







Hadoop配置
本地模式下,不需要配置也可以使用,因此伪分布式需要追加如下配置:
export HADOOP_HOME="/usr/local/hadoop-2.7.2"
export PATH=$HADOOP_HOME参考结果如下:
JAVA_HOME=/usr/local/jdk1.8.0_171
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
HADOOP_HOME=/usr/local/hadoop-2.7.2
ANT_HOME=/usr/local/apache-ant-1.10.5
PATH=$JAVA_HOME/bin:$PATH/bin:$HADOOP_HOME/bin
export JAVA_HOME ANT_HOME CLASSPATH PATH HADOOP_HOME
source /etc/profile 使得配置生效,验证HADOOP_HOME参数:
echo $HADOOP_HOME
接下来, 在hadoop的安装目录下,修改 core-site.xml 和 etc/hadoop/hdfs-site.xml
![]()
[root@hadoop-a hadoop]# ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml.template
core-site.xml httpfs-site.xml slaves
hadoop-env.cmd kms-acls.xml ssl-client.xml.example
hadoop-env.sh kms-env.sh ssl-server.xml.example
hadoop-metrics2.properties kms-log4j.properties yarn-env.cmd
hadoop-metrics.properties kms-site.xml yarn-env.sh
hadoop-policy.xml log4j.properties yarn-site.xml
hdfs-site.xml mapred-env.cmd
1、etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>fs.defaultFS参数配置的是HDFS的地址。 localhost为hostname,hostname有修改的需要改成自己的(我的hostname为 hadoop-a,因此<value>hdfs://hadoop-a:9000</value>)。
2、etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>dfs.replication配置的是HDFS存储时的备份数量,因为这里是伪分布式环境只有一个节点,所以这里设置为1。
3、格式化HDFS
备注: 如果需要重新格式化NameNode,需要先将原来NameNode和DataNode下的文件全部删除,不然会报错,NameNode和DataNode所在目录是在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。
bin/hdfs namenode -format启动服务
