







文章目录
Elasticsearch介绍
官网:https://www.elastic.co/cn/
简称: ES
Elasticsearch 是一个开源的分布式搜索分析引擎,建立在一个全文搜索引擎库 Apache Lucene基础之上;
Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎;
一个分布式的实时文档存储,每个字段 可以被索引与搜索;
一个分布式实时分析搜索引擎;
能承受上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据。
Elasticsearch应用场景
信息检索
日志分析
业务数据分析
数据库加速
运维指标监控
安装配置
安装包下载:https://elasticsearch.cn/download/
因为Elasticsearch是用java开发的,所以运行还需要jdk,所以还需要下载:jdk-7u80-linux-x64.tar.gz
但是在7.6以上的版本里,已经集成里jgdk 的安装包,所以直接安装Elasticsearch就可以。
官网的下载很慢可以使用华为开源镜像下载站下载:https://mirrors.huaweicloud.com/elasticsearch/
[root@server1 ~]# rpm -ivh elasticsearch-7.6.1-x86_64.rpm
安装完成后因为自带jdk所以不需要担心依赖性的问题,然后可以在/etc/elasticsearch有一个jvm.options的文件,这里面有锁定服务开启是使用的内存量,默认是1G,所以如果要注意到你的主机内存,如果可用内存过低,服务是无法启动的,Xmx设置不超过物理RAM的50%,以确保有足够的物理RAM留给内核文件系统缓存,但不要超过32G。
[root@server1 ~]# vim /etc/elasticsearch/jvm.options
-Xms1g
-Xmx1g
配置集群信息
Elasticsearch在单主机上可以直接使用,但是为了效果这里我配置集群去使用,如果是单机就不需要开启集群相关的配置
然后去配置主配置文件
[root@server1 ~]# vim /etc/elasticsearch/elasticsearch.yml
17 cluster.name: my-app #编写集群名称,自定义
23 node.name: server1 #设置本机的主机名,集群配置要配置所有节点上的解析
33 path.data: /var/lib/elasticsearch #默认的数据储存目录
37 path.logs: /var/log/elasticsearch #默认的日志储存目录
43 #bootstrap.memory_lock: true #内存锁定功能开启或关闭,如果主机内存不是很多,不要打开,否则服务无法启动
55 network.host: 172.25.254.1 #主机ip
59 http.port: 9200 #http访问的端口
72 cluster.initial_master_nodes: ["server1"] #集群内主机名整合,目前只有一个节点,后面可以继续添加集群节点
还需要在/etc/security/limits.conf 文件进行设定修改系统限制
在文件的最后进行添加
[root@server1 ~]# vim /etc/security/limits.conf
elasticsearch - nofile 65536 #设置最大文件数
elasticsearch - nproc 4096 #设置最大进程数
elasticsearch soft memlock unlimited #软件内存锁定
elasticsearch hard memlock unlimited #硬件内存锁定
修改systemd启动文件,在service语句块下添加
[root@server1 ~]# vim /usr/lib/systemd/system/elasticsearch.service
LimitNOFILE=65535
LimitMEMLOCK=infinity #添加内存锁定
# Specifies the maximum number of processes
LimitNPROC=4096 #这个数字就是/etc/security/limits.conf里设置的nproc 4096
修改swap的使用优先级,使它尽量少用或不用 !!!
[root@server1 ~]# echo 0 > /proc/sys/vm/swappiness
[root@server1 ~]# cat /proc/sys/vm/swappiness
0 #将原本的30改为0
[root@server1 ~]# vim /etc/fstab #把fstab下的自动挂载swap注释掉,开机及就不会去挂载swap分区,也就无法使用了
#/dev/mapper/rhel-swap swap swap defaults 0 0
启动服务
[root@server1 ~]# daemon-reload
[root@server1 ~]# vim /etc/elasticsearch/elasticsearch.yml
开启后直接通过9200端口就可以去访问了
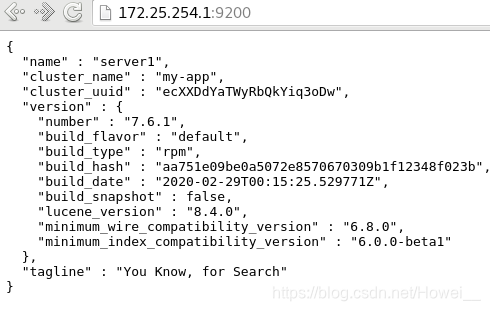
添加图形界面
图形界面是从github上去下载的,可以自行去选择自己喜欢的
我下载的是
wget https://github.com/mobz/elasticsearch-head/archive/master.zip
[root@server1 ~]# unzip master.zip #解压
