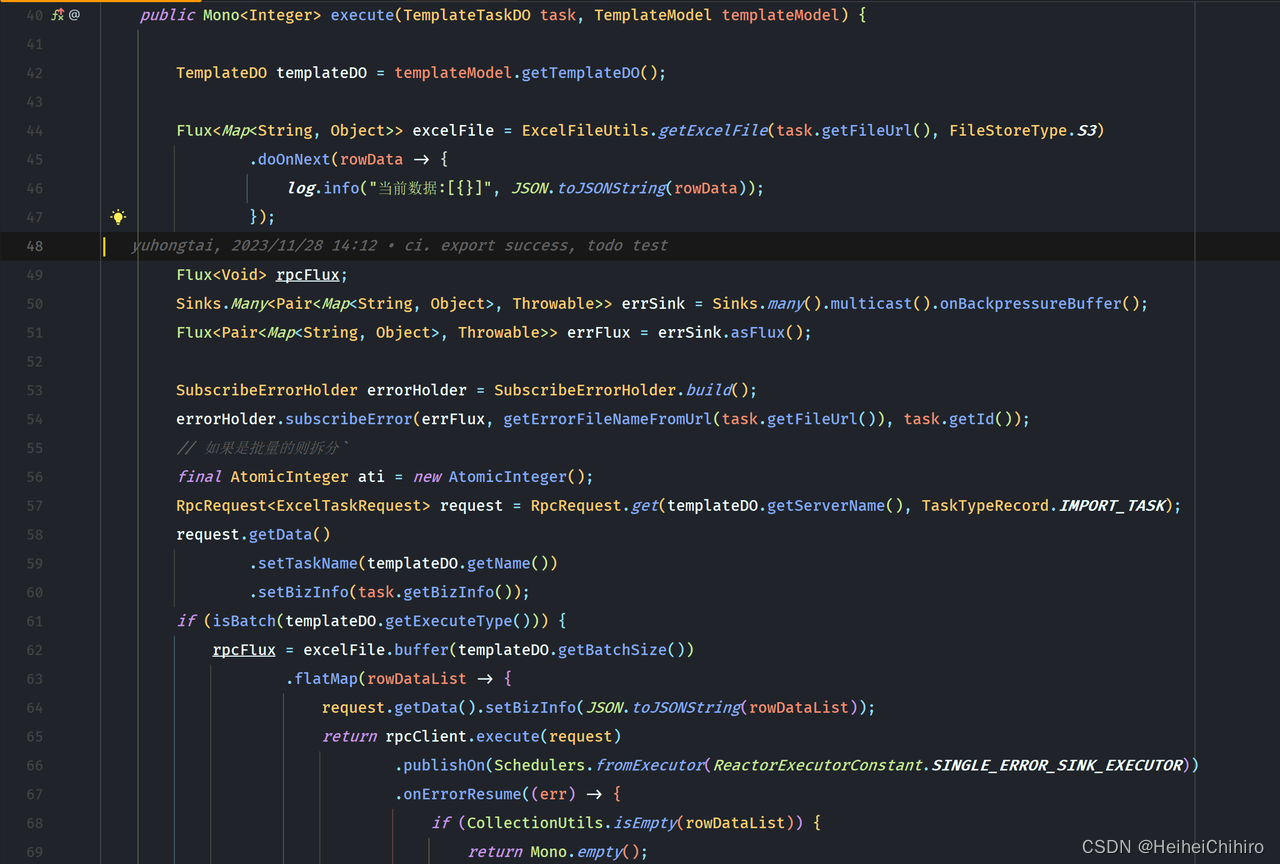
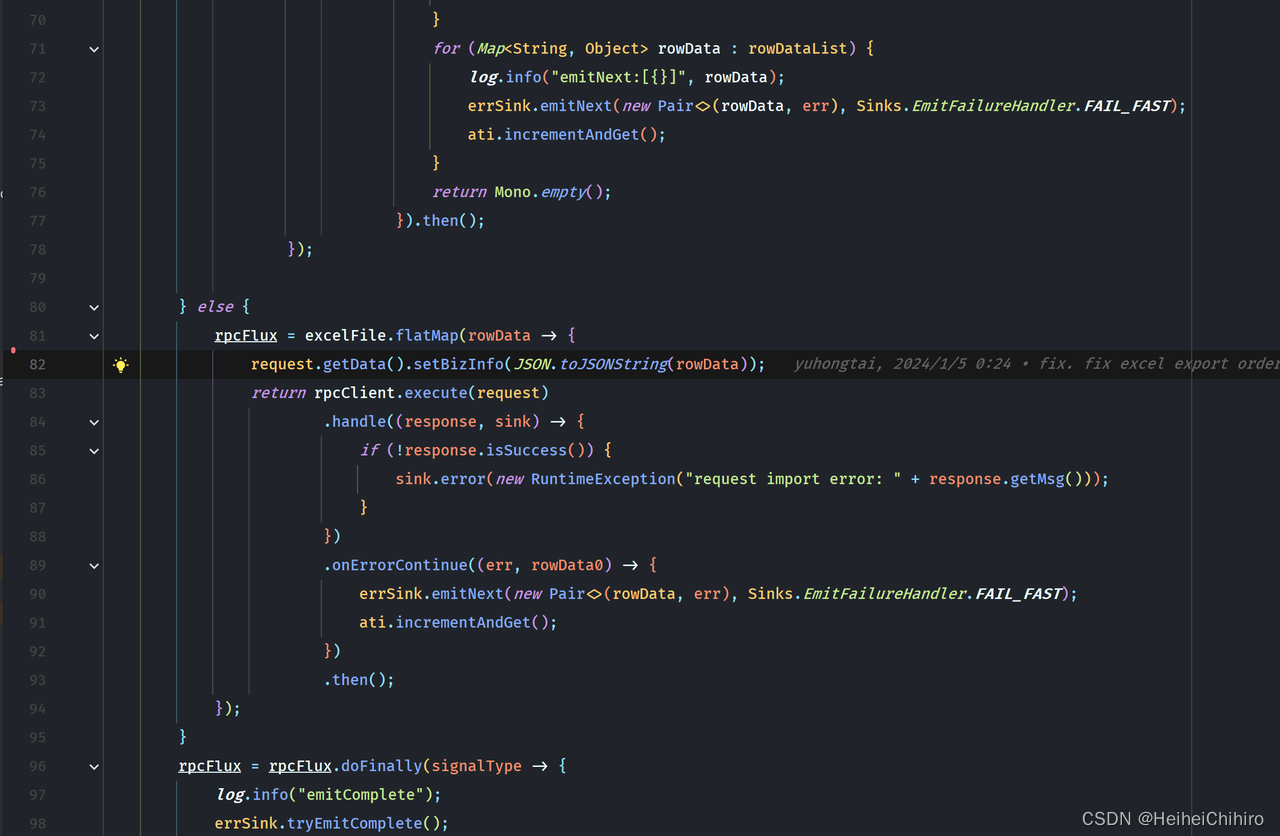

逻辑讲解: 将oss上的待执行excel文件下载下来,并读取文件数据,将数据发射到flux中,下游的subscriber消费这些数据,将数据发送给在template中指定的服务,同时对于处理过程中报错的数据,将其导出为一份excel,上传oss
- 44行 创建excel数据文件flux,通过ExcelFileUtils获得excel文件数据的flux流,数据这块我用了Map<String,Object>表示,key是表头名称,value是数据。我们来看看ExcelFileUtils.getExcelFile中的具体内容
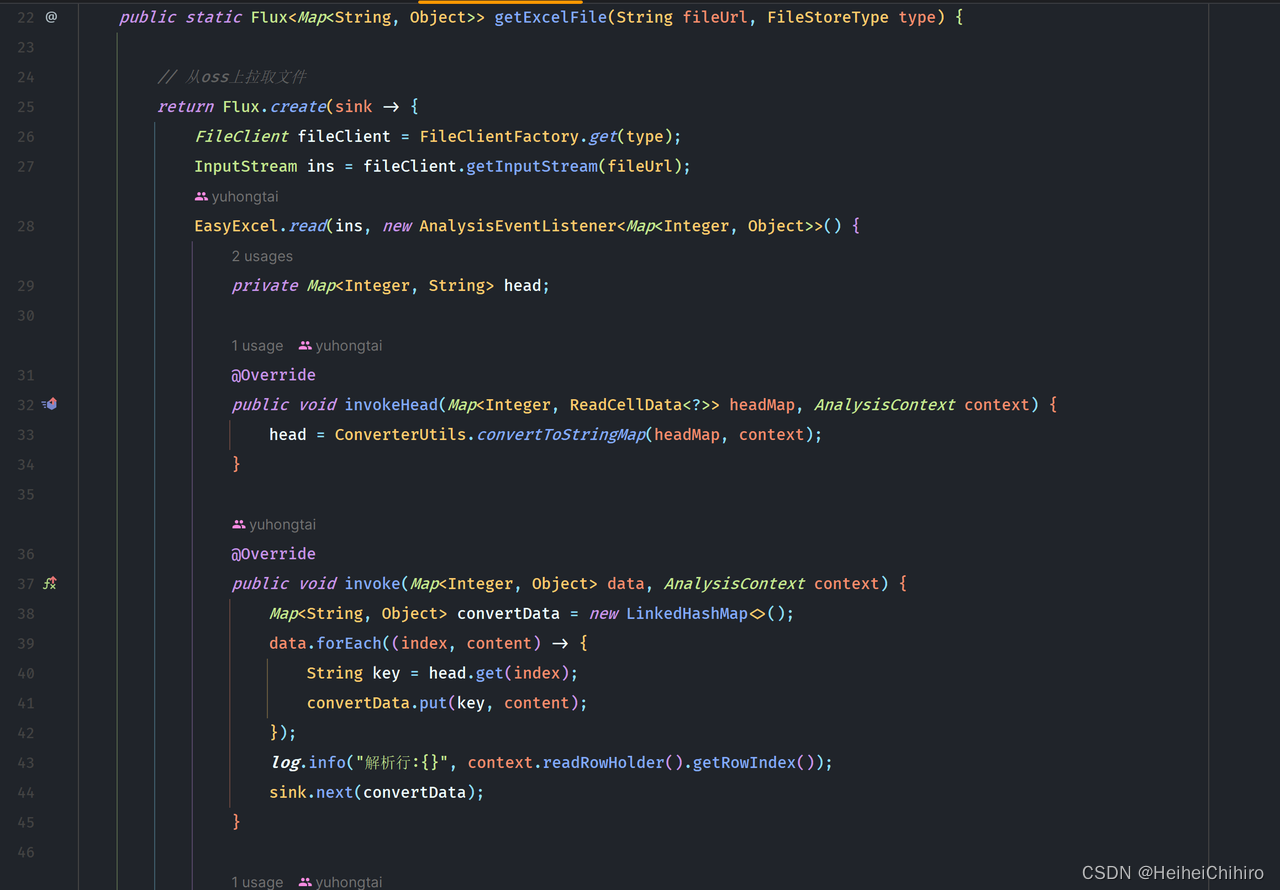
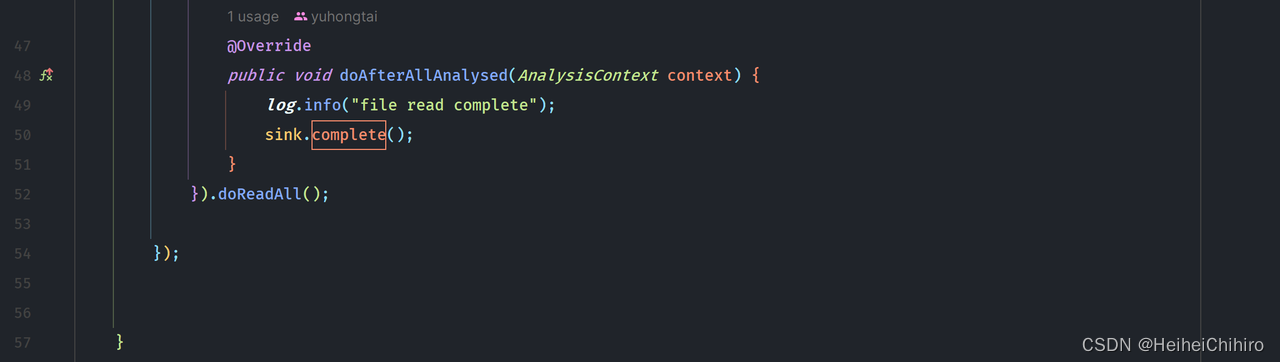
若是看不懂的,建议先学习下easy-excel的基本使用,其实就是自定义AnalysisEventListener(后续简称ael)。我们在Flux的create方法中创建ael,在ael读取到数据时,将数据通过FluxSink对象的next方法提交给流,在所有数据读取完结时,调用sink.complete()方法结束流。其中表头的类型是Map<Integer,String>,key是表头在excel中的列数,value是表头名称
关于sink. 在reactor中,sink可以理解为流的入口,一个手动的元素发射器。形象点说的话,它就是枪的扳机,按下去就是发射子弹(元素),当然它可远远不只是发射子弹这么简单
常见的sink用法是
sink.next(T t) 发出元素
sink.complete() 发出流完成信号,并终止流
sink.error(Throwable e) 发出流错误信号
- 50行 创建错误数据处理sink,该sink的作用是将导入错误的数据加上异常原因,交给订阅的异常数据处理器去处理,异常数据处理器是给将错误的数据重新生成一个excel供下载,以便于后续的排查和重新导入
关于Sinks类. Sinks类是sink建造工厂类,它提供开发者编程式创建流的能力,将sink暴露给外部调用者,而不是必须在flux或mono的上下文里面才能获取.