1、启动NameNode
${HADOOP_HOME}/sbin/hadoop-daemon.sh start namenode2、启动DataNode
${HADOOP_HOME}/sbin/hadoop-daemon.sh start datanode3、启动SecondaryNameNode
${HADOOP_HOME}/sbin/hadoop-daemon.sh start secondarynamenode4、查看启动结果
输入jps查看进程
[hadoop@localhost hadoop-2.7.2]$ jps
8865 NameNode
8967 DataNode
10072 SecondaryNameNode
10121 Jps
也可以在浏览器中访问 http://localhost:50070/ (我的hostname改为hadoop-a,所以我的访问路径为hadoop-a:50070,hostname有改动的需要注意)
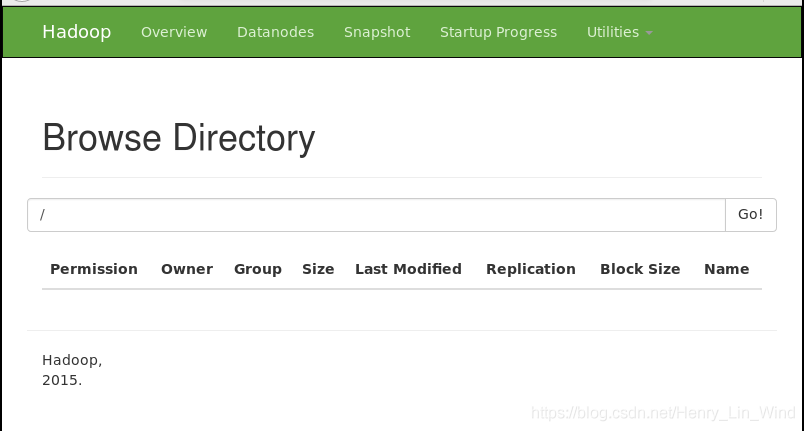
可以看到有个节点存活,说明启动成功。

HDFS上测试创建目录、上传、下载文件
1、HDFS上创建目录
${HADOOP_HOME}/bin/hdfs dfs -mkdir /myhadoop在网页上查看结果 Utilities > Browse the file system,可以看到新建的文件夹。
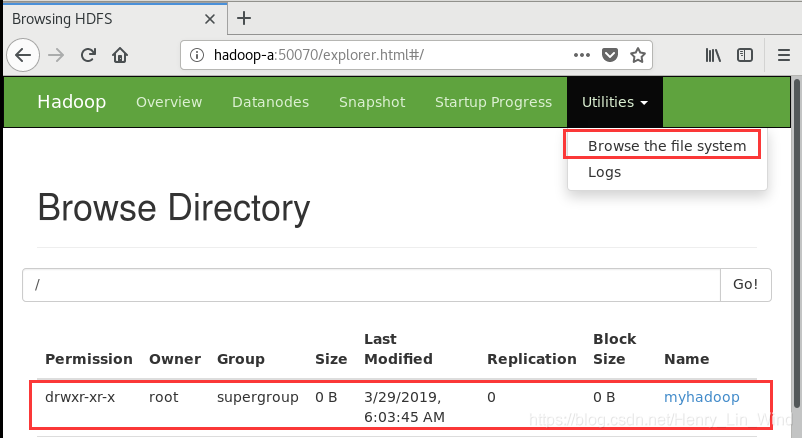
2、上传本地文件到HDFS上
${HADOOP_HOME}/bin/hdfs dfs -put ${HADOOP_HOME}/etc/hadoop/core-site.xml /myhadoop3、读取HDFS上的文件内容
${HADOOP_HOME}/bin/hdfs dfs -cat /myhadoop/core-site.xml4、从HDFS上下载文件到本地
bin/hdfs dfs -get /myhadoop/core-site.xml5 、除了在控制台外,使用hadoop-eclipse-plugin插件,更为便捷地执行创建目录、上传、下载文件
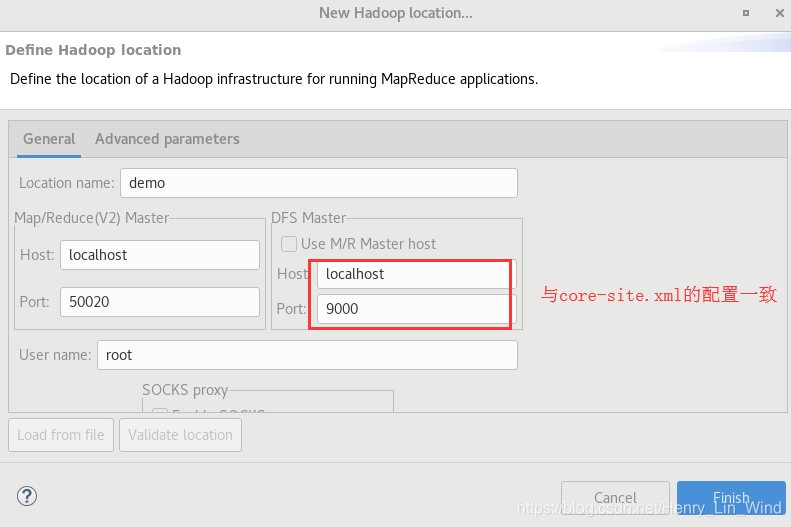
新建一个连接,DFS master的设置与 core-site.xml 一致,填入hostname和通道号。确保前述的服务已经启动,可以通过jps查看。
hadoop-eclipse-plugin 插件的安装和配置参考我的博客 : https://blog.csdn.net/Henry_Lin_Wind/article/details/88812421
设置完成后,在Project Explorer 的DFS Location查看。(确保已做好配置和相关服务进程已启动)
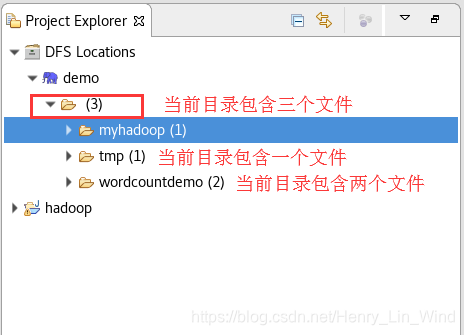
6、在网页查看相关的操作结果
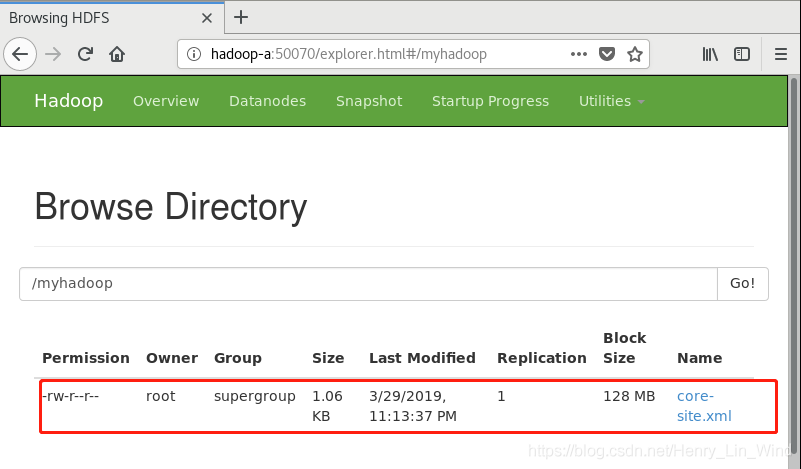
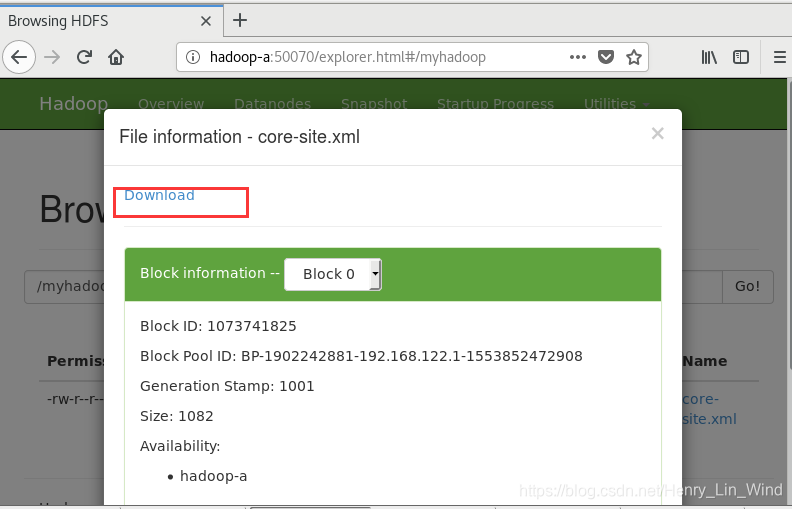
配置、启动YARN
1、配置mapred-site.xml