[root@server1 ~]# ls
elasticsearch-head-master #得到这样一个目录
因为head插件本质上是一个nodejs的工程,因此需要安装node:
[root@server1 ~]# wget https://mirrors.tuna.tsinghua.edu.cn/nodesource/rpm_9.x/el/7/x86_64/nodejs-9.11.2-1nodesource.x86_64.rpm
[root@server1 ~]# rpm -ivh nodejs-9.11.2-1nodesource.x86_64.rpm #安装nodejs
因为使用npm install的时候它的安装依赖性会自行去网上下载,但是因为它的安装源在国外,我们下载会很慢,所以去更换它的安装源
[root@server1 ~]# cd elasticsearch-head-master/ #进入刚解压出来的目录里
使用淘宝的npm源来安装
[root@server1 elasticsearch-head-master]# npm install --registry=https://registry.npm.taobao.org
**注意:**这里安装的时候还需要一个命令支持,PhantomJS not found on PATH 找不到这个命令,并且它会自动下载,但是它给的网站下载是很慢的,所以需要自行提前去下载好,下载网址:https://mirrors.huaweicloud.com/phantomjs/ ,找到和它要求一样的包

下载完后解压拆解,
[root@server1 ~]# tar xfj phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@server1 bin]# cd phantomjs-2.1.1-linux-x86_64/bin/ #进入它的bin文件
[root@server1 bin]# cp phantomjs /usr/local/bin #复制到系统命令目录里
[root@server1 bin]# yum install -y fontconfig-2.13.0-4.3.el7.x86_64 #还需要安装它的依赖性包
[root@server1 bin]# phantomjs #测试使用就没有问题了
phantomjs>
完成操作再去安装nmp就没有问题了
安装完成还在elasticsearch-head-master目录下修改一个文件配置,将http访问指向本机ip的9200端口
[root@server1 elasticsearch-head-master]# vim _site/app.js
4374 this.base_uri = this.config.base_uri || this.prefs.get("ap p-base_uri") || "http://172.25.254.1:9200";
[root@server1 elasticsearch-head-master]# npm run start & #后台启动就可以了
启动后会开启9100端口提供去访问

最后修改ES跨域支持,添加两条配置
[root@server1 ~]# vim /etc/elasticsearch/elasticsearch.yml
http.cors.enabled: true #是否支持跨域,true支持
http.cors.allow-origin: "*" #*表示支持所有域名
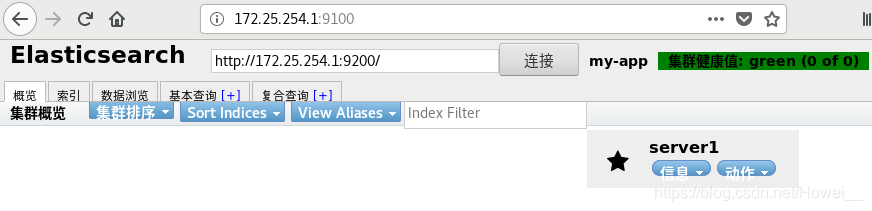
[root@server1 ~]# systemctl restart elasticsearch.service #重启服务
重启之后就可以去页面上连接节点了。连接后显示健康就没问题
ES分布式部署
首先需要再使用两台主机,来搭建集群
server2和server3,也去安装ES,配置文件可以直接从server1上传过去简单改一下就好
[root@server2 ~]# vim /etc/elasticsearch/elasticsearch.yml
17 cluster.name: my-app
23 node.name: server2 #设置本机的主机名,集群配置要配置所有节点上的解析
55 network.host: 172.25.254.2 #主机ip
59 http.port: 9200 #http访问的端口
69 discovery.seed_hosts: ["server1","server2","server3"] #给server1上添加同样的节点主机名
73 cluster.initial_master_nodes: ["server1","server2","server3"] #给server1上添加同样的节点主机名
[root@server3 ~]# vim /etc/elasticsearch/elasticsearch.yml
17 cluster.name: my-app
23 node.name: server3 #设置本机的主机名,集群配置要配置所有节点上的解析
55 network.host: 172.25.254.3 #主机ip
59 http.port: 9200 #http访问的端口
69 discovery.seed_hosts: ["server1","server2","server3"]
73 cluster.initial_master_nodes: ["server1","server2","server3"]
其他的配置和server1相同,开启ES服务
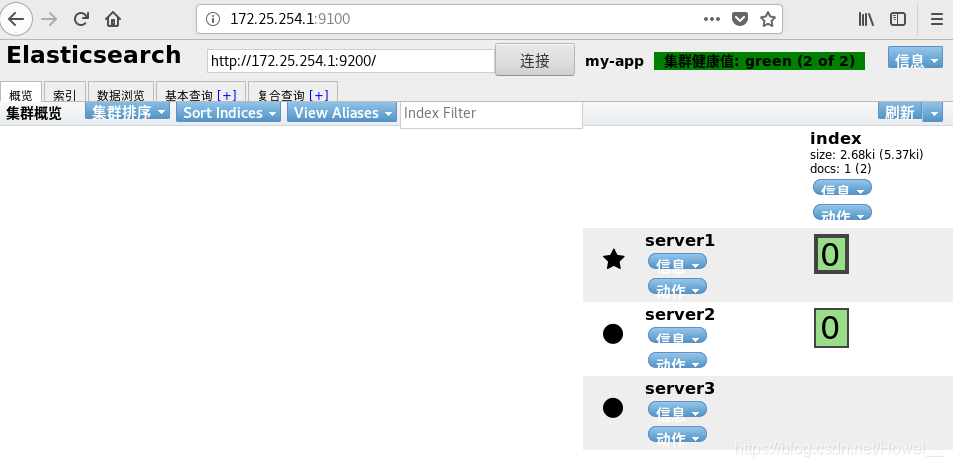