创建单个元素的sink
Sinks.one()
创建多个元素的sink
Sinks.many().multicast().onBackpressureBuffer()
multicast()允许1个流有多个subscriber,unicast()只允许1个流只有一个subscriber.Sinks.Many<Object> sinks = >Sinks.many().multicast().onBackpressureBuffer(); // 订阅者1 sinks.asFlux().subscribe(x->{ System.out.println("sub_1:"+x); }); // 订阅者2 sinks.asFlux().subscribe(x->{ System.out.println("sub_2:"+x); });比如上述代码,同一个flux被subscribe了2次,就是2个订阅者,假如我们把multicast(),换成unicast(),则在第二次subscribe时会报错,这是不允许的
onBackpressureBuffer()则是关于背压的设置。这个词在计算机中指的是在数据传输过程中,消费者处理消息速度比生产者慢,导致生产者无法继续生产的情况。背压的设置有3种选项:
- onBackpressureBuffer()
提供一块缓冲区作为未消费数据的临时存储,直到buffer区也满了,发送者才无法发射数据。- directAllOrNothing
如果一个订阅者无法消耗更多的数据,那么所有的订阅者都会停止,直到所有订阅者都能订阅数据- directBestEffort
停止向无法接收数据的订阅者推送数据,其他订阅者正常
查看订阅错误的详细方法(如下图所示)
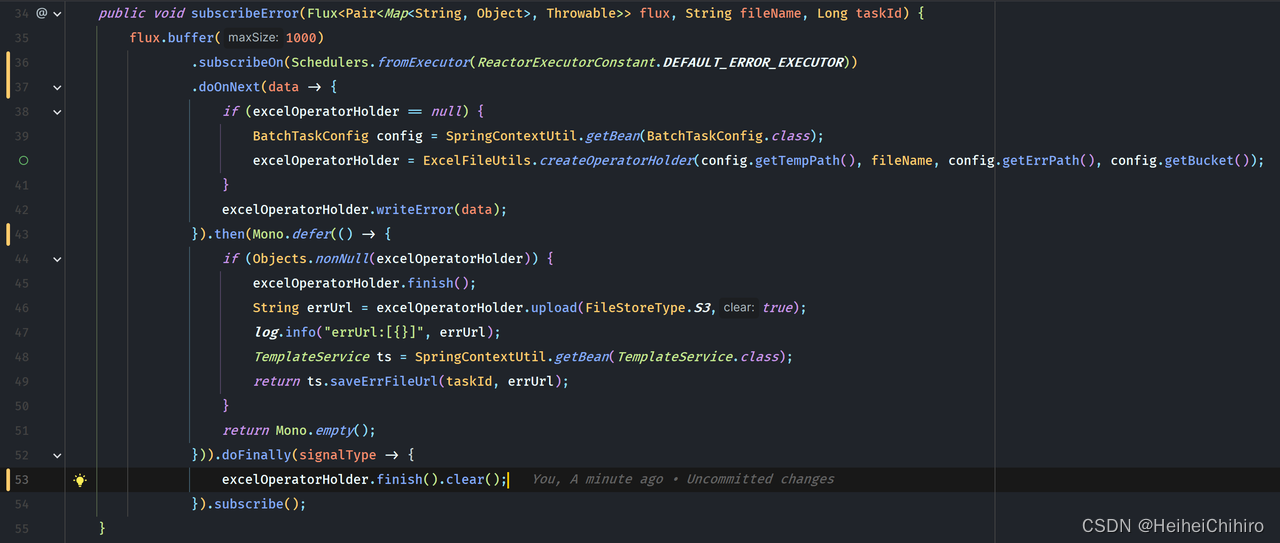
首先是先将数据通过buffer操作符进行缓存,当流收到元素时,只有元素数量到1000或者流结束时才会发给下游,这样是为了避免订阅者将数据写入磁盘中时太过频繁,无需每一行错误数据到来,就excelWriter.write()一次。
接着通过subscribeOn指定调度池,使订阅错误数据的能和当前的流并行。
在doOnNext中,我初始化了excelOperatorHolder(excel操作包装类),并通过它将数据写入本地临时文件,接着在后面用then将"上传文件到oss并更新数据库"这个流合并过来,最后通过doFinally保证本地excel临时文件一定会被清理
doFinally. 在doFinally中,可以指定流结束时要做的操作,不论是正常结束,还是错误中断,还是主动取消,它都会被执行。它和try finally中的finally语义一样
-
请求远程服务
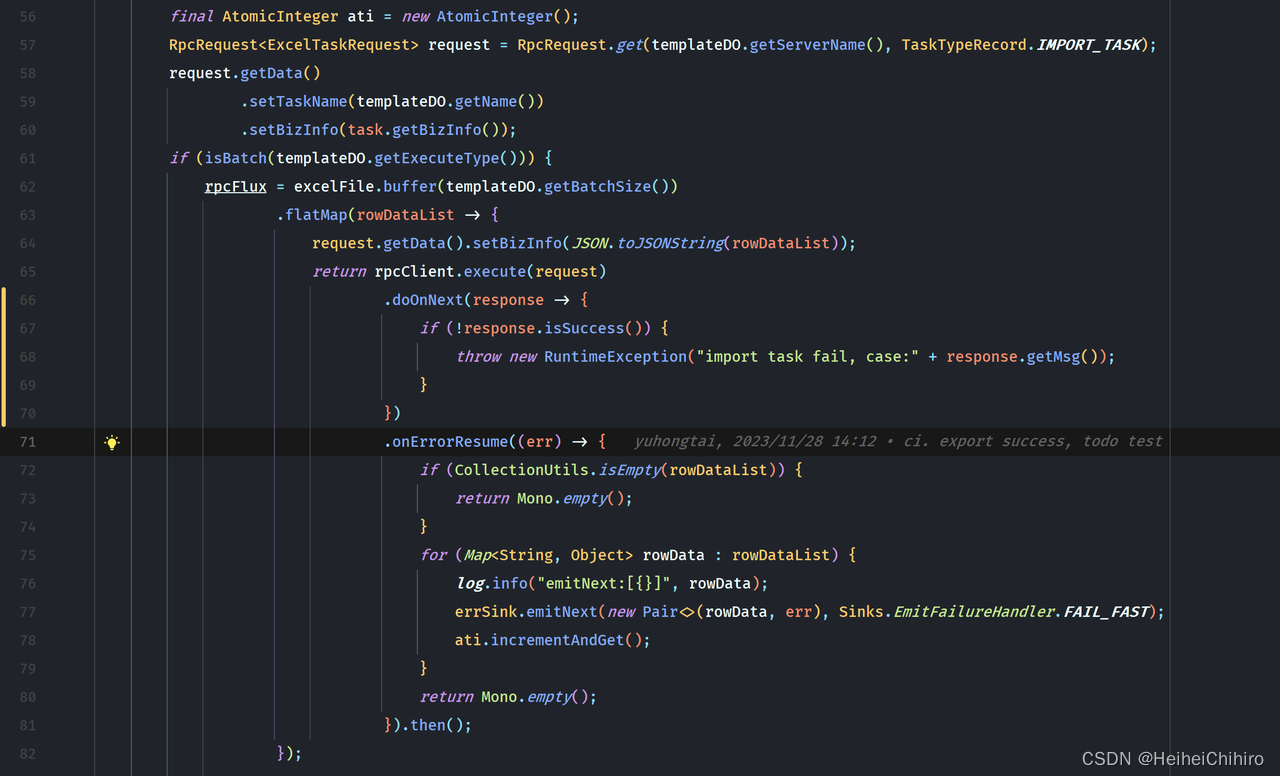
逻辑讲解: 组装请求消息,请求远程服务,拿到返回值之后判断是否成功,失败则抛出异常,将数据交给异常数据订阅者,并累加错误数据行数。- 创建rpc调用请求,塞入业务数据bizInfo,并初始化错误行数ati为0
- rpc调用远程服务
- 在handle中判断返回结果,如果错误通过上下文中的sink.error,发出错误信号
- 在onErrorContinue中对错误行数进行累加
onErrorContinue和onErrorResume的区别是,onErrorContinue不会抛出异常,中断流,而onErrorResume你可以选择抛也可以选择不抛
-
结束流处理
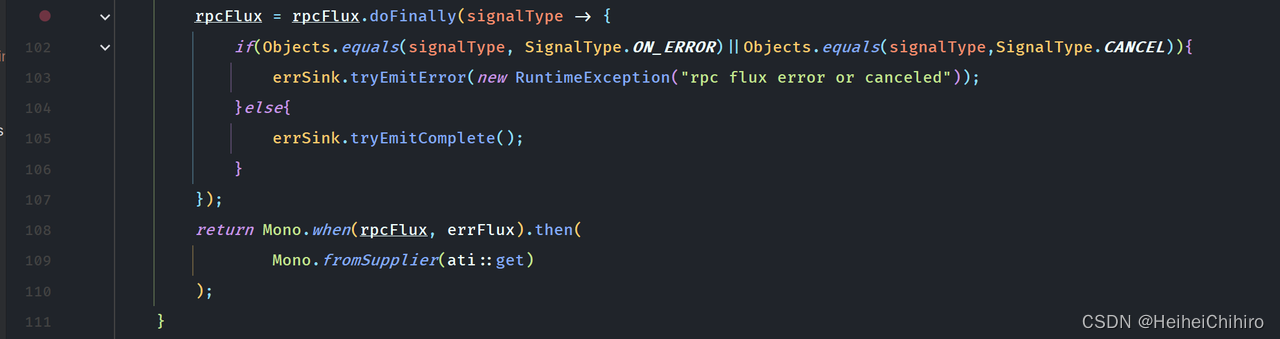
在doFinally中,对流最后的信号做处理,如果是error和cancel则终止异常流,如果没问题,则正常结束异常流。
由于使用了onErrorContinue,正常的业务错误不会导致数据流error
108行 Mono.when(Publisher<?>… sources) 会等待所有的publisher完成,并返回一个Mono.empty(),这类似CountDownLatch的await操作,因此当有场景需要多个流完成再走到下游的场景时,就可以用when操作符。
最后使用.then(Mono.fromSupplier(ati::get))返回错误行数,需要注意的是我这里使用的是Mono.fromSupplier而不是Mono.just,因为得保证ati::get在上面的流处理完成之后再被执行(延迟执行)。如果使用了Mono.just,那么在编排流的时候,ati::get就会被执行。因此我们可以得出结论:
如果要让操作在流中(延迟)执行,就得使用Mono.fromSupplier,Mono.fromRunnable、Mono.defer()等api,除非你要返回的值已经在流中被处理,比如在flatMap中,则可以用Mono.just()返回,因为flatMap就已经在流之中了.
