







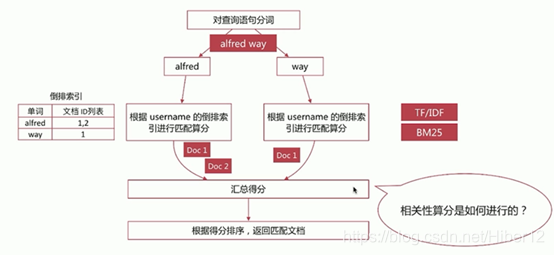
相关性算分:指文档与查询语句间的相关度,通过倒排索引可以获取与查询语句相匹配的文档列表
如何将最符合用户查询需求的文档放到前列呢?
本质问题是一个排序的问题,排序的依据是相关性算分,确定倒排索引哪个文档排在前面
影响相关度算分的参数:
1、TF(Term Frequency):词频,即单词在文档中出现的次数,词频越高,相关度越高
2、Document Frequency(DF):文档词频,即单词出现的文档数
3、IDF(Inverse Document Frequency):逆向文档词频,与文档词频相反,即1/DF。即单词出现的文档数越少,相关度越高(如果一个单词在文档集出现越少,算为越重要单词)
4、Field-length Norm:文档越短,相关度越高
——TF/IDE模型
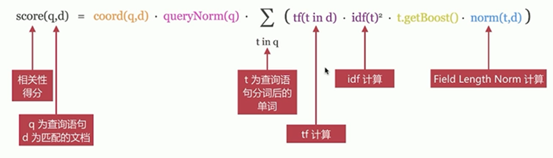
——BM25模型(5.X之后的默认模型)
对之前算分进行优化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 502
502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









