






昨天面试被老师狠狠拷打了差分隐私,于是今天决定好好复习一下。遂写了这一篇。。。
核心思想:
通过对数据或查询结果添加噪声,使得任何单个个体是否存在与数据集中,对最终发布的统计分析结果的影响微乎其微。攻击者即使看到了分析结果,也无法确定某个个体的记录是否对此结果有贡献。
核心目的:
在对包含敏感信息进行分析的时候,严格保护每个个体的隐私,防止从分析结果中推断特定个体的具体信息。
相关概念:
相邻数据集:两个数据集D与D'仅有一条记录不同。使用DP,在获取相邻数据集后,无法推断出这条记录的信息。
隐私预算ε:对隐私保护程度的量化。控制了在相邻数据集上输出同一个结果的概率比值的最大差异。ε 是一个累积量。对同一个数据集进行多次差分隐私查询时,每次查询都会消耗一部分隐私预算。总消耗超过预设的全局ε时,隐私保证就会失效。需要谨慎管理。ε越小,则隐私保护越强,加入的噪声越大。ε越大,允许输出的差异越大,隐私保护越弱,但数据可用性越高。
查询:数据集的映射函数f
敏感度Δf:用于度量数据集更改一个个体时,对查询结果的影响程度。敏感度越大,查询结果对个体数据变化更敏感,越不利于隐私保护。即为相邻数据集之间的最大差异值。
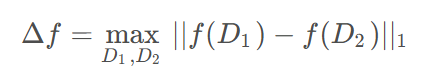
相关公式:
f(D):原始查询结果,未添加噪声
M(D):添加噪声后的查询结果。差分隐私的目的,就是使得M(D)与M(D‘)的分布尽可能接近
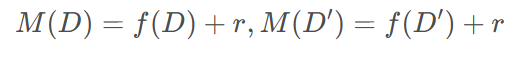
Pr[M(D)∈S]:算法M所有可能输出的结果的概率。Pr表示概率。S为所有可能输出结果的任意子集。
差分隐私的分类:
1.ε-差分隐私
一种严格的差分隐私。相邻数据库D1,D2,使用添加了随机扰动的查询机制M,得到所有可能输出的集合S,都有:
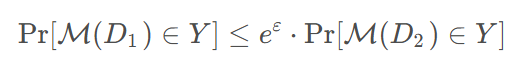
查询结果在相邻数据集之间的概率比不会超过e^ε。
2.(ε, δ)-差分隐私
一种较为松弛的差分隐私机制,允许有一定的失败概率δ。相邻数据库D1,D2,使用添加了随机扰动的查询机制M,得到所有可能输出的集合S,都有:
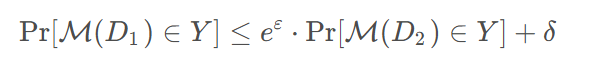
δ表示差分隐私保护失败的概率,为一个很小的正数。
加噪机制:
1.拉普拉斯机制(严格DP)
对原始查询结果添加拉普拉斯噪声。噪声服从拉普拉斯分布Y~L(0,Δf/ε)。
拉普拉斯机制的概率密度函数,其中μ = 0 ,b=Δf/ε:
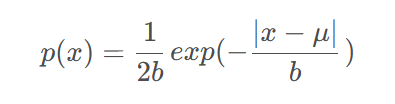
2.高斯机制(松弛DP)
对原始查询结果添加高斯噪声。噪声服从高斯分布Y~L(0,σ^2)。
高斯分布的概率密度函数,σ=Δf/ε。
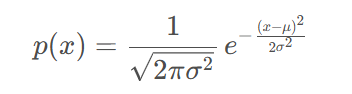
联邦学习中的DP:
1.本地差分隐私:每个客户端在上传之前就加噪声
优点:服务端完全看不到原始梯度,最强保护。
缺点:噪声大,模型性能可能下降。
eg:外卖平台的打分系统。每个用户上传分数,通过添加噪声来隐藏上传的具体分数。噪声保护了用户的具体分数,让商家没法知道谁打出了差评,但加入了噪声会影响平均分数,使得商家评分不准确。这个实例中,客户端梯度:用户评分,噪声:打分改变;服务器聚合:平均分数。
2.全局差分隐私:服务器在聚合前或后加噪声
优点:噪声较小,模型准确率高。
缺点:客户端数据在上传前未保护,对中间攻击者不安全。
DP-SGD
结合差分隐私和随机梯度下降的优化算法,保证深度学习模型在训练过程中保护数据隐私,同时通过梯度下降优化模型参数。
步骤:
梯度裁剪:限制每个样本的贡献。避免某个样本产生过大的影响。
添加噪声:保证每次更新不会泄露单个数据点的信息。
梯度更新:使用随机梯度下降来更新模型参数。
先写到这吧,之后如果还想到什么再补充。


















 1312
1312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