然后在页面里点击符合查询index/daemo去检索集群节点
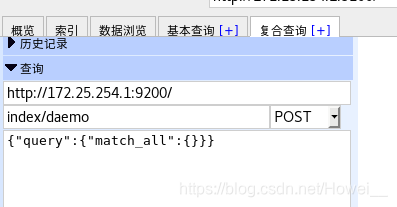
可以看到3主机都被加载出来了,server1前面的星表示它是master节点,其他两个是工作节点
ES里的节点角色说明
- Master:
主要负责集群中索引的创建、删除以及数据的Rebalance等操作。
Master不负责数据的索引和检索,所以负载较轻。当Master节点失联或者挂掉的时候,ES集群会自动从其他Master节点选举出一个Leader。 - Data Node:
主要负责集群中数据的索引和检索,一般压力比较大。 - Coordinating Node:
是原来的Client node的,主要功能是来分发请求和合并结果的。所有节点默认就是Coordinating node,且不能关闭该属性。 - Ingest Node:
专门对索引的文档做预处理
节点优化配置
在生产环境下,如果不修改Elasticsearch节点的角色信息,高并发的场景下集群容易出现崩溃等问题。
默认情况下Elasticsearch集群中每个节点都有成为主节点的资格,也都存储数据,还可以提供查询服务。
节点角色是由以下参数控制:
• node.master: false|true 是否可以作master节点
• node.data: true|false 是否可以储存数据
• node.ingest: true|false 是否可以预处理文档
• search.remote.connect: true|false 是否可以跨集群查询
默认情况下这些属性的值都是true。
节点的组合配置方式
-
第一种(默认方式)
node.master: true
node.data: true
node.ingest: true
search.remote.connect: true
这种组合表示这个节点即有成为主节点的资格,又存储数据。
如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。
不建议设置为这样。 -
第二种
node.master: false
node.data: true
node.ingest: false
search.remote.connect: false
这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。
这个节点称为data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据。后期提供存储和查询服务。 -
第三种
node.master: true
node.data: false
node.ingest: false
search.remote.connect: false
这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点。
这个节点我们称为master节点。 -
第四种
node.master: false
node.data: false
node.ingest: false
search.remote.connect: false
这种组合表示这个节点即不会成为主节点,也不会存储数据,
这个节点的意义是作为一个协调节点,主要是针对海量请求的时候可以进行负载均衡。 -
第五种
node.master: false
node.data: false
node.ingest: true
search.remote.connect: false
这种组合表示这个节点即不会成为主节点,也不会存储数据,这个节点的意义是ingest节点,对索引的文档做预处理。
生产集群中可以对这些节点的职责进行划分:
-
建议集群中设置3台以上的节点作为master节点,这些节点只负责成为主节点,维护整个集群的状态。
-
再根据数据量设置一批data节点,这些节点只负责存储数据,后期提供建立索引和查询索引的服务,这样的话如果用户请求比较频繁,这些节点的压力也会比较大。
-
所以在集群中建议再设置一批协调节点,这些节点只负责处理用户请求,实现请求转发,负载均衡等功能。
实验测试
对于目前的3台主机,我们分别进行不同的设定,这些设定都是需要额外添加进去的
[root@server1 ~]# vim /etc/elasticsearch/elasticsearch.yml
node.master: true #可以做master
node.data: false #不存数据
[root@server2 ~]# vim /etc/elasticsearch/elasticsearch.yml
node.master: true #可以作master
node.data: true #可以存数据
[root@server3 ~]# vim /etc/elasticsearch/elasticsearch.yml
node.master: false #不能作master
node.data: true #只能存数据
设定完成这三个节点都重启服务,注意在server1上我们现在设定不能存数据,但是之前已经产生数据了,所以需要去清楚之前的数据才可以。
[root@server1 ~]# cd /usr/share/elasticsearch/bin/
[root@server1 bin]# systemctl stop elasticsearch
[root@server1 bin]# ./elasticsearch-node repurpose
[root@server1 bin]# systemctl restart elasticsearch.service
