






目录
一.爬虫介绍
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
1.1 我们为什么要使用爬虫呢?
我们生活在一个大数据时代,对于自己想了解的东西可以就行查阅相关资料可得,那么最简单的途径就是询问“度娘”,而我们将面临着,搜索出的结果数量庞大,不知如何统计,什么信息才是有用的,什么信息可以影响我们的决策,那么这个时候,就可以引进爬虫,来帮助我们,辅助我们进行分析,这就是使用爬虫的根本目的
具体讲解可点击该链接来学习:爬虫知识点讲解
二.爬虫项目讲解
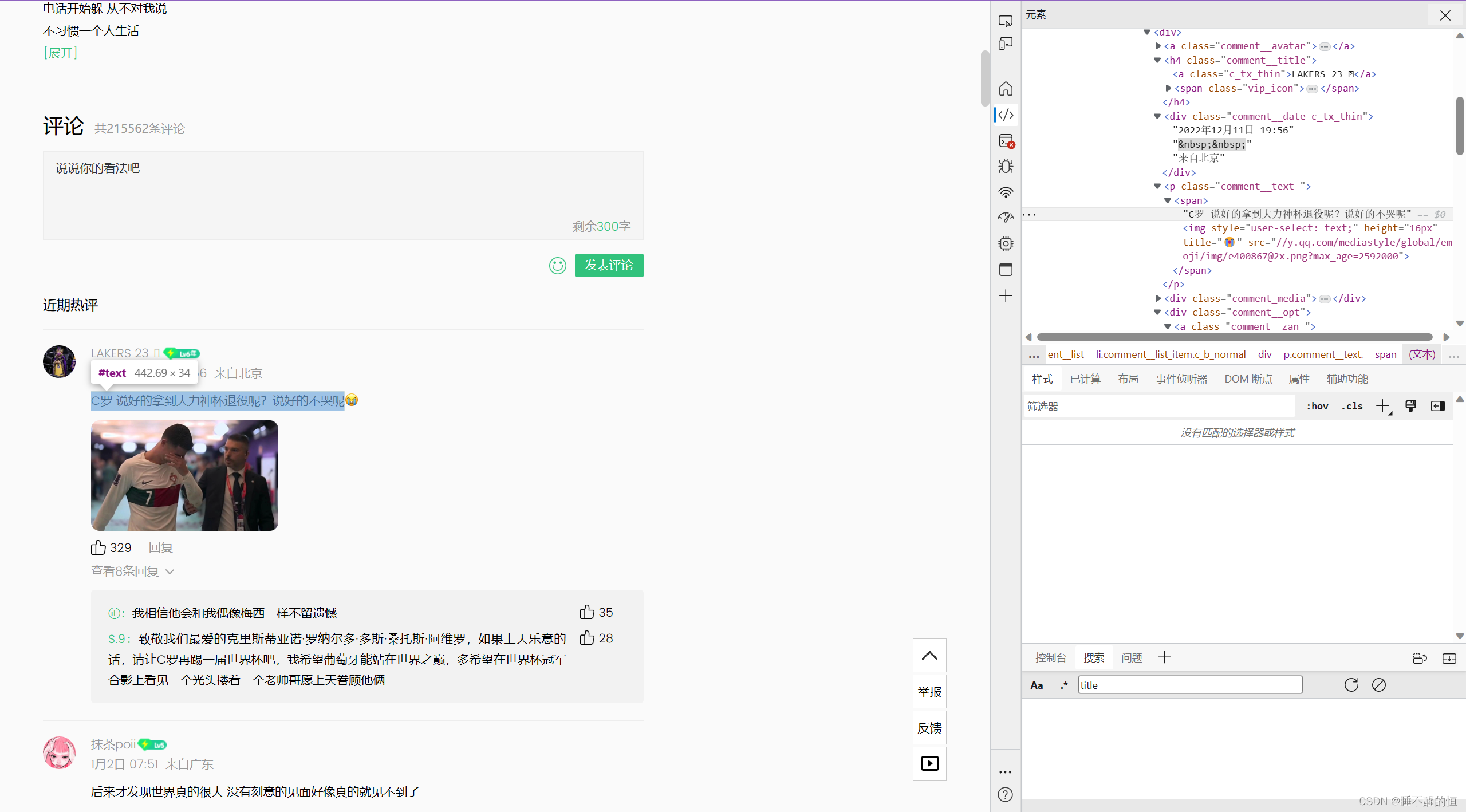
今天,我们将爬取《说好不哭》的评论信息 。首先我们看一下开发者界面(F12进入):
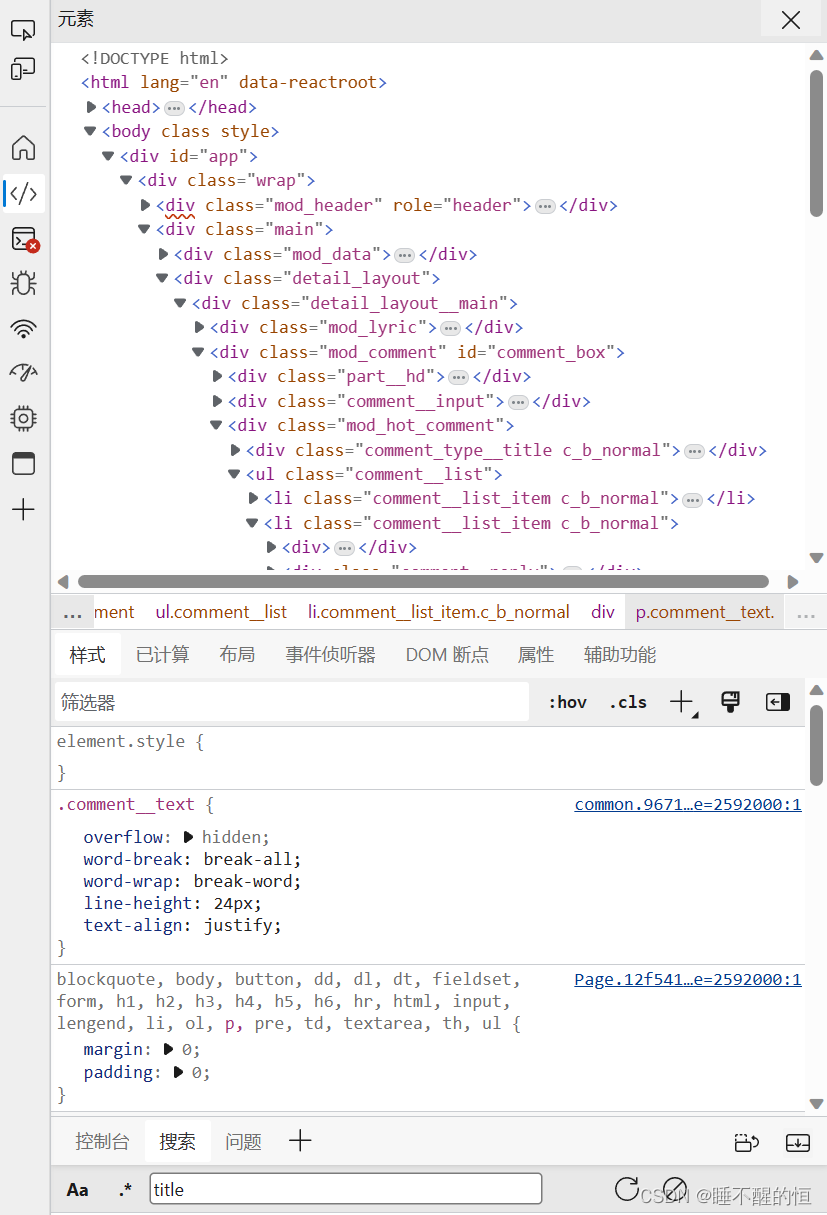
找到 发表评论的作者姓名——发表时间——点赞数——评论内容
1. 作者姓名
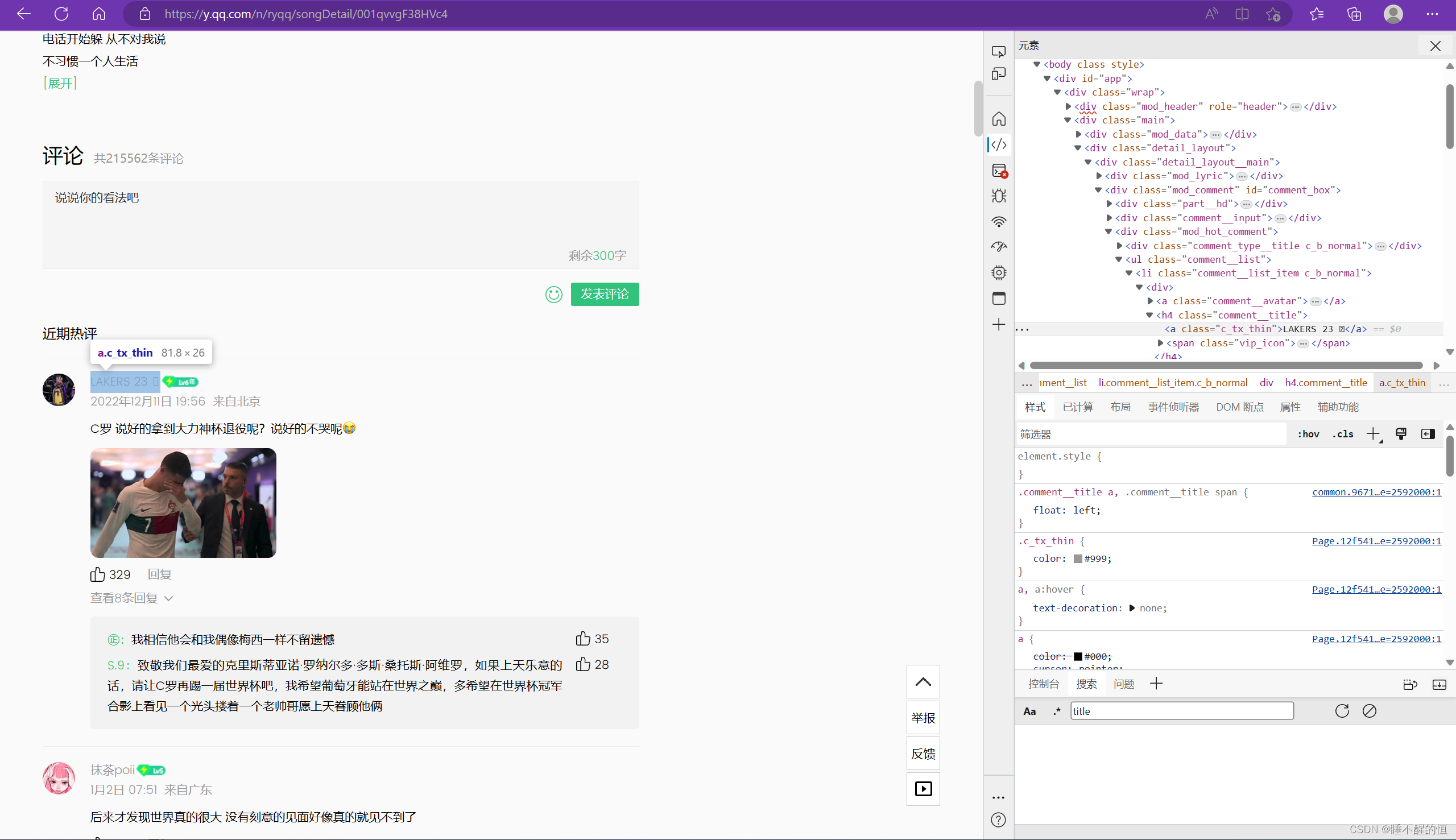
2. 发表时间
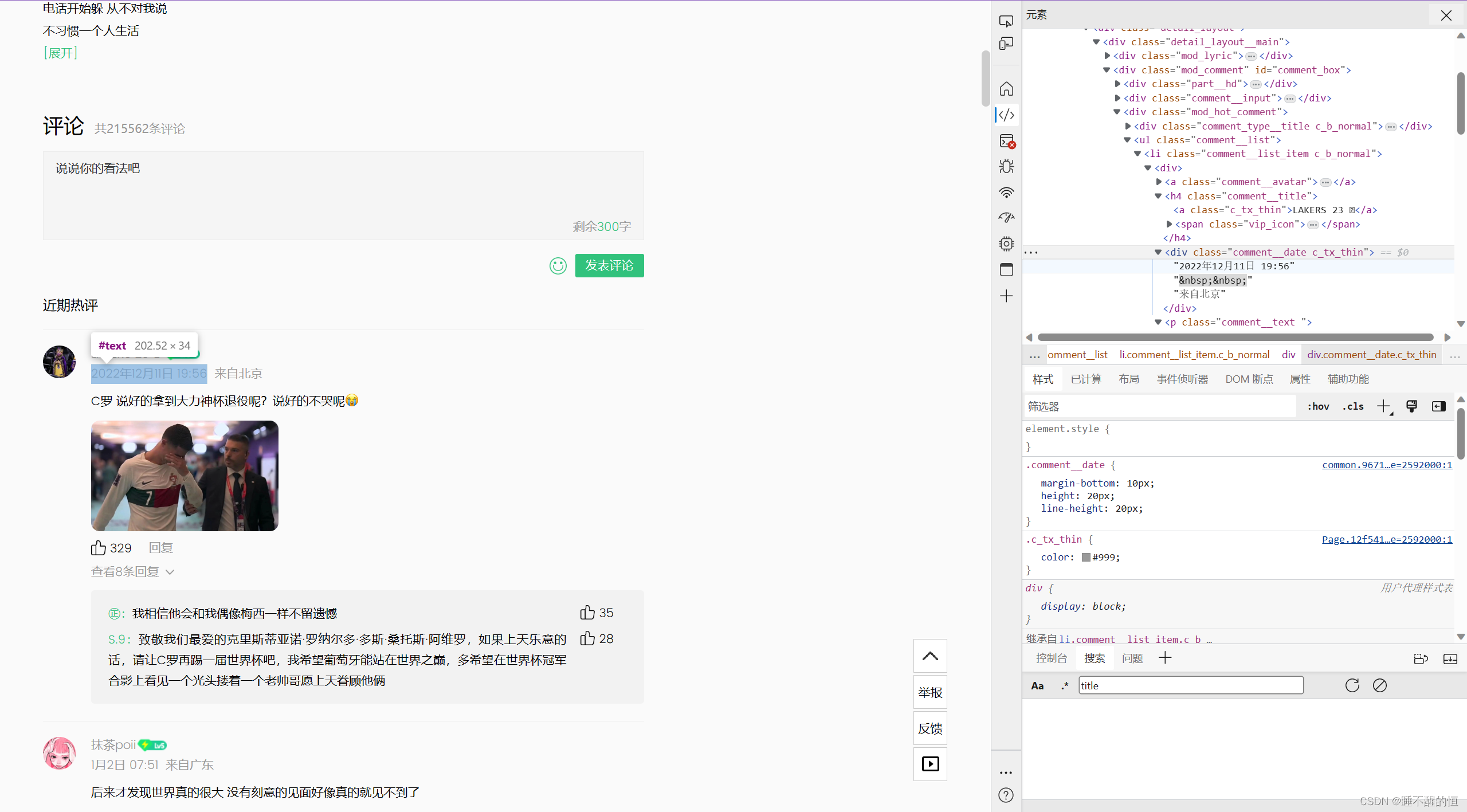
3. 点赞数
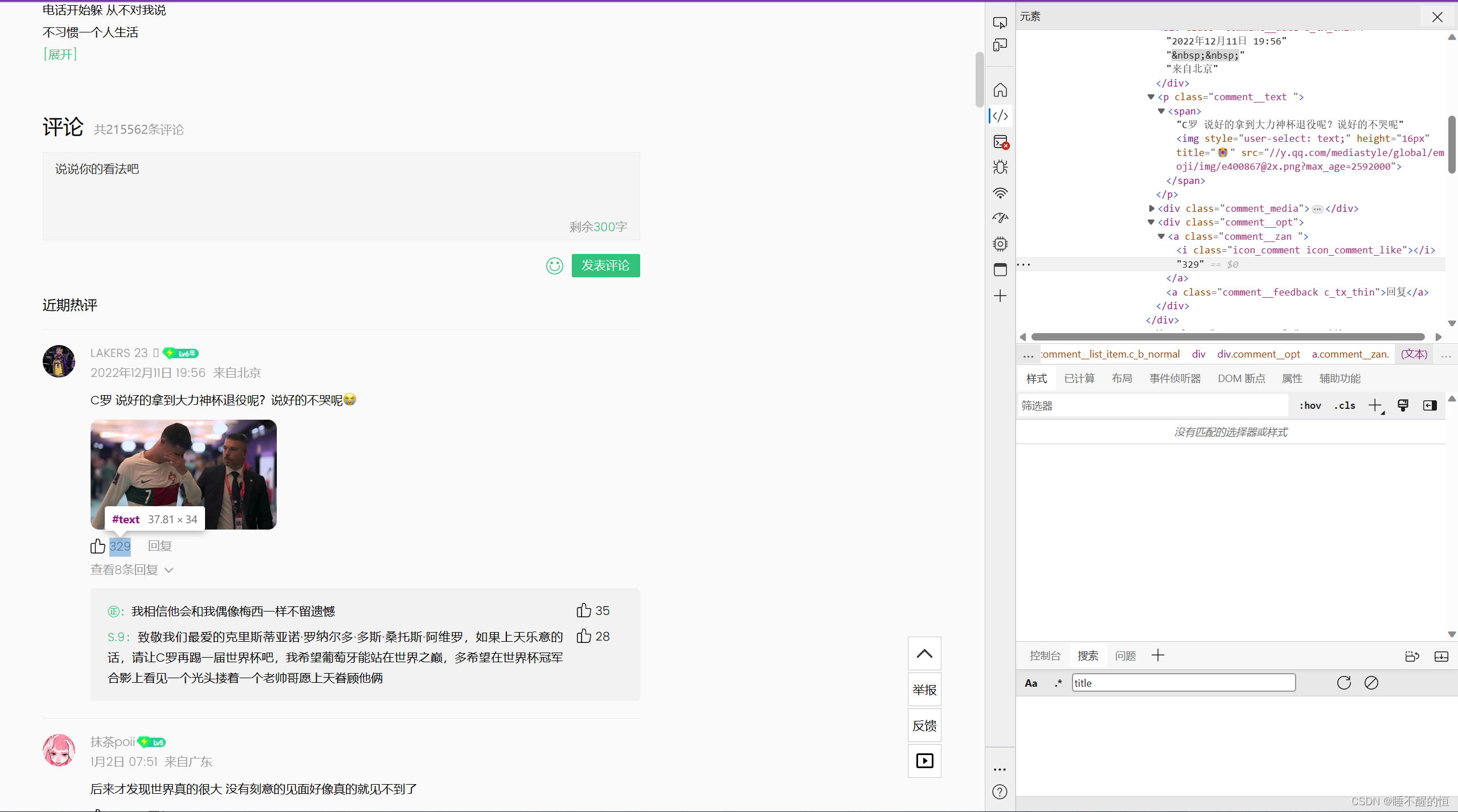
4. 评论内容
三. 爬取实战
3.1 导入基本第三方库
import requests
import xlwt
import json
import xlrd
3.2 进行爬取
workbook=xlwt.Workbook(encoding='utf-8')
worksheet=workbook.add_sheet('说好不哭评论')
worksheet.write(0,0,'昵称')
worksheet.write(0,1,'时间')
worksheet.write(0,2,'点赞数')
worksheet.write(0,3,'评论')
