






今日在学习时,随着视频的节奏敲着代码,昏昏欲睡,但一串红色的报错让我从梦中清醒过来
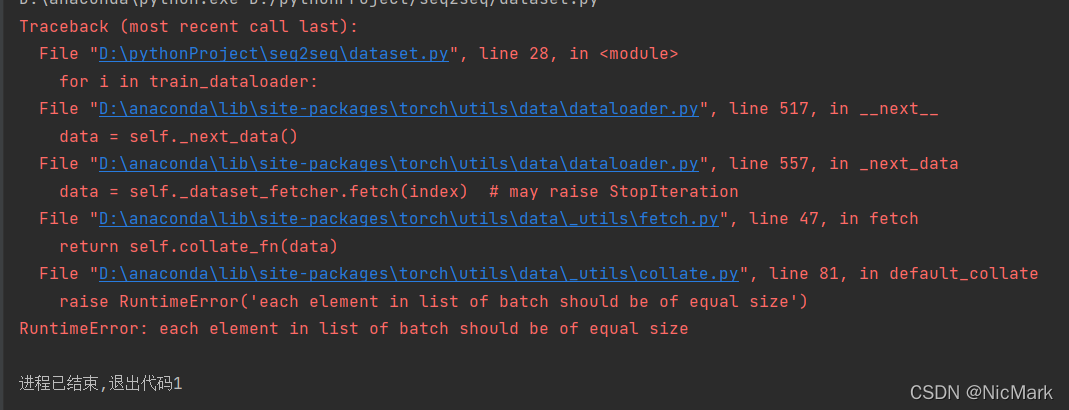
通过报错信息可以了解到,我们的collate_fn出现了问题,其问题在于我们的每一个batch有不一样长数据,即batch_size不一样长。
可能有小伙伴对于batch,batch_size的理解有一点模糊(包括我在内),在查询相关的一些资料后,我的理解是可以将其理解为一个二位数组
(借用一位博主的图片)
那位博主有关这张图片的博客,侵删


这里的一个batch内有五个信息,则batch=1,batch_size = 5
(如有不恰当之处,欢迎指正,感激不尽)
在DataLoader()中,当我们没有自定义collate_fn`时,其会调用所默认的collate_fn
def default_collate(batch):
r"""Puts each data field into a tensor with outer dimension batch size"""
elem = batch[0]
elem_type = type(elem)
if isinstance(elem, torch.Tensor):
out = None
if torch.utils.data.get_worker_info() is not None:
# If we're in a background process, concatenate directly into a
# shared memory tensor to avoid an extra copy
numel = sum([x.numel() for x in batch])
storage = elem.storage()._new_shared(numel)
out = elem.new(storage)
return torch.stack(batch, 0, out=out)
elif elem_type.__module__ == 'numpy' and elem_type.__name__ != 'str_' \
and elem_type.__name__ != 'string_':
if elem_type.__name__ == 'ndarray' or elem_type.__name__ == 'memmap':
# array of string classes and object
if np_str_obj_array_pattern.search(elem.dtype.str) is not None:
raise TypeError(default_collate_err_msg_format.format(elem.dtype))
return default_collate([torch.as_tensor(b) for b in batch])
elif elem.shape == (): # scalars
return torch.as_tensor(batch)
elif isinstance(elem, float):
return torch.tensor(batch, dtype=torch.float64)
elif isinstance(elem, int_classes):
return torch.tensor(batch)
elif isinstance(elem, string_classes):
return batch
elif isinstance(elem, container_abcs.Mapping):
return {key: default_collate([d[key] for d in batch]) for key in elem}
elif isinstance(elem, tuple) and hasattr(elem, '_fields'): # namedtuple
return elem_type(*(default_collate(samples) for samples in zip(*batch)))
elif isinstance(elem, container_abcs.Sequence):
# check to make sure that the elements in batch have consistent size
it = iter(batch)
elem_size = len(next(it))
if not all(len(elem) == elem_size for elem in it):
raise RuntimeError('each element in list of batch should be of equal size')
transposed = zip(*batch)
return [default_collate(samples) for samples in transposed]
太长不看型:本报错下只需要关注这一个判断代码即可
elif isinstance(elem, container_abcs.Sequence):
# check to make sure that the elements in batch have consistent size
it = iter(batch)
elem_size = len(next(it))
if not all(len(elem) == elem_size for elem in it):
raise RuntimeError('each element in list of batch should be of equal size')
transposed = zip(*batch)
我们可以看到
if not all(len(elem) == elem_size for elem in it):
raise RuntimeError('each element in list of batch should be of equal size')
意在表明如果不是所有的batch_size都一样,那么它就会报错,返回之前看到的那个报错。
ps:(container_abcs.Sequence)是什么意思有无大佬可以简要的说明下吗
那么我们要怎么解决这个问题呢?很简单,就是根据自己的需求自己定义一个collate_fn函数即可。
拿我来说:
这是我的dataset,可以清晰的看到由于randint取值的范围,导致数字的长度不同,进而在转成str并以list输出时的len()便不相同。
class NumDataset(Dataset):
def __init__(self):
#使用numpy随即创建一堆数字
self.data = np.random.randint(0,1e8,size=[5000])
def __getitem__(self, index):
return list(str(self.data[index]))
def __len__(self):
return self.data.shape[0]
那么我们只需要定义一个
def collate_fn(data):
list_data = []
for i in data:
list_data.append(i)
return list_data
在这里的话,由于没有判断长度的因素,所以dataloader会正常返回。















 2872
2872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