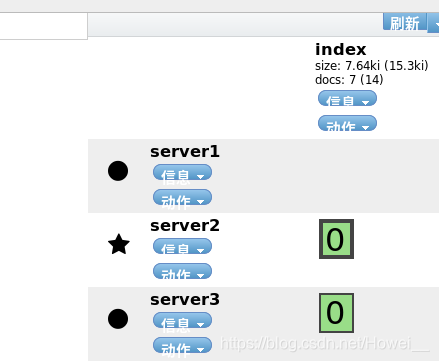
最后我们得到的就是server1和server2可以成为master节点,server2和server3可以储存数据
不同节点的需求建议:
- master节点:普通服务器即可(CPU、内存 消耗一般)
- data节点:主要消耗磁盘、内存。
path.data: data1,data2,data3
这样的配置可能会导致数据写入不均匀,建议只指定一个数据路径,磁盘可以使用raid0阵列,而不需要成本高的ssd。 - Coordinating节点:对cpu、memory要求较高。
logstash数据采集
Logstash是一个开源的服务器端数据处理管道。
logstash拥有200多个插件,能够同时从多个来源采集数据,
转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(大多
都是 Elasticsearch。)
Logstash管道有两个必需的元素,输入和输出,以及一个可选
元素过滤器。
Logstash管道有两个必需的元素,输入和输出,以及一个可选
元素过滤器。
-
输入:采集各种样式、大小和来源的数据
Logstash 支持各种输入选择 ,同时从众多常用来源捕捉事件。
能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。 -
过滤器:实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。如:
利用 Grok 从非结构化数据中派生出结构;
从 IP 地址破译出地理坐标;
将 PII 数据匿名化,完全排除敏感字段;
简化整体处理,不受数据源、格式或架构的影响. -
输出:选择您的存储库,导出您的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
安装配置
因为前面的三台主机给的内存都是2G,所以再去开启一台主机配置logstash,如果你给的一台主机内存高也可以直接在一台主机上去配置,server4去安装logstash
推荐下载地址:https://mirrors.huaweicloud.com/logstash/
国内的服务器,下载快,这个logstash也是需要jdk 的
[root@server4 ~]# rpm -ivh jdk-8u181-linux-x64.rpm
[root@server4 ~]# rpm -ivh logstash-7.7.1.rpm
安装完可以直接执行它的脚本去启动
-e后面的参数就是指定输入和输出的模式,这里写的都是标准模式
/usr/share/logstash/bin/logstash -e 'input { stdin { } }
output { stdout {} }'
启动时会有一段加载过程,会产生输出
111 #启动后随便去进行输入内容
{ #都会自动返回输出给你
"@timestamp" => 2020-06-11T08:42:59.995Z,
"@version" => "1",
"message" => "111",
"host" => "server4"
}
还可以去编写配置指定输入输出和过滤器的配置参数,
在/etc/logstash/conf.d/ 这个目录里创建.conf结尾的文件都会被采集到配置信息里
[root@server4 ~]# vim /etc/logstash/conf.d/file.conf
input {
stdin { } #输入为标准输入
}
#中间的过滤器可以不指定
output {
stdout { } #输出为标准输出
}
指定我们自己编写配置启动还是同样可以生效
[root@server4 ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/file.conf #指定我们编写的配置启动
123
{
"message" => "123",
"host" => "server4",
"@version" => "1",
"@timestamp" => 2020-06-11T08:52:23.099Z
}
logstash输出插件
除了指定的标准输出之外,还可以参考官方文档,添加多个模块,指定输出保存的路径和输出的格式
[root@server4 ~]# vim /etc/logstash/conf.d/file.conf
input {
stdin { }
}
output {
stdout { }
file {
path => "/tmp/logstash.txt" #指定输出路径
codec => line { format => "custom format: %{message}"} #输出格式
}
}
再去启动logstash输入
[root@server4 ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/file.conf
[root@server4 ~]# cat /tmp/logstash.txt #输入的内容会保存在这里
custom format: 11
custom format: 132
Logstash 输出到 ES主机
在自定义的配置文件里,设定使用elasticsearch插件去输出
[root@server4 ~]# vim etc/logstash/conf.d/file.conf
input {
stdin { }
}
output {
stdout { }
elasticsearch { #使用ES插件
hosts => "172.25.254.1:9200" #输出到ES主机,这里是支持列表的,可以写入多个ip
