







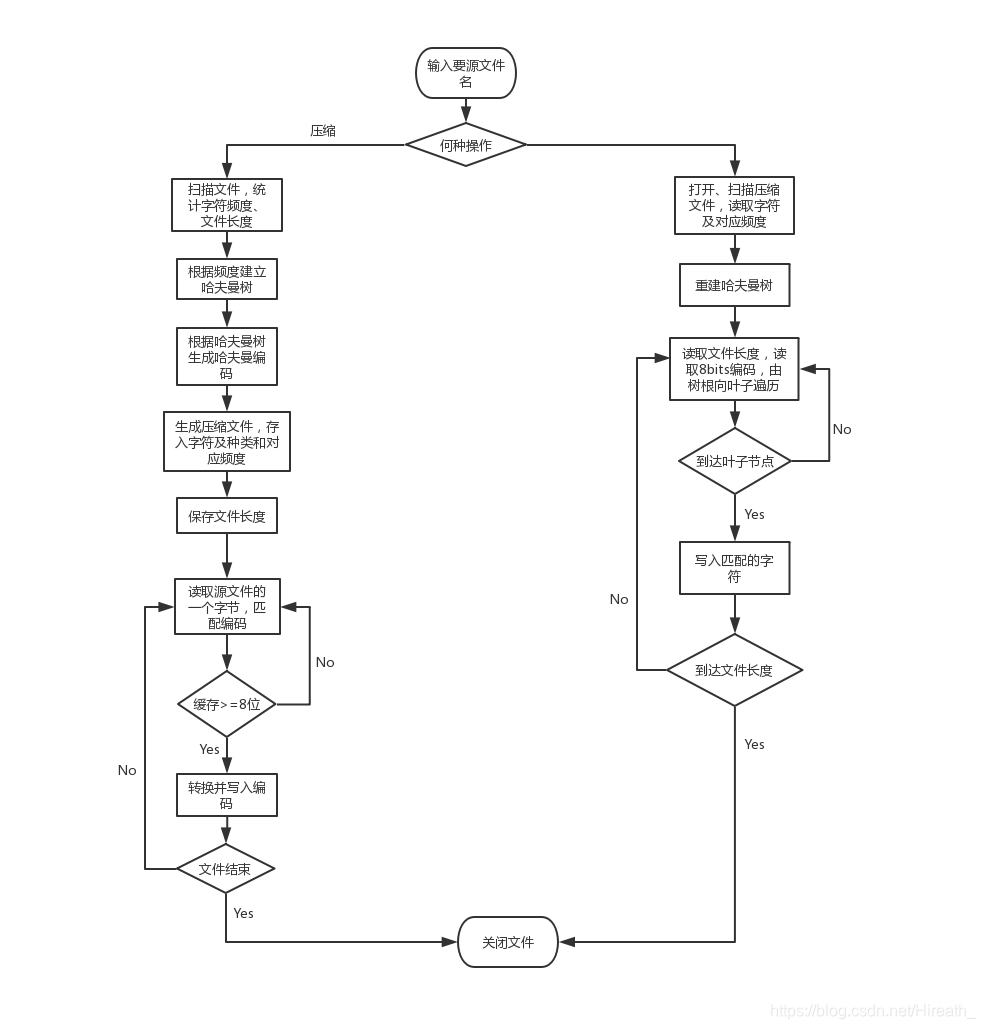
哈夫曼树压缩



#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>//求文件大小的库函数
// 统计字符频度的临时结点
typedef struct {
unsigned char uch; // 以8bits为单元的无符号字符
unsigned long weight; // 每类(以二进制编码区分)字符出现频度
int flag; //交互输入时判断是否已存在
} TmpNode;
// 哈夫曼树结点
typedef struct {
unsigned char uch; // 以8bits为单元的无符号字符
unsigned long weight; // 每类(以二进制编码区分)字符出现频度
char *code; // 字符对应的哈夫曼编码(动态分配存储空间)
int parent, lchild, rchild; // 定义双亲和左右孩子
} HufNode, *HufTree;
typedef char elementType;
typedef struct lBnode
{
elementType data;
struct lBnode *lChild,*rChild;
} BiNode,*BiTree;//二叉链表结构
// 选择最小和次小的两个结点,建立哈夫曼树调用
void select(HufNode *huf_tree, unsigned int n, int *s1, int *s2)
{
// 找最小权值的结点
unsigned int i;
unsigned long min = ULONG_MAX;
*s1=*s2=0;
for(i = 0; i < n; ++i)
if(huf_tree[i].parent == 0 && huf_tree[i].weight < min)
{
min = huf_tree[i].weight;
*s1 = i;
}
huf_tree[*s1].parent=1; // 标记此结点已被选中
// 找次小
min=ULONG_MAX;
for(i = 0; i < n; ++i)
if(huf_tree[i].parent == 0 && huf_tree[i].weight < min)
{
min = huf_tree[i].weight;
*s2 = i;
}
}
// 建立哈夫曼树
void CreateTree(HufNode *huf_tree, unsigned int char_kinds, unsigned int node_num)
{
unsigned int i;
int s1, s2;
for(i = char_kinds; i < node_num; ++i)
{
select(huf_tree, i, &s1, &s2); // 选择最小的两个结点
huf_tree[s1].parent = huf_tree[s2].parent = i;
huf_tree[i].lchild = s1;
huf_tree[i].rchild = s2; //建立联系
huf_tree[i].weight = huf_tree[s1].weight + huf_tree[s2].weight;
}
}
//打印哈夫曼树
int printTree(char *ifname,char *ofname)
{
unsigned int i, j;
unsigned int char_kinds; // 字符种类
unsigned char char_temp; // 暂存8bits字符
unsigned long file_len = 0;
FILE *infile, *outfile;
TmpNode node_temp;
unsigned int node_num;
HufTree huf_tree;
char code_buf[256] = "\0"; // 待存编码缓冲区
unsigned int code_len;
TmpNode *tmp_nodes =(TmpNode *)malloc(256*sizeof(TmpNode));
// 初始化暂存结点
for(i = 0; i < 256; ++i)
{
tmp_nodes[i].weight = 0;
tmp_nodes[i].uch = (unsigned char)i; // 数组的256个下标与256种字符对应
}
// 遍历文件,获取字符频度
infile = fopen(ifname, "rb");
// 判断输入文件是否存在
if (infile == NULL)
return -1;
fread((char *)&char_temp, sizeof(unsigned char), 1, infile); // 读入一个字符
while(!feof(infile))
{
++tmp_nodes[char_temp].weight; // 统计下标对应字符的权重,利用数组的随机访问快速统计字符频度
++file_len;
