







 本文深入解析了Okapi BM25算法,包括逆文档频率、词频相关性和文档长度因素。BM25通过调整TF-IDF模型,考虑文档长度影响,提高搜索精度。核心讲解了IDF公式、词频归一化参数k1和文档长度调整K值的作用。
本文深入解析了Okapi BM25算法,包括逆文档频率、词频相关性和文档长度因素。BM25通过调整TF-IDF模型,考虑文档长度影响,提高搜索精度。核心讲解了IDF公式、词频归一化参数k1和文档长度调整K值的作用。
文章目录
1、引言
BM25(全称:Okapi BM25) 其中 BM 指的 Best Matching 的缩写,是搜索引擎常用的一种相关度评分函数。和TF/IDF一样,BM25 也是基于词频和文档频率和文档长度相关性来计算相关度,但是规则有所不同,文章中将会给出详细讲解。
BM25 也被认为是 目前最先进的 评分算法。
2、相关度概率模型
BM25 是一个 bag-of-words 检索功能,它根据每个文档中出现的查询词对一组文档进行排名,而不管它们在文档中的接近程度如何。它是一系列评分函数,其组件和参数略有不同。
3、Okapi BM25 函数
给定一个查询
Q
Q
Q,包含关键词
q
1
,
q
2
,
⋅
⋅
⋅
,
q
n
q_1,q_2,···,q_n
q1,q2,⋅⋅⋅,qn ,对于文档
D
D
D 的 BM25 分数为计算公式:
s
c
o
r
e
(
D
,
Q
)
=
∑
i
=
1
n
I
D
F
(
q
i
)
∙
S
(
q
i
,
D
)
score(D,Q)=\sum_{i=1}^nIDF(q_i) \bull S(q_i,D)
score(D,Q)=i=1∑nIDF(qi)∙S(qi,D)
- s c o r e ( D , Q ) score(D,Q) score(D,Q):表示查询 Q Q Q对文档 D D D的最终评分
- I D F ( q i ) IDF(q_i) IDF(qi):表示查询词的 I D F IDF IDF 权重,其计算公式为
- S ( q i , D ) S(q_i,D) S(qi,D):表示
- q i q_i qi:表示查询Q中第 i 个 term
- D D D:表示当前计算评分的文档
3.1 逆文档频率: I D F ( q i ) IDF(q_i) IDF(qi)
3.1.1 函数公式及参数
I D F ( q i ) = l n ( N − n ( q i ) + 0.5 n ( q i ) + 0.5 + 1 ) IDF(q_i)=ln({N-n(q_i)+0.5 \over n(q_i)+0.5}+1) IDF(qi)=ln(n(qi)+0.5N−n(qi)+0.5+1)
- N N N:指的是索引中的文档总数
- n ( q i ) n(q_i) n(qi):表示包含的文档的 q i q_i qi 的文档个数。
3.1.2 函数曲线
以下是
I
D
F
(
q
i
)
IDF(q_i)
IDF(qi) 随着文档频率
n
(
q
i
)
n(q_i)
n(qi)(反词频)的变化曲线:

BM25 的 IDF 看起来与经典的 Lucene IDF 差别不大。这里存在差异的原因是它采用了概率相关模型,而 TF-IDF 所使用的的是向量空间模型 。
3.1.3 总结
原本 I D F ( q i ) IDF(q_i) IDF(qi) 对文档频率(反词频)非常高的词项是有可能计算出负值得出负分的,所以 Lucene 对 BM25 的常规 IDF 进行了一项优化:通过在获取对数之前将值加 1,让结果无法得出负值。最终结果是一个看起来和 Lucene 当前的 IDF 曲线极为相似的 IDF曲线。
总结:BM25 相对于 TF-IDF 在 IDF 计算分数的层面上增益并不明显。
3.2 词频相关性函数: S ( q i , D ) S(q_i,D) S(qi,D)
3.2.1 函数及参数
S ( q i , D ) = f ( q i , D ) ∙ ( k 1 + 1 ) f ( q i , D ) + K S(q_i,D)={f(q_i,D) \bull (k_1+1)\over f(q_i,D)+ K} S(qi,D)=f(qi,D)+Kf(qi,D)∙(k1+1)
- f ( q i , D ) f(q_i, D) f(qi,D):表示词项 q i q_i qi 在文档 D D D 中的词频。
- K K K:表示文档长度相关性(这里的文档长度指的是词项个数)。
- k 1 k_1 k1:控制非线性项频率归一化(饱和度),默认值为1.2。
3.2.2 相关性曲线
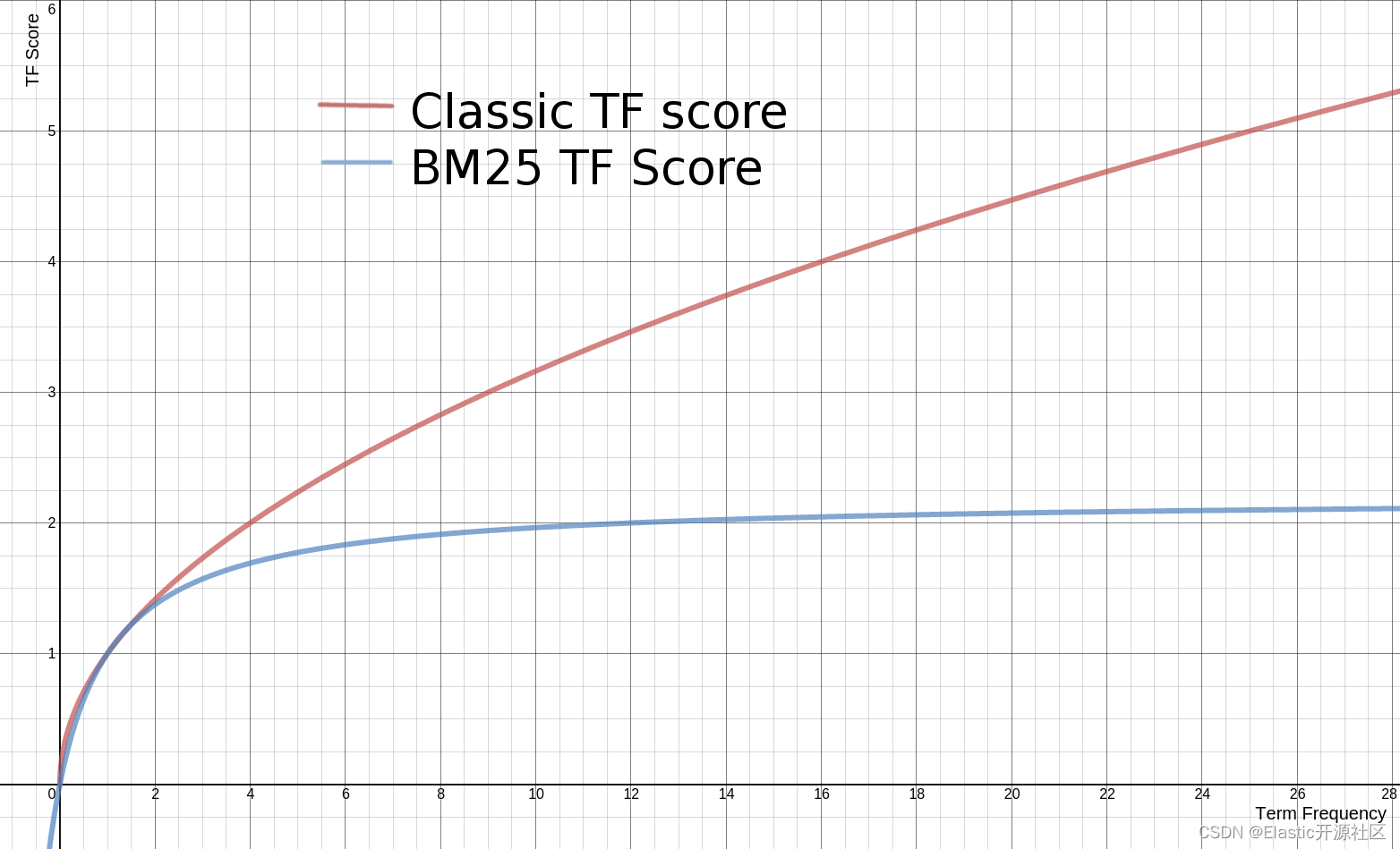
在 TF-IDF 算法中,
c
o
o
r
d
(
q
,
d
)
coord(q,d)
coord(q,d)可以对匹配到的词项提供加成,文档中出现的次数越多,加成越多,这个关系是一个线性函数。
但是,如果同一个 doc 中,出现了 1000 次某个相同的词项,比如 _id = 1 的文档的 title 字段为:“苹果-苹果- ··· -苹果”(共 1000 次苹果),而 _id = 2 的文档的 title 字段为:“苹果-苹果-···-苹果”(共 100 次苹果)。那么对于词项“苹果”,文档1的相关性应该是文档2的十倍吗?
显然不是,对于文档一和文档二,这两个文档对苹果这个词项的相关性应该是非常接近的,换句话说,当文档中出现了一个词项的时候,后面再次出现相同词项,对当前文档的相关性虽然应该有提升,但是提升幅度应该逐渐下降。当词频足够多或者说达到某个阈值的时候,再增加词频对于相关度的提升应该无限趋近于0。
降低 TF 的增益权重的常用手段是对其取平方根,但是这仍然是一个无穷大函数,所以就需要设置一个阈值来限制 TF 的最大值。而 k 1 k_1 k1 就是控制因子。
对于
f
(
q
i
,
D
)
∙
(
k
1
+
1
)
f
(
q
i
,
D
)
+
K
{f(q_i,D) \bull (k_1+1)\over f(q_i,D)+ K}
f(qi,D)+Kf(qi,D)∙(k1+1),将分子分母同时➗
f
(
q
i
,
D
)
f(q_i,D)
f(qi,D):
f
(
q
i
,
D
)
∙
(
k
1
+
1
)
f
(
q
i
,
D
)
+
K
=
k
1
+
1
K
f
(
q
i
,
D
)
+
1
{f(q_i,D) \bull (k_1+1)\over f(q_i,D)+ K}={ k_1+1\over {K\over f(q_i,D)}+1}
f(qi,D)+Kf(qi,D)∙(k1+1)=f(qi,D)K+1k1+1
其中,
K
K
K 此时为常量,
k
1
k_1
k1也为常量,默认为 1.2,随着
f
(
q
i
,
D
)
f(q_i,D)
f(qi,D)的不断增大,
K
f
(
q
i
,
D
)
K\over f(q_i,D)
f(qi,D)K 无限趋近于 0,因此
K
f
(
q
i
,
D
)
+
1
{K\over f(q_i,D)}+1
f(qi,D)K+1无限趋近于1,所以此时
S
(
q
i
,
D
)
S(q_i,D)
S(qi,D)的值为最大值,也就是
k
1
+
1
k_1+1
k1+1。
也就是说,当文档频率不断增大,TF 得分最大值也就是 k 1 + 1 k_1+1 k1+1,而不会继续增大下去。