关于Mono.fromXX,Flux.formXX这类fromXX之间的区别,可以查阅手册或者通过注释了解,总体上就是从一个source中获得元素,无非是传入source不同罢了.flatMap(x->{ // 操作 int a = ..... return Mono.just(a); }) .subscribe()
excel导出
excel导出在流程上和excel导入类似,因此我这里只会提一下分页查询的场景实现
excel导出在流程上,分为
- 请求excel头
- 分页请求excel数据,只传递请求页,每页数量由业务接口自己决定
- 生成excel,上传oss
代码如下:
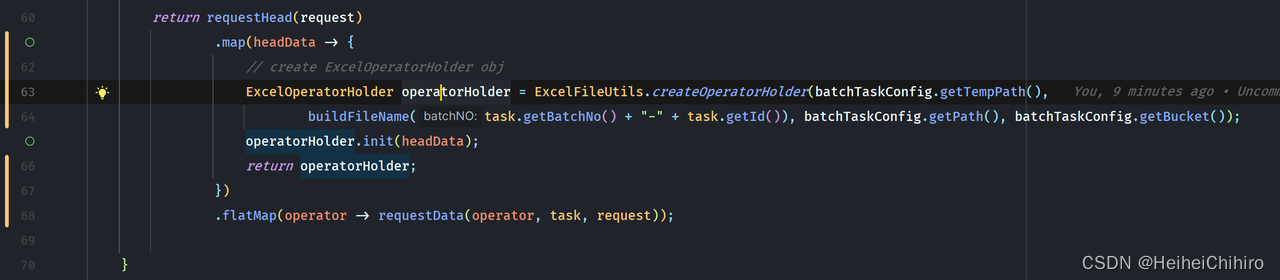
从60行开始,先请求excel头数据,创建excelOperatorHolder对象,ExcelOperatorHolder对象是任务excel操作的句柄,里面包含了上传地址、文件名等信息。接着在flatMap中请求excel数据,我们来看一下请求excel数据的代码
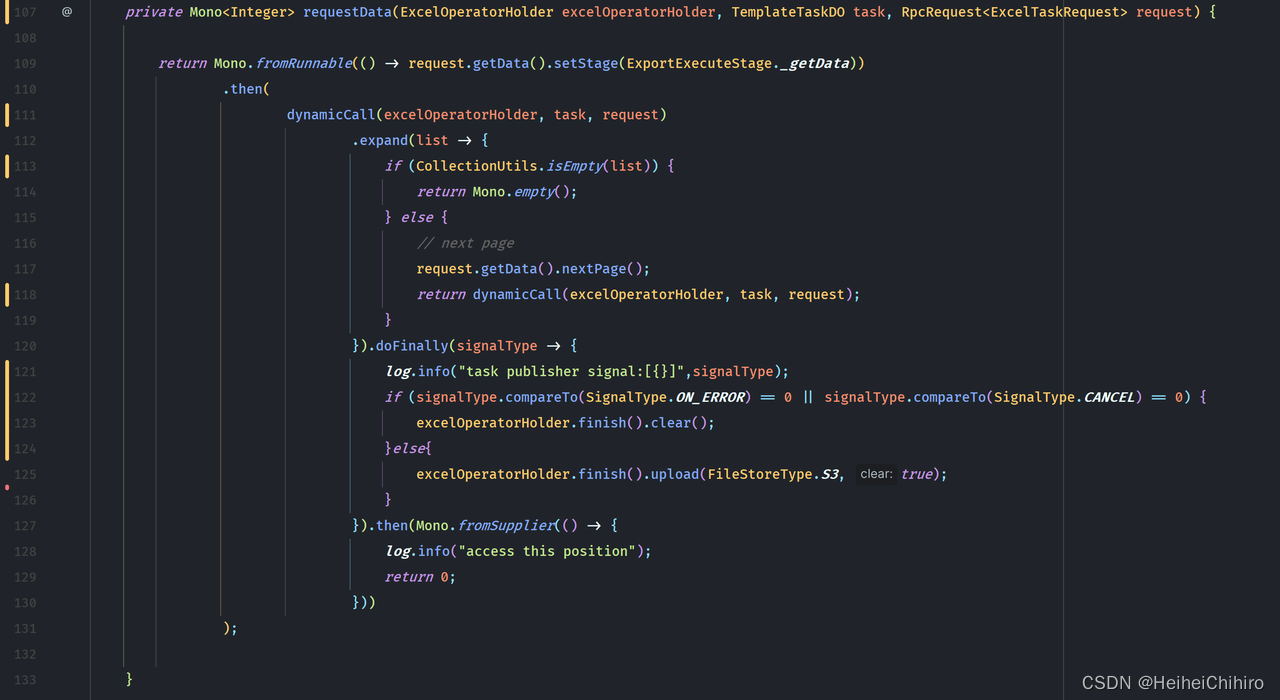
- 108行 首先用Mono.fromRunnable设置执行状态。需要注意执行状态的设置必须是是一个在流中的Mono,否则在流还未执行时,request的状态就早早地变成了_getData了.
- 111行 dynamicCall,字面意思是动态调用,在从业务方获取数据时,我们需要依赖每一次调用的结果来判断是否要complete当前流,因此expand方法就派上用场了
expand()
接收参数,并返回一个Publisher。它递归的将自己发射的数据再重新发射给expand自己,直到数据为空(Mono.empty()),
如上面代码中102行dynamicCall返回的数据将重新进入96行expand之中
expand按照递归方式区分,会分为BFS遍历的expand和DFS的expandDeep()
在expand中,我们判断返回的数据列表是否为空,如果为空则返回Mono.empty(),退出递归,否则继续调用dynamicCall.
在doFinally中,判断流信号是失败、取消还是完成,若失败则清理临时文件,成功则上传文件到oss并清理临时文件。
来简单看一下dynamicCall的内容
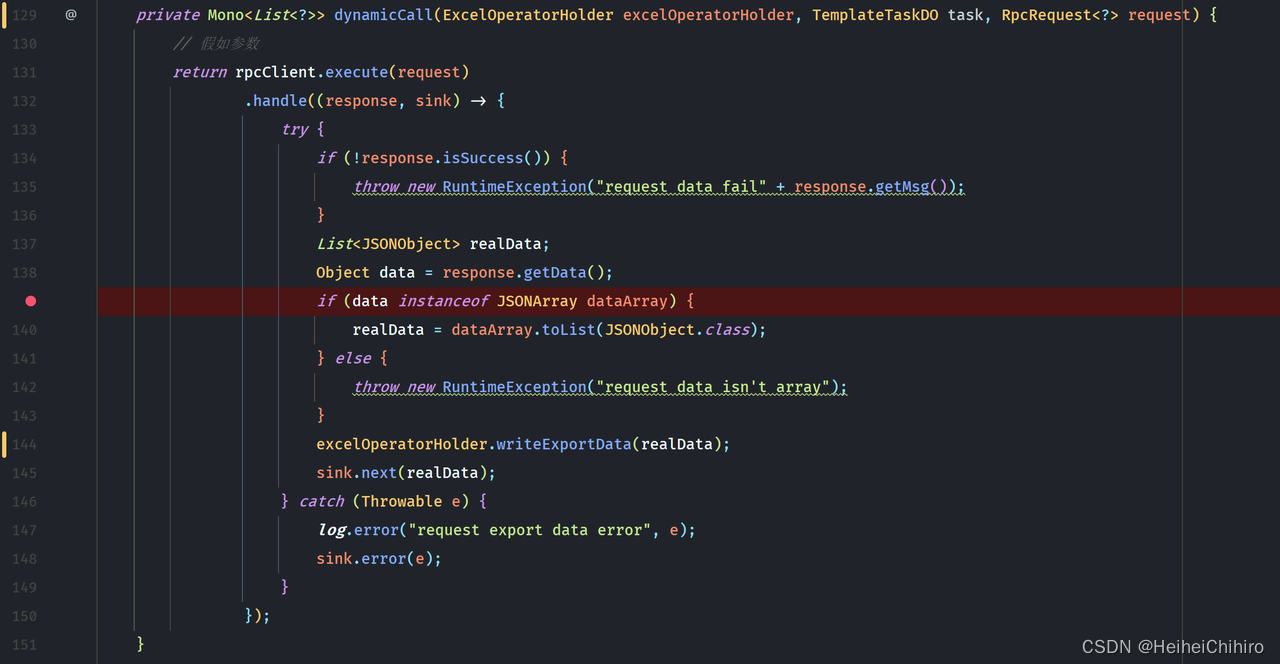
在dynamicCall中,先使用rpc请求远程的服务,并在handle中对返回的数据做处理,最后通过sink传递给下游。具体rpcClient怎么设计的,我们后面再详细讲,这里不展开.
handle方法相对于flatMap、map操作符更加灵活,它能拿到当前流的sink,通过sink去发送各种元素、信号,没有太多类型上的限制。
自定义rpc协议(超级简陋版)的实现
项目中的rpc通过reactor-netty编写,未使用webflux自带的webClient,有以下几个原因
- 自带的WebClient使用的是http协议,对于rpc场景冗余的信息比较多,没必要(当然它比较成熟)
- 使用reactor-netty练练手,虽然简陋,但是收获多(主要原因…)
- 这里先贴一下reactor-netty的官网,reactor-netty是对netty的完整reactor实践
https://projectreactor.io/docs/netty/release/reference/index.html
rpc的消息格式
前一小节讲了rpc请求-接收的大致流程,相信读者应该已经明白的差不多了,这一节我稍微展示下消息格式的设计,由于消息格式以及其编解码属于netty的内容,本节也不会展开讲。本项目的消息格式设计比较简单, 总体上是基于netty本身的LengthFieldBasedFrameDecoder去设计,也就是在encode时包含消息各部分的长度信息,再通过长度信息读到byte[]中去,最后组装成消息对象
- 消息格式MessageProtocol
@Getter
@ToString
@Accessors(chain = true)
@Builder
public class MessageProtocol {
// 消息类型 0x1请求 0x2回复
private byte command;
// 消息头
private ProtocolHeader header;
// 消息体
private byte[] data;
@Data
@Accessors(chain = true)
public static class ProtocolHeader {
// 消息id
private long msgId;
// 任务类型 1-导出 2-导入
private int taskType;
}
}
MessageProtocol是netty直接encode、decode的对象,它属于rpc协议的底层,对api调用方来说是感知不到的
消息格式总体上分为3部分:
- 消息类型
表示是请求、还是响应
- 消息头
包含了消息的额外信息,比如消息id、任务类型、消息发送方的时间戳。
其中消息id非常重要,它是一次请求-响应的唯一标识
- 消息体
消息的具体内容。由于数据内容无确定类型,因此用byte[]表示
2. 请求对象RpcRequest
RpcRequest是项目中RpcClient使用的标准请求体
@Data
public class RpcRequest<T> {
// 请求配置参数,不会传给远程机器
private Attach attach;
// 实际传输对象
private T data;
@Data
@Accessors(chain = true)
public static class Attach {
// 服务name
private String serviceId;
// 任务类型
private Integer taskType;
// 重试次数
private int retryNum;
// 超时时间
private int timeout;
}
public static <T> RpcRequest<T> get(String serviceId, Integer taskType) {
Attach attach = new Attach()
.setTaskType(taskType)
