









Experience replay:经验回放 -DQN的高级技巧
本笔记整理自 (作者: Shusen Wang):
https://www.bilibili.com/video/BV1rv41167yx?from=search&seid=18272266068137655483&spm_id_from=333.337.0.0
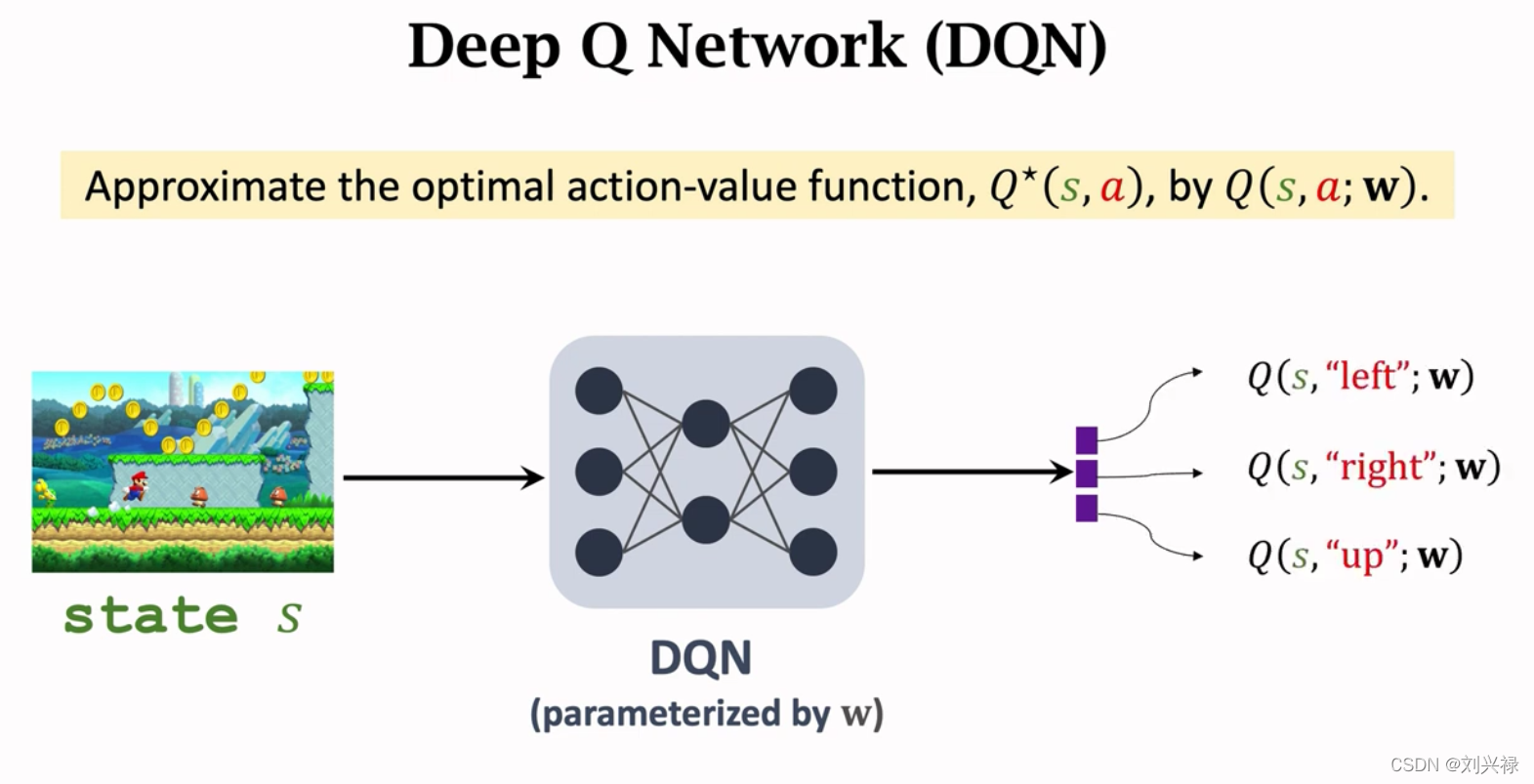




