







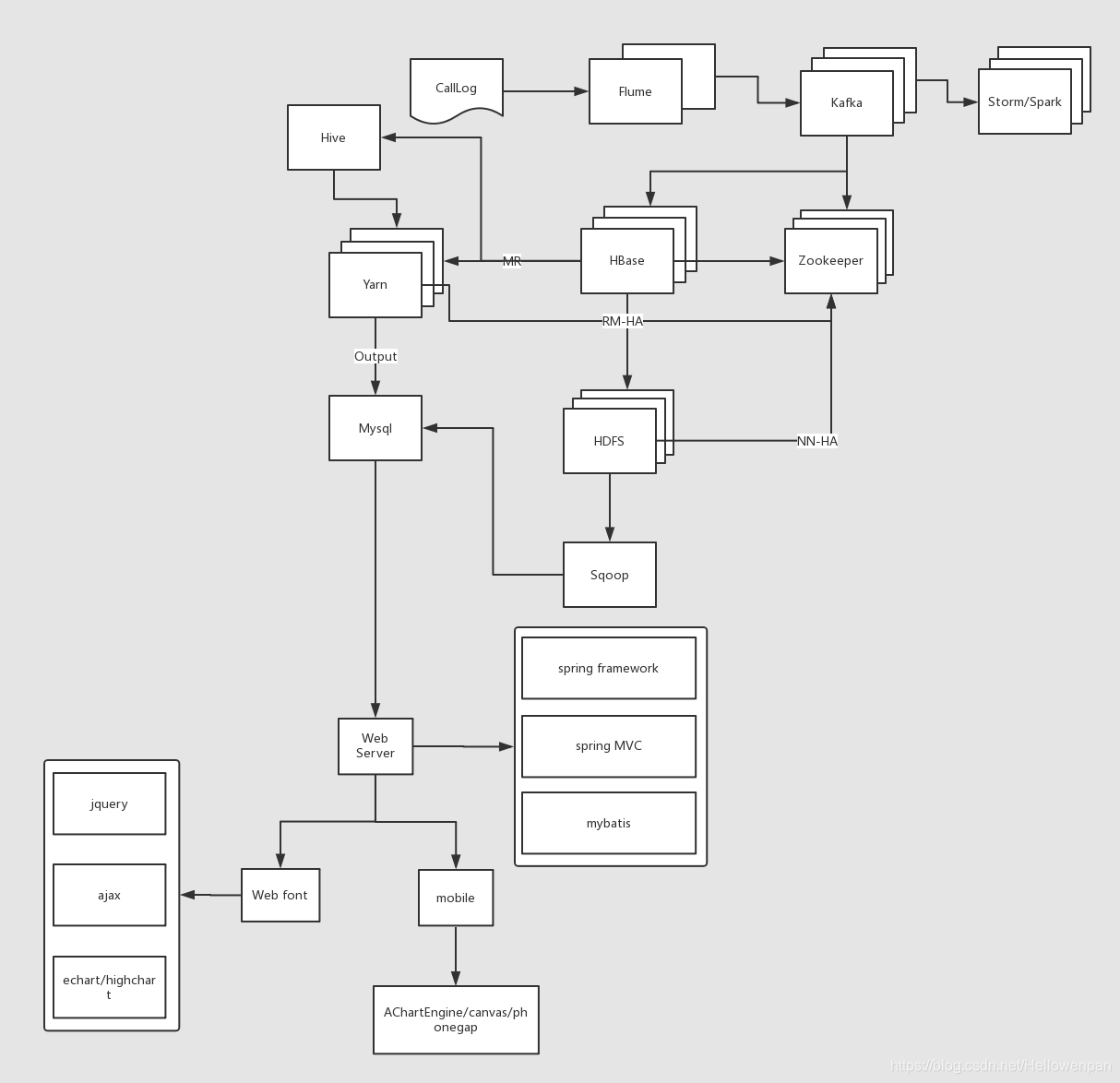
项目大体流程:
- 先由自己写好的生产者程序jar包不停的向call.log文件中生产通话日志,模拟用户通话
- 使用flume监控日志文件call.log,将该日志文件作为flume的source源,通过channel和sink
- 使用kafka创建topic,flume监控得到的数据作为kafka的producer,然后将数据写入到指定的topic中
- 启动一个消费者程序,将topic中的数据进行消费,将消费到的数据按照设计的rowkey写入到HBASE中进行存储
- 通过MapReduce程序,从HBASE中取得所有数据进行数据的分析统计
- 将统计结果写入到MySQL中,最后通过echarts来进行图表展示
一、分区键设计
1.分区是解决数据倾斜的有效手段,分区比较简单, 关键在于需要分多少区,在程序中传入我们要将hbase中的表分成的分区个数,然后在hbase中建表的时候,就按照我们传入的分区个数和自定义的分区键进行分区
分区键格式如下:
00|
00| 01|
01| 02|
02| 03|
..........