fread((char *)&char_temp, sizeof(unsigned char), 1, infile); // 读入一个字符
}
fclose(infile);
// 排序,将频度为零的放最后,剔除
for(i = 0; i < 256-1; ++i)
for(j = i+1; j < 256; ++j)
if(tmp_nodes[i].weight < tmp_nodes[j].weight)
{
node_temp = tmp_nodes[i];
tmp_nodes[i] = tmp_nodes[j];
tmp_nodes[j] = node_temp;
}//冒泡排序
// 统计实际的字符种类(出现次数不为0)
for(i = 0; i < 256; ++i)
if(tmp_nodes[i].weight == 0)
break;
char_kinds = i;
if (char_kinds == 1)
{
outfile = fopen(ofname, "wb"); // 打开压缩后将生成的文件
fwrite((char *)&char_kinds, sizeof(unsigned int), 1, outfile); // 写入字符种类
fwrite((char *)&tmp_nodes[0].uch, sizeof(unsigned char), 1, outfile); // 写入唯一的字符
fwrite((char *)&tmp_nodes[0].weight, sizeof(unsigned long), 1, outfile); // 写入字符频度,也就是文件长度
free(tmp_nodes);
fclose(outfile);
}
else
{
node_num = 2 * char_kinds - 1; // 根据字符种类数,计算建立哈夫曼树所需结点数
huf_tree = (HufNode *)malloc(node_num*sizeof(HufNode)); // 动态建立哈夫曼树所需结点
// 初始化前char_kinds个结点
for(i = 0; i < char_kinds; ++i)
{
// 将暂存结点的字符和频度拷贝到树结点
huf_tree[i].uch = tmp_nodes[i].uch;
huf_tree[i].weight = tmp_nodes[i].weight;
huf_tree[i].parent = 0;
huf_tree[i].lchild = 0;
huf_tree[i].rchild = 0; //初始化节点的父节点、左孩子、右孩子
}
free(tmp_nodes); // 释放字符频度统计的暂存区
// 初始化后node_num-char_kins个结点
for(; i < node_num; ++i)
{
huf_tree[i].parent = 0;
huf_tree[i].lchild = 0;
huf_tree[i].rchild = 0;
}
CreateTree(huf_tree, char_kinds, node_num); // 创建哈夫曼树
printf("下标 元素 父节点 \n");
for(i=1;i<char_kinds;i++)
{
printf("%2d ",i);
printf("%6c ",huf_tree[i].uch);
printf("%8d \n",huf_tree[i].parent); //打印每个结点的下标、对应的符号、父节点下标
}
// 关闭文件
fclose(infile);
fclose(outfile);
// 释放内存
for(i = 0; i < char_kinds; ++i)
free(huf_tree[i].code);
free(huf_tree);
}
}
// 生成哈夫曼编码
void HufCode(HufNode *huf_tree, unsigned char_kinds)
{
unsigned int i;
int cur, next, index;
char *code_tmp = (char *)malloc(256*sizeof(char)); // 暂存编码,最多256个叶子,编码长度不超多255
code_tmp[256-1] = '\0';
for(i = 0; i < char_kinds; ++i)
{
index = 256-1; // 编码临时空间索引初始化
// 从叶子向根反向遍历求编码
for(cur = i, next = huf_tree[i].parent; next != 0;
cur = next, next = huf_tree[next].parent)
if(huf_tree[next].lchild == cur)
code_tmp[--index] = '0'; // 左孩子是0
else
code_tmp[--index] = '1'; // 右孩子是1
huf_tree[i].code = (char *)malloc((256-index)*sizeof(char));
strcpy(huf_tree[i].code, &code_tmp[index]); // 保存哈夫曼编码到树结点中
