






50、File类:
(1)文件操作:


(2)目录操作:

(3)获取文件信息:

(4)获取目录信息:

(5)文件更名:
File类中有一个public boolean renameTo(File dest)的方法可以 实现文件名称的修改,并且也可以实现文件位置的移动
51、输入输出流:
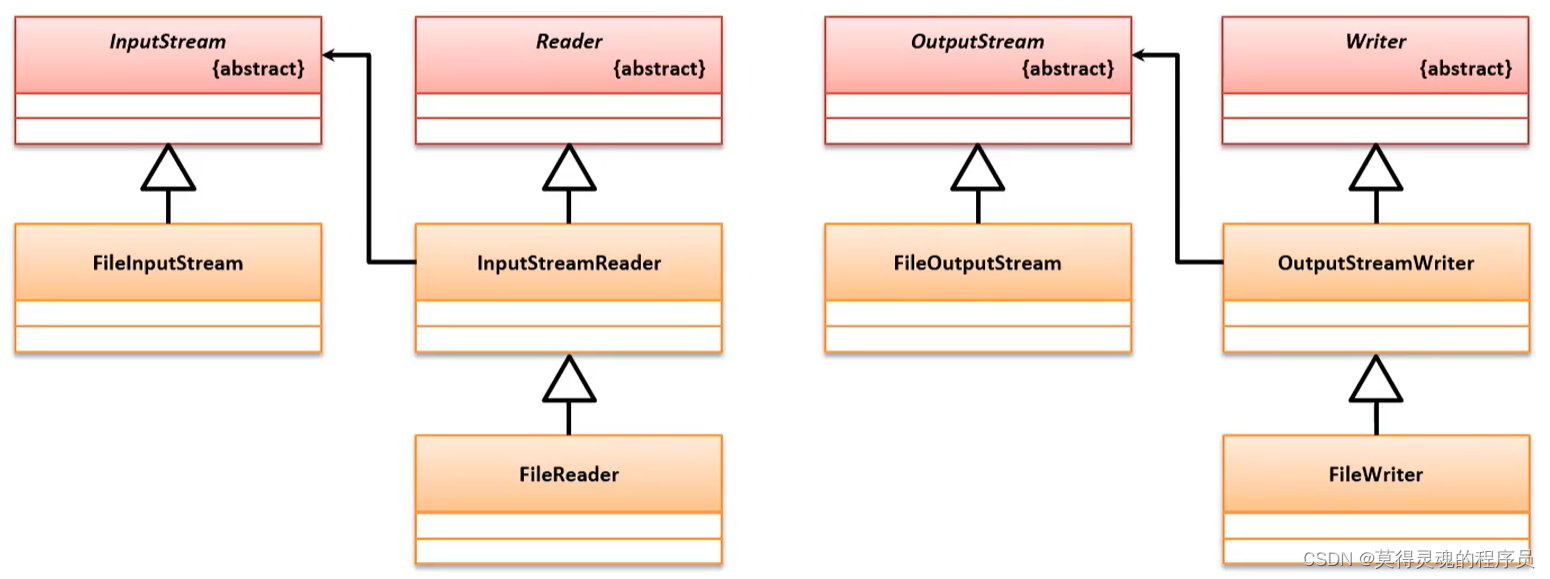
(1)OutputStream:

(a)FileOutputStream:

(2)InputStream:
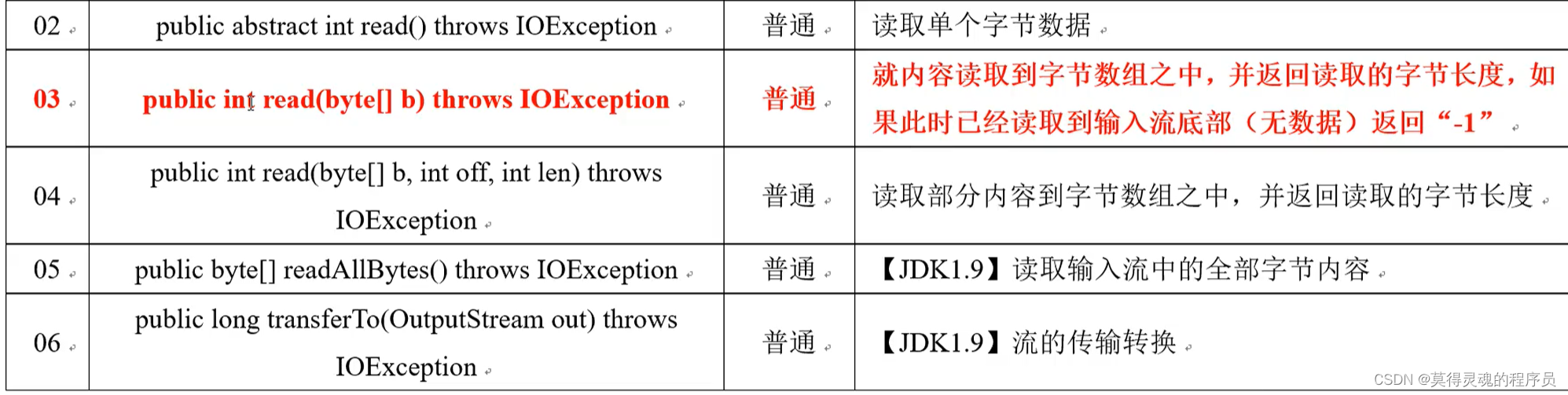
(3)Writer:


(4)Reader:
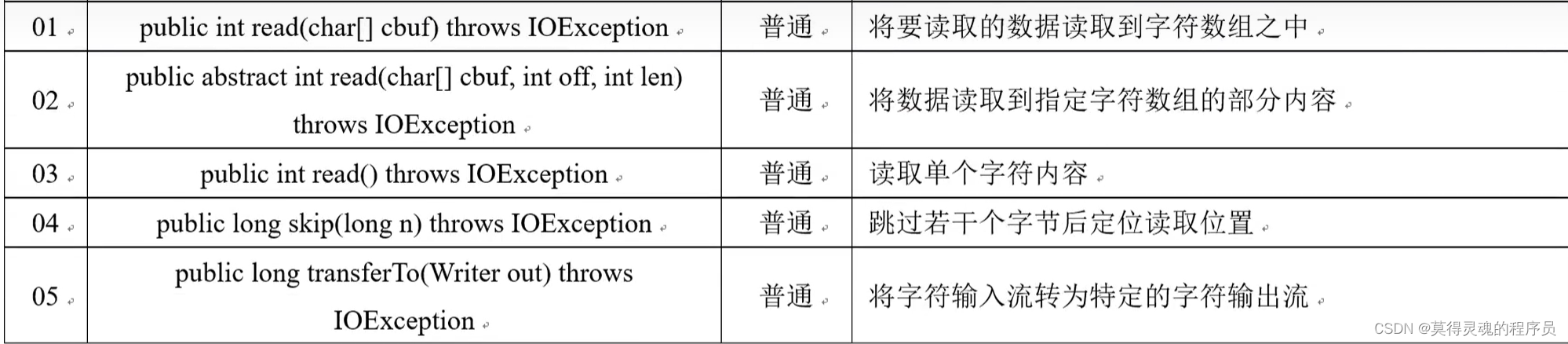
(5)字节流和字符流的区别:
如果使用的是字节流,即使没有关闭流,文件中也依然有数据
如果使用的是字符流,如果没有关闭流,那么文件中不会有数据,数据还在内存的缓冲区中,除非此时追加的数据很大,内存存不下了,或者使用flush()方法强制性刷新缓冲区,这时文件中才会有数据。