index => "logstash-%{+YYYY.MM.dd}" #指定索引名
}
}
[root@server4 ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/file.conf
test #输入数据
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"host" => "server4",
"@timestamp" => 2020-06-11T09:14:20.703Z,
"message" => "test",
"@version" => "1"
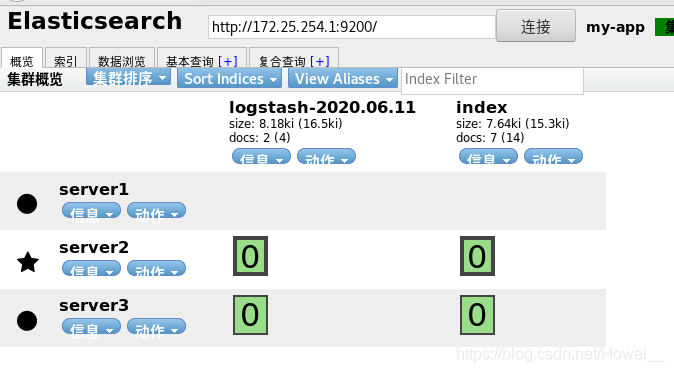
在页面上可以看到收到了logstash 的数据
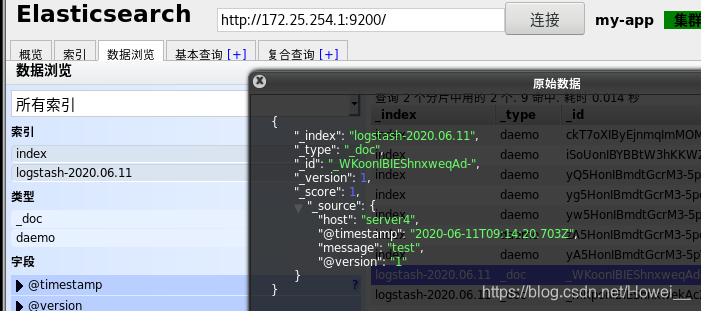
还可以在数据浏览里查看接收到的这条信息和我们输入的是一样的
这样我们测试输出传送没有问题,现在就要考虑我们的输入了,将日志文件放到输入里直接通过logstash输出到ES上。
这里为了测试,在server4上安装apache,访问测试生成大量的访问日志
[root@server4 ~]# yum install -y httpd
[root@server4 ~]# echo "www.redhat.cn" > /var/www/html/index.html #写一个默认发布页
[root@server4 ~]# systemctl enable --now httpd
[root@server1 ~]# ab -c 1 -n 100 http://172.25.254.4/index.html #访问100次
[root@server4 ~]# cat /var/log/httpd/access_log #产生的访问数据都在这个文件里
要注意的是,logstash运行的时候是通过logstash用户执行的,所以对于要执行的目录和文件都要有可读的权限
[root@server4 ~]# vim /etc/logstash/conf.d/file.conf
input {
file {
path => "/var/log/httpd/access_log" #执行输入的文件
start_position => "beginning" #从哪开始读,设置为开头,也可以设置为end,表示加载后期的变动
}
}
output {
stdout { }
elasticsearch {
hosts => "172.25.254.1:9200"
index => "logstash-%{+YYYY.MM.dd}"
}
}
再去启动后就会自动长生大量的输出,就是在读取/var/log/httpd/access_log里的内容,并且输出到ES上,可以看到ES上的logstash出现了大量的数据文件
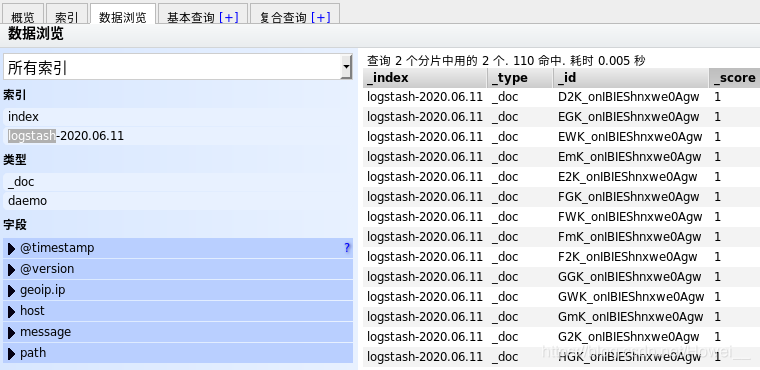
重要说明的一点是,如果当前ES上的logstash被删除了,再次去执行一次输入输出也不会再有输出结果了,因为在执行过之后就会有记录,不会再重复的读取一个文件的内容。
[root@server4 ~]# cd /usr/share/logstash/data/plugins/inputs/file/
[root@server4 file]# ls -A #这里面有一个隐藏文件
.sincedb_15940cad53dd1d99808eeaecd6f6ad3f
[root@server4 file]# cat .sincedb_15940cad53dd1d99808eeaecd6f6ad3f
9450679 0 64768 10290 1591868378.088398 /var/log/httpd/access_log #文件里的内容,记录就是关于读取的文件的
[root@server4 file]# ls -i /var/log/httpd/access_log
9450679 /var/log/httpd/access_log
如果需要数据重载,就可以选择删除这个隐藏文件,再去执行
隐藏的sincedb文件一共6个字段
- inode编号
- 文件系统的主要设备号
- 文件系统的次要设备号
- 文件中的当前字节偏移量
- 最后一个活动时间戳(浮点数)
- 与此记录匹配的最后一个已知路径
syslog 跨主机日志采集插件
如果当需要采集其他主机上日志时,按照上面的方法就需要在所有的主机上安装logstash然后转发日志到ES里,这样就显得很麻烦,因为logstash本身运行的时候消耗的资源也是不少的。
所以就需要使用logstash伪装成日志服务器,直接接受远程日志。
操作方法:
在server4这台安装logstash的主机上编辑配置文件,让rsyslog的日志通过514端口输入到ES上
[root@server4 file]# vim /etc/logstash/conf.d/syslog.conf
input {
syslog {
type => "rsyslog"
port => 514
}
}
output {
stdout { }
elasticsearch {
hosts => "172.25.254.1:9200"
index => "syslog-%{+YYYY.MM.dd}"
}
}
写好配置,就可以执行通过这个配置运行logstash
[root@server4 file]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/syslog.conf
再去其他需要转发日志的主机上配置日志转发
[root@server1 ~]# vim /etc/rsyslog.conf
