






hadoop
判断map task处理的数据量:一个map task 对应一个split,split大小由split max、split min、block size决定,一般取中间值block size,map task数*128M(hadoop默认block size大小)。
apark
One stack rule them all
Ad-hoc Queries :体现在Spark SQL
Batch Processing:体现在Spark Core
String Processing :体现在Spark Streaming

spark运行模式:
1. local(用于测试)
2. standalone
3. Mesos
4. Hadoop(YARN)
Spark的基础:RDD(弹性分布式数据集)
RDD创建方式以下四种:
1. 从Hadoop文件系统(HDFS、Hive、HBase)输入创建;
textFile() 方法可以将本地文件或者HDFS文件转换成RDD;
wholeTextFile() 读取目录里面的小文件,返回(文件名,内容)对;
sequenceFile[K,V]() 方法可以将sequenceFile转换成RDD;
hadoopRDD() 方法可以将其他任何Hadoop的输入类型转化成RDD。
scala> var rdd = sc.textFile("hdfs:///tmp/lxw1234/1.txt") 2. 由父RDD转换得到新的RDD;
3. 通过parallelize或者makeRDD将单机数据创建为分布式RDD;
scala> var rdd = sc.parallelize(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at :21
scala> rdd.collect
res3: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> rdd.partitions.size
res4: Int = 15
//设置RDD为3个分区
scala> var rdd2 = sc.parallelize(1 to 10,3)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at :21
scala> rdd2.collect
res5: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> rdd2.partitions.size
res6: Int = 3 4. 基于DB(oracle)、NoSQL(HBase)、S3(SC3)、数据流 创建。
Spark涉及的基本概念:
Application:Spark的应用程序,用户提交后,Spark为App分配资源,将程序转换并执行,其中Application包含一个Drive Program和若干个Executor。
Driver Progream: 运行Application的main()函数,并创建SparkContext。
SparkContext:Spark程序的入口,负责调度各个运算资源,协调各个worker Node上的Executor。
RDD Graph:RDD是Spark的核心结构,可以通过一系列算子进行操作(主要有Transformation和Action操作)。当RDD遇到Action算子时,将之前所有的算子形成一个有向无形环(DAG),再在Spark中转化为Job,提交到集群执行。一个App中可以包含多个Job。
Executor:是为Application在Worker Node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘中。每个Application都会申请各自的Executor来处理任务。
Work Node:集群中任何可以运行Application代码的节点,运行一个或多个Executor进程。
Spark组件:
Job:一个RDD Graph触发的作业,往往由Spark Action触发算子,在SparkContext中通过runJob方法想Spark提交Job。
Stage:每个Job会根据RDD的依赖关系被切分为很多歌Stage,每个Stage中会包含一组相投的Task,这一组Task也叫TaskSet
Task:一个分区对应一个Task,Task执行RDD中对应的Stage包含的算子,Task被封装好后放入Exector的线程池中执行。
DAGScheduler:根据Job构建基于Stage的DAG,并提交Stage给TaskSheduler。
TaskScheduler:将TaskSet提交给worker Node集群并返回结果。

整体流程:
client提交应用,Master找到一个Worker启动Driver,Driver像Master资源管理器申请资源,之后将应用转化为RDD Graph,再由DAGScheduler将RDD Graph转化为Stage的有向无形环,提交给TaskScheduler,有TaskScheduler提交任务给Exector执行。
Spark Runtime

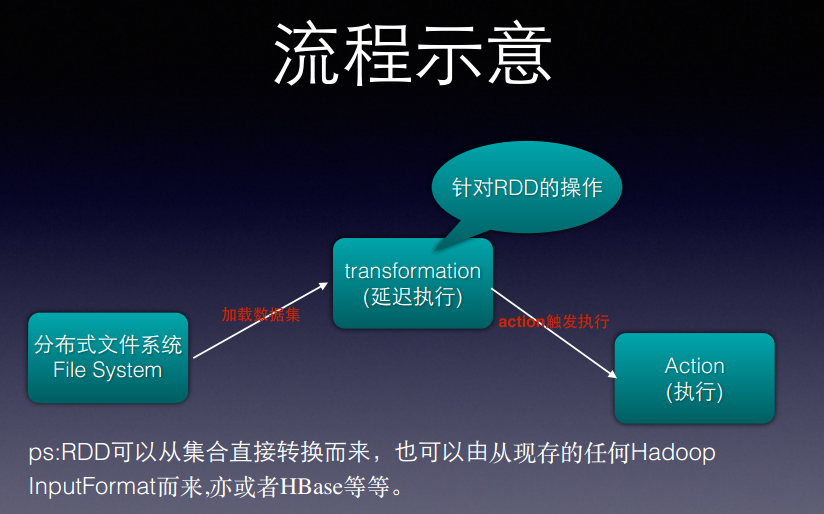
两种执行方式:
1. File System --transformation转换-> Action执行(延迟执行)
transformation是针对RDD的操作,但是并不是真正执行,而是延迟执行,到Action中才会真正执行。
2. File System --SparkContext.p**-->
RDD可以直接从集合转换而来,也可以其他任何数据源过来。














 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