}
free(code_tmp); // 释放编码临时空间
}
// 压缩函数
int compress(char *ifname, char *ofname)
{
unsigned int i, j;
unsigned int c_kinds; // 字符种类
unsigned char c_temp; // 暂存8bits字符
unsigned long file_len = 0;
FILE *infile, *outfile;
TmpNode node_temp;
unsigned int node_num;
HufTree huf_tree;
char code_buf[256] = "\0"; // 待存编码缓冲区
unsigned int code_len;
TmpNode *tmp_nodes =(TmpNode *)malloc(256*sizeof(TmpNode));
// 初始化暂存结点
for(i = 0; i < 256; ++i)
{
tmp_nodes[i].weight = 0;
tmp_nodes[i].uch = (unsigned char)i; // 数组的256个下标与256种字符对应
}
// 遍历文件,获取字符频度
infile = fopen(ifname, "rb");
// 判断输入文件是否存在
if (infile == NULL)
return -1;
fread((char *)&c_temp, sizeof(unsigned char), 1, infile); // 读入一个字符
while(!feof(infile))
{
++tmp_nodes[c_temp].weight; // 统计下标对应字符的权重,利用数组的随机访问快速统计字符频度
++file_len;
fread((char *)&c_temp, sizeof(unsigned char), 1, infile); // 读入一个字符
}
fclose(infile);
//冒泡 排序,将频度为零的放最后,剔除
for(i = 0; i < 256-1; ++i)
for(j = i+1; j < 256; ++j)
if(tmp_nodes[i].weight < tmp_nodes[j].weight)
{
node_temp = tmp_nodes[i];
tmp_nodes[i] = tmp_nodes[j];
tmp_nodes[j] = node_temp;
}
// 统计实际的字符种类(出现次数不为0)
for(i = 0; i < 256; ++i)
if(tmp_nodes[i].weight == 0)
break;
c_kinds = i;
//只有一个字符的情况单独考虑
if(c_kinds != 1)
{
node_num = 2 * c_kinds - 1; // 根据字符种类数,计算建立哈夫曼树所需结点数
huf_tree = (HufNode *)malloc(node_num*sizeof(HufNode)); // 动态建立哈夫曼树所需结点
// 初始化前char_kinds个结点
for(i = 0; i < c_kinds; ++i)
{
// 将暂存结点的字符和频度拷贝到树结点
huf_tree[i].uch = tmp_nodes[i].uch;
huf_tree[i].weight = tmp_nodes[i].weight;
huf_tree[i].parent = 0;
}
free(tmp_nodes); // 释放字符频度统计的暂存区
// 初始化后node_num-char_kins个结点
for(; i < node_num; ++i)
huf_tree[i].parent = 0;
CreateTree(huf_tree, c_kinds, node_num); // 创建哈夫曼树
HufCode(huf_tree, c_kinds); // 生成哈夫曼编码
// 写入字符和相应权重,供解压时重建哈夫曼树
outfile = fopen(ofname, "wb"); // 打开压缩后将生成的文件
fwrite((char *)&c_kinds, sizeof(unsigned int), 1, outfile); // 写入字符种类
for(i = 0; i < c_kinds; ++i)
{
fwrite((char *)&huf_tree[i].uch, sizeof(unsigned char), 1, outfile); // 写入字符(已排序,读出后顺序不变)
fwrite((char *)&huf_tree[i].weight, sizeof(unsigned long), 1, outfile); // 写入字符对应权重
}
// 紧接着字符和权重信息后面写入文件长度和字符编码
fwrite((char *)&file_len, sizeof(unsigned long), 1, outfile); // 写入文件长度
infile = fopen(ifname, "rb"); // 以二进制形式打开待压缩的文件
