







hive和数据库的区别
Hive 和数据库除了拥有类似的查询语言,再无类似之处。
1)数据存储位置
Hive 存储在 HDFS 。数据库将数据保存在块设备或者本地文件系统中。
2)数据更新
Hive中不建议对数据的改写。而数据库中的数据通常是需要经常进行修改的,
3)执行延迟
Hive 执行延迟较高。数据库的执行延迟较低。当然,这个是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
4)数据规模
Hive支持很大规模的数据计算;数据库可以支持的数据规模较小。
hive和rdbms的数据库区别?
hive是使用mr计算,使用yarn调度资源,使用mysql存储元数据,使用hdfs存储数据,对小文件不友好,适合大文件一般都是PB TB级别的文件,没有主键和其他的约束,只有一个位图的索引
内部表:通过create table 表名的方法,生成的表格,
- 先有一个数据文件
- 建立一个与文件格式对应的表格
- 将文件导入到表格中
外部表:
上面的所有表格,都称为数据库的内部表,接下来的是数据库的外部表。
内部表和外部表的区别是什么?***
什么是内部表?
直接使用create table创建的表格,表格会自动的在数据库所在的文件夹中,创建一个自己表格名字的文件夹。
删除表的时候,表格的文件夹和数据会一起被删除。
什么是外部表?
使用create external table创建的表格,自己不会生成文件夹,需要使用location去指定一个文件夹给它。
删除表的时候,表格的文件夹和数据会被全部保留下来,insert into的数据也会一起保留下来。
16.hive内外部表的区别
1.未被external修饰的是内部表,被external修饰的为外部表。
2.内部表数据由Hive自身管理,外部表数据由HDFS管理。
3.内部表数据存储在hive.metastore.warehouse.dir,外部表数据存储位置由用户自己决定。
4.删除内部表会直接删除元数据及存储数据,删除外部表仅仅删除元数据,HDFS上的文件不会被删除。
5.对内部表的修改会直接同步到元数据,而对外部表的表结构和分区进行修改,则需要修改【MSCK REPAIR TABLE table_name】。
什么时候用内部表,什么时候用外部表?
- 保存日志信息或者数据的埋点信息的时候,使用外部表;
- 保存sql语句的计算结果的时候,使用内部表;
- 其他的业务数据,可以用外部表也可以用内部表,没有具体限制。
分区表:
分区是以文件夹的方式而存在的,在表格中这个分区字段会变成一个虚拟的列,可以直接被用来查询。
目的:分区可以加快表格查询的速度,因为将数据按不同类型分开保存,搜索的时候可以减少检索的数据量;在做表格数据抽取的时候,需要分区管理数据,因为在hive中无法update和delete数据,所以需要通过直接删除分区的方式删除数据。
静态分区和动态分区的区别是什么?
静态分区的分区值是自己设置的,动态分区的分区值是通过select查询出来的某个列的值,动态分区需要打开动态分区的开关和打开nostrict非严格模式的开关,效率比静态分区要低。
静态可以通过load data和insert overwrite的方式添加数据,动态只能通过insert overwrite添加。
外部分区表的添加和创建:
- 在hdfs系统里面,已经存在了一个日志的文件夹,里面根据每一天的数据,已经创建好了每天的文件夹,先设置外部表对应文件夹的结构
分区的目的:
更好的细化和管理表格的数据,例如每一天数据都用一个分区的文件夹进行管理;
查询分区字段的时候,可以有效的提高查询效率,因为查询的数据量变少了。
hive数据库中的分桶表:cluster
使用hive数据库中的哈希hash算法,将不同的数据,按照算法的结果保存在不同的文件中。
创建一个分桶表:
create table 表名(
列名 数据类型
)
clustered by (表中已经存在的字段名) into 数量 buckets
row format delimited fields terminated by ‘,’;
如果这个列经常要用来做表连接,就设置成分桶的列,两个做表连接的表格,都需要用id来连接,a.id=b.id,那么就给a表和b表做成分桶表,来增加表连接的速度,因为分桶可以减少表连接的笛卡尔积数量。
-
使用insert复制表格的内容到分桶表中,复制的同时进行数据的分桶,cluster by (id)默认是按照id升序排序的
insert overwrite table stu_info_c
select * from stu_info_c_tmp cluster by (id); -
尝试换一种方法,让id从大到小的进行分桶和排序,distribute by id 按照id分桶,sort by id desc 对id进行降序排序
insert overwrite table stu_info_c
select * from stu_info_c_tmp distribute by id sort by id desc;
4个by的区别
1)Order By:全局排序,只有一个Reducer;
2)Sort By:分区内有序;
3)Distrbute By:类似MR中Partition,进行分区,结合sort by使用。distribute by的分区规则是根据分区字段的hash码与reduce的个数进行相除后,余数相同的分到一个区。
Hive要求distribute by语句要写在sort by语句之前
4) Cluster By:当Distribute by和Sorts by字段相同时,可以使用Cluster by方式。Cluster by除了具有Distribute by的功能外还兼具Sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
在生产环境中Order By用的比较少,容易导致OOM。
在生产环境中Sort By + Distrbute By用的多。
distribute by id sort by id asc 等于 cluster by id
order by 和sort by 它们的区别?**
它们都可以用来对列进行排序,但是sort by可以用在分桶中,order by不能用在分桶中。
分桶使用的场景:
分桶在表连接的时候,才会用到,可以加快两张表联合查询的速度,只有当联合表格的分桶数量相等,或者分桶数量是倍数关系的时候,才有加速的效果。
为什么分桶可以让表连接加速?