.setServiceId(serviceId)
.setRetryNum(3)
.setTimeout(3000);
RpcRequest<T> request = new RpcRequest<>();
request.setAttach(attach);
return request;
}
}
RpcRequest包含了两部分,Attach是本次请求的配置信息,比如请求服务名称、超时设置,而data就是真正要传输的消息对象了
3. 响应对象RpcResponse
@Builder
@Getter
public class RpcResponse<T> {
// 响应码
private Integer code;
// 数据对象
private T data;
// 文本消息
private String msg;
public static class RespCode {
public static final Integer REQ_DEFAULT = 0;
public static final Integer SUCCESS = 200;
public static final Integer FAIL = 500;
}
public boolean isSuccess() {
return Objects.equals(RespCode.SUCCESS, code);
}
}
RpcResponse是消息响应的标准包装类,code是它的返回码,data是实际返回的数据,msg是发生错误时返回的文本消息,与RpcRequest不同,RpcRequest只有data会被传给服务端,而RpcResponse会被完整的传回给客户端
消息编码器和解码器
消息的编码和解码不打算讲解,这块是netty中对MessageToByteEncoder、LengthFieldBasedFrameDecoder 的应用,它的思路其实就是在对数据编码时,加入每个字段的长度信息(长度信息的长度是固定的),在解码时先读取字段长度,再正确的读出数据
DataEncoder
@Slf4j
public class DataEncoder extends MessageToByteEncoder<MessageProtocol> {
@Override
protected void encode(ChannelHandlerContext ctx, MessageProtocol msg, ByteBuf out) throws Exception {
int messageLength = NettyCoreConfig.typeLength + NettyCoreConfig.headerLength;
byte[] dataBytes = null;
if (msg.getData() != null) {
dataBytes = SerializeFactory.serialize(SerializeEnum.FASTJSON2, msg.getData());
messageLength += dataBytes.length;
}
byte type = msg.getCommand();
out.writeInt(messageLength);
out.writeByte(type);
out.writeLong(msg.getHeader().getMsgId());
out.writeInt(msg.getHeader().getTaskType());
if (dataBytes != null) {
out.writeBytes(dataBytes);
}
}
}
DataDecoder
@Slf4j
public class DataDecoder extends LengthFieldBasedFrameDecoder {
public DataDecoder(int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment,
int initialBytesToStrip) {
super(maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip);
}
@Override
protected MessageProtocol decode(ChannelHandlerContext ctx, ByteBuf inEx) throws Exception {
// 获得派生ByteBuf
ByteBuf in = (ByteBuf) super.decode(ctx, inEx);
try {
if (in == null) {
return null;
}
if (in.readableBytes() < NettyCoreConfig.headSize) {
return null;
}
int frameLength = in.readInt();
if (in.readableBytes() < frameLength) {
return null;
}
MessageProtocol.MessageProtocolBuilder builder = MessageProtocol.builder();
byte type = in.readByte();
builder.command(type);
builder.header(readHeader(in));
byte[] dataBytes = new byte[frameLength - NettyCoreConfig.headerLength - NettyCoreConfig.typeLength];
in.readBytes(dataBytes);
builder.data(dataBytes);
return builder.build();
} finally {
if (in != null) {
in.release();
}
}
}
rpc的请求接收&连接池的实现
来看一下RpcClient的代码,我们前面请求任务数据时调用的它。
RpcClient的代码非常简单,没有复杂的链路追踪、灰度、保活、中心化,大道至简…
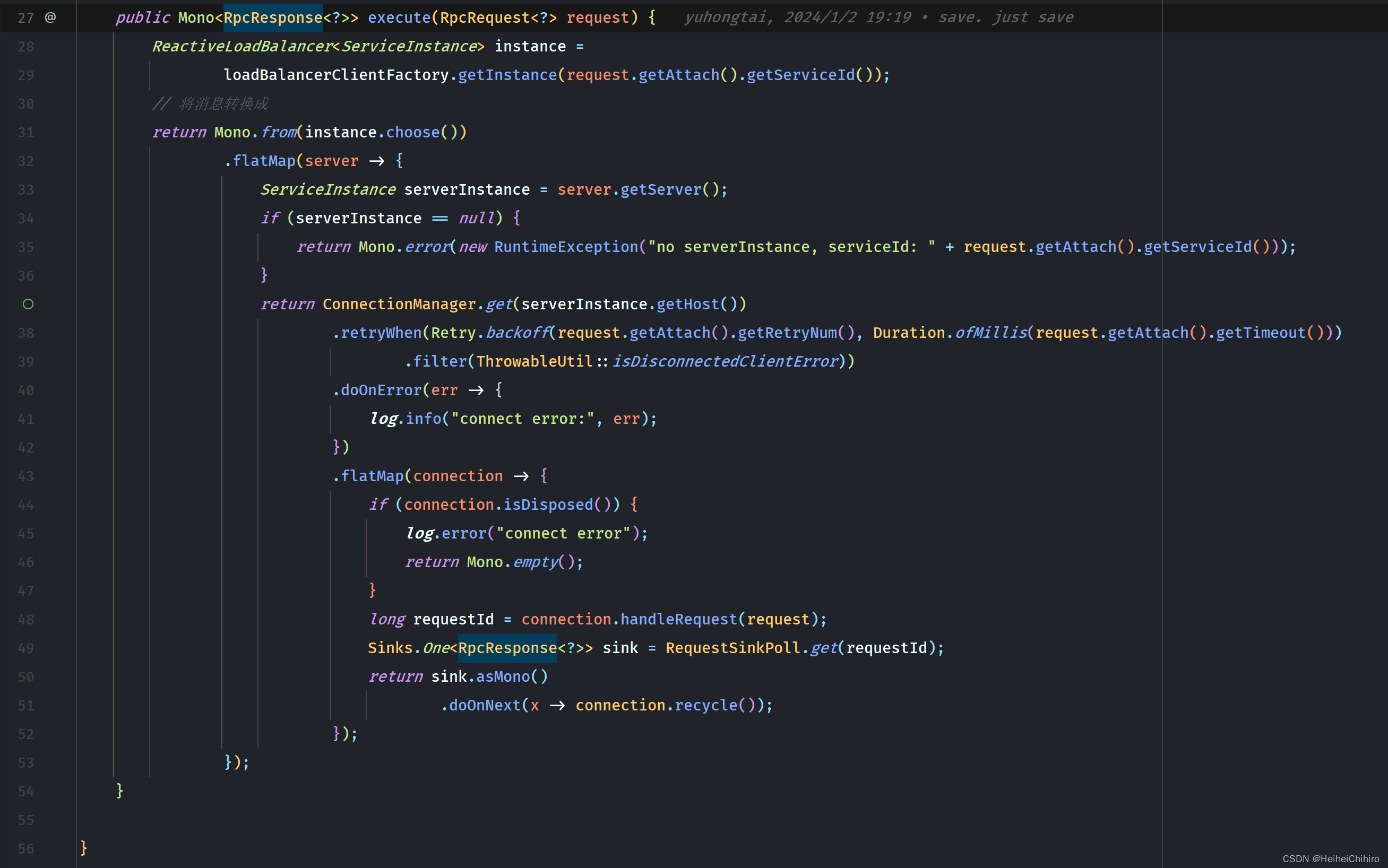
1. 获得当前请求的服务实例,初始化