n=1
for page in range(0,20):
print('-'*100)
url_left= 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk=792727314&hostUin=0&format=json&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq.json&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=237773700&cmd=8&needmusiccrit=0'
url=url_left+'&pagenum='+str(page)+'&pagesize=25'
headers={'User-agent':''}
r=requests.get(url,headers=headers)
data=json.loads(r.text)
common_comments=data.get('comment').get('commentlist')
for i in range(0,len(common_comments)):
worksheet.write(n,0,common_comments[i].get('nick'))
worksheet.write(n,1,common_comments[i].get('time'))
worksheet.write(n,2,common_comments[i].get('praisenum'))
worksheet.write(n,3,common_comments[i].get('rootcommentcontent'))
n+=1
print('第{}页评论爬取完成'.format(str(page)))
print('-'*100)
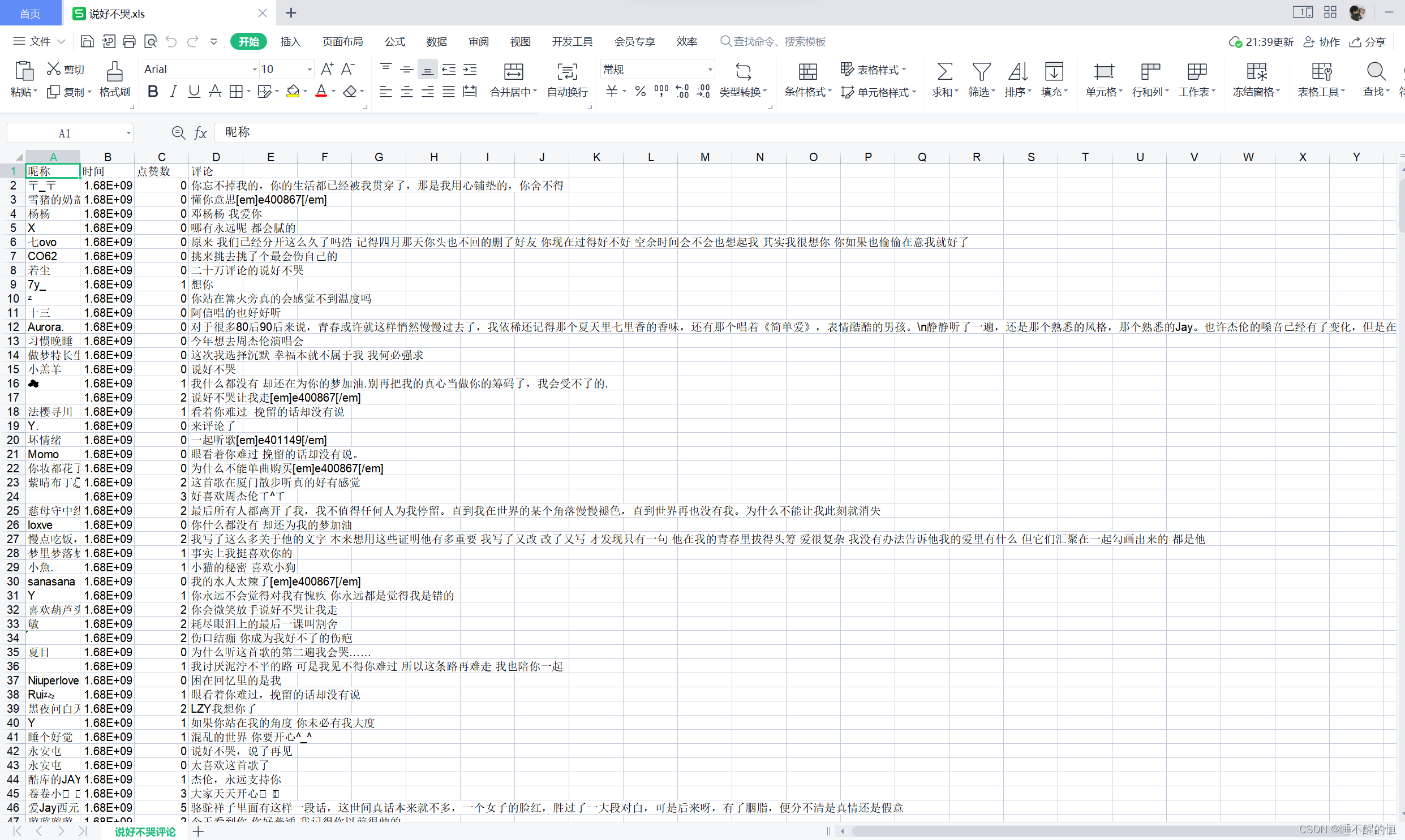