原因:因为磁盘存储数据只能是字节,所以此时需要在内存中将字符数据转换为字节数据才能够存储
close()方法会强制性刷新内存缓冲区
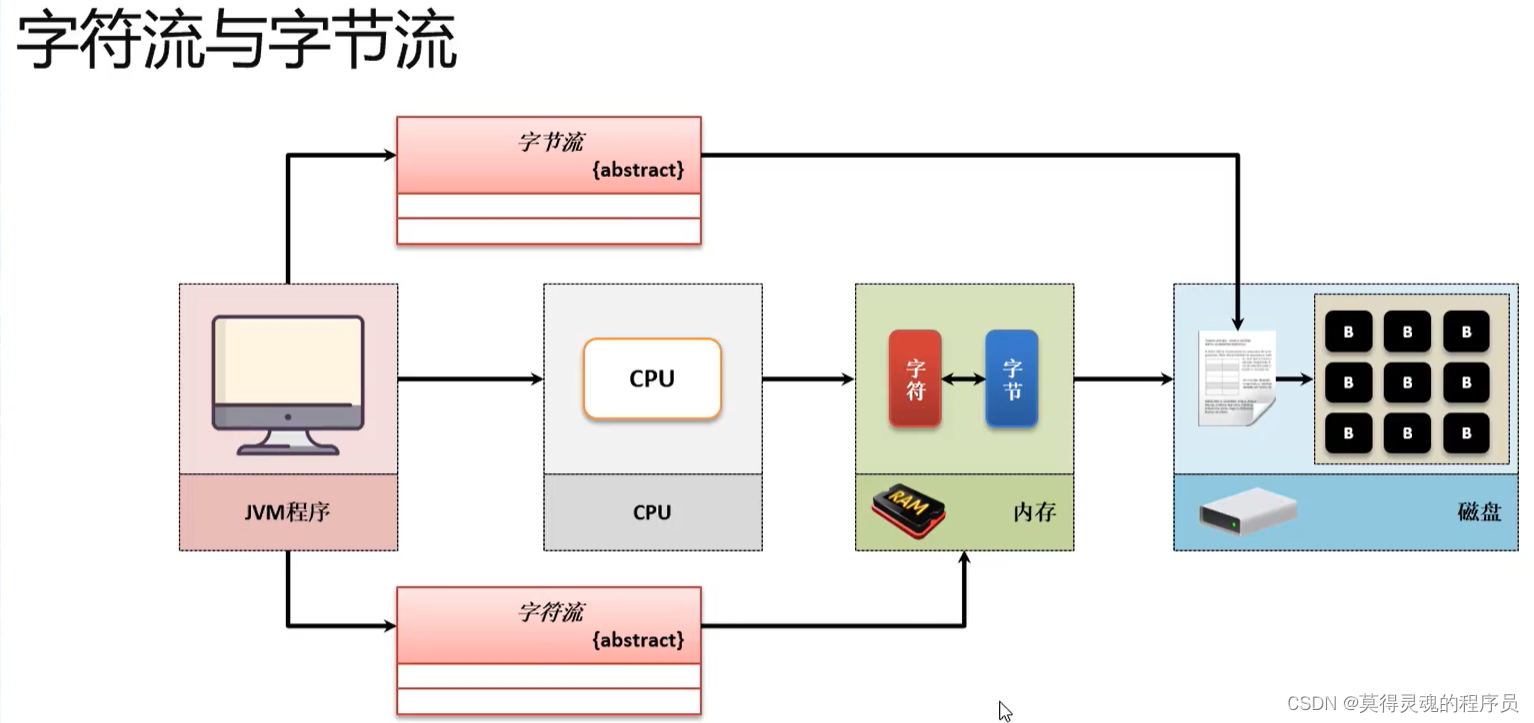
52、转换流:
转换流是将字节流转换为字符流:因为字符流更适合中文的操作
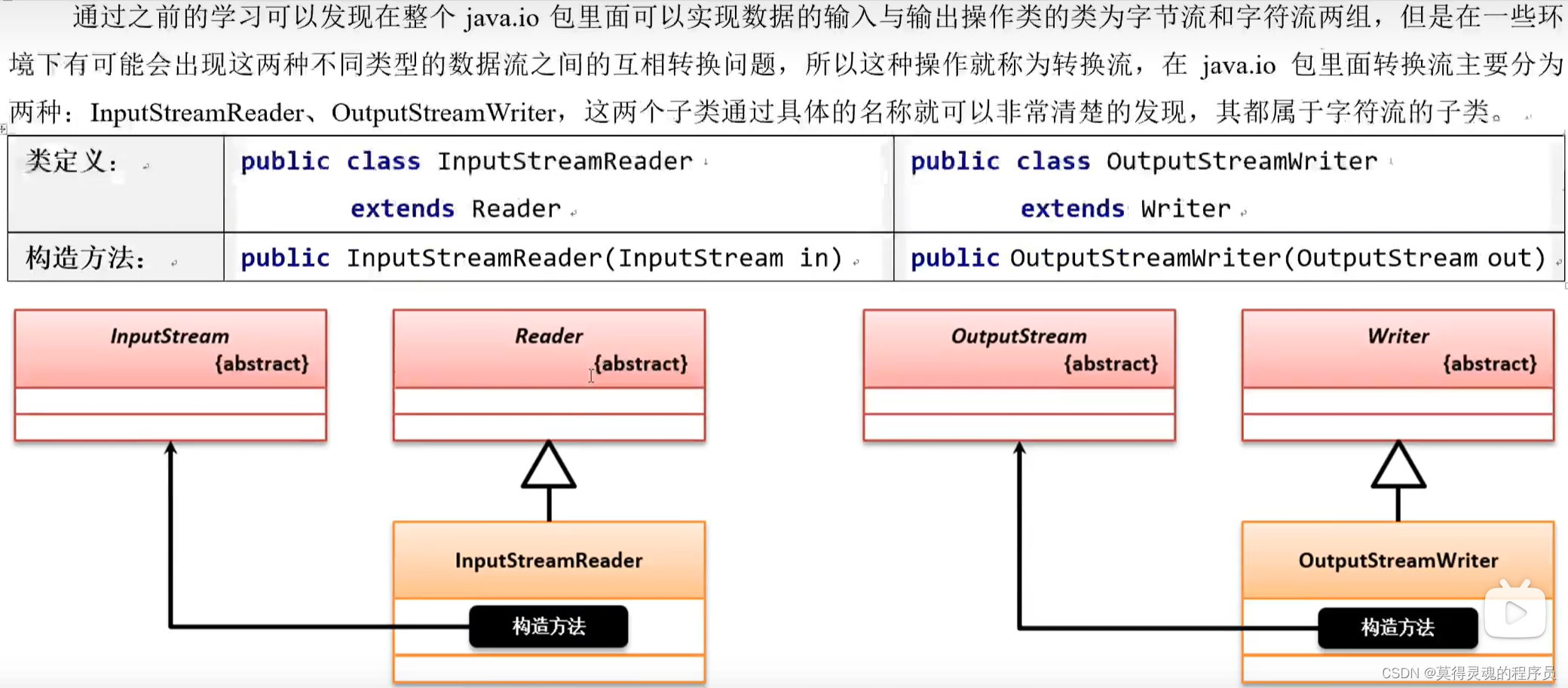
53、字符编码:

54、内存流:
内存流有字节内存流和字符内存流
特别注意:内存流的构造方法是接收一个字节数组,而之前的流是接收一个文件类
内存输出流中有一个方法toByteArray(),这个方法可以将缓存在内存中的字节数据一次性读出。在JDK1.9以后,字节数输出流(InputStream)中提供有一个读取全部数据的方法可以实现类似的效果

55、管道流:
管道流也分为字节管道流和字符管道流
管道流存在的意义在于可以实现不同进程之间的数据交互,也可以实现线程之间的数据交互,但是如果是线程之间的信息交互可以直接通过所在进程来实现

56、打印流:
注意:在JDK1.5之后除了String类追加有格式化字符串的处理支持之外,在PrintWriter/PrintStream类中也提供有一个格式化的信息输出
printf() 这个方法可以采用占位符标记实现输出管理(%d、%s等)

57、System类对IO的支持:
注意:打印流中PrintWriter比PrinterSteam要好用,但是System类并没有与PrintWriter所整合,原因在于,System类与PrintSteam类是JDK1.0出来的,而PrinterWriter类是JDK1.1的时候出来的
System类中拥有 in(表示标准的键盘输入)、out(表示进行正确的信息输出)、err(表示错误的信息输出) 三个 常量,而这三个常量对应了各自的输入输出流(由JVM进行对象实例化)
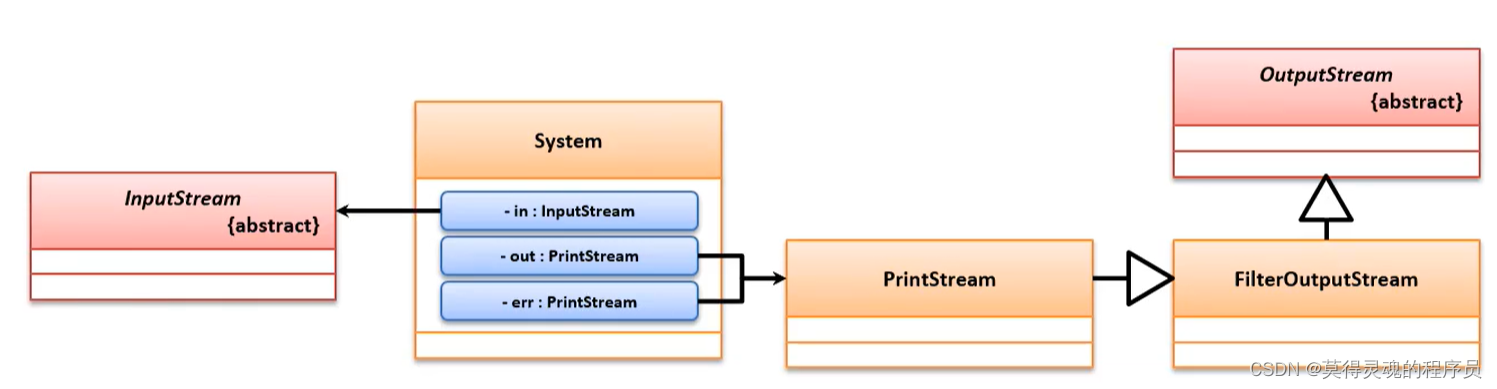
注意:为什么对象输出的时候会直接调用类中的toString()方法?

58、缓冲输入流(JDK1.1):
在实际的项目开发中,如果直接使用InputStream或者Reader类实现内容读取的时候必须将其所有要读的数据保存在数组之中才可以正常实现功能,但是这样的处理操作过于繁琐,所以此时可以考虑将所有读取到的内容暂时放到一个缓冲区之中,这样在需要的时候一次性读取全部的内容,这样就避免了繁琐的数组操作,而BufferedReader类可以实现此功能