07
private byte[][] genSplitkeys( int regionCount){
int splitkeyCount = regionCount - 1; //分区键的个数
/**
*0,1,2,3,4
* 0000111
* 1111000
* 2222999
* (负无穷,0|—), [0|,1|) , [1|,正无穷)
*/
List<byte[]> bsList = new ArrayList<>();
byte[][] bs = new byte[splitkeyCount][];
//构造分区键
for (int i = 0;i < splitkeyCount;i++){
String splitkey = i + "|";
bsList.add(Bytes.toBytes(splitkey));
}
bsList.toArray(bs);
return bs;
}以上方法用户生成在hbase中的分区键。分区键之间为什么要加 “ | ”进行分割呢?其实竖线的值比较大,而rowkey存储在哪个分区是需要按位比较的,而且一般分区是0x_ xxxxxx_bbbb 。。。,使用竖线可以将rowkey拦截在分区内 。
该方法返回byte[][]数组,是因为在建表的时候,进行预分区,需要在表描述器中以字节数组的形式传入分区键。
void createTable(HTableDescriptor var1, byte[][] var2) throws IOException;二、rowkey的设计
在HBASE中rowkey的设计是最为关键的部分,如果rowkey如果设计的不合理,那么很容易造成数据倾斜,使某台服务器的负载加重。rowkey的设计一般遵循三个原则:长度原则,唯一性原则,散列原则
1.长度原则:
最大的值64kb,推荐长度:10 ~ 100byte
最好是8的倍数,能短则短,rowkey太长会影响性能
2.唯一性原则: rowkey应该具备唯一性
3.散列原则:
3-1)盐值散列:不能使用时间戳直接作为rowkey,可以在时间戳作为的rowkey前面增加一个随机数来实现盐值散列
3-2)字符串的反转,比如时间戳不能直接作为rowkey,但是可以将时间戳反转一下作为rowkey。
一般电话号码使用字符串反转较多:135 4811 2164
3-3)计算分区号:hashMap
一般是将要进行分析的所有有用字段都拼接到rowkey中,方便进行MapReduce分析的时候直接取得rowkey进行拆分,然后得到相应的字段。
在本项目中使用的rowkey格式如下:rowkey = regionNum + “_” + call1 + “_”+ calltime + “_” + call2 + “_” + duration+ "_" + flag
regionNum:是通过指定的方法生成的随机的分区数,通过使用电话号码call1和通话时间calltime(仅取年月)进行位运算,然后对分区个数进行求模得到的一个随机数,这样就保证了同一个电话号码的同一个月的数据都保存在同一个分区中,到时候对hbase中的数据进行查询的时候效率会更高效。
flag:是标志位,为了区分是主叫用户还是被叫用户
最终生成的rowkey形式如下:0X_13542584654_20181004120511_15202856822_0054_1
生成分区号:
/**
* 计算分区号(0,1,2)
* 保证同一个电话号码的同一个月的数据都在一个分区中,方便进行查询等操作
* @return
*/
protected static int genRegionNum(String tel,String date){
//13548112164 取后四位
String usercode = tel.substring(tel.length() - 4);
//20180101121200
String yearMonth = date.substring(0,6); //仅截取年和月
int userCodeHash = usercode.hashCode();
int yearMonthHash = yearMonth.hashCode();
//crc校验异或算法
int crc = Math.abs(userCodeHash ^ yearMonthHash);
//取模
int regionNum = crc % ValueConstant.REGION_COUNT;
return regionNum;
}当kafka消费者消费到一条数据的时候,通过消费到的字段,进行拆分然后构建rowkey,最后向hbase中插入一条数据:
/**
* kafka消费者消费到数据后向hbase插入数据
* @param value
*/
public void insertData(String value) throws Exception{
//将通话日志保存到hbase表中
//1.获取通话日志数据
String[] values = value.split("\t");
String call1 = values[0];
String call2 = values[1];
String calltime = values[2];
String duration = values[3];
//rowkey设计使用计算分区号:rowkey = regionNum + call1 + calltime + call2 + duration
String rowkey = genRegionNum(call1,calltime) + "_" + call1 + "_" + calltime + "_" + call2 + "_" +
duration + "_1";
//主叫用户的put
Put put = new Put(Bytes.toBytes(rowkey));
byte[] family = Bytes.toBytes(Names.CF_CALLER.getValue());
put.addColumn(family,Bytes.toBytes("call1"),Bytes.toBytes(call1));
put.addColumn(family,Bytes.toBytes("call2"),Bytes.toBytes(call2));
put.addColumn(family,Bytes.toBytes("calltime"),Bytes.toBytes(calltime));
put.addColumn(family,Bytes.toBytes("duration"),Bytes.toBytes(duration));
put.addColumn(family,Bytes.toBytes("flg"),Bytes.toBytes("1"));
//在想hbase中插入主叫的数据的同时,也需要向hbase表中插入一条被叫的数据,所以就需要两个rowkey和put对象
String calleeRowkey = genRegionNum(call1,calltime) + "_" + call2 + "_" + calltime + "_" +
call1 + "_" + duration + "_0";
//被叫用户的put
Put calleePut = new Put(Bytes.toBytes(calleeRowkey));
byte[] calleeFamily = Bytes.toBytes(Names.CF_CALLER.getValue());
calleePut.addColumn(calleeFamily,Bytes.toBytes("call1"),Bytes.toBytes(call2));
calleePut.addColumn(calleeFamily,Bytes.toBytes("call2"),Bytes.toBytes(call1));
calleePut.addColumn(calleeFamily,Bytes.toBytes("calltime"),Bytes.toBytes(calltime));
calleePut.addColumn(calleeFamily,Bytes.toBytes("duration"),Bytes.toBytes(duration));
calleePut.addColumn(calleeFamily,Bytes.toBytes("flg"),Bytes.toBytes("0"));
// 3.保存数据
List<Put> puts = new ArrayList<>();
puts.add(put);
puts.add(calleePut);
putData(Names.TABLE.getValue(),puts); //往表中插入数据
}














 490
490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









