









 本文探讨了机器学习中的过拟合与欠拟合现象,解释了这两种情况的特点及影响,并提出了几种解决方法,包括减少特征数量、使用正则化等技术。
本文探讨了机器学习中的过拟合与欠拟合现象,解释了这两种情况的特点及影响,并提出了几种解决方法,包括减少特征数量、使用正则化等技术。
过拟合(Overfitting)与欠拟合(Underfitting)
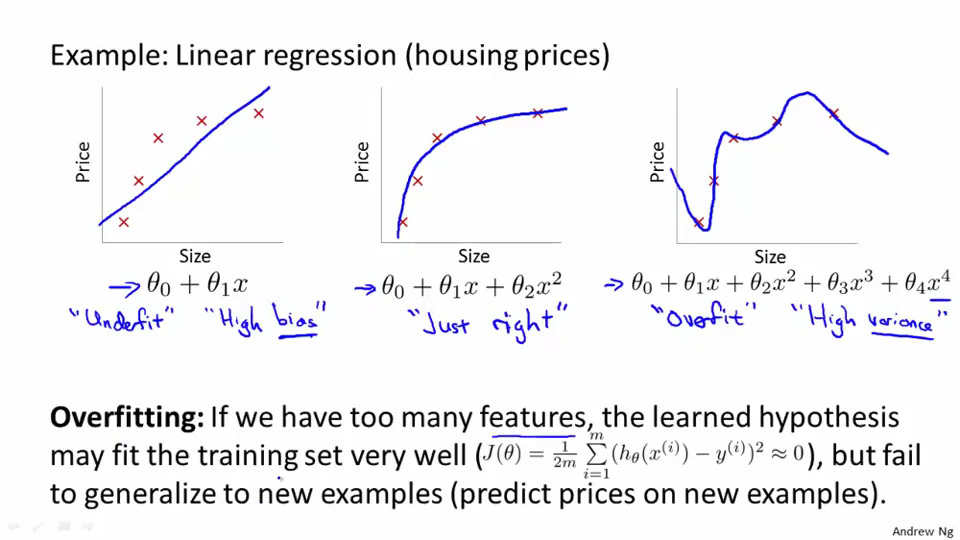
欠拟合
一个模型不能很好的拟合数据,或者说有很强的偏向,或者说有很大的偏差(High bias)
此时我们不能很好的预测新样本数据
过拟合
特点:J(θ)≈0
一个模型过于拟合训练数据,或者说有很高的方差(High varionce).
这种情况可能也会造成函数过大,变量过多的情况
小结
我们需要更为准确的预测,一组数据不可能代表所有的可能性.
所以我们需要泛化(generalize)模型来预测新的样本数据.
解决
- 减少特征
- 人工删除
- 模型选择算法
- 正则化(Regularization)
- 保留所有特征但是减少θJ的数量级或者大小.
- 其中每一个都为预测y贡献一点点
代价函数
对于正则化来,说我们通过改变代价函数来约束参数的大小,从而改变该特征对模型影响的大小来使模型更为简单.举个栗子:
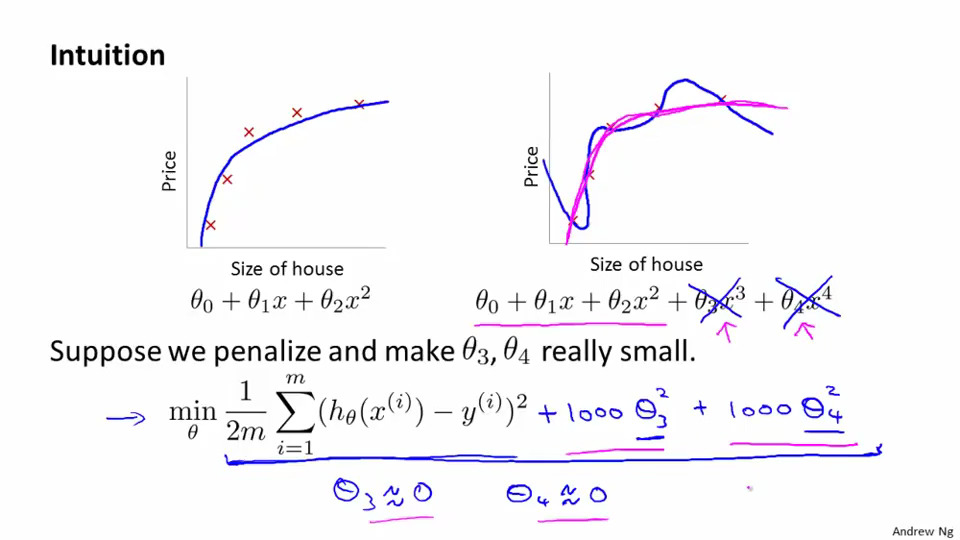
在这个栗子中,由于costFunction,
我们将这种代价函数一般化:
J(θ)=12m[∑i=1m(hθ(x(i))−y(i))+λ∑j=1nθ2j]
首先这个代价函数有两个目标:
1. 匹配训练集
2. 保持参数尽可能小
其中λ∑nj=1θ2j叫做正则化参数(regularization parameter)也就是我们常说的模型的偏见,用于第二个目标
λ用于平衡两个目标之间的平衡.
如果λ过大会欠拟合,过小会过拟合.
注意:通常不会正则化theta0,虽然影响不大.
梯度下降
那么通过上面代价函数的修改,梯度下降则变为:
repeatuntilconvergence{θ0:=θ0−α1m∑i=1m(hθ(x(i))−y(i))x(i)0θj:=θj(1−αλm)−α1m∑i=1m(hθ(x(i))−y(i))x(i)j(j=1,2,...,n)}
一般的(1−αλm)<1,一般小于1一点点.
正则方程
我们在线性回归中介绍了正则方程.
在这里我们也可以用来计算正则方程参数.
下面是线性回归中无偏向的正则方程:
X(design matrix)=⎡⎣⎢⎢⎢(x(1))T⋮(x(n))T⎤⎦⎥⎥⎥
θ=(XTX)−1XTy
那么加上偏好
θ=(XTX+λ⎡⎣⎢⎢⎢⎢⎢⎢⎢000⋮0010⋮0001⋮0⋯⋯⋯⋱0001⎤⎦⎥⎥⎥⎥⎥⎥⎥)−1XTy
其中矩阵大小为(n+1)∗(n+1)
可逆矩阵
可以证明:只要λ>0那么存在上述矩阵.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