中间通过了转换流将Reader与InputStream联系起来
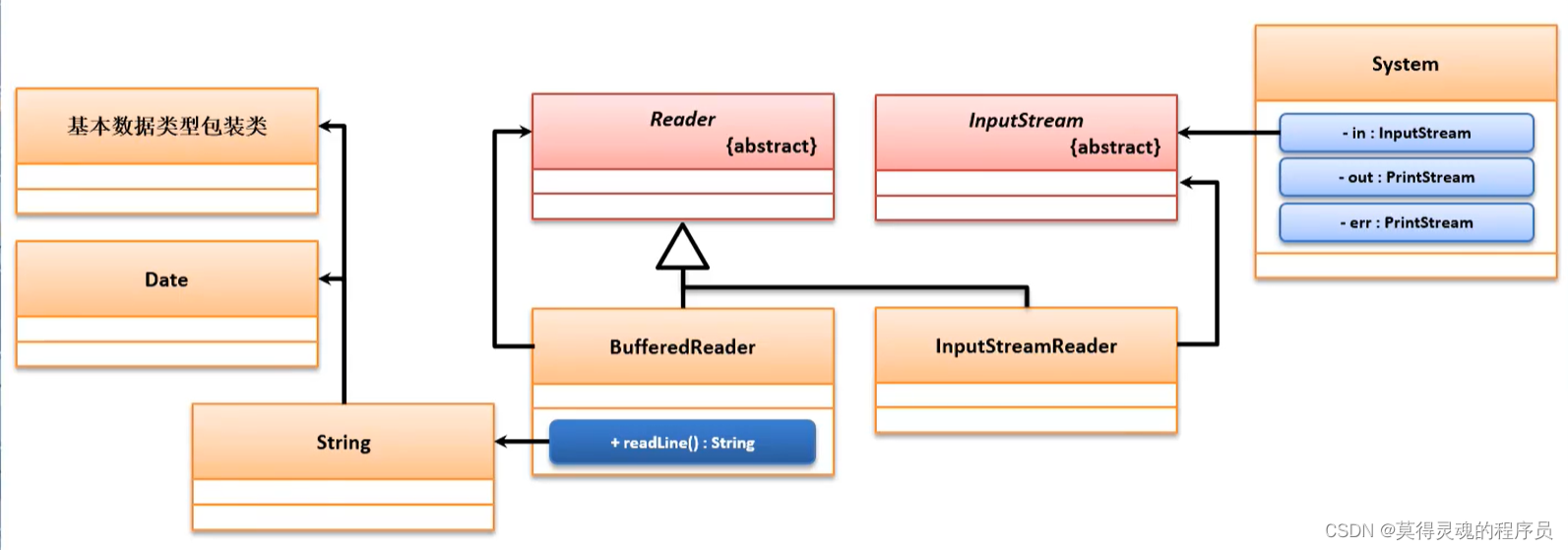
59、Scanner工具类(JDK1.5):
进行数据输入的时候,使用InputStream类实现非常麻烦,因为都需要通过字节的形式来进行处理,而通过BufferedReader类处理虽然方便,但是却只能够使用”\n"作为读取的分隔符,所以JDK1.5之后提供了java.util.Scanner工具类
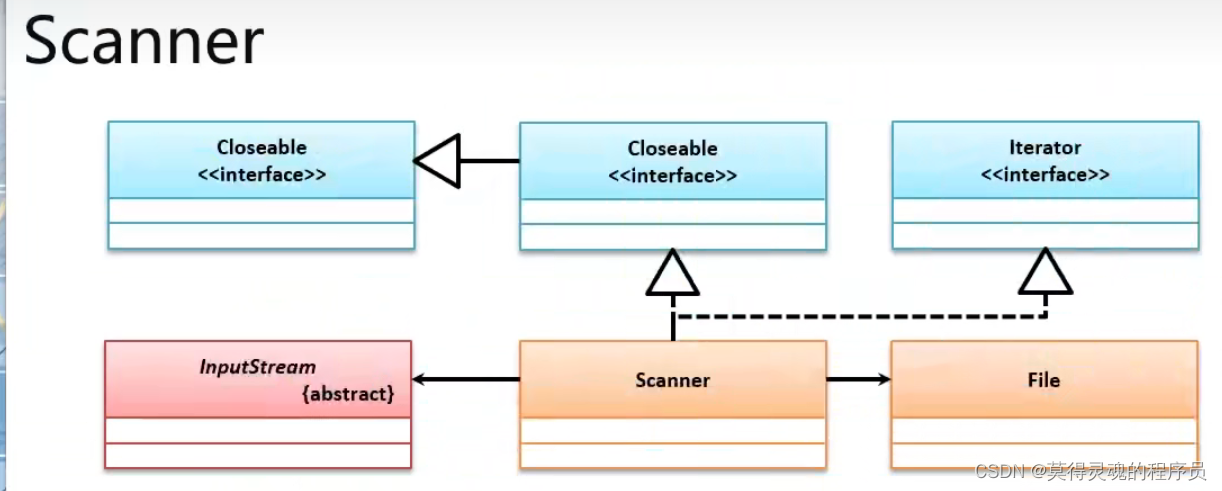
next()方法接收的数据,以空字符作为分隔符:空格,制表符,换行


60、序列化:
Serializable接口与Clonable接口一样,没有定义方法,只是一个标识作用
(1)实现序列化与反序列化的类:

(2)transient关键字:作用:使用此关键字定义的属性不会被序列化
在java中对于序列化的处理有两种机制:全自动序列化管理(ObjectOutputStream,ObjectInputStream),另外一种是手工实现序列化的管理,在手工实现的序列化操作中,就可以自己来决定哪些属性不要被序列化,但是开发难度较高,所以才针对自动序列化的处理提供transient关键字
61、网络编程:
TCP程序:使用三次握手和四次挥手的方式保证所有的数据可靠的进行传输
UDP程序:发送数据报,而接收数据报的一方不一定可以接收到信息