因为分桶可以让表连接的笛卡尔积数据量变少。
分区和分桶有什么区别?***
分区使用的是表中不存在的新字段,分桶是使用表中已有的字段;
分区是自己指定的规则(分区字段=分区值),分桶是根据Hash算法分配;
分区是建立的文件夹,在文件夹中保存数据,分桶是直接拆分表格为多个小文件;
分区是对分区字段查询的时候加速,分桶只有表连接的时候加速。
如果现在,做数据的增量抽取,如何在重复抽取的过程中,避免出现重复的数据?
增量抽取的数据,会放在每天的分区里面中,然后通过删除今天的分区达到避免重复数据出现的效果。
如何删除分区呢?
alter table 表名 drop partition(分区字段=’分区值‘);
load data inpath ‘路径’ into table 库名.表名 partition(分区字段=分区值);
insert overwrite table 表名 partition(分区字段=分区值) select * from 另一个表名;
如果某个数据有问题,如果更新这个数据?
-get 这个文件,修改文件本身,删除hdfs原文件,在-put上传上去
1、**下载文件:
hadoop fs -get hdfs文件名字
hadoop fs -get /a.txt 将hdfs上面的根目录中的a.txt下载到linux本地当前文件夹中
2、删除东西:
hadoop fs -rm -r 文件夹或者文件的位置和名字
**3、上传文件:
hadoop fs -put linux上面的文件位置和名字 hdfs的位置
hadoop fs -put a.txt / 将本地的a.txt上传到hdfs的根目录
4、加载数据到数据库的表,
load data inpath ‘路径’ into table 库名.表名 partition(分区字段=分区值);
聚合函数sum count max min avg,常用的数字函数abs round floor ceil(不能用trunc)、字符串函数concat substr length upper lower initcap、日期函数last_day months_between add_months、分析函数 over(partition by 分组 order by 排序)、排名函数(rank dense_rank row_number)、平移函数(lag lead)都是一样的,空值判断(nvl)2 collect_list()函数有序不去重
2.3 collect_set()无序去重;⾏转列:使⽤concat_ws()函数就可以实现,
列转⾏:爆炸函数explode()和侧视图lateral view ⼀起使⽤:lateral view explode()
hive 优化
5)合理设置Map数
mapred.min.split.size: 指的是数据的最小分割单元大小;min的默认值是1B
mapred.max.split.size: 指的是数据的最大分割单元大小;max的默认值是256MB
通过调整max可以起到调整map数的作用,减小max可以增加map数,增大max可以减少map数。
需要提醒的是,直接调整mapred.map.tasks这个参数是没有效果的。
https://www.cnblogs.com/swordfall/p/11037539.html
6)合理设置Reduce数
Reduce个数并不是越多越好
(1)过多的启动和初始化Reduce也会消耗时间和资源;
(2)另外,有多少个Reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
在设置Reduce个数的时候也需要考虑这两个原则:处理大数据量利用合适的Reduce数;使单个Reduce任务处理数据量大小要合适;
1.列裁剪:
2.分区裁剪:
在查询的过程中减少不必要的分区,即尽量指定分区
5.善用union all:
不同表的union all相当于multi inputs,同一表的union all相当于map一次输出多条
6.避免笛卡尔积:关联的时候一定要写关联条件
7.join前过滤掉不需要的数据
8.小表放前大表放后
位于join操作符左边的表会先被加载到内存
3.10 笛卡尔积
Join的时候不加on条件,或者无效的on条件,因为找不到 Join key,Hive 只能使用1个 Reducer 来完成笛卡尔积。当 Hive 设定为严格模式(hive.mapred.mode=strict,nonstrict)时,不允许在 HQL 语句中出现笛卡尔积
hive数据库的数据倾斜:****
表现:在日志中,reduce的百分比卡在了99%的位置不动了,可能几分钟可以跑完的数据,半个多小时了还没结束。大部分需要计算的数据量集中在少部分运行的机器上。
- 大表和小表进行表连接的时候
第一种方法:拆分大表
例如a表有1000万数据,b表只有200万,那么可以:
select * from
(select * from a limit 5000000) a1 join b on a1.id=b.id
unoin all
select * from