添加一条日志采集规则,将所有日志转发到server4上通过514端口
*.* @@172.25.254.4:514
[root@server1 ~]# systemctl restart rsyslog.service
其他节点都配置完,重启之后就可以看到server4上已经接收到日志信息了
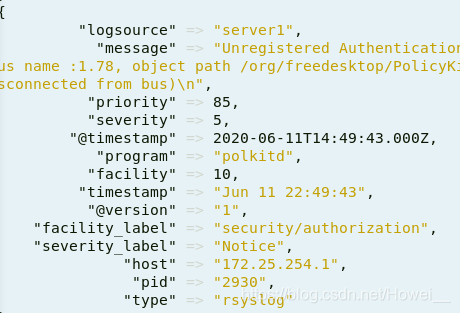
ES上也接收到了
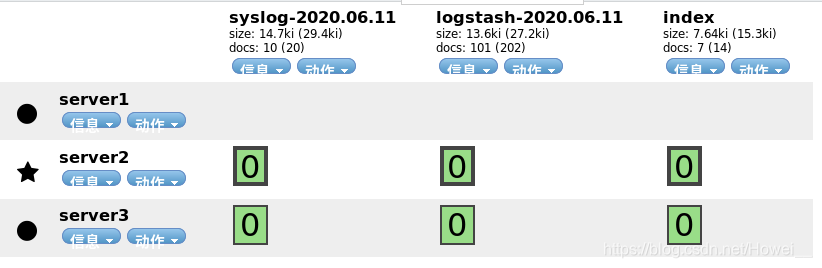
多行过滤插件
多行过滤可以把多行日志记录合并为一行事件,前面我们测试标准输入输出的时候都是输一行采集一行,但是想要一次采集多行就需要使用multiline插件
[root@server4 file]# vim /etc/logstash/conf.d/multline.conf
input {
stdin {
codec => multiline {
pattern => "^EOF" #设定输入的关键字
negate => true
what => previous #表示向上匹配,就是碰到EOF的时候会把之前的所有输入作为一个整体
}
}
}
output {
stdout { }
}
[root@server4 file]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/multline.conf
11
112
123
EOF
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"message" => "11\n112\n123",
"tags" => [
[0] "multiline"
],
"host" => "server4",
"@version" => "1",
"@timestamp" => 2020-06-11T15:10:50.401Z
}
这样的多行过滤还可以应用到日志的采集时,如果一条日志它是多行存在的就可以,使用输入关键字设定配置日志信息。
过滤插件
使用grok插件可以过滤日志,添加过滤器
[root@server4 file]# vim /etc/logstash/conf.d/grok.conf
input {
stdin {}
}
filter {
grok { #使用grok过滤器,自定义输出模板
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
output {
stdout { }
}
过滤的match的设定是根据你输入的数据格式写的,用的测试模板也是从官方文档里取的:55.3.244.1 GET /index.html 15824 0.043,分为ip、模式、请求、大小、周期等信息
[root@server4 file]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/grok.conf
55.3.244.1 GET /index.html 15824 0.043
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{ #自动根据你的输入,分解过滤成这样的输出
"@version" => "1",
"client" => "55.3.244.1",
"host" => "server4",
"duration" => "0.043",
"method" => "GET",
"request" => "/index.html",
"message" => "55.3.244.1 GET /index.html 15824 0.043",
"bytes" => "15824",
"@timestamp" => 2020-06-11T15:39:54.415Z
}
在生产环境中,针对apache这类web服务,我们可以根据访问日志的信息去分割,提取相应的ip信息记录来源和访问次数
[root@server4 file]# vim /etc/logstash/conf.d/apache.conf
input {
file {
path => "/var/log/httpd/access_log" #指定文件
start_position => "beginning"
}
}
filter{
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" } #使用httpd自己的过滤模板
}
}
output {
elasticsearch {
hosts => "172.25.254.1:9200" #输出到ES里
index => "apachelog-%{+YYYY.MM.dd}"
}
}
启动logstash后,去访问100次server4的http服务采集数据
[root@server4 file]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/apache.conf
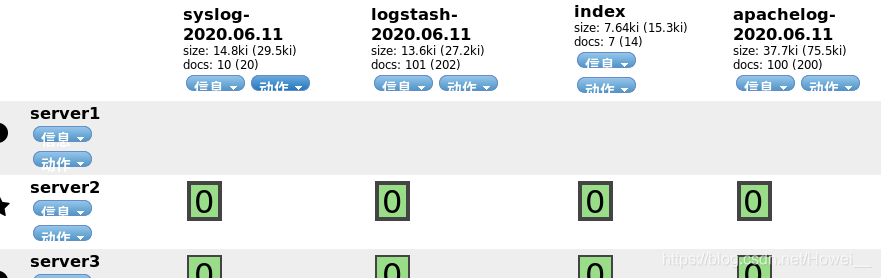
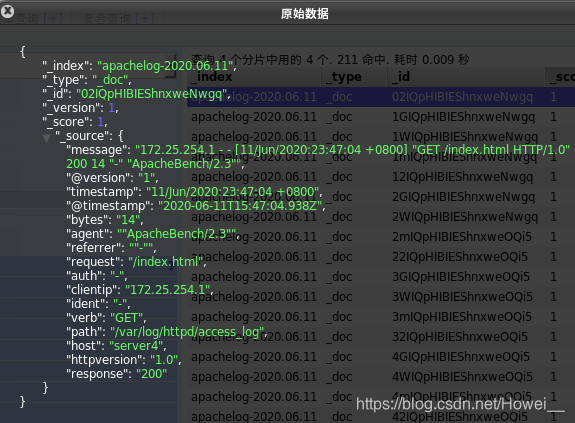
可以看到,输出的日志信息就全部被分割开了,所有的信息都有了统一的索引值方便数据统计。
kibana数据可视化
Kibana 核心产品搭载了一批经典功能:柱状图、线状图、饼
图、旭日图,等
可以将地理数据融入地图里,展示各个地区的访问情况。
利用 Graph 功能分析数据间的关系。
安装配置
官方下载:https://elasticsearch.cn/download/
国内下载地址https://mirrors.huaweicloud.com/kibana/
