







- 从最简单的线性模型开始,可以看作是单层神经网络,多个输入对应一个输出。
可表示为:
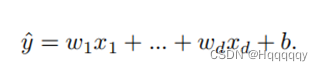
或
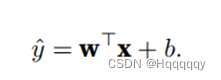
损失函数即为真实值与预测值之间的差距
可通过最小化损失函数来学习w,b参数
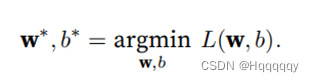
为了学习(更新)w,b参数,从而优化模型,所以引出随机梯度下降的优化算法
但是在整个训练集上计算梯度太贵,从而引出小批量随机梯度下降算法
- 再将模型进行升级,变换到分类问题
多个输入对应多个输出,我们希望输出的为分类的匹配概率
从而引入softmax函数
想要衡量两个概率的区别,从而建立损失函数,所以引入交叉熵的概念
损失函数即为
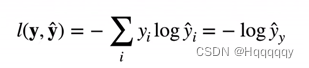
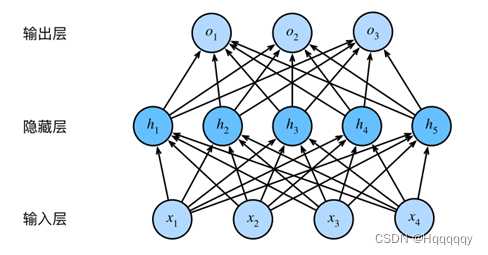
- 继续讲模型升级,使其多层,变为多层感知机
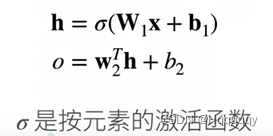
为什么要引入激活函数呢?
是为了将线性变为非线性,从而使模型更加复杂,来解决实际问题。
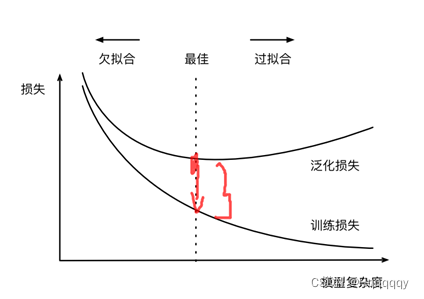
对于过拟合与欠拟合的概念,用这张图可以解释的很清楚:
过拟合的解决办法,通常有衰退法和丢弃法(dropout)
对于衰退法,是利用L2正则化技术,从而控制权重w
权重衰退体现在哪呢?
我们首先对该损失函数求导,计算梯度如下:
然后带入原先的参数更新式子中:
得到:
而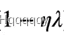
这项小于1,所以wt比原先更新式中首先衰退了一点,然后再进行优化更新,从而防止过拟合。
对于丢弃法(dropout)
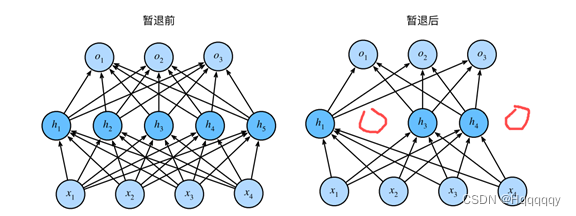
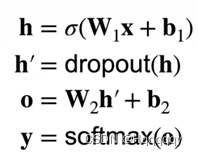
丢弃法是指对每个元素进行如下扰动,从而防止过拟合。















 110
110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