(select * from a limit 5000000,5000000) a2 join b on a2.id=b.id;
第二种方法:使用mapjoin优化器 select /*+ mapjoin(表名) /
1.先打开mapjoin表连接的开关
set hive.auto.convert.join=true;
2.使用优化器进行表连接 mapjoin(小表名)
select /+ mapjoin(b) / from a join b on a.id=b.id;
将小的表格的所有数据,通过mapjoin优化器,全部读取到内存中,然后用大表的数据去匹配内存中的小表数据,达到查询加速的效果。
-
表格中有大量空值(特别是在字符串的列上)的时候
使用字符串+随机值对空值进行填充
nvl(列名,concat(‘rand’,cast(rand()*10000000 as int))) -
不合理的sql语句,在hive里面,尽量的不要使用distinct,使用group by进行去重
例如count(distinct 列名)
去重统计使用:select count(列名) from (select 列名 from 表名 group by 列名) a; -
使用一些常见的开关来优化
当数据量比较小的时候,使用本地模式进行运算(当计算的数据量超过20M(20万行左右)以后,就不要用了):
set hive.exec.mode.local.auto=true;
分组聚合计算的优化:
set hive.map.aggr=true;
负载均衡的优化:
set hive.groupby.skewindata=true;
内部表和外部表的区别?
动态分区和静态分区的区别?
分区和分桶的区别?
怎么进行数据的抽取?
数据倾斜的表现是什么?
发生了数据倾斜,怎么办?
小文件过多的优化:
小文件从哪里来的?
分区分桶会得到很多的小文件;
数据源本身就有很多小文件;
reduce数量过多的时候。
小文件过多的时候,为什么会影响到服务器性能?
影响:
每一个文件,都需要一个jvm的进程去处理和执行,会造成资源的浪费,影响执行的效率;
hdfs存储过多小文件,会造成硬盘资源的浪费。
怎么调整和优化?
1.不要使用textfile存储数据
2.通过开关来调节:
控制每个map端拆分数据的最大值大小:
set mapred.max.split.size=xxx;
控制每一个处理数据节点的处理数据大小:
set mapred.min.split.size.per.node=xxx;
设置的合并的map端输出的数据:
set hive.merge.mapfiles=true;
设置的合并的reduce端输出的数据:
set hive.merge.mapredfiles=true;
设置合并后的数据的大小:
set hive.merge.size.per.task=xxx;
需要被合并的文件大小:
set hive.merge.smallfiles.avgsize=xxx;
怎么解决
(1)采用har归档方式,将小文件归档
(2)采用CombineTextInputFormat
(3)有小文件场景开启JVM重用;如果没有小文件,不要开启JVM重用,因为会一直占用使用到的task卡槽,直到任务完成才释放。
JVM重用可以使得JVM实例在同一个job中重新使用N次,N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间
Udf udaf udtf的区别
1、UDF:用户定义(普通)函数,只对单行数值产生作用;
继承UDF类,添加方法 evaluate()
2、UDAF:User- Defined Aggregation Funcation;用户定义聚合函数,可对多行数据产生作用;等同与SQL中常用的SUM(),AVG(),也是聚合函数;
另一种涉及两个类:AbstractGenericUDAFResolver、GenericUDAFEvaluator;
继承UDAFResolver类,重写 getEvaluator() 方法;
继承GenericUDAFEvaluator类,生成实例给getEvaluator();
在GenericUDAFEvaluator类中,重写init()、iterate()、terminatePartial()、merge()、terminate()方法;
3、UDTF:User-Defined Table-Generating Functions,用户定义表生成函数,用来解决输入一行输出多行;
继承GenericUDTF类,重写initialize(返回输出行信息:列个数,类型), process, close三方法;
hive怎么解析SQL
将sgL转换为抽象语法树AST tree,然后遍历 ASTtree,查询 queryBlock然后遍历 queryBlock,翻译成执行操作树,然后逻辑层优化器进行操作树优化,减少 shuffle 数据量,然后遍历操作树,翻译成mgpReduce ,任务。然后物理层优化器进行,mapreduce 任务的转化,生成最终计划