(1)java.net包:
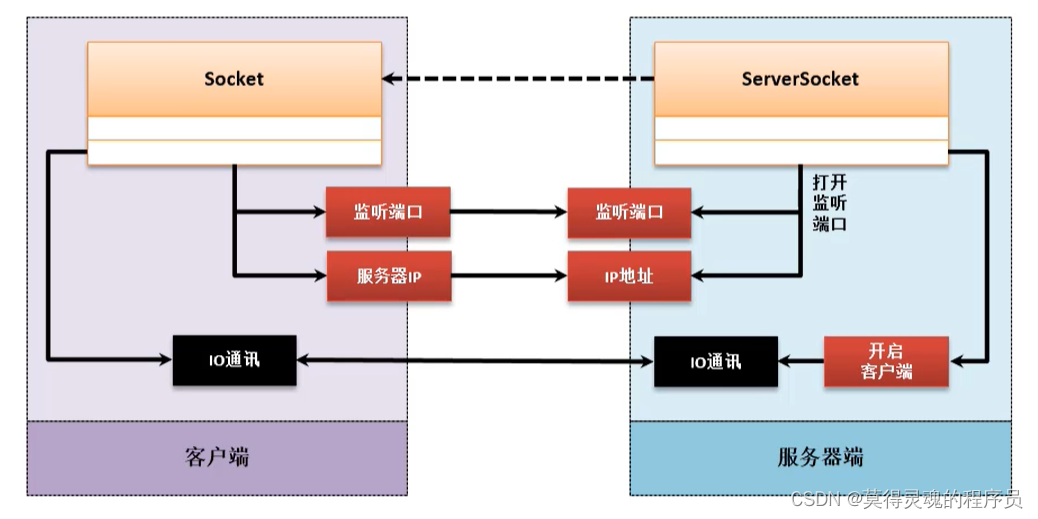
服务端通过ServerSockert类的构造方法绑定端口,再通过accept()方法等待客户端连接
客户端通过Socket类的构造方法绑定IP地址以及端口,然后Socket类可以通过方法获取输入输出流对象