35行 通过spring cloud内置均衡组件LoadBalancerClientFactory,传入服务的名称,获得响应式均衡负载服务实例对象(ReactiveLoadBalancer) instance,通过它的choose方法,我们可以得到被选中的服务实例对象信息。ReactiveLoadBalancer可以自定义实现类,以满足定制化的均衡负载逻辑

接着,将instance的choose方法的返回结果作为流的开始,在flatMap中拿到服务实例,通过ConnectionManager.get()方法从连接池里取出connection。连接的建立,回收等逻辑都在ConnectionManager中
38行 retryWhen的作用是在收到error信号时,过滤并重试当前的流。
它的参数是一个Retry对象,里面包含着最大重试次数和指数退避的初始时间间隔(也可以设置成固定的),这里建议看api。我们在filter中,过滤掉不属于IO、网络异常之外的case,保证只有网络异常的情况才会进行重试
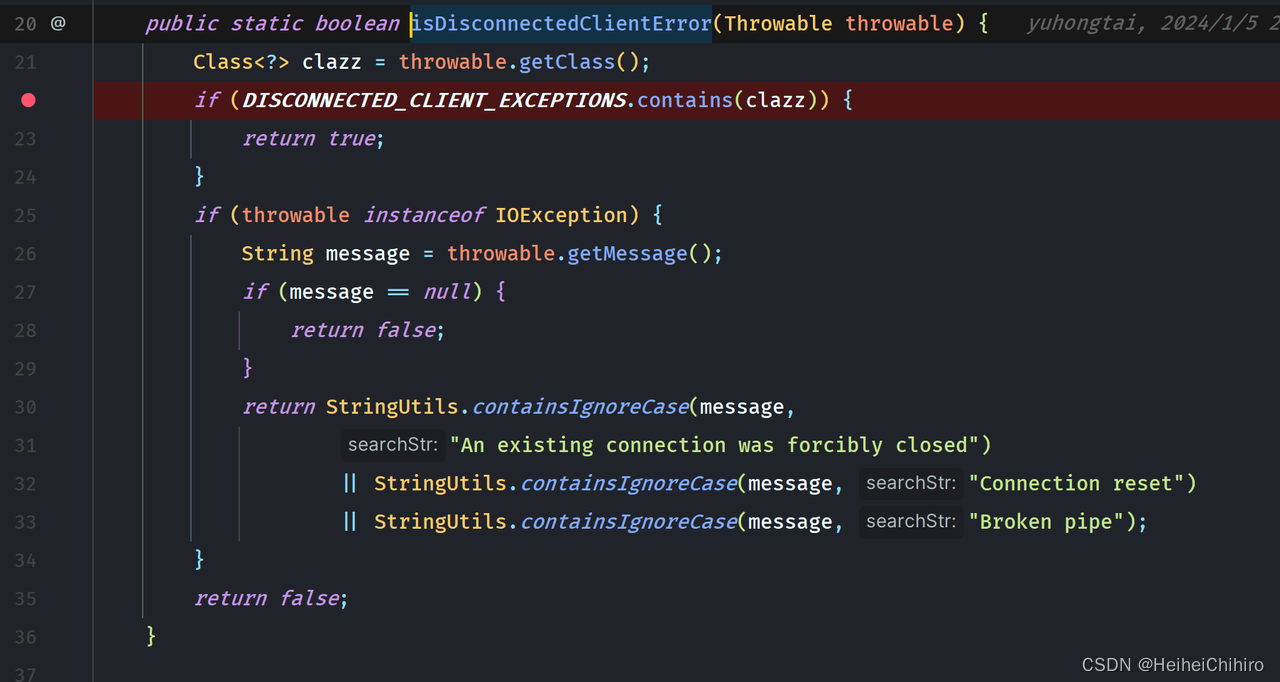
注意: retry的重试范围
retryXXX()系列的api有一个需要特别注意的点是它的执行范围,它只会重试当前所在的流。我们直接看个例子:================================ Test 1 ======================================= @SneakyThrows public static void main(String[] args) { AtomicInteger count = new AtomicInteger(); Flux<Integer> flux1 = Flux.just(1, 2, 3); Flux<Integer> flux2 = Flux.just(9, 10, 11); flux1.doOnNext(data -> { System.out.println(data); }) .thenMany(flux2.doOnNext(data2 -> { System.out.println(data2); if (count.incrementAndGet() > 2) { count.set(0); throw new RuntimeException(); } }) .retry(3)) // 开始重试,注意此时它是挂在flux2上的 .subscribe(); Thread.sleep(1000000L); } // 上面的代码,flux1输出几遍,flux2输出几遍? // 答案是flux1输出1遍,flux2输出3遍,然后抛出异常,如下所示: 1 2 3 9 10 11 9 10 11 9 10 11 9 10 11 14:34:51.299 [main] ERROR reactor.core.publisher.Operators -- Operator called default onErrorDropped reactor.core.Exceptions$ErrorCallbackNotImplemented: java.lang.RuntimeException Caused by: java.lang.RuntimeException: null .... ================================ Test 2 ======================================= //我们小小地改变一下retry的位置,看下输出的变化 @SneakyThrows public static void main(String[] args) { AtomicInteger count = new AtomicInteger(); Flux<Integer> flux1 = Flux.just(1, 2, 3, 4, 5, 6, 7, 8); Flux<Integer> flux2 = Flux.just(9, 10, 11); flux1.doOnNext(data -> { System.out.println(data); }) .thenMany(flux2.doOnNext(data2 -> { System.out.println(data2); if (count.incrementAndGet() > 2) { count.set(0); throw new RuntimeException(); } })) .retry(3) // 位置改变了哦,现在它挂在flux1和flux2共同组成的流上 .subscribe(); Thread.sleep(1000000L); } // 输出 1 2 3 9 10 11 1 2 3 9 10 11 1 2 3 9 10 11 1 2 3 9 10 11 14:40:59.288 [main] ERROR reactor.core.publisher.Operators -- Operator called default onErrorDropped reactor.core.Exceptions$ErrorCallbackNotImplemented: java.lang.RuntimeException Caused by: java.lang.RuntimeException: null at pers.nanahci.reactor.datacenter.core.netty.RpcClient.lambda$main$7(RpcClient.java:89) at reactor.core.publisher.FluxPeekFuseable$PeekFuseableSubscriber.onNext(FluxPeekFuseable.java:196) at reactor.core.publisher.FluxArray$ArraySubscription.fastPath(FluxArray.java:172) at reactor.core.publisher.FluxArray$ArraySubscription.request(FluxArray.java:97) at reactor.core.publisher.FluxPeekFuseable$PeekFuseableSubscriber.request(FluxPeekFuseable.java:144) at