在Hive中,有以下几种常见的Join方式:
Map Join:在Hive中,当一个小表能够全部存放在内存的时候,可以使用Map Join来实现关联操作。这种方式会将小表加载到内存中,并构建一个哈希表,然后通过Map阶段将大表数据和小表哈希表进行连接获取结果。使用Map Join可以大幅减少关联过程中的磁盘IO,提高查询性能。
Broadcast Join:当一个小表无法完全放入内存中时,但是小表相对于大表仍然较小,可以采用Broadcast Join。在这种方式下,会将小表的数据复制到每个计算节点上,然后通过Map阶段将大表数据和小表数据进行关联操作。
Sort Merge Join:当两个表的大小都较大无法全部放入内存,并且两个表都已经按照Join键进行排序时,可以使用Sort Merge Join。在这种方式下,需要先对两个表按照Join键进行排序,然后通过归并的方式将两个表进行关联操作。
Bucket Join:当两个表都已经以相同的Join键进行分桶存储时,可以使用Bucket Join。在这种方式下,Hive可以将相同桶号的数据对应的分片进行关联操作,从而提高查询效率。
以上是Hive中常用的几种Join方式,选择合适的Join方式可以根据数据集大小、内存大小以及数据分布情况等因素来进行判断和选择
表格文件保存的几种常见的格式:
5. text:hive默认的表格保存格式,可以通过load data来加载数据
行存储的方式进行数据存储,占用空间,并且读取速度比较慢
6. sequence:序列格式,占用的空间比text实际要大
也是行存储的方式,使用key value键值对的方式存储数据。
7. rc:
facebook创建的一种文件存储格式,列存储的方式。使用懒加载存储和管理数据(对每一行的数据单独的进行数据压缩,如果要读取,只读对应的数据,只解压对应的数据),查询速度比较快。
- orc:
列存储的方式,是rc的优化版,同样有懒加载的特点,优化在文件的压缩和存储上,orc是项目组中使用最多的文件存储格式
1. Hive的3种执行引擎适用场景
● Hive底层的计算由分布式计算框架实现,目前支持三种计算引擎,分别是MapReduce、Tez、 Spark
1.6.11 Tez引擎优点?
Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
Mr/tez/spark区别:
Mr引擎:多job串联,基于磁盘,落盘的地方比较多。虽然慢,但一定能跑出结果。一般处理,周、月、年指标。
Spark引擎:虽然在Shuffle过程中也落盘,但是并不是所有算子都需要Shuffle,尤其是多算子过程,中间过程不落盘 DAG有向无环图。 兼顾了可靠性和效率。一般处理天指标。
Tez引擎:完全基于内存。 注意:如果数据量特别大,慎重使用。容易OOM。一般用于快速出结果,数据量比较小的场景。
Hadoop相关
SecondaryNameNode 辅助的名称节点:
收集整个平台,所有的机器的运行状态,将运行的状态传递给NameNode
NameNode 名称节点
负责沟通和客户端之前的通信
DataNode 数据节点
负责存储数据
HDFS 读写的过程中,namenode 参与数据传输吗? (1分)
参考答案:不参与数据传输
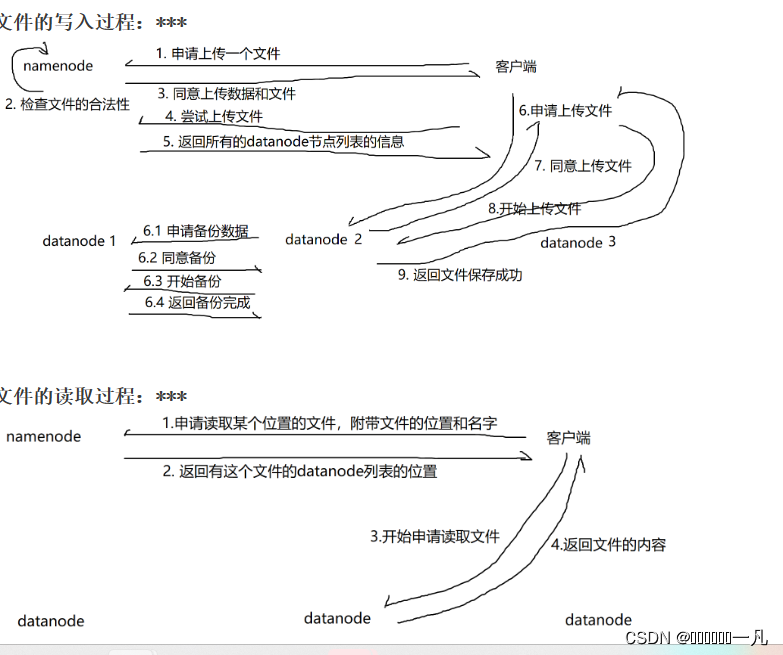
HDFS 在读取文件的时候,如果其中一个块突然损坏了怎么办
客户端读取完 DataNode 上的块之后会进行 checksum 验证,也就是把客户端读取到本地的块与 HDFS 上的原始块进行校验,如果发现校验结果不一致,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的 DataNode 继续读。
. HDFS 在上传文件的时候,如果其中一个 DataNode 突然挂掉了怎么办
客户端上传文件时与 DataNode 建立 pipeline 管道,管道的正方向是客户端向DataNode 发送的数据包,管道反向是 DataNode 向客户端发送 ack 确认,也就是正确接收到数据包之后发送一个已确认接收到的应答。当 DataNode 突然挂掉了,客户端接收不到这个 DataNode 发送的 ack 确认,客户端会通知 NameNode,NameNode 检查该块的副本与规定的不符,nameNode 会通知 DataNode 去复制副本,并将挂掉的 DataNode 作下线处理,不再让它参与文件上传与下载
MapReduce计算引擎: hive on mr大数据的分布式计算引擎数据的计算,分成了map 和 reduce两个部分:
假如现在要去计算一个sql语句:select deptno,sum(sal) from emp group by deptno;
- 将emp表的数据,拆分成N份,分别给到不同的机器(map端)
- 每个不同的机器,单独的对自己的数据进行分组计算(reduce端)
- 每个机器都计算完成之后,再进行数据的汇总(reduce端)(hash)
Mr的shuffle过程