workbook.save('说好不哭.xls')我此时将爬取好的文件放入“说好不哭.xls”中,大家可以随意更改文件名称,都是可以的。
爬取过程终端展示:

说好不哭.xls:
四. 可视化——词云
4.1 wordcloud 简介
wordcloud.WordCloud()代表一个文本对应的词云- 可以根据文本中词语出现的频率等参数绘制词云
- 绘制词云的形状、尺寸和颜色均可设定
- 以WordCloud对象为基础,配置参数、加载文本、输出文件
4.2 更加详细的词云讲解,可查看:词云讲解 该链接
4.3 导入可视化第三方库
import matplotlib.pyplot as plt
import jieba
import wordcloud
import matplotlib4.4 将.xls文件中评论输出到.txt文件当中
workbook = xlrd.open_workbook(r"D:/pythonProject5/说好不哭.xls") #excel路径
#table = workbook.sheet_by_name(u'C') # 按名字打开
table = workbook.sheet_by_index(0) # 按顺序打开
nrows = table.nrows # 行数
ncols = table.ncols # 列数
l= []
for i in range(nrows):
rows = table.row_values(i) # 一行的值 list 浮点数
l.append(rows) #二维列表
t= ''
out_file = '说好不哭.txt'
with open (out_file,'w',encoding='utf-8')as f: # 这是输出位置,修改即可,excel第一行与第一列别有序号
for j in l:
for k in range(ncols):