reactor.core.publisher.FluxConcatArray$ConcatArraySubscriber.onSubscribe(FluxConcatArray.java:193) at reactor.core.publisher.FluxPeekFuseable$PeekFuseableSubscriber.onSubscribe(FluxPeekFuseable.java:178) at reactor.core.publisher.FluxArray.subscribe(FluxArray.java:53) at reactor.core.publisher.FluxArray.subscribe(FluxArray.java:59) at reactor.core.publisher.Flux.subscribe(Flux.java:8773) at reactor.core.publisher.FluxConcatArray$ConcatArraySubscriber.onComplete(FluxConcatArray.java:258) at reactor.core.publisher.FluxConcatArray.subscribe(FluxConcatArray.java:78) at reactor.core.publisher.FluxRetry$RetrySubscriber.resubscribe(FluxRetry.java:117) at reactor.core.publisher.FluxRetry.subscribeOrReturn(FluxRetry.java:52) at reactor.core.publisher.Flux.subscribe(Flux.java:8759) at reactor.core.publisher.Flux.subscribeWith(Flux.java:8894) at reactor.core.publisher.Flux.subscribe(Flux.java:8739) at reactor.core.publisher.Flux.subscribe(Flux.java:8663) at reactor.core.publisher.Flux.subscribe(Flux.java:8581) at pers.nanahci.reactor.datacenter.core.netty.RpcClient.main(RpcClient.java:93) // 1,2,3,9,10,11都被输出了3遍 ,太长了,我直接说明
-
43行 flatMap 发送消息,并返回接收消息Mono
- 先检查connection是否关闭,若关闭了,则直接返回Mono.empty()
- 若未关闭,则调用handleRequest()发送请求消息
在handleRequest中,RequestSinkPoll会为每一个发送的消息赋予一个唯一的msgId,即消息header中的msgId字段,服务端处理完成返回响应时,带的也是这个msgId。该msgId在requestSinkPol中会对应到一个sink对象,当inbound收到消息后,会通过msgId找到该sink,并发射元素 - 通过msgId获取对应的sink,返回该sink的Mono对象,并在Mono上编排doOnNext方法,保证inbound收到消息后,connection会被回收
-
回到37行的ConnectionManager,我们重点来看一下
@Slf4j
public class ConnectionManager {
// 连接池
private static final ConnectionPool connectionPool = new ConnectionPool();
// 连接管理器handler
private final static DataChannelManager dataChannelManager = new DataChannelManager();
// 回收器接口。由于回收器逻辑不多,代码较少,为了提高代码内聚,所有的Recycle都会定义在当前类中,所以用的是内部接口
public interface Recycle {
// 负责回收链接
void recycle(RConnectionHolder connection);
}
// noop连接回收器,它不会回收任何的链接
private static final Recycle NOOP_RECYCLE = new Recycle() {
@Override
public void recycle(RConnectionHolder connection) {
// do nothing
}
};
// 回收器,若connection未被关闭,则将连接放入到连接池
private static final Recycle NORMAL_RECYCLE = new Recycle() {
@Override
public void recycle(RConnectionHolder connection) {
if (connection.isDisposed()) {
return;
}
connectionPool.add(connection);
}
};
// 通过host获取对应的connection,由于调用链路上是reactive的,因此返回的是Mono对象
public static Mono<RConnectionHolder> get(String host) {
// 从池子拿
return Mono.fromSupplier(() -> connectionPool.poll(host))
.switchIfEmpty(
// 创建新的connection
Mono.defer(() -> TcpClient.create()
.host(host)
.port(9896) // 我写死了,可以配置
.runOn(LoopResources.create("rexcel-req-client"))
.doOnChannelInit((connectionObserver, channel, remoteAddress) -> initPipeline(channel.pipeline()))
.doOnConnected(ConnectionManager::initConnection)