fread((char *)&c_temp, sizeof(unsigned char), 1, infile); // 每次读取8bits
while(!feof(infile))
{
// 匹配字符对应编码
for(i = 0; i < c_kinds; ++i)
if(c_temp == huf_tree[i].uch)
strcat(code_buf, huf_tree[i].code);
// 以8位(一个字节长度)为处理单元
while(strlen(code_buf) >= 8)
{
c_temp = '\0'; // 清空字符暂存空间,改为暂存字符对应编码
for(i = 0; i < 8; ++i)
{
c_temp <<= 1; // 左移一位,为下一个bit腾出位置
if(code_buf[i] == '1')
c_temp |= 1; // 当编码为"1",通过或操作符将其添加到字节的最低位
}
fwrite((char *)&c_temp, sizeof(unsigned char), 1, outfile); // 将字节对应编码存入文件
strcpy(code_buf, code_buf+8); // 编码缓存去除已处理的前八位
}
fread((char *)&c_temp, sizeof(unsigned char), 1, infile); // 每次读取8bits
}
// 处理最后不足8bits编码
code_len = strlen(code_buf);
if(code_len > 0)
{
c_temp = '\0';
for(i = 0; i < code_len; ++i)
{
c_temp <<= 1;
if(code_buf[i] == '1')
c_temp |= 1;
}
c_temp <<= 8-code_len; // 将编码字段从尾部移到字节的高位
fwrite((char *)&c_temp, sizeof(unsigned char), 1, outfile); // 存入最后一个字节
}
// 关闭文件
fclose(infile);
fclose(outfile);
// 释放内存
for(i = 0; i < c_kinds; ++i)
free(huf_tree[i].code);
free(huf_tree);
}
else
{
outfile = fopen(ofname, "wb"); // 打开压缩后将生成的文件
fwrite((char *)&c_kinds, sizeof(unsigned int), 1, outfile); // 写入字符种类
fwrite((char *)&tmp_nodes[0].uch, sizeof(unsigned char), 1, outfile); // 写入唯一的字符
fwrite((char *)&tmp_nodes[0].weight, sizeof(unsigned long), 1, outfile); // 写入字符频度,也就是文件长度
free(tmp_nodes);
fclose(outfile);
}
}
// 解压函数
int extract(char *ifname, char *ofname)
{
unsigned int i;
unsigned long file_len;
unsigned long writen_len = 0; // 控制文件写入长度
FILE *infile, *outfile;
unsigned int char_kinds; // 存储字符种类
unsigned int node_num;
HufTree huf_tree;
unsigned char code_temp; // 暂存8bits编码
unsigned int root; // 保存根节点索引,供匹配编码使用
infile = fopen(ifname, "rb"); // 以二进制方式打开压缩文件
// 判断输入文件是否存在
if (infile == NULL)
return -1;
// 读取压缩文件前端的字符及对应编码,用于重建哈夫曼树
fread((char *)&char_kinds, sizeof(unsigned int), 1, infile); // 读取字符种类数
if (char_kinds == 1)
{
fread((char *)&code_temp, sizeof(unsigned char), 1, infile); // 读取唯一的字符
fread((char *)&file_len, sizeof(unsigned long), 1, infile); // 读取文件长度
outfile = fopen(ofname, "wb"); // 打开压缩后将生成的文件
while (file_len--)
{
fwrite((char *)&code_temp, sizeof(unsigned char), 1, outfile);
}
fclose(infile);
fclose(outfile);
}
else
{
node_num = 2 * char_kinds - 1; // 根据字符种类数,计算建立哈夫曼树所需结点数