在大数据处理中,"shuffle"是指将数据重新分区和重新排序的过程。这个过程通常发生在MapReduce等分布式计算框架中,用于将数据从一个节点传输到另一个节点,以便进行后续的计算或处理。
下面是一个简单的描述Mr的shuffle过程的步骤:
在MapReduce中,shuffle是指将Map阶段的输出数据按照键进行分区、排序和传输到Reduce节点的过程。具体步骤如下:
Map阶段:将输入数据划分为若干个数据块,每个数据块由一个Map任务处理。Map任务将输入数据转换为键值对,并将键值对写入本地磁盘。
Partition阶段:将Map任务的输出数据按照键进行分区,每个分区对应一个Reduce任务。分区的数量通常与Reduce任务的数量相同。
Sort阶段:在每个分区内,对键值对进行排序,以便后续的合并操作。
Combine阶段:将相同键的键值对进行合并,减少数据传输量。
Shuffle阶段:将每个分区的数据发送到对应的Reduce节点,以便进行后续的Reduce操作
为了优化Shuffle过程,可以考虑以下几点:
压缩(Compression):在传输中间文件时,可以使用压缩算法减少数据的传输量,从而减少网络带宽的使用。
合并(Combining):在Map任务的本地磁盘上进行合并操作,减少中间结果的数量,从而减少传输的数据量。
路由(Routing):根据Reduce任务的位置和负载情况,将中间结果直接发送给最终的Reduce任务,减少数据的传输距离。
本地化(Localization):将Reduce任务调度到与Map任务所在节点相同的节点上,以减少数据的传输。
内存管理(Memory Management):合理管理内存资源,避免过多的磁盘IO操作,提高性能。
这些优化策略可以根据具体的应用场景和系统配置进行选择和调整,以提高MapReduce的性能和效率
mr的shuffle过程有几种
在MapReduce中,Shuffle过程主要完成数据的分区和排序,使得相同键的数据被发送到同一个Reducer进行处理。在Shuffle过程中,有以下几种常见的方式:
Sort-based Shuffle:这是最常用的Shuffle方式。它的工作原理是,首先在Map阶段将输出的键值对按照键进行排序,然后将排序后的数据按照Reducer的数量进行分区,每个分区对应一个Reducer。在Reducer阶段,每个Reducer会接收到一个或多个分区的数据,并再次按照键进行排序,以便进行后续的数据处理。
Hash-based Shuffle:这种Shuffle方式将键值对根据键的哈希值进行分区。在Map阶段,每个键值对会根据哈希函数计算出一个分区编号,然后将数据发送给对应的Reducer进行处理。在Reducer阶段,只需要对接收到的数据进行排序即可。
Grouping Shuffle:这种Shuffle方式是在Sort-based Shuffle的基础上进行的改进,用于对具有相同键的数据进行分组。在Map阶段,除了按键排序之外,还会根据键分组,将相同键的数据放在一起。在Reducer阶段,每个Reducer接收到的数据已经按照键排序并分组,方便进行后续的聚合操作。
在实际使用中,Sort-based Shuffle是最常用的方式,因为它在处理大规模数据时具有较好的性能和扩展性。而Hash-based Shuffle主要适用于数据量较小且键分布均匀的情况。Grouping Shuffle则使用于需要对相同键的数据进行聚合操作的场景。根据具体的需求和数据特点,选择合适的Shuffle方式可以提高MapReduce的性能和效率。
yarn
Yarn是一种用于管理和调度大规模分布式计算的工具。它的工作机制可以概括为以下几个步骤:
-
用户提交应用程序:用户通过Yarn客户端提交应用程序,包括应用程序的名称、代码和依赖项等信息。
-
ResourceManager分配资源:Yarn的ResourceManager负责管理整个集群的资源,并将可用的资源分配给应用程序。
-
ApplicationMaster启动:一旦资源分配完成,Yarn会为应用程序启动一个ApplicationMaster。ApplicationMaster是应用程序特定的主管程序,负责和ResourceManager通信,并协调应用程序的执行。
-
Container分配:ApplicationMaster向ResourceManager请求分配容器。Container是一个虚拟的计算资源单位,它包含了一定的内存、CPU和磁盘资源。
-
任务执行:一旦Container分配到应用程序,ApplicationMaster会启动相应的任务(如MapReduce任务或Spark任务)来在容器中执行。
-
监控和容错:Yarn会监控任务的执行情况,并在需要时重新分配失败的任务或容器。
-
应用程序完成:当应用程序的所有任务都执行完毕时,ApplicationMaster会通知ResourceManager释放资源。
总的来说,Yarn的工作机制就是通过ResourceManager分配和管理集群资源,通过ApplicationMaster协调应用程序的执行,并通过Container将任务在集群中的节点上执行。通过这种机制,Yarn实现了高效的资源管理和任务调度。