.wiretap(true)
// 在map中将connection封装成RConnection
.connect()).map(connection ->
new RConnectionHolder(connection, NORMAL_RECYCLE)
)
// 链接成功打印日志
.doOnSuccess(connection -> {
log.info("connect success,channel id:[{}]", connection.getConnection().channel().id());
})
);
}
private static void initPipeline(ChannelPipeline pipeline) {
pipeline.addFirst(new IdleStateHandler(0, 0,
NettyCoreConfig.maxIdleTime), dataChannelManager);
pipeline.addLast(EventExecutorPoll.DEFAULT_EVENT_EXECUTOR,
new DataDecoder(NettyCoreConfig.maxFrameLength,
NettyCoreConfig.lengthFieldOffset, NettyCoreConfig.lengthFieldLength,
NettyCoreConfig.lengthAdjustment, NettyCoreConfig.initialBytesToStrip),
new DataEncoder());
}
private static void initConnection(Connection conn) {
conn.addHandlerFirst(new IdleStateHandler(0, 0,
NettyCoreConfig.maxIdleTime));
conn.addHandlerLast(dataChannelManager);
conn.addHandlerLast(new DataDecoder(NettyCoreConfig.maxFrameLength,
NettyCoreConfig.lengthFieldOffset, NettyCoreConfig.lengthFieldLength,
NettyCoreConfig.lengthAdjustment, NettyCoreConfig.initialBytesToStrip));
conn.addHandlerLast(new DataEncoder());
}
}
ConnectionManager主要做了以下这些事
- 获取Connection
- 创建Connection
- 回收Connection
其逻辑流程图如下表示:
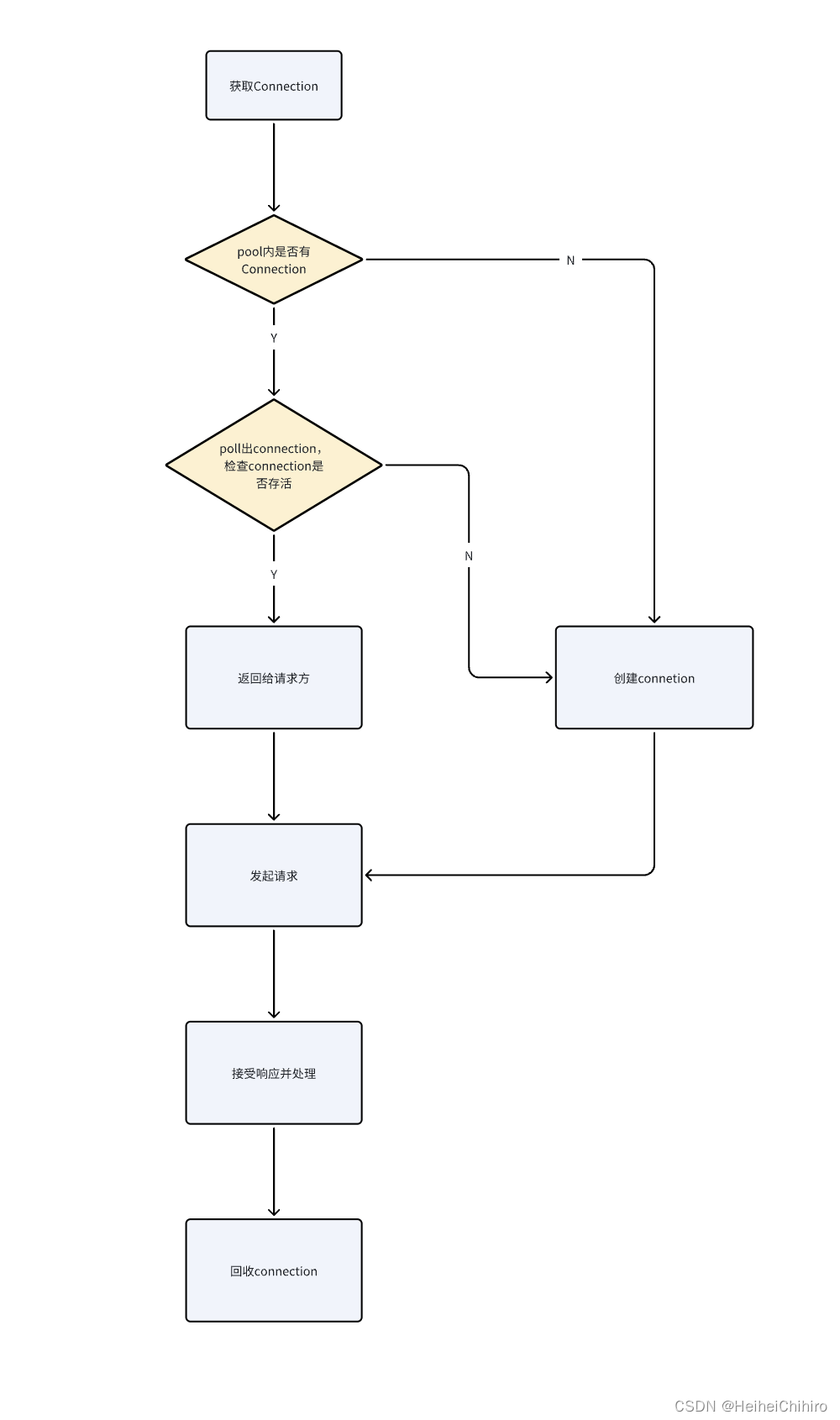
当发起请求的时候,会先从连接池中poll一条connection出来,检查是否存活,如果存活了则返回。若connection已经关闭了,或着poll内没有connection,则重新new一条请求,将其包装成RConnection,将连接回收器放进去,并订阅inbound链路。
下面是订阅inbound的代码,其位于RConnection中,在构造函数中调用
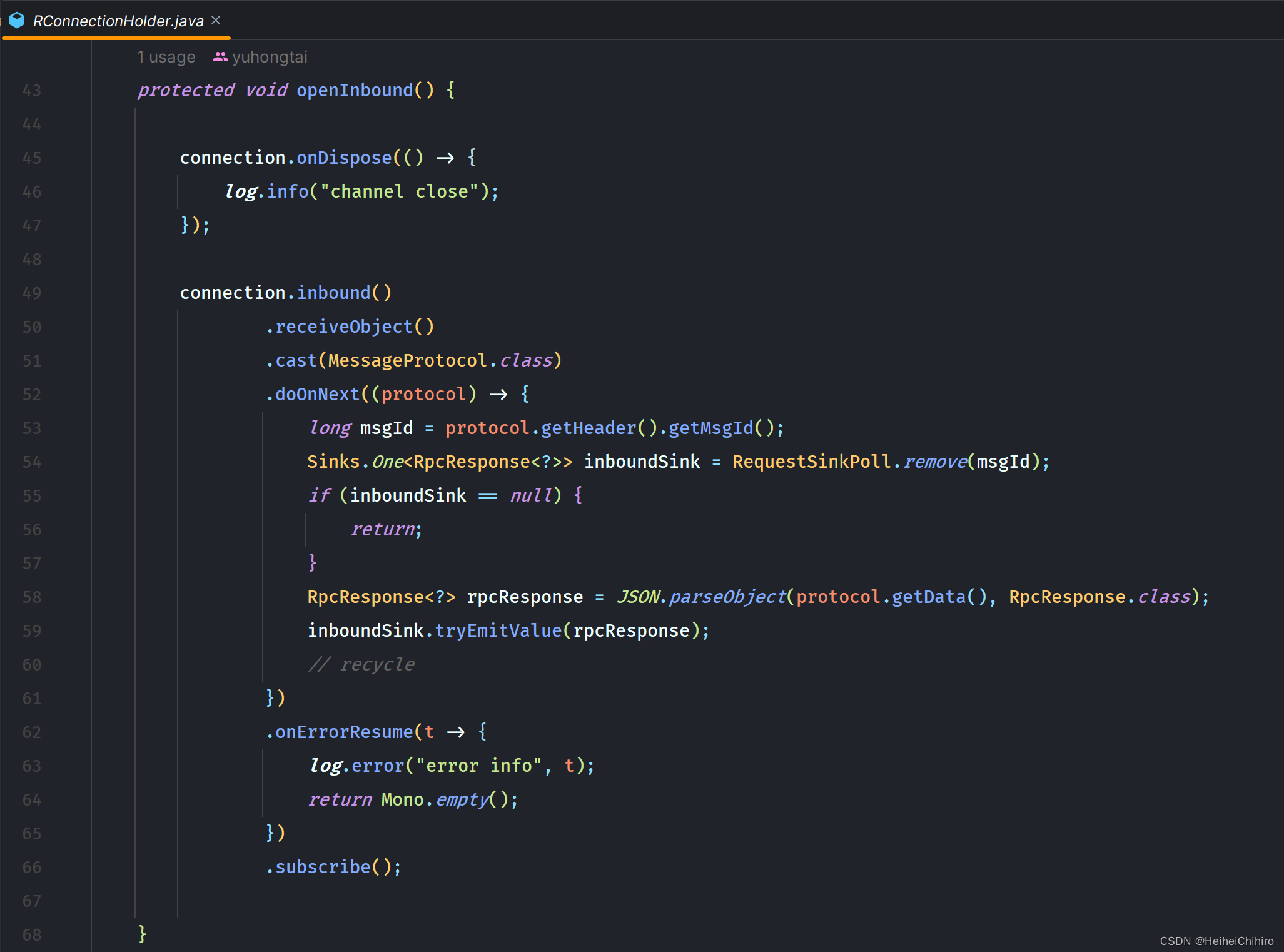
逻辑讲解: 获得connection的inbound,通过cast获取MessageProtocol对象,注意 对象类型取决于Decoder中返回的类型,不能乱填。接着在doOnNext中,获取响应的msgId,将其从RequestSinkPoll中remove出来,然后转换对象类型,通过sink发射元素
注意,要在inbound流上调用subscribe方法,否则inbound流没有订阅者,这些逻辑都不会触发,我们就没法拿到接收的消息
sdk端
服务准备
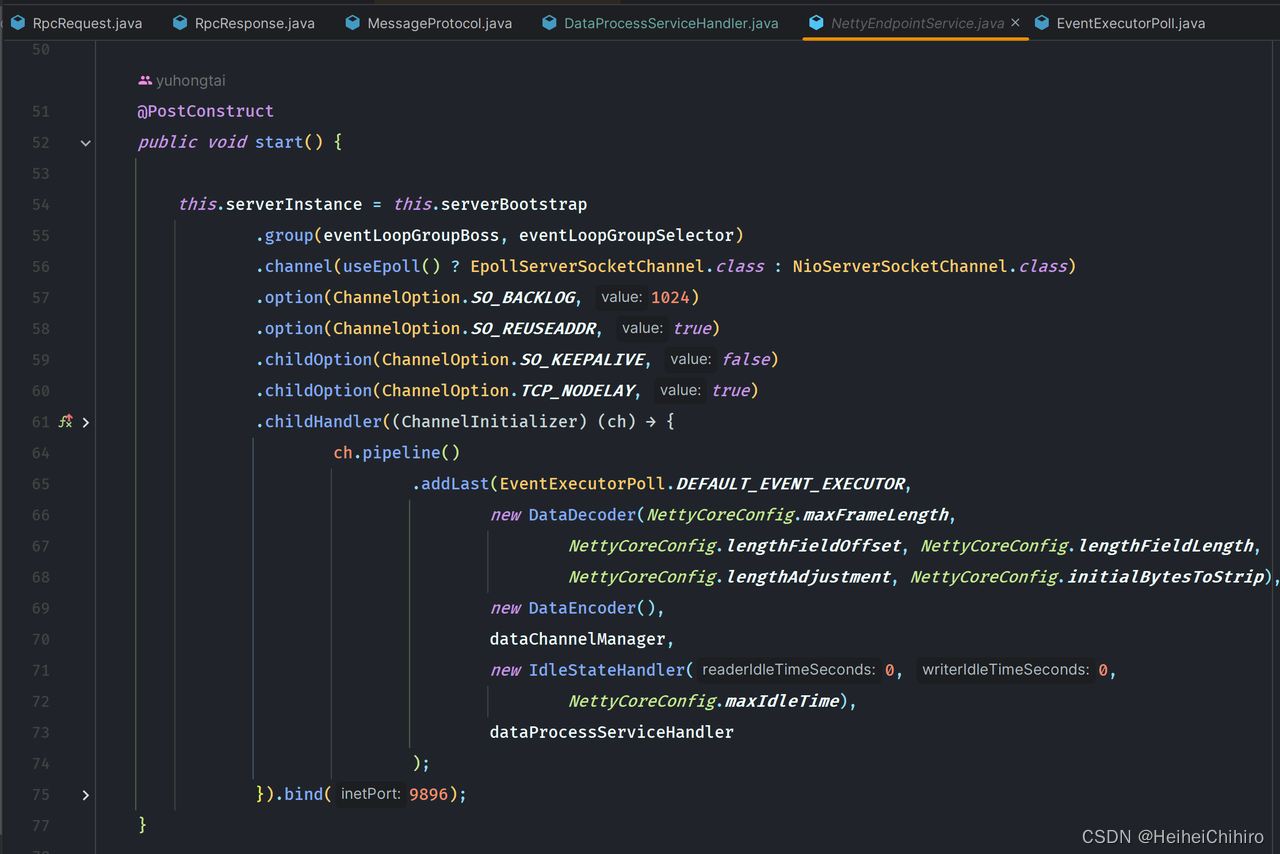
为了接收来自客户端的消息,我们需要在引入sdk的服务端绑定端口,对来自客户端的消息进行监听,NettyEndpointService正是为此而创建, 我们在NettyEndpointService的start方法中开启了对特定端口的监听
-
useEpoll方法是为了在当前系统是linux时,使用EpollServerSocketChannel,以获得更好的性能。
-
设置channel的参数:
channel(监听channel)
- ChannelOption.SO_BACKLOG. 对应于tcp/ip协议中的backlog参数,表示的是服务端可连接队列数,服务端会将待处理的连接放入队列中,若超过backlog的数量,则无法再建立连接
- ChannelOption.SO_REUSEADDR. 对应于套接字选项中的SO_REUSEADDR. 该参数表示允许重复使用本地地址和端口,比如A和B两个程序同时监听80端口,需要开启这个设置
childChannel(socket channel)
- ChannelOption.SO_KEEPALIVE. 连接保活,若channel长时间没有数据交流,则关闭链接
- ChannelOption.TCP_NODELAY. 不使用Nagle算法,不缓存小包等到攒到大包了才发送,避免消息的延迟
-
初始化channel处理器,按顺序添加编码器、解码器、channel管理器、idle管理器以及数据处理DataProcessServiceHandler
接收并处理数据
与使用了reactor的客户端不同,sdk端没有使用reactor,这里主要是考虑到了一般的业务项目不太会引入project reactor(用也可以),因此直接使用了原生的netty进行开发
rpc接收消息流程如下:
DataProcessServiceHandler 负责接收消息,捕获异常并返回数据给客户端
->
TaskDispatcher 负责将消息交给对应的任务类型处理器
->
TaskTypeProcessor 任务类型处理器,专门负责处理一种类型的任务
->
ExcelHandler 用户自定义实现的业务逻辑