huf_tree = (HufNode *)malloc(node_num*sizeof(HufNode)); // 动态分配哈夫曼树结点空间
// 读取字符及对应权重,存入哈夫曼树节点
for(i = 0; i < char_kinds; ++i)
{
fread((char *)&huf_tree[i].uch, sizeof(unsigned char), 1, infile); // 读入字符
fread((char *)&huf_tree[i].weight, sizeof(unsigned long), 1, infile); // 读入字符对应权重
huf_tree[i].parent = 0;
}
// 初始化后node_num-char_kins个结点的parent
for(1; i < node_num; ++i)
huf_tree[i].parent = 0;
CreateTree(huf_tree, char_kinds, node_num); // 重建哈夫曼树(与压缩时的一致)
// 读完字符和权重信息,读取文件长度和编码,进行解码
fread((char *)&file_len, sizeof(unsigned long), 1, infile); // 读入文件长度
outfile = fopen(ofname, "wb"); // 打开压缩后将生成的文件
root = node_num-1;
//计算出根节点编号
while(1)
{
fread((char *)&code_temp, sizeof(unsigned char), 1, infile); // 读取一个字符长度的编码
// 处理读取的一个字符长度的编码(通常为8位)
for(i = 0; i < 8; ++i)
{
// 由根向下直至叶节点正向匹配编码对应字符
if(code_temp & 128)
{
root = huf_tree[root].rchild;
}
else
{
root = huf_tree[root].lchild;
}
if(root < char_kinds)
{
fwrite((char *)&huf_tree[root].uch, sizeof(unsigned char), 1, outfile);
++writen_len;
if (writen_len == file_len)
{
break;
}
// 控制文件长度,跳出内层循环
root = node_num-1; // 复位为根索引,匹配下一个字符
}
code_temp <<= 1; // 将编码缓存的下一位移到最高位,供匹配
}
if (writen_len == file_len)
{
break; // 控制文件长度,跳出外层循环
}
fclose(infile);
fclose(outfile);
//关闭文件
// 释放内存
free(huf_tree);
}
}
}
//打印哈夫曼编码表
int printcode(char *ifname ,char *ofname)
{
unsigned int i, j;
unsigned int char_kinds; // 字符种类
unsigned char char_temp; // 暂存8bits字符
unsigned long file_len = 0;
FILE *infile, *outfile;
TmpNode node_temp;
unsigned int node_num;
HufTree huf_tree;
char code_buf[256] = "\0"; // 待存编码缓冲区
unsigned int code_len;
TmpNode *t_nodes =(TmpNode *)malloc(256*sizeof(TmpNode));
// 初始化暂存结点
for(i = 0; i < 256; ++i)
{
t_nodes[i].weight = 0;
t_nodes[i].uch = (unsigned char)i; // 数组的256个下标与256种字符对应
}
// 遍历文件,获取字符频度
infile = fopen(ifname, "rb");
// 判断输入文件是否存在
if (infile == NULL)
{
return -1; //-1代表文件打开失败或不存在
}
fread((char *)&char_temp, sizeof(unsigned char), 1, infile); // 读入一个字符
while(!feof(infile))
{
++t_nodes[char_temp].weight; // 统计下标对应字符的权重,利用数组的随机访问快速统计字符频度
++file_len;
fread((char *)&char_temp, sizeof(unsigned char), 1, infile); // 读入一个字符
}
fclose(infile);
//关闭文件
// 排序,将频度为零的放最后,剔除
for(i = 0; i < 256-1; ++i)
{
for(j = i+1; j < 256; ++j)
{