直接安装rpm包,注意安装kibana的版本要和你的ES版本一致,否则会导致可kibana无法访问
[root@server4 ~]# rpm -ivh kibana-7.6.1-x86_64.rpm
编辑配置
[root@server4 ~]# vim /etc/kibana/kibana.yml
2 server.port: 5601 #服务监听端口
7 server.host: "172.25.254.4" #服务地址
28 elasticsearch.hosts: ["http://172.25.254.1:9200"] #指定ES的地址
37 kibana.index: ".kibana" #kibana在ES中创建的索引
115 i18n.locale: "zh-CN" #开启中文支持
[root@server4 ~]# systemctl enable --now kibana.service #开启服务并自启
开启服务后,检测端口是否正常开启
[root@server4 ~]# netstat -ntlp | grep 5601
tcp 0 0 172.25.254.4:5601 0.0.0.0:* LISTEN 13848/node
使用操作
正常启动后就可以通过网页去直接访问kibana如果出现网页报错可以多刷新几次试试
这里提供了样例数据可以让你参考,主要还是需要自行去建立。
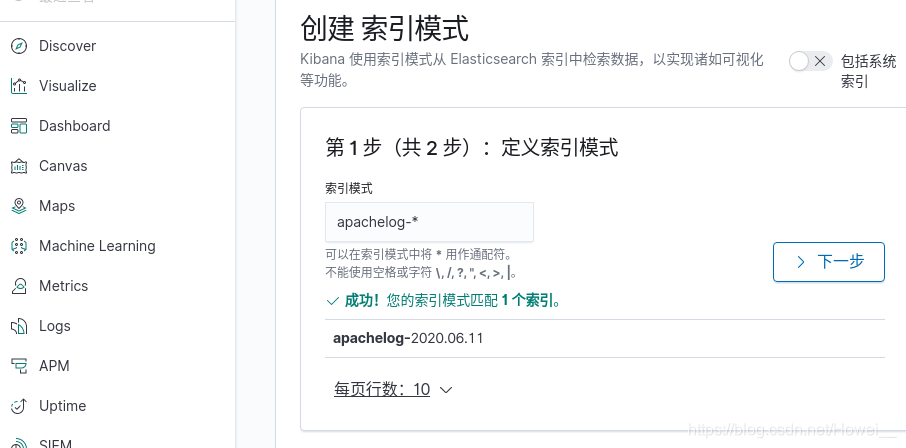
选择“自己浏览”,进入后,左侧选择Discover创建索引,这里的数据我们是直接可以从ES上拿来的,所以索引模式“apachelog-* ”指向apache的访问日志
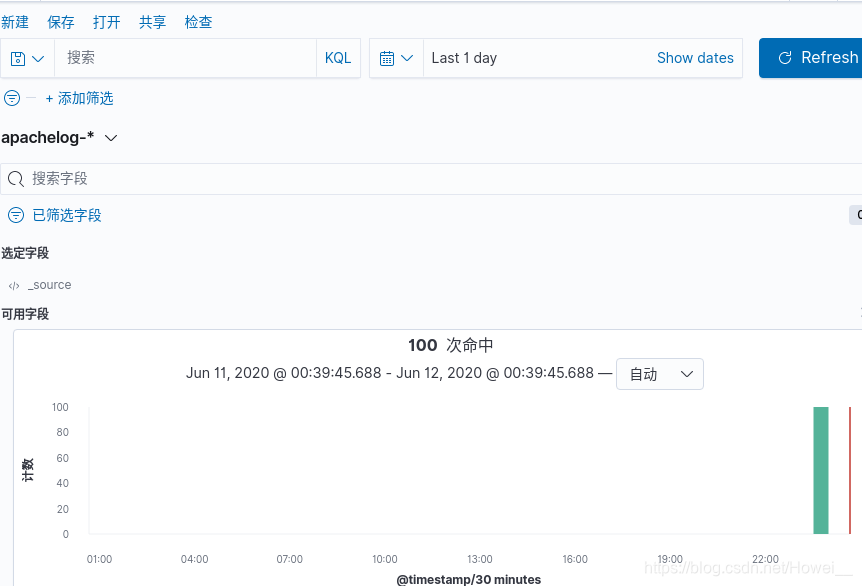
创建完索引后,在点击Discover就可以看到信息,如果看不到信息,是因为时间设置的不够长,之前的数据间隔太久了,更改统计的时间就可以
在左上方有保存,点击可进行保存数据
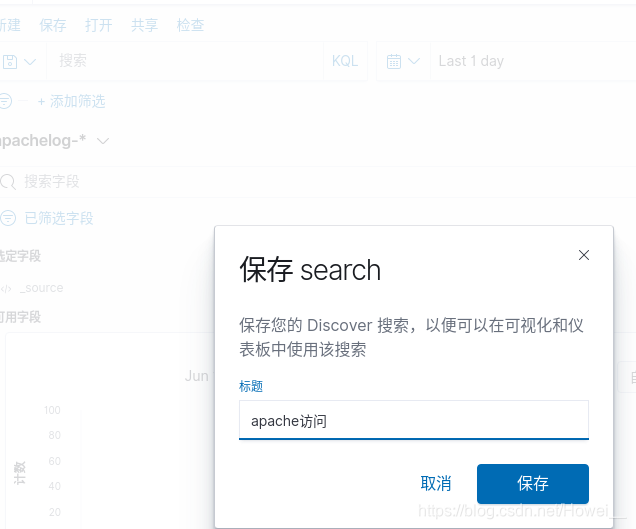
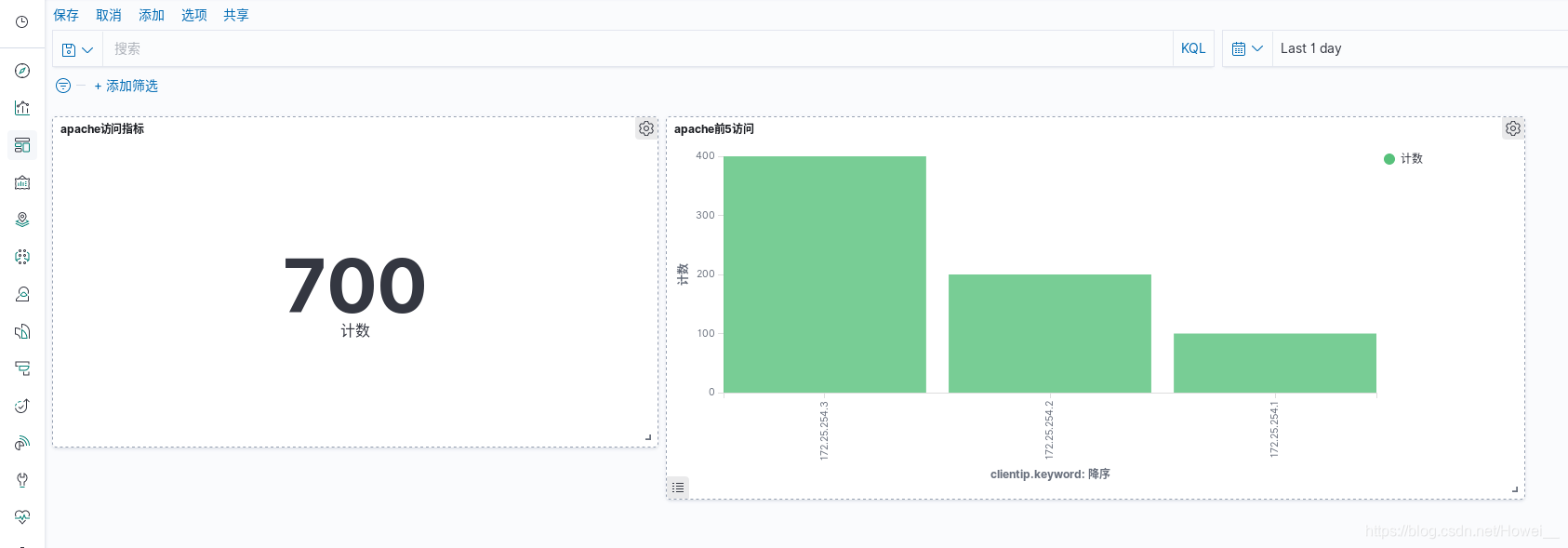
创建仪表板
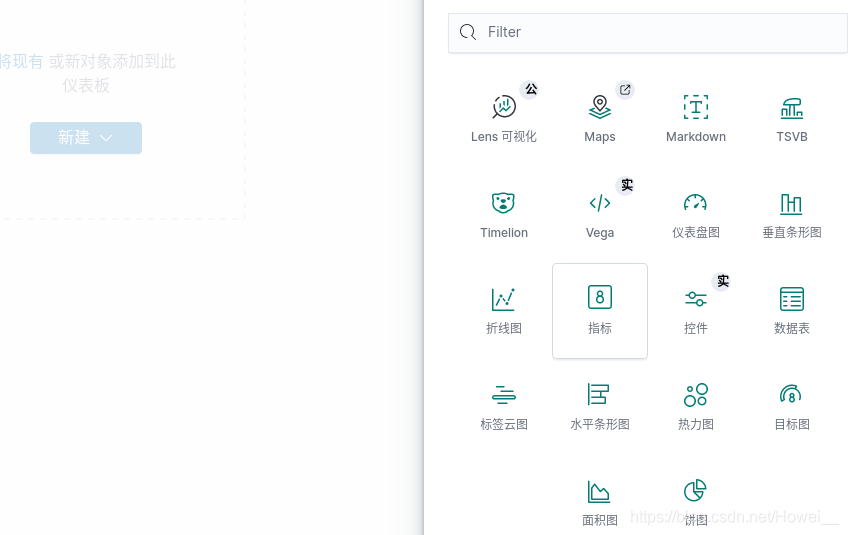
然后需要去创建仪表板展示数据,不然如何能快速的分析出我们需要的数据内容
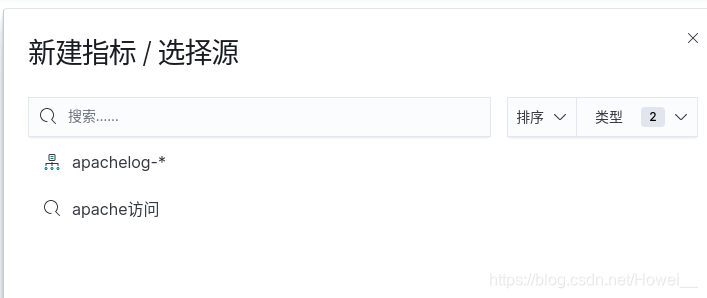
点击左侧的Dashbord,创建仪表版,点击新建,选择指标模块
这里就可以刚才保存的数据
再点击保存,将仪表板保存下来
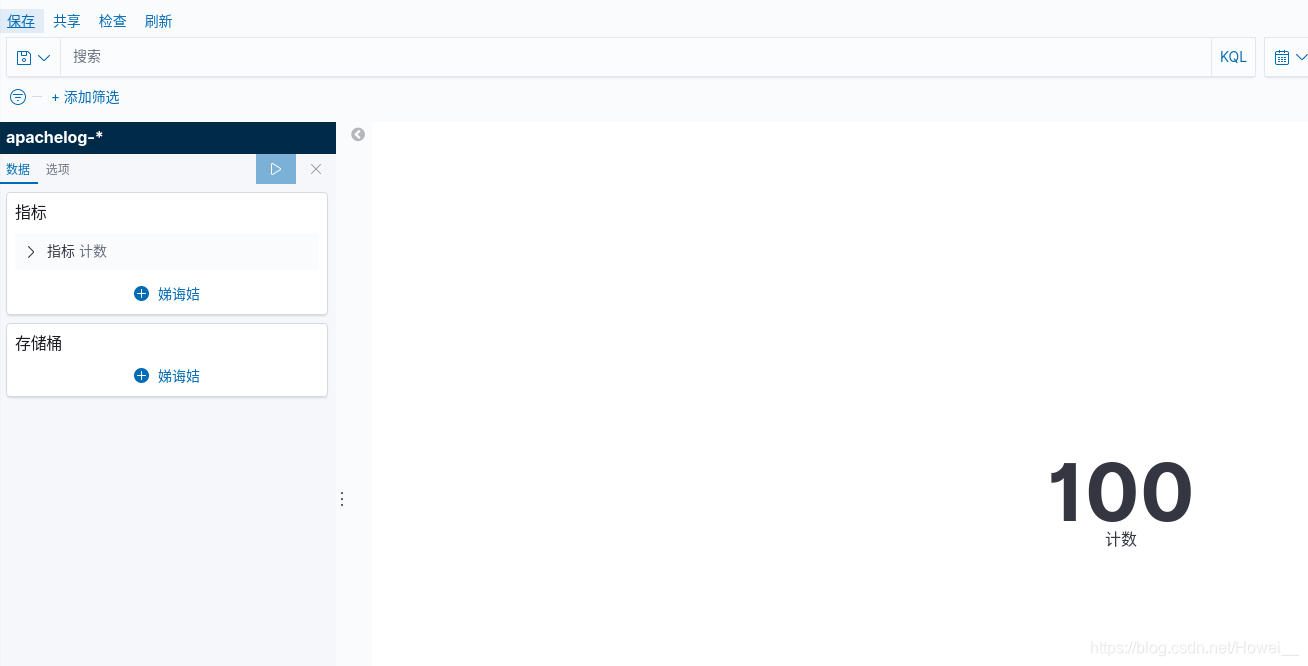
最后就可以通过添加把我们制定的仪表板保存下来了,并且展示出来
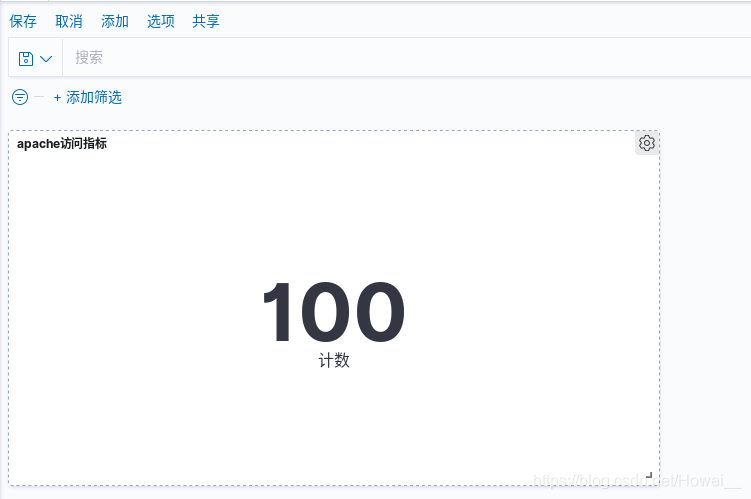
还可以继续创建仪表板
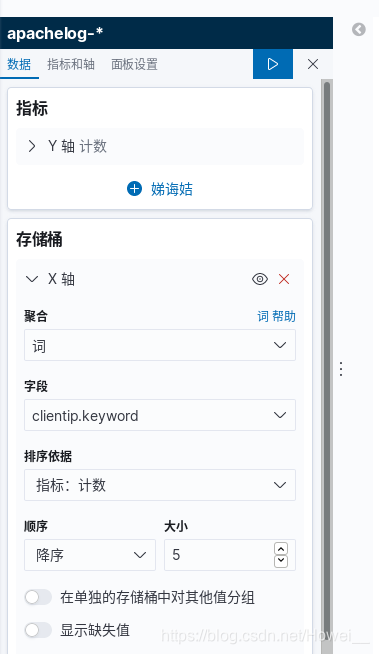
点击左侧的Visualize,创建可视化,还是使用apachelog-* 这个数据来创建一个垂直条形图
创建出来之后,需要添加X轴,并且根据之前过滤出来的访问ip进行前五名的降序排列
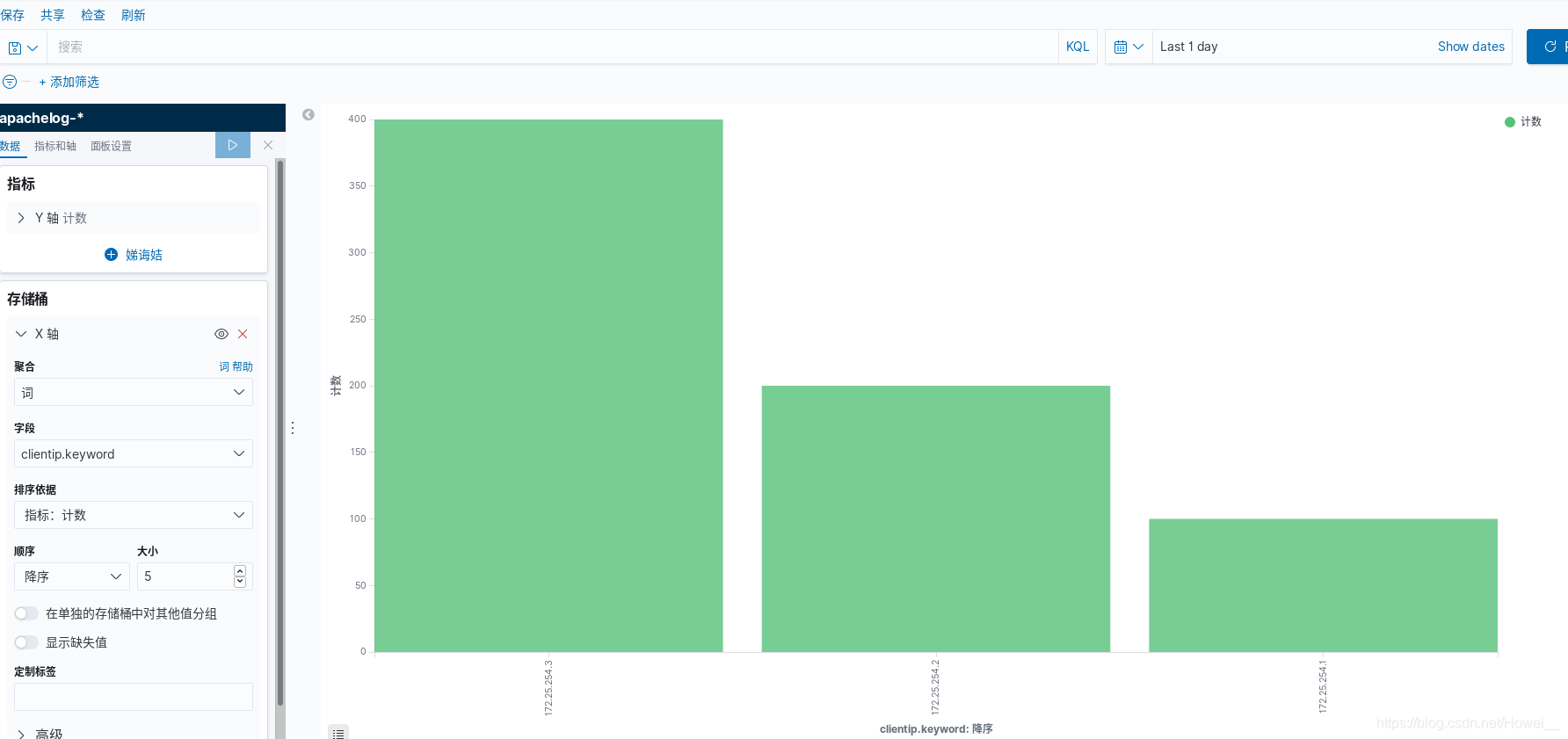
这里就还需要多用几台主机进行访问产生数据使用
[root@server2 ~]# ab -c 1 -n 200 http://172.25.254.4/index.html
[root@server3 ~]# ab -c 1 -n 400 http://172.25.254.4/index.html
再到kibana里面就可以看到实时的数据变化,x轴还标注了数据来源ip
同样添加到仪表盘里展示
xpack安全验证
x-pack介绍:
x-pack是一个基于elastic安全的插件包。可以实现安全认证,监控、报表、图形等功能。自elk5.0版本以后集成到elk中。
特点:
安装方便,灵活。虽然已经集成,但是可以随意的启用或禁用某个功能
创建证书
集群模式需要先创建证书,这样的操作可以让集群里的主机共用一个证书,不需要重新去绑定连接
操作在ES主机上执行,
[root@server1 ~]# cd /usr/share/elasticsearch/bin #创建证书的命令在这个路径下
[root@server1 elasticsearch]# ./elasticsearch-certutil ca #调用命令创建ca证书
#这里有两个需要执行的操作
Please enter the desired output file [elastic-stack-ca.p12]: #这个指定输出的文件可以直接使用默认的,回车跳过
Enter password for elastic-stack-ca.p12 : #设置密码,是在调用ca是需要的,可以直接回车跳过也可以输入一个密码
[root@server1 bin]# ./elasticsearch-certutil cert --ca elastic-stack-ca.p12 #使用刚才生成的elastic-stack-ca.p12
Enter password for CA (elastic-stack-ca.p12) : #这里就需要输密码,上面没有设置的密码,直接回车跳过,下面也是直接跳过
Please enter the desired output file [elastic-certificates.p12]:
Enter password for elastic-certificates.p12 :
然后把生成的两个文件放入ES的配置文件里,生成的文件就在当前目录的上级目录里
[root@server1 bin]# cd ..