DataProcessServiceHandler继承了SimpleChannelInboundHandler,内部聚合了TaskDispatcher,它是任务bean的聚合类,通过TaskDispatcher我们可以找到对应的任务类型处理器。每一个任务类型处理器都会实现TaskTypeProcessor接口,在config类中通过@Bean注册到容器
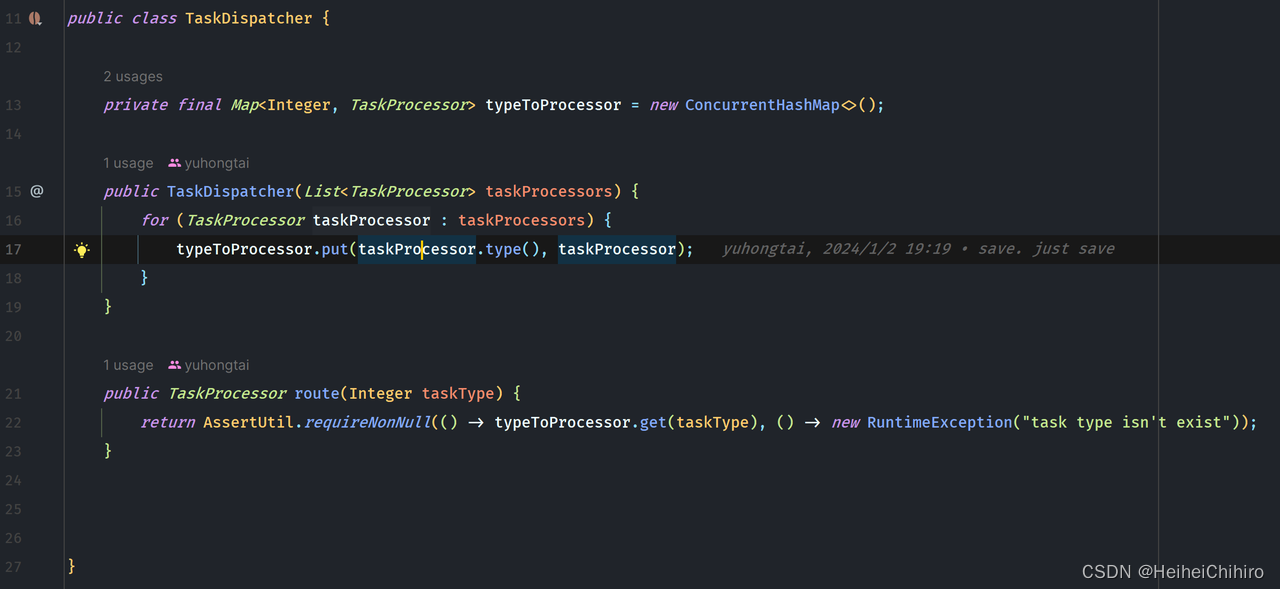
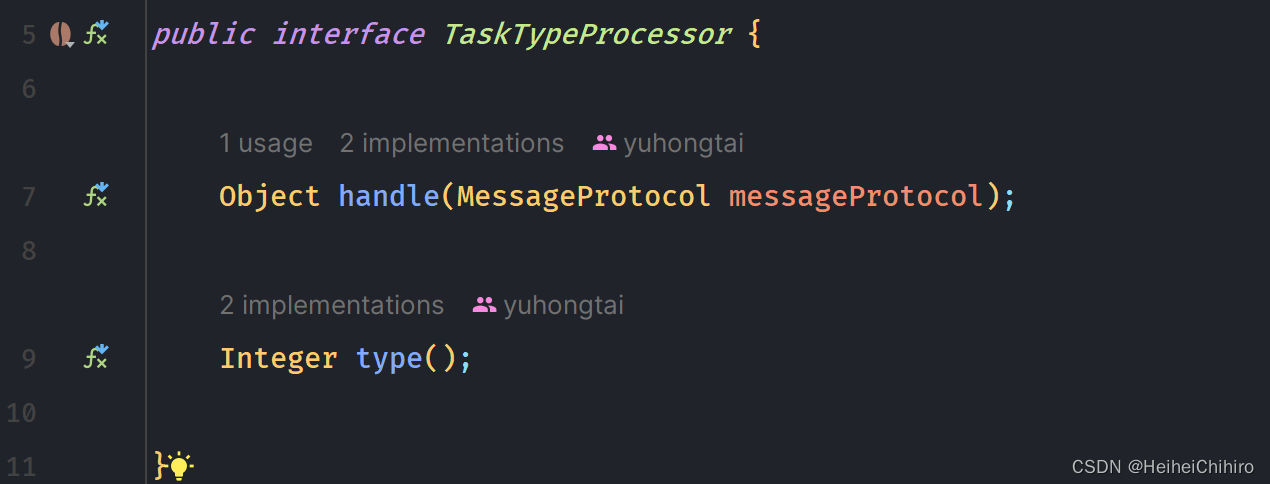
sdk消息处理逻辑入口在DataProcessServiceHandler的channelRead0方法中,DataProcessServiceHandler本身是一个ChannelHandler
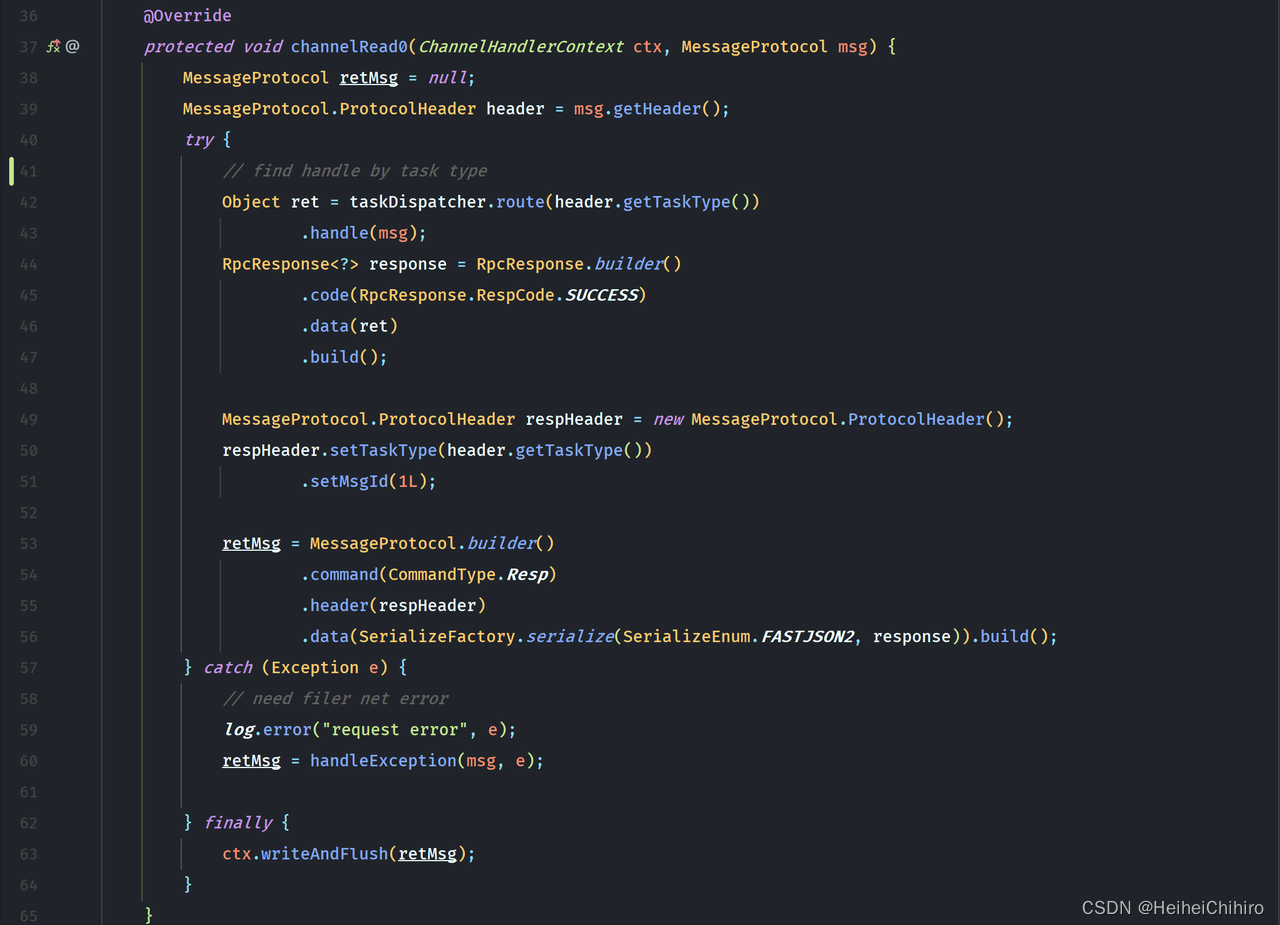
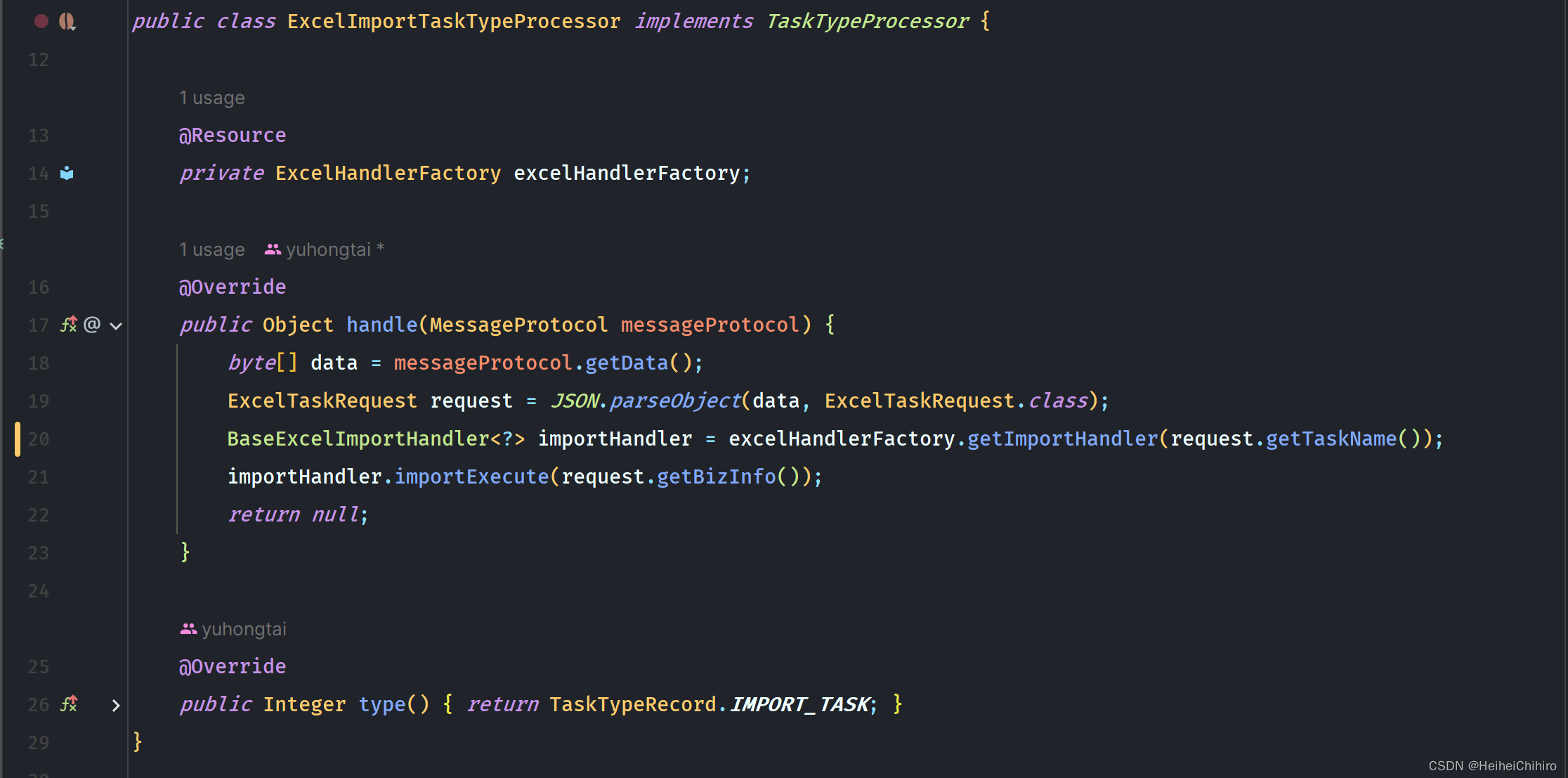
- 首先从header中取出任务类型,通过taskDispatcher的route方法,找到对应的TaskTypeProcessor,调用handle方法处理消息。以ExcelExportTaskTypeProcessor为例,我们看看代码
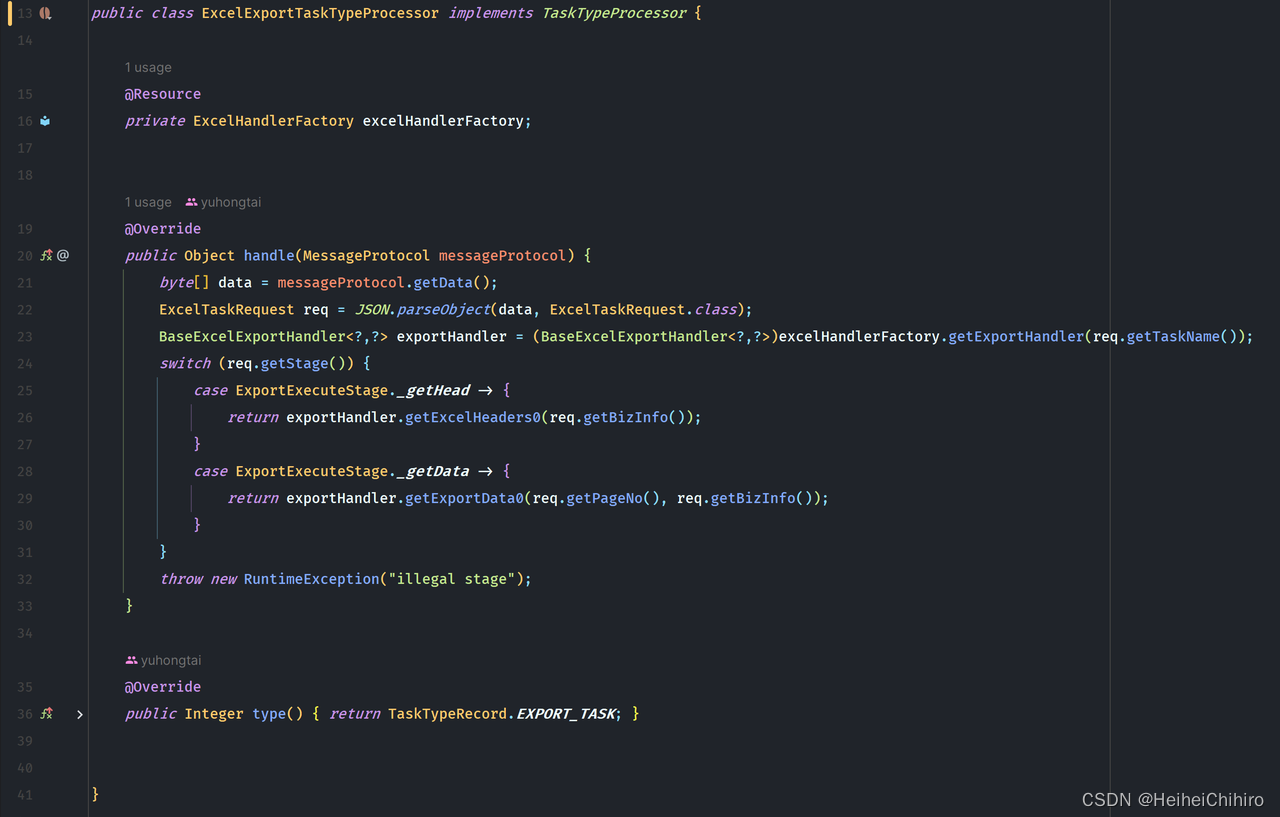
ExcelExportTaskTypeProcessor持有ExcelHandlerFactory,它是ExcelHandler的工厂管理类,
- 取出MessageProtocal中的data,将其转换成该任务对应的数据类型,接着依据taskName参数去获取用户自己实现的ExcelExportHandler, 再将参数传入方法内,获取excel表头或excel数据
- 将TaskProcessor返回的数据组装成RpcResponse,若发生异常则调用异常处理方法,生成带错误msg、code为500的RpcResponse
- 在finally中写入到channel
任务处理器的实现
sdk端的任务处理器采用注解驱动的形式
- 任务导出
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface ExcelExport {
// 任务名称
String value();
}
- 任务导入
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface ExcelImport {
// 任务
String value();
}
两个注解的内容比较简单,只有默认的value熟悉,它对应的就是任务名称,一个业务服务中,任务名称不能重复。
任务处理器的关系结构如下
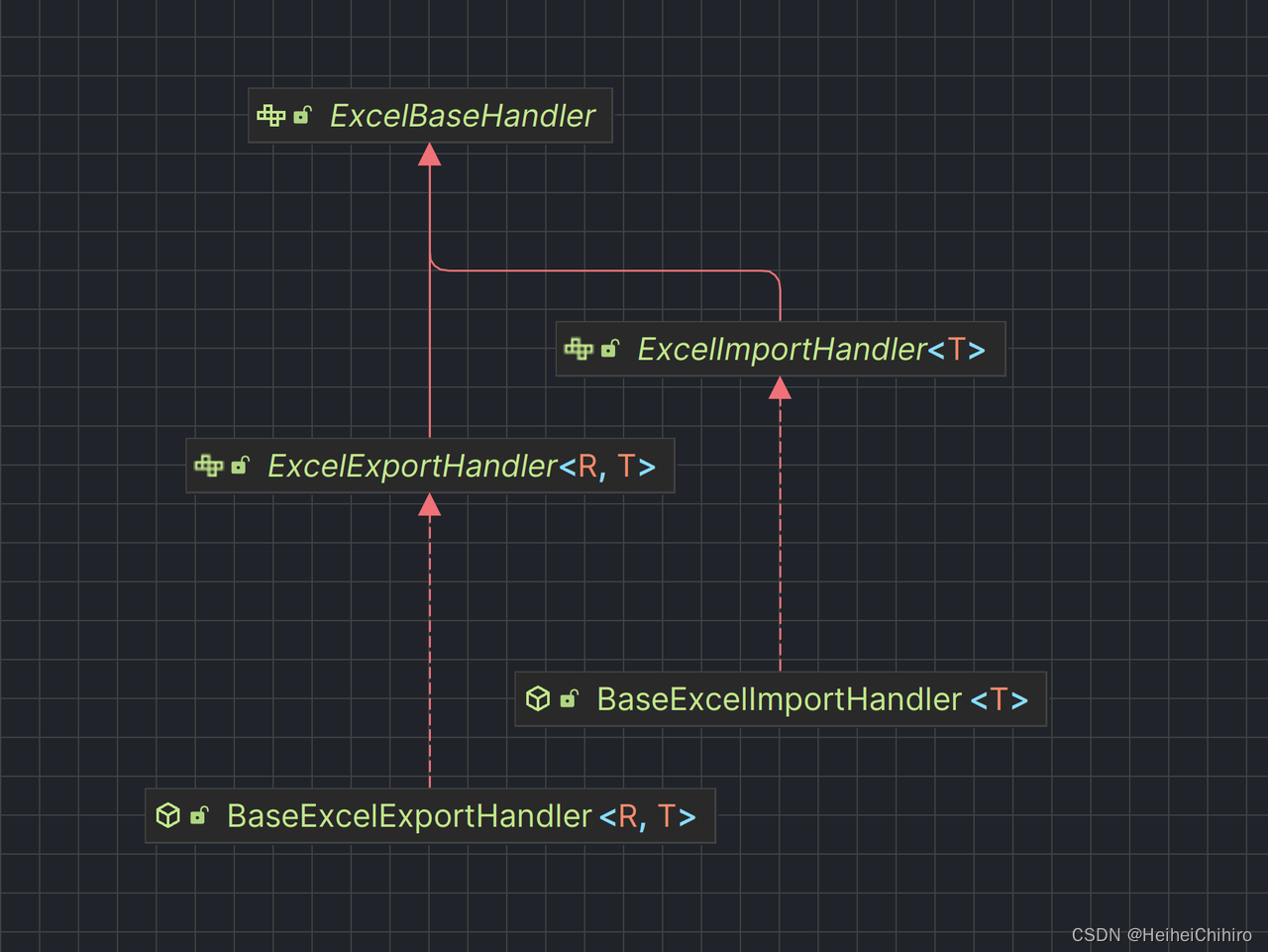
任务处理器是用户自定义的业务逻辑处理器,需要配合注解使用,下面是一个简单的例子:
@ExcelExport("testExcelTask")
@Component
@Slf4j
public class TestExcelExportHandler extends BaseExcelExportHandler<TestResp, TestReq> {
private int index = 0;
// 返回excel表头
@Override
public List<List<String>> getExcelHeaders(TestReq param) {
List<String> names = new ArrayList<>();
names.add("姓名");
List<String> bazi = new ArrayList<>();
bazi.add("八字");
//---------------------------------------------
List<List<String>> res = new ArrayList<>();
res.add(names);
res.add(bazi);
return res;
//return null;
}
// 返回excel数据
@Override
public List<TestResp> getExportData(Integer pageNo, TestReq param) {
List<@Nullable TestResp> testRespList = Lists.newArrayList();
if(pageNo > 1000){
return testRespList;
}
for (int i = 0; i < 1000; i++) {
TestResp testResp = new TestResp();
testResp.setName("俞鸿泰dawdawdawdawdawdadhukwanjdnasjd: "+(index++));
testResp.setBazi("wndkajnwduanjkdnwajkkndmsdlakwndklawmdklad mlkwamdklw"+(index));
testRespList.add(testResp);
}
log.info("当前页:[{}]",pageNo);
return testRespList;
}
}
@ExcelExport(“testExcelTask”)标识它的任务类型是导出,名称是"testExcelTask",同时它继承了任务处理器父类BaseExcelExportHandler,表明他是个任务处理器
继承任务处理器接口BaseExcelExportHandler的实现类会被ExcelHandlerFactory收集,by任务类型放到不同的map里,key是任务名称
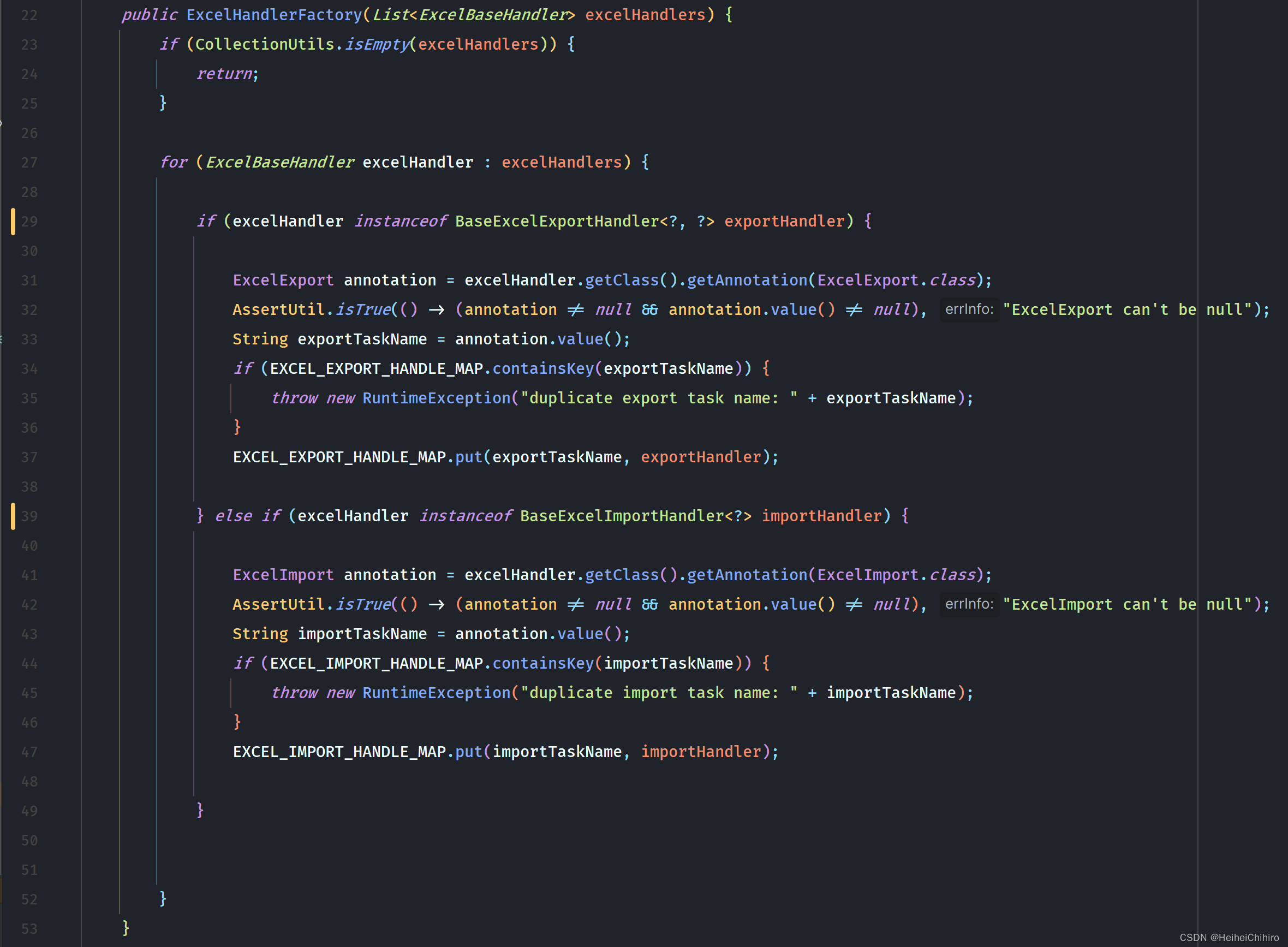
在ExcelExportTaskTypeProcessor中,handle方法里会通过任务名称从ExcelhandleFactory中拿到对应的处理器并调用方法,拿取excel的数据
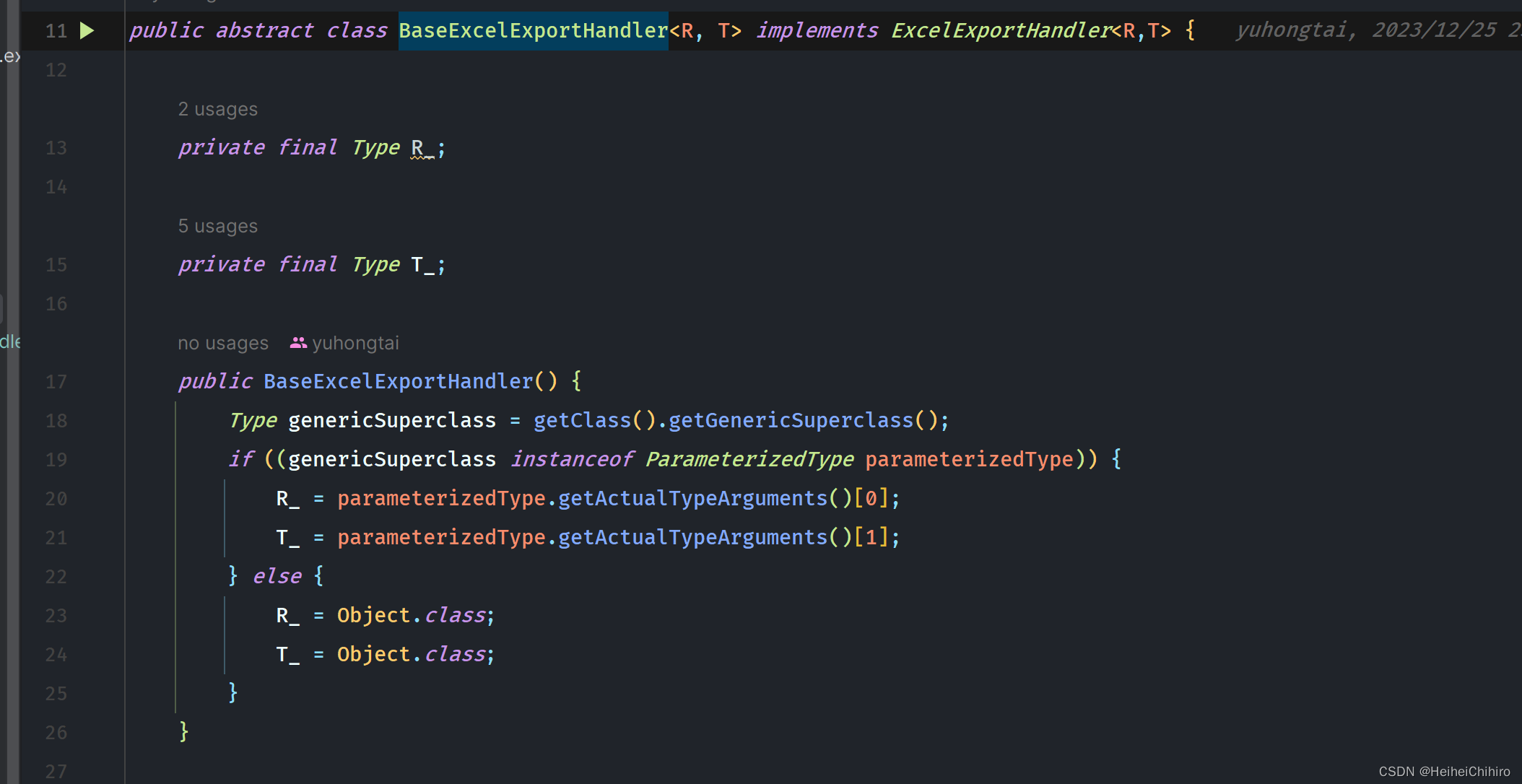
注意: BaseExcelExportHandler抽象类实现了类自身泛型的获取,获取泛型是为了byte[]的反序列化
结语
本文写的还是有些仓促,有一些点表述的不是很好,还请读者见谅,后续我再改改~

















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