if(t_nodes[i].weight < t_nodes[j].weight)
{
node_temp = t_nodes[i];
t_nodes[i] = t_nodes[j];
t_nodes[j] = node_temp;
}
}
} //冒泡排序
// 统计实际的字符种类(出现次数不为0)
for(i = 0; i < 256; ++i)
if(t_nodes[i].weight == 0)
break;
char_kinds = i;
if (char_kinds == 1)
{
outfile = fopen(ofname, "wb"); // 打开压缩后将生成的文件
fwrite((char *)&char_kinds, sizeof(unsigned int), 1, outfile); // 写入字符种类
fwrite((char *)&t_nodes[0].uch, sizeof(unsigned char), 1, outfile); // 写入唯一的字符
fwrite((char *)&t_nodes[0].weight, sizeof(unsigned long), 1, outfile); // 写入字符频度,也就是文件长度
free(t_nodes);//释放内存
fclose(outfile);//关闭文件
}
else
{
node_num = 2 * char_kinds - 1; // 根据字符种类数,计算建立哈夫曼树所需结点数
huf_tree = (HufNode *)malloc(node_num*sizeof(HufNode)); // 动态建立哈夫曼树所需结点
// 初始化前char_kinds个结点
for(i = 0; i < char_kinds; ++i)
{
// 将暂存结点的字符和频度拷贝到树结点
huf_tree[i].uch = t_nodes[i].uch;
huf_tree[i].weight = t_nodes[i].weight;
huf_tree[i].parent = 0;
}
free(t_nodes); // 释放字符频度统计的暂存区
// 初始化后node_num-char_kins个结点
for(; i < node_num; ++i)
{
huf_tree[i].parent = 0;
}
//初始化结点的父节点
CreateTree(huf_tree, char_kinds, node_num); // 创建哈夫曼树
HufCode(huf_tree, char_kinds); // 生成哈夫曼编码
for(i=0;i<node_num;i++)
{
printf("%c %s\n",huf_tree[i].uch,huf_tree[i].code);
}
// 关闭文件
fclose(infile);
fclose(outfile);
// 释放内存
for(i = 0; i < char_kinds; ++i)
free(huf_tree[i].code);
free(huf_tree);
}
}
//WPL
int length(char str[])
{
int i,len=0;
for(i=0;str[i]!='\0';i++)
{
len++;
}
return len-1;
}
//求出每个结点的哈夫曼编码,编码的长度就是这个节点位于哈夫曼树的第几层
int wpl(char *ifname ,char *ofname)
{
int p,a,b;
a=b=1;
unsigned int i, j;
unsigned int char_kinds; // 字符种类
unsigned char char_temp; // 暂存8bits字符
unsigned long file_len = 0;
FILE *infile, *outfile;
TmpNode node_temp;
unsigned int node_num;
HufTree huf_tree;
char code_buf[256] = "\0"; // 待存编码缓冲区
unsigned int code_len;
/*
** 动态分配256个结点,暂存字符频度,
** 统计并拷贝到树结点后立即释放
*/
TmpNode *tmp_nodes =(TmpNode *)malloc(256*sizeof(TmpNode));
// 初始化暂存结点
for(i = 0; i < 256; ++i)
{
tmp_nodes[i].weight = 0;
tmp_nodes[i].uch = (unsigned char)i; // 数组的256个下标与256种字符对应
}
// 遍历文件,获取字符频度
infile = fopen(ifname, "rb");
// 判断输入文件是否存在
if (infile == NULL)
return -1;
fread((char *)&char_temp, sizeof(unsigned char), 1, infile); // 读入一个字符
while(!feof(infile))
{
++tmp_nodes[char_temp].weight; // 统计下标对应字符的权重,利用数组的随机访问快速统计字符频度
