







Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
目录
需要复现
整体评价
模型的工程性较强,面向实际工程中的:标注数据集少,通过弱监督方式得到弱监督数据集的情形。---------have both a small amount of strongly labeled data and a large amount of weakly labeled data
弱标记数据在训练过程中与强标记数据简单结合时,会降低模型性能
模型结构
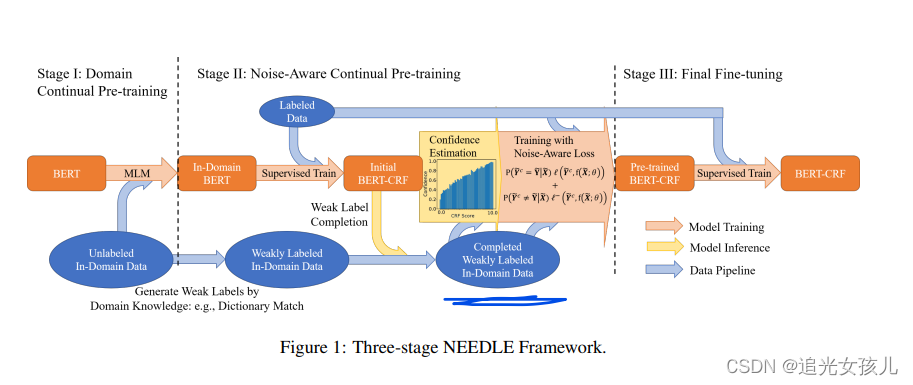
在有限的label data上,已有的研究成果
在无标注数据集上,重新迭代训练已有的预训练模型,以使得更好的适用于新的domain。
模型方法
**(1)采用PLM在target domain 的数据集上做预训练
(2)使用domain领域的知识库生成弱监督数据集(弱监督有标注数据集),并使用(1)中的模型,在弱监督数据集和labeled data 上继续微调。**这个过程称为noise-aware-weakly supervised learning,包括两个部分: weak label completion procedure and noise-aware loss function.
- Weak Label Completion
the encoder θenc is initialized from Stage I and NER CRF head is randomly initialized.
对于一个给定的弱监督的标注句子,其自身已有的label表示为Yw,利用模型补充的label为Yc,
**定义的规则是:**当Yw是O时,采用CRF预测的label作为补充的label,其他情况下,采用弱监督的label作为其label。
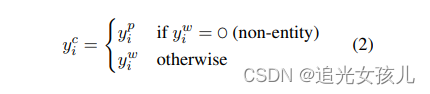
- Noise-Aware Loss Function——true label为Y,weak label为Yc
在weak data上的损失函数计算公式为:

在weak和labeled data上的,总的损失函数的计算公式是:
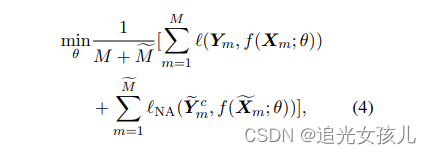
(3)将(2)预训练后的model在labeled data 重新微调。
实验部分
- 参数搜索(grid search)
- ablaltion study
• WLC: Weak label completion.
• NAL: Noise-aware loss function, i.e., Eq.(4).
Since NAL is built on top of WLC, the two components need to be used together.
• FT: Final fine-tuning on strongly labeled data
(Stage III).
- 分析部分
- size of weak data
- Size of Strongly Labeled Data.
- Weak Label Errors
- Label Distribution Mismatch.
- Entity BIO Sequence Mismatch in Weak Label
Completion. Another error of the weakly labels is
the mismatched entity BIO sequence in the weak
label completion step, e.g., B-productType followed by I-color
















 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