[root@server1 elasticsearch]# ls
bin elastic-stack-ca.p12 lib modules plugins
elastic-certificates.p12 jdk LICENSE.txt NOTICE.txt README.asciidoc
[root@server1 elasticsearch]# cp elastic-certificates.p12 elastic-stack-ca.p12 /etc/elasticsearch
注意要查看这两个文件的权限,因为ES执行的时候是通过elasticsearch用户来执行的,所以直接把文件的拥有者改成elasticsearch。
[root@server1 elasticsearch]# ll
-rw-------. 1 root elasticsearch 3451 Jun 12 10:27 elastic-certificates.p12
-rw-------. 1 root elasticsearch 2527 Jun 12 10:27 elastic-stack-ca.p12
[root@server1 elasticsearch]# chown elasticsearch elastic-certificates.p12 elastic-stack-ca.p12
配置到其他节点
可以直接将这两个证书通过发送直接放到其他节点的/etc/elasticsearch里
[root@server1 elasticsearch]# scp -p elastic-stack-ca.p12 elastic-certificates.p12 server2:/etc/elasticsearch/
[root@server1 elasticsearch]# scp -p elastic-stack-ca.p12 elastic-certificates.p12 server3:/etc/elasticsearch/
传送过去后也是需要整改权限的
启用xpack安全验证
这个配置很简单,在所有节点上直接添加指定的配置
[root@server1 ~]# vim /etc/elasticsearch/elasticsearch.yml
xpack.security.enabled: true #确认开启证书
xpack.security.transport.ssl.enabled: true #ssl开启
xpack.security.transport.ssl.verification_mode: certificate #指定加密的模式
xpack.security.transport.ssl.keystore.path: /etc/elasticsearch/elasticcertificates.p12 #证书的路径
xpack.security.transport.ssl.truststore.path: /etc/elasticsearch/elasticcertificates.p12
其他节点都一样,直接添加配置进去就可以,
配置完成将所有节点重启加载配置。
当去再去使用kibana连接时就需要输入用户和密码进行认证了
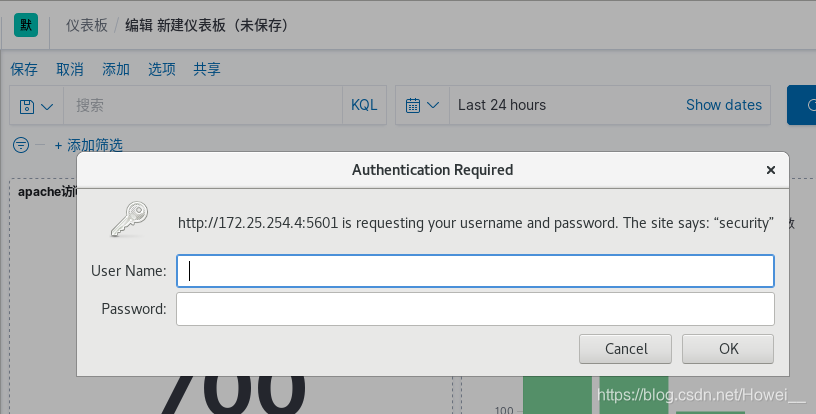
这里就需要去创建用户密码
[root@server1 elasticsearch]# cd /usr/share/elasticsearch/bin
[root@server1 bin]# ./elasticsearch-setup-passwords interactive #执行命令创建密码和用户
Enter password for [elastic]: #ES的超级用户
Reenter password for [elastic]:
Enter password for [apm_system]:
Reenter password for [apm_system]:
Enter password for [kibana]: #kibana用户的密码
Reenter password for [kibana]:
Enter password for [logstash_system]: #logstash用户的密码
Reenter password for [logstash_system]:
Enter password for [beats_system]:
Reenter password for [beats_system]:
Enter password for [remote_monitoring_user]: #远程连接用户的密码
Reenter password for [remote_monitoring_user]:
Changed password for user [apm_system]
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [remote_monitoring_user]
Changed password for user [elastic]
设置完密码和ihou就会创建出这些相应的用户
kibana认证
在kibana的主机里的配置目录里开启ES的认证用户
[root@server4 ~]# vim /etc/kibana/kibana.yml
46 elasticsearch.username: "kibana"
47 elasticsearch.password: "redhat"
[root@server4 ~]# systemctl restart kibana.service #重启服务
再去访问网页时就会需要输入用户和密码,可以直接使用elastic用户登陆,这里是没有限制的
logstash认证
logstash也需要去用户认证,在编辑的.conf文件里output下面指定用户和密码,这样去发送数据的时候就不会失败了
[root@server4 conf.d]# vim etc/logstash/conf.d/file.conf
input {
file {
path => "/var/log/httpd/access_log"
start_position => "beginning"
}
}
output {
stdout { }
elasticsearch {
hosts => "172.25.254.1:9200"
index => "logstash-%{+YYYY.MM.dd}"
user => "elastic" #登陆用户
password => "redhat" #登陆密码
}
}
head图形界面认证
要能使用head图形界面查看logstash还需要在,安装head的ES主机上添加一条配置
[root@server1 bin]# vim /etc/elasticsearch/elasticsearch.yml
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
[root@server1 bin]# systemctl restart elasticsearch.service
重启之后再去网页访问9100端口,指定用户和密码:http://172.25.254.1:9100/?auth_user=elastic&auth_password=redhat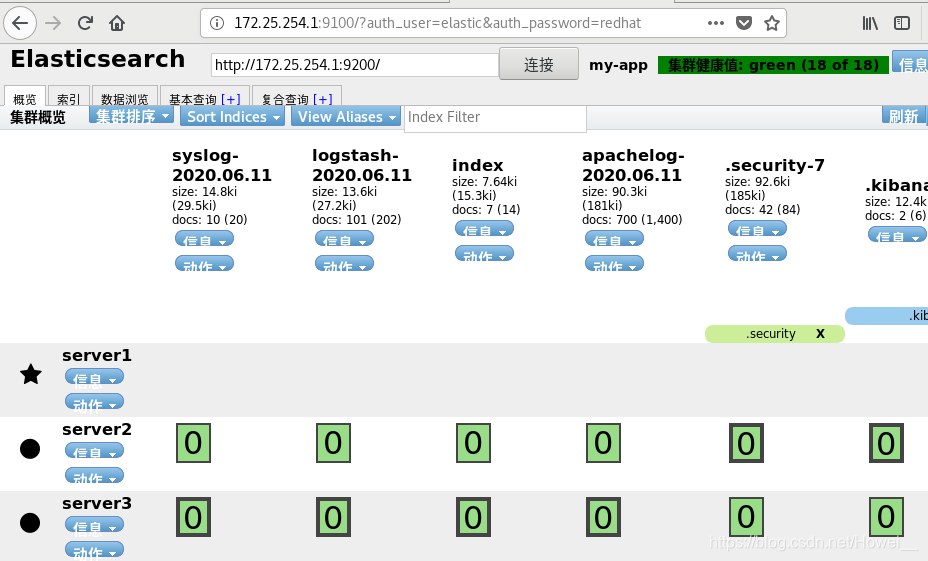















 3721
3721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