++file_len;
fread((char *)&char_temp, sizeof(unsigned char), 1, infile); // 读入一个字符
}
fclose(infile);
// 排序,将频度为零的放最后,剔除
for(i = 0; i < 256-1; ++i)
for(j = i+1; j < 256; ++j)
if(tmp_nodes[i].weight < tmp_nodes[j].weight)
{
node_temp = tmp_nodes[i];
tmp_nodes[i] = tmp_nodes[j];
tmp_nodes[j] = node_temp;
}
// 统计实际的字符种类(出现次数不为0)
for(i = 0; i < 256; ++i)
if(tmp_nodes[i].weight == 0)
break;
char_kinds = i;
if (char_kinds == 1)
{
outfile = fopen(ofname, "wb"); // 打开压缩后将生成的文件
fwrite((char *)&char_kinds, sizeof(unsigned int), 1, outfile); // 写入字符种类
fwrite((char *)&tmp_nodes[0].uch, sizeof(unsigned char), 1, outfile); // 写入唯一的字符
fwrite((char *)&tmp_nodes[0].weight, sizeof(unsigned long), 1, outfile); // 写入字符频度,也就是文件长度
free(tmp_nodes);
fclose(outfile);
}
else
{
node_num = 2 * char_kinds - 1; // 根据字符种类数,计算建立哈夫曼树所需结点数
huf_tree = (HufNode *)malloc(node_num*sizeof(HufNode)); // 动态建立哈夫曼树所需结点
// 初始化前char_kinds个结点
for(i = 0; i < char_kinds; ++i)
{
// 将暂存结点的字符和频度拷贝到树结点
huf_tree[i].uch = tmp_nodes[i].uch;
huf_tree[i].weight = tmp_nodes[i].weight;
huf_tree[i].parent = 0;
}
free(tmp_nodes); // 释放字符频度统计的暂存区
// 初始化后node_num-char_kins个结点
for(; i < node_num; ++i)
huf_tree[i].parent = 0;
CreateTree(huf_tree, char_kinds, node_num); // 创建哈夫曼树
HufCode(huf_tree, char_kinds); // 生成哈夫曼编码
//因为是动态分配内存所以每一步都需要重新压缩,生成哈夫曼编码
int mix=0,temp;
for(i=0;i<=83;i++)
{
a=(int)huf_tree[i].weight;
b=length(huf_tree[i].code);
a=a*b;
mix=mix+a;
if(i==83)
{
printf(" WPL = %d\n",mix); //求出WPL
}
}
return 0;
}
}
//求文件大小
//调用了sys/stat.h头文件来求文件大小
int file_size(char* filename)//获取文件名为filename的文件大小。
{
struct stat statbuf;
int r;
r = stat(filename,&statbuf);//调用stat函数
if(r != 0) return -1;//获取失败。
return statbuf.st_size;//返回文件大小。
}
int main()
{
while(1)
{
int opt, flag = 0; // 每次进入循环都要初始化flag为0
char ifname[256], ofname[256]; // 保存输入输出文件名
int *w1;
int size1=0;//源文件大小
int size2=0;//压缩文件大小
float ratio=0;//压缩比
printf("---------------------------------------------------------------------------\n") ;
printf(" Please input the number of operations: \n") ;
printf(" 1: compress\n") ;
printf(" 2: extract\n") ;
printf(" 3: Print \n") ;
printf(" 4: WPL\n") ;
printf(" 5: hufcode\n") ;
printf(" 6: compression ratio\n") ;
printf(" 7: quit\n") ;