这个网络通信是基于TCP协议的,处理流程如下:
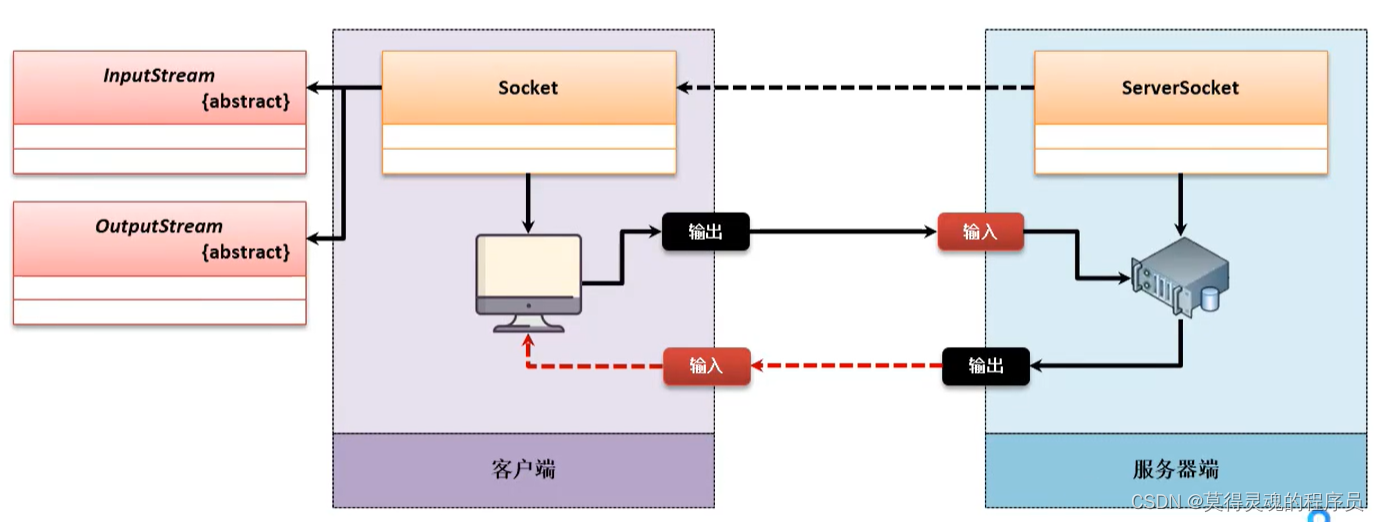
(2)Echo程序模型:
Echo模型最大的特点在于:客户端发送数据给服务器,服务器端接收到此数据之后直接进行回应,并且这种回应的处理可以持续进行,当客户确定不再需要继续进行交互的时候则断开整个的服务器连接
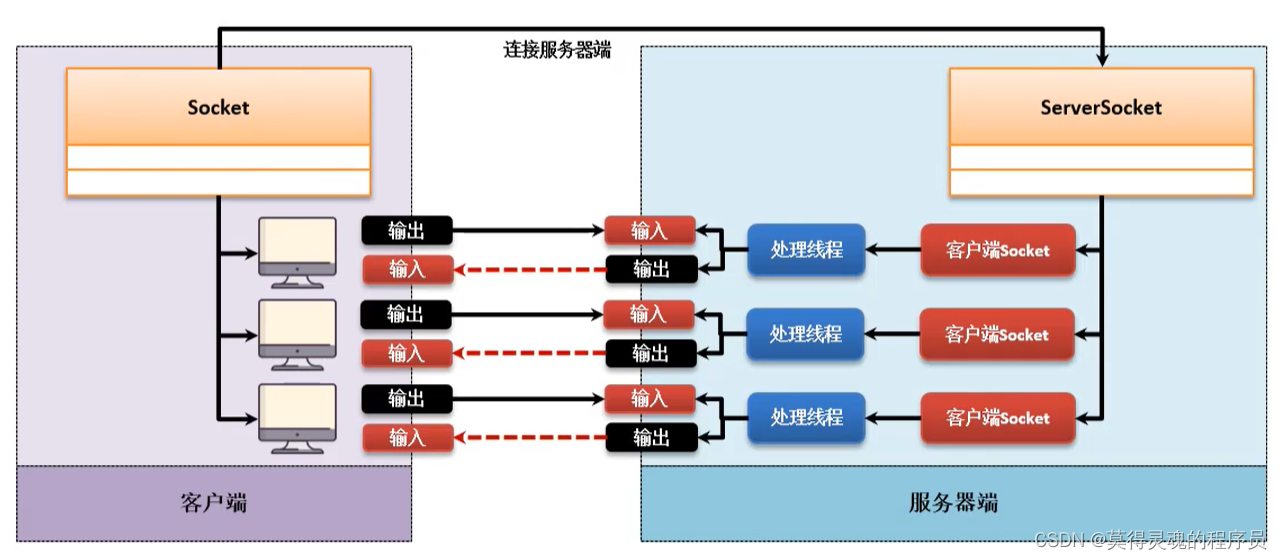
(3)BIO程序模型:
步骤:|- 创建一个多线程客户端处理类,接收客户端Socket对象,通过Socket对象获得输入输出流进行交互
|- 服务端通过while循环不断的接收等待连接的Socket,并将其传入多线程客户端处理类,开启处理线程
BIO(Blocking IO 、阻塞IO处理)是最为传统的一种网络通讯模型的统一描述,这种模型主要是为了解决服务器的并发处理问题,通过之前的程序已经成功的实现了一个ECHO交互模型,但是这个模型本身存在有一个问题:当前的操作属于单线程服务器的开发,同一时间段只能够有一个线程进行访问
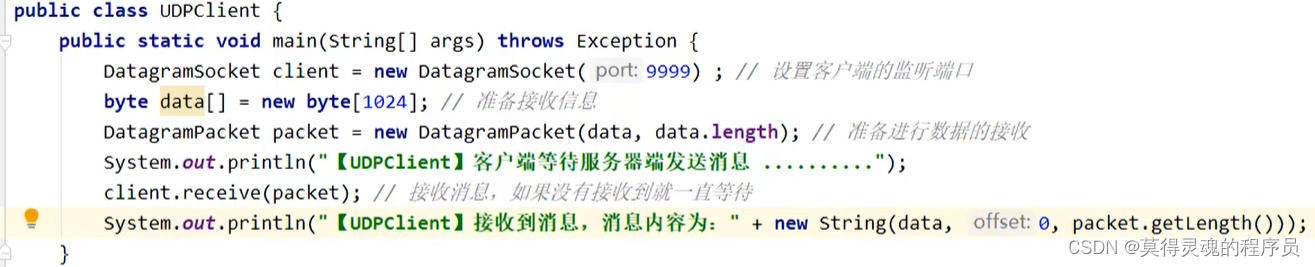
(4)UDP程序:
客户端使用DatagramSocket类构造设置客户端监听端口,然后创建数据报对象DatagramPacket,最后使用DatagramSocket对象的receive()方法进行接收服务器端数据报
















 1550
1550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