1.2.11 Yarn调度器
1)Hadoop调度器重要分为三类:
FIFO 、Capacity Scheduler(容量调度器)和Fair Sceduler(公平调度器)。
Apache默认的资源调度器是容量调度器;
CDH默认的资源调度器是公平调度器。
2)区别:
FIFO调度器:支持单队列 、先进先出 生产环境不会用。
容量调度器:支持多队列。队列资源分配,优先选择资源占用率最低的队列分配资源;作业资源分配,按照作业的优先级和提交时间顺序分配资源;容器资源分配,本地原则(同一节点/同一机架/不同节点不同机架)
公平调度器:支持多队列,保证每个任务公平享有队列资源。资源不够时可以按照缺额分配。
sqoop 相关
Sqoop使用Hadoop的MapReduce作业来传输数据。其中,Map阶段负责将数据从关系型数据库读取到Hadoop的分布式文件系统(HDFS)中,Reduce阶段负责将数据写入目标存储位置(例如,Hive表)
1.7.2 Sqoop导入导出Null存储一致性问题
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用–input-null-string和–input-null-non-string两个参数。导入数据时采用–null-string和–null-non-string。
1.7.5 Sqoop一天导入多少数据
100万日活=》10万订单,1人10条,每天1g左右业务数据
Sqoop每天将1G的数据量导入到数仓。
1.7.6 Sqoop数据导出的时候一次执行多长时间
每天晚上00:10开始执行,Sqoop任务一般情况20-30分钟的都有。取决于数据量(11.11,6.18等活动在1个小时左右)。
1.7.7 Sqoop在导入数据的时候数据倾斜
Sqoop参数撇嘴: split-by:按照自增主键来切分表的工作单元。
num-mappers:启动N个map来并行导入数据,默认4个;
1.7.8 Sqoop数据导出Parquet(项目中遇到的问题)
Ads层数据用Sqoop往MySql中导入数据的时候,如果用了orc(Parquet)不能导入,需转化成text格式
(1)创建临时表,把Parquet中表数据导入到临时表,把临时表导出到目标表用于可视化
(2)ads层建表的时候就不要建Parquet表
YARN 是hadoop 的集群资源管理器,是为了要改善MapReduce1 的实现,但它具有足够的通用性,同样也支持其他的分布式计算模式
YARN 的基本思想就是将JobTracker 的两大主要职能:资源管理、作业的调度监控分为两个独立的进程。一个是全局的ResourceManager,另一个是每一个应用对应的ApplicationMaster
资源管理:YARN负责对集群中的资源进行管理,包括CPU、内存、磁盘空间等。它将整个集群的资源划分为多个容器,将资源分配给不同的应用程序。
作业调度:YARN通过调度器进行作业调度,根据应用程序的需求和优先级,动态地将资源分配给不同的应用程序。
进程隔离:YARN通过容器(Container)的概念实现了应用程序之间的进程隔离。每个应用程序运行在独立的容器中,互不干扰,提高了集群的资源利用率和安全性。
状态监控和容错:YARN提供了对应用程序的状态监控和容错机制,可以在应用程序失败时重新启动或迁移应用程序。
扩展性和可伸缩性:YARN的架构设计具有高度的扩展性和可伸缩性,它支持在一个集群中运行大规模的应用程序,并可以根据需求动态地扩展集群的规模。
2.shuffle中环形缓存使用的排序算法(快速排序与并归排序)
-
map shuffle也称为shuffle writer, 每个map 处理分配的split, 然后写入到环形缓冲区中,当缓冲区中的数据达到 一定比率,就会开启线程将缓冲区中的数据写入文件,称为spill, spill 同时会对数据进行分区、排序、合并操作,然后写入到文件,这是一个边写缓冲区,边spill的过程,中间可能会产生多个文件,只到map 读取数据完毕会将spill 的所有小文件进行分区、排序、合并成为最终一个数据文件一个索引文件。
-
reduce shuffle 也称为shuffle reader, 待map阶段执行完成,每个reducer开启若干线程 从所有的map阶段输出的索引文件与数据文件获取对应的分区数据,若内存足够则存放在内存中,否则输出到磁盘,在这个过程中还会同时对内存、 磁盘数据进行合并(merge)、排序,最终形成一个有序的大文件,提供给reduce执行。
在shuffle writer 与shuffle reader阶段都发生按照数据的key进行排序,spill 过程对内存缓冲区的数据进行快速排序,map最终合并小文件
并归排序,shuffle reader 拉取map端的数据并归排序。
用到两种排序算法:快速排序与并归排序
6.spark和mr的区别
MR是基于进程,spark是基于线程
spark把运算的中间数据存放在内存,迭代计算效率更高;MR的中间结果需要落地,需要保存到磁盘,这样必然会有磁盘IO操作,影响性能