Experience replay


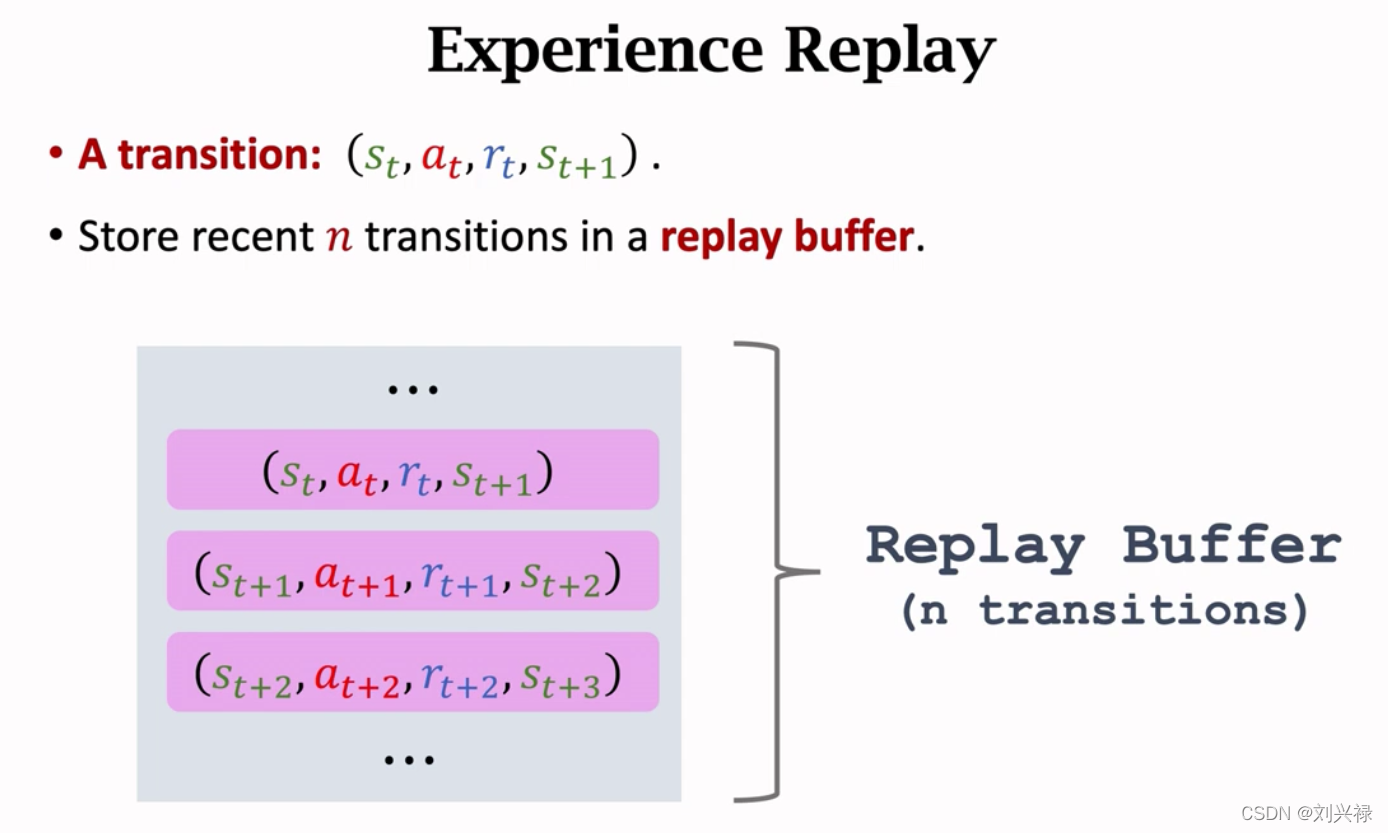




- 用优先经验抽样代替随机抽样


- 右边的场景更加重要





本笔记整理自 (作者: Shusen Wang):
https://www.bilibili.com/video/BV1rv41167yx?from=search&seid=18272266068137655483&spm_id_from=333.337.0.0
- 用优先经验抽样代替随机抽样
 7195
984
1018
9642
7195
984
1018
9642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