非常直观的可以看到,这条曲线随着词频的不断增大,无限地趋近于 (k + 1)(默认 k = 1.2)
3.2.3 k 1 k_1 k1值的作用:
我们可以人为的通过设置 k 的值来控制最大 TF 得分。更重要的一点是增加 k 的值可以延迟 TF 达到最大值的速度,通过拉伸这个临界值,可以来调节较高和较低词频之间的差异相关性。
3.3 文档长度相关性: K K K
K = k 1 ∙ ( 1 − b + b ∙ ∣ D ∣ a v g d l ) K=k_1\bull(1-b+b\bull{|D|\over avgdl}) K=k1∙(1−b+b∙avgdl∣D∣)
- k 1 k_1 k1:控制非线性项频率归一化(饱和度),默认值为1.2。
- b b b:控制文档长度标准化 t f tf tf值的程度,默认值为0.75。
- ∣ D ∣ |D| ∣D∣:表示文档D的词项长度,即 term 数量
- a v g d l avgdl avgdl:表示所有文档的平均长度,这里的长度指的是词项的数量。
假设 L = ∣ D ∣ a v g d l L= {|D|\over avgdl} L=avgdl∣D∣,即 当 前 文 档 长 度 平 均 文 档 长 度 当前文档长度\over 平均文档长度 平均文档长度当前文档长度
下图是不同 L L L下, S ( q i , D ) S(q_i,D) S(qi,D) 随着词频的变化曲线:
- 紫色曲线为:
L
L
L =
1
5
1\over5
51,即
当前文档长度:平均文档长度 = 1:5 - 红色曲线为:
L
L
L = 1,即
当前文档长度:平均文档长度 = 1:1 - 黄色曲线为:
L
L
L = 5,即
当前文档长度:平均文档长度 = 5:1

从图中可以看出, L L L越小,越快的随着词频的增加而达到 S ( q i , D ) S(q_i,D) S(qi,D) 即TF评分阈值,也就是最佳分数。
总的来说:当词频越小的时候,提升词频对评分的帮助是越大的。反之,当词频足够的时候,再提升词频对 S ( q i , D ) S(q_i,D) S(qi,D)的提升几乎无帮助。
4、最终函数公式
s c o r e ( D , Q ) = ∑ i = 1 n l n ( N − n ( q i ) + 0.5 n ( q i ) + 0.5 + 1 ) ∙ f ( q i , D ) ∙ ( k 1 + 1 ) f ( q i , D ) + K score(D,Q)=\sum_{i=1}^nln({N-n(q_i)+0.5 \over n(q_i)+0.5}+1)\bull {f(q_i,D) \bull (k_1+1)\over f(q_i,D)+ K} score(D,Q)=i=1∑nln(n(qi)+0.5N−n(qi)+0.5+1)∙f(qi,D)+Kf(qi,D)∙(k1+1)


















 2168
2168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}