容错性
spark容错性高,它通过弹性分布式数据集RDD来实现高效容错,RDD是一组分布式的存储在节点内存中的只读性质的数据集,这些集合石弹性的,某一部分丢失或者出错,可以通过整个数据集的计算流程的血缘关系来实现重建;MR的话容错可能只能重新计算了,成本较高
适用面
spark更加通用,spark提供了transformation和action这两大类的多个功能的api,另外还有流式处理sparkstreaming模块,图计算GraphX等;MR只提供了map和reduce两种操作,流计算以及其他模块的支持比较缺乏
框架和生态
Spark框架和生态更为复杂,首先由RDD、血缘lineage、执行时的有向无环图DAG、stage划分等等,
很多时候spark作业都需要根据不同的业务场景的需要进行调优,以达到性能要求,MR框架及其生态相对较为简单,对性能的要求也相对较弱,但是运行较为稳定,适合长期后台运行
运行环境:
MR运行在YARN上,
spark
local:本地运行
standalone:使用Spark自带的资源管理框架,运行spark的应用
yarn:将spark应用类似mr一样,提交到yarn上运行
mesos:类似yarn的一种资源管理框架
// 同一个sql允许并行任务的最大线程数
set hive.exec.parallel.thread.number=8;
//存储临时Hive统计信息的方式
set hive.stats.dbclass=counter;
HiveSQL控制map数和reduce数
1、若读取小文件较多,则设置在map端进行小文件合并参数
2、配置MR任务结束后进行文件合并
动态分区无Reduce产生小文件处理
在设置动态分区后,产生的文件数会取决于map数和分区数的大小,假设动态分区初始有N个map数,同时生成M个分区,则中间会生成N*M个文件,通常这种情况就是让大部分数据尽量输出到一个reduce中进行处理,但是有些HiveSql不会产生reduce,也就是说文件最后没有进行合并处理,这种情况下可以用distribute by rand()的方式保证数据进行一次reduce操作,实现文件的合并。
两种处理方式参数设置如下:
1、 设置reduce个数
set mapred.reduce.tasks=50;
备注:set设置的参数是生成的文件个数,distribute by rand()保证数据随机分配到50个文件中。
2、设置每个reducer处理的数据
set hive.exec.reducers.bytes.per.reducer=5120000000;
备注:set设置的参数是生成的文件大小,distribute by rand()保证数据的平均大小是512Mb。
Reduce数设置
在设置reduce数时,一定要遵循以下公式:
reduce数 * 分区数 < 6W
reduce数=60000 / 分区数
//设置reduce数
set hive.exec.reducers.max = reduce数
8.如何解决spark生成的小文件问题
使用mr对于表数据重新插入表中;
spark执行sql中添加coalesce(10);
9.rank,defense_rank,row_number 的区别
rank 允许并列排名,row_number不允许并列排名,两者均为跳跃排序;
defense_rank不为跳跃排序,且存在并列排名;
10.hive sql优化
优化的根本思想:
尽早尽量过滤数据,减少每个阶段的数据量
减少job数
解决数据倾斜问题
尽早尽量过滤数据,减少每个阶段的数据量
LEFT SEMI JOIN是IN和EXISTS的一种高效实现,在hive0.13之前是不支持IN和EXISTS的
LEFT SEMI JOIN产生的数据不会重复。
11.使用动态分区
12.union all优化
hive0.13之前不支持union all直接放外层,必须外层套一个查询,例如:
是不支持的。
hive对union all的优化只局限于非嵌套查询。
不同表太多的union all,不推荐使用。可以写在中间表的不同分区里,然后再进行union all
13.尽量避免使用distinct
尽量避免使用distinct进行重排,特别是大表,容易产生数据倾斜(key一样在一个reduce处理)。使用group by替代
select distinct key from a
select key from a group by key
14.排序优化
只有order by产生的结果是全局有序的,可以根据实际场景进行选择排序
order by实现全局排序,一个reduce实现,由于不能并发执行,所以效率低
sort by实现部分有序,单个reduce的输出结果是有序的,效率高,通常与distribute by一起使用(distribute by 关键词可以指定map到reduce的key分发)
cluster by col1等价于distribute by col1 sort by col1,但不能指定排序规则
15.使用explain dependency查看sql实际扫描多少分区