t = t+str(j[3])+',' #拼接
f.write(t.strip(',')) # 去逗号
f.write('\n')
t= ''
4.5 绘制词云,利用jieba提取词组与短语分析频次
matplotlib.rcParams['font.sans-serif'] = ['simple'] # 设置绘图字体
def wordFreq(filepath, text, topn):
# jieba分词库分词
words = jieba.lcut(text.strip())
counts = {}
# 列表生成式获取停用词
stopwords = [line.strip() for line in open('stop_words.txt', 'r', encoding='utf-8').readlines()]
word_clear = [] # 用于生成词云的词语列表,避免重复分词,节约运行时间
# 统计词频
for word in words:
if (len(word) == 1):
continue
elif word not in stopwords:
if word == "伦":
word = "周杰伦"
elif word == "喜欢" :
word == "好棒"
elif word == "nice":
word == "好!"
elif word == "好听":
word == "悦耳"
word_clear.append(word)
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(topn):
word, count = items[i]
print(f"{word}:{count}")
return word_clear
def gen_cloudword(txt):
wcloud = wordcloud.WordCloud(font_path=r'C:\Windows\Fonts\simhei.ttf', width=1000, max_words=100, height=860,
margin=2).generate(txt)
wcloud.to_file("loud_star.png") # 保存图片
# 显示词云图片
plt.imshow(wcloud)
plt.axis('off')
plt.show()
text = open('1.txt', "r", encoding='utf-8').read()
words_clear = wordFreq('1.txt', text, 20)
gen_cloudword(' '.join(words_clear))
此时代码中加入了停顿词文件,目的是消除词频出现率较高的没用词,例如:的、你、我、它等
大家可以随意加入自己想删除的无用词,例如我的停顿词为:
若想用我的停顿词可以评论找我领取
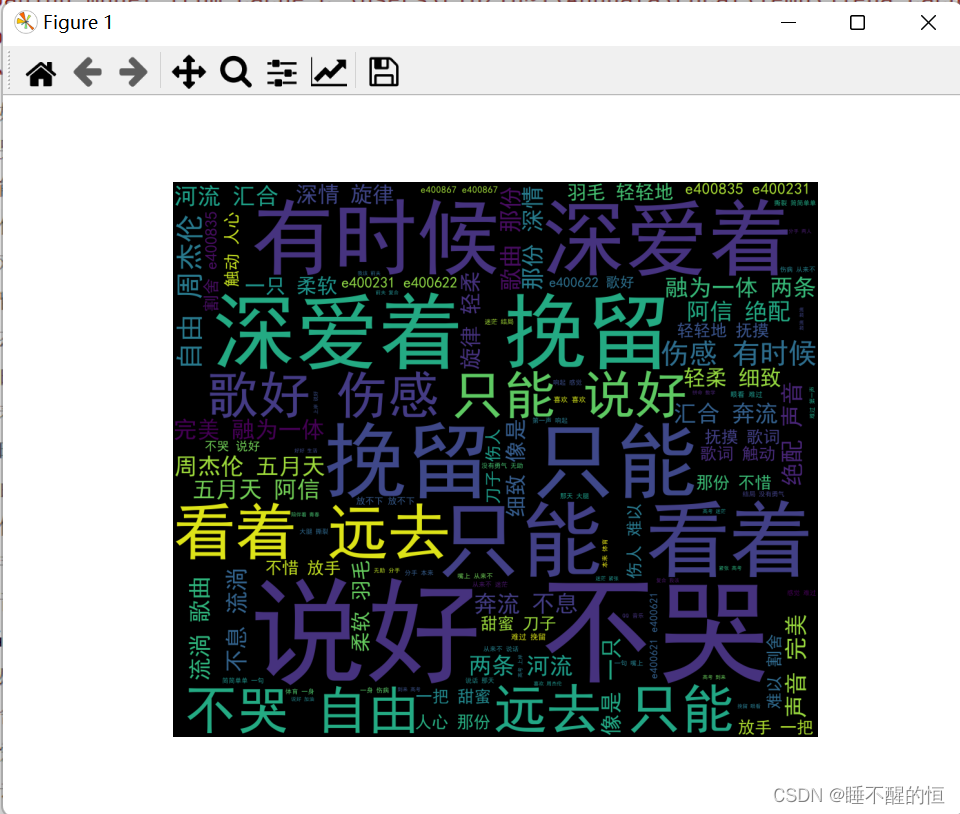
运行结果词云展示:
这是各类词语出现的词频,这里统计了前20个
五. 完整代码
import requests
import xlwt
import json
import xlrd
import matplotlib.pyplot as plt
import jieba
import wordcloud
import matplotlib
workbook=xlwt.Workbook(encoding='utf-8')
worksheet=workbook.add_sheet('说好不哭评论')
worksheet.write(0,0,'昵称')
worksheet.write(0,1,'时间')
worksheet.write(0,2,'点赞数')
worksheet.write(0,3,'评论')
n=1
for page in range(0,20):