默认没有mapred-site.xml文件,但是有个mapred-site.xml.template配置模板文件。复制模板生成mapred-site.xml。
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml添加配置,指定mapreduce运行在yarn框架上
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>2、 配置yarn-site.xml
添加配置及其作用:
-
yarn.nodemanager.aux-services配置了yarn的默认混洗方式,选择为mapreduce的默认混洗算法。
-
yarn.resourcemanager.hostname指定了Resourcemanager运行在哪个节点上。
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>3、 启动Resourcemanager
${HADOOP_HOME}/sbin/yarn-daemon.sh start resourcemanager4、 启动nodemanager
${HADOOP_HOME}/sbin/yarn-daemon.sh start nodemanager5、 jps查看是否启动成功
[root@hadoop-a hadoop-2.7.2]# jps
8897 NameNode
24161 NodeManager
24259 Jps
9253 DataNode
9798 org.eclipse.equinox.launcher_1.5.300.v20190213-1655.jar
9353 SecondaryNameNode
23915 ResourceManager
6、ResourceManager - http://localhost:8088/
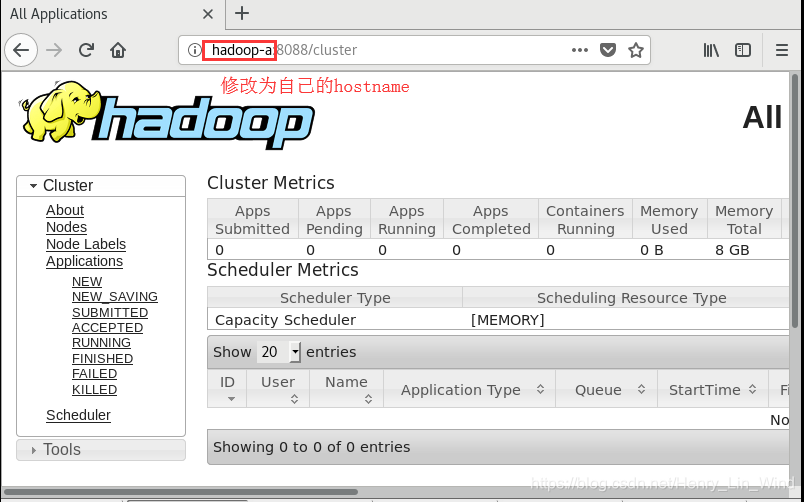
完成上述操作后,我们就可以50070上看输出结果,还可以在8088上看mapreduce作业的记录
接下来运行自带的 wordcounter 来验证
1、 创建测试用的Input文件
${HADOOP_HOME}/bin/hdfs dfs -mkdir -p /wordcountdemo/input2、上传一个测试文件到input文件夹
${HADOOP_HOME}/bin/hdfs dfs -put ${HADOOP_HOME}/etc/hadoop/core-site.xml /wordcountdemo/input
3、运行WordCount MapReduce Job
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wordcountdemo/input /wordcountdemo/output4、查看结果,可以在50070看到输出结果,8088看到操作记录

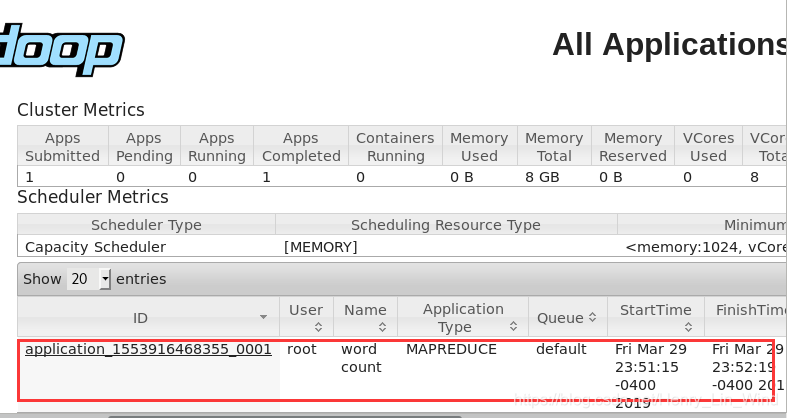















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