11.sqoop 增量更新数据设置;-m参数的作用
1.append方式 2.lastmodified方式,必须要加–append(追加)或者–merge-key(合并,一般填主键)
执行sqoop命令 (–incremental lastmodified --incremental lastmodified --append的作用:把大于last-value时间的数据都导入进来,之前就存在但是后期修改过的数据并不会进行合并,只会当做新增的数据加进来,所以使用–incremental lastmodified --append有可能导致数据重复的问题
–incremental lastmodified --merge-key的作用:修改过的数据和新增的数据(前提是满足last-value的条件)都会导入进来,并且重复的数据(不需要满足last-value的条件)都会进行合并
;
设置mapper数;
sqoop工具:
以命令行的方式,进行表格的全量和增量的抽取,在不同的数据库的表和表之间进行数据的抽取和数据的迁移。
查看对应的数据库中,所有的表名:
sqoop list-tables --connect jdbc:oracle:thin:@192.168.2.153:1521/ORCL
–username zx
–password 111222
数据的全量抽取:其他数据库到hive不需要先创建表格,hive会自动创建表格
sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.2.153:1521/ORCL
–username zx
–password 111222
–table EMP
–hive-database bigdata
–fields-terminated-by ‘,’
-m 1
-m 1的选项,是当被抽取的表格没有主键的时候添加的选项,如果有主键就不要这一句
数据抽取的时候,相同的表格,只能被抽取一次
hive导出数据到oracle:需要先在oracle中建表
sqoop export
指定要导入到Oracle的那张表(通常与hive中的表同名)
–table TABLE_NAME
host_ip:导入oracle库所在的ip:导入的数据库
–connect jdbc:oracle:thin:@HOST_IP:DATABASE_NAME
oracle用户账号
–username USERNAME
oracle用户密码
–password PASSWORD
hive表数据文件在hdfs上的路径
–export-dir /user/hive/warehouse/test.db/TABLE_NAME
指定表的列名,必须指定
–columns 列名1,列名2
列分隔符(根据hive的表结构定义指定分隔符)
–input-fields-terminated-by ‘\001’
行分隔符
–input-lines-terminated-by ‘\n’
如果hive表中存在null字段,则需要添加参数,否则无法导入
–input-null-string ‘\N’
–input-null-non-string ‘\N’
12.insert overwrite 执行时数据为0条,分区是否会被覆盖?
不会
dolphinscheduler 的原理
DolphinScheduler是一个开源的分布式任务调度系统,旨在帮助用户管理和调度大规模的数据处理任务。它的原理可以概括为以下几个方面:
-
架构:DolphinScheduler采用了主从架构,包括Master节点和Worker节点。Master节点负责任务的调度和管理,Worker节点负责执行具体的任务。
-
任务定义:用户可以通过DolphinScheduler的Web界面或API定义任务,任务可以是Shell脚本、Spark作业、Hive作业等。任务可以设置依赖关系,即一个任务的执行依赖于其他任务的完成。
-
调度策略:DolphinScheduler支持多种调度策略,包括定时调度、依赖调度和手动触发调度。用户可以根据任务的需求设置不同的调度策略。
-
任务调度:Master节点根据任务的依赖关系和调度策略,将任务分配给可用的Worker节点执行。Master节点会监控任务的执行状态,并记录任务的日志和统计信息。
-
容错和高可用:DolphinScheduler具有容错和高可用的特性。当Master节点发生故障时,系统会自动切换到备用的Master节点,保证系统的可用性。
-
监控和告警:DolphinScheduler提供了监控和告警功能,可以实时监控任务的执行状态和性能指标,并在任务执行失败或超时时发送告警通知。
总的来说,DolphinScheduler通过任务定义、调度策略和任务调度等机制,实现了对大规模数据处理任务的管理和调度。它具有灵活的架构、多样化的任务类型支持以及容错和高可用的特性,使得用户可以方便地管理和调度复杂的数据处理任务。















 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