printf("---------------------------------------------------------------------------\n") ;
scanf("%d", &opt);
if (opt == 7)
break;
switch(opt)
{
case 1:
printf("Please input the infile name: ");
fflush(stdin); // 清空标准输入流,防止干扰gets函数读取文件名
gets(ifname);
printf("Please input the outfile name: ");
fflush(stdin);
gets(ofname);
printf("Compressing……\n");
flag = compress(ifname, ofname); // 压缩,返回值用于判断是否文件名不存在
break;
case 2:
printf("Please input the infile name: ");
fflush(stdin); // 清空标准输入流,防止干扰gets函数读取文件名
gets(ifname);
printf("Please input the outfile name: ");
fflush(stdin);
gets(ofname);
printf("Extracting……\n");
flag = extract(ifname, ofname); // 解压,返回值用于判断是否文件名不存在
break;
case 3:
printf("Please input the infile name: ");
fflush(stdin); // 清空标准输入流,防止干扰gets函数读取文件名
gets(ifname);
printf("Please input the outfile name: ");
fflush(stdin);
gets(ofname);
flag = compress(ifname, ofname); // 压缩,返回值用于判断是否文件名不存在
printTree(ifname,ofname) ;//打印哈夫曼树
break;
case 4:
printf("Please input the infile name: ");
fflush(stdin); // 清空标准输入流,防止干扰gets函数读取文件名
gets(ifname);
printf("Please input the outfile name: ");
fflush(stdin);
gets(ofname);
flag = compress(ifname, ofname); // 压缩,返回值用于判断是否文件名不存在
wpl(ifname,ofname);//求WPL
break;
case 5:
printf("Please input the infile name: ");
fflush(stdin); // 清空标准输入流,防止干扰gets函数读取文件名
gets(ifname);
printf("Please input the outfile name: ");
fflush(stdin);
gets(ofname);
flag = compress(ifname, ofname); // 压缩,返回值用于判断是否文件名不存在
printcode(ifname,ofname);//打印哈夫曼编码
break;
case 6:
printf("Please input the infile name: ");
fflush(stdin); // 清空标准输入流,防止干扰gets函数读取文件名
gets(ifname);
printf("Please input the outfile name: ");
fflush(stdin);
gets(ofname);
flag = compress(ifname, ofname); // 压缩,返回值用于判断是否文件名不存在
size1=file_size(ifname);//求原文件大小
printf("Source file size = %d\n",size1);
size2=file_size(ofname);//求压缩后文件大小
printf("Compressed flie size = %d\n",size2);
ratio=(float)size2/(float)size1;//压缩比
printf("the compress ratio is %f\n",ratio);
break;
}
if (flag == -1)
{
printf("Sorry, infile \"%s\" doesn't exist!\n", ifname);
}
// 如果标志为-1则输入文件不存在
else
{
printf("Operation is done!\n");
}
// 操作完成
}
return 0;
}















 1716
1716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