print('-'*100)
url_left= 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk=792727314&hostUin=0&format=json&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq.json&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=237773700&cmd=8&needmusiccrit=0'
url=url_left+'&pagenum='+str(page)+'&pagesize=25'
headers={'User-agent':''}
r=requests.get(url,headers=headers)
data=json.loads(r.text)
common_comments=data.get('comment').get('commentlist')
for i in range(0,len(common_comments)):
worksheet.write(n,0,common_comments[i].get('nick'))
worksheet.write(n,1,common_comments[i].get('time'))
worksheet.write(n,2,common_comments[i].get('praisenum'))
worksheet.write(n,3,common_comments[i].get('rootcommentcontent'))
n+=1
print('第{}页评论爬取完成'.format(str(page)))
print('-'*100)
workbook.save('说好不哭.xls')
# print(common_comments)
workbook = xlrd.open_workbook(r"D:/pythonProject5/说好不哭.xls") #excel路径
#table = workbook.sheet_by_name(u'C') # 按名字打开
table = workbook.sheet_by_index(0) # 按顺序打开
nrows = table.nrows # 行数
ncols = table.ncols # 列数
l= []
for i in range(nrows):
rows = table.row_values(i) # 一行的值 list 浮点数
l.append(rows) #二维列表
t= ''
out_file = '说好不哭.txt'
with open (out_file,'w',encoding='utf-8')as f: # 这是输出位置,修改即可,excel第一行与第一列别有序号
for j in l:
for k in range(ncols):
t = t+str(j[3])+',' #拼接
f.write(t.strip(',')) # 去逗号
f.write('\n')
t= ''
matplotlib.rcParams['font.sans-serif'] = ['simple'] # 设置绘图字体
def wordFreq(filepath, text, topn):
# jieba分词库分词
words = jieba.lcut(text.strip())
counts = {}
# 列表生成式获取停用词
stopwords = [line.strip() for line in open('stop_words.txt', 'r', encoding='utf-8').readlines()]
word_clear = [] # 用于生成词云的词语列表,避免重复分词,节约运行时间
# 统计词频
for word in words:
if (len(word) == 1):
continue
elif word not in stopwords:
if word == "伦":
word = "周杰伦"
elif word == "喜欢" :
word == "好棒"
elif word == "nice":
word == "好!"
elif word == "好听":
word == "悦耳"
word_clear.append(word)
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(topn):
word, count = items[i]
print(f"{word}:{count}")
return word_clear
def gen_cloudword(txt):
wcloud = wordcloud.WordCloud(font_path=r'C:\Windows\Fonts\simhei.ttf', width=1000, max_words=100, height=860,
margin=2).generate(txt)
wcloud.to_file("loud_star.png") # 保存图片
# 显示词云图片
plt.imshow(wcloud)
plt.axis('off')
plt.show()
text = open('说好不哭.txt', "r", encoding='utf-8').read()
words_clear = wordFreq('1.txt', text, 20)
gen_cloudword(' '.join(words_clear))
谢谢大家~欢迎指正批评

















 858
858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











