








论文地址: https://arxiv.org/abs/1511.05952
本论文是由DeepMind操刀,Schaul主导完成的文章,发表于顶会ICLR2016上,主要解决经验回放中的”采样问题“(在DQN算法中使用了经典的”experience replay“,但存在一个问题是其采用均匀采样和批次更新,导致特别少但价值特别高的经验没有被高效的利用)。
还是往常的学习顺序,先摘要和结论

通常情况下,在使用“经验”回放的算法中,通常从缓冲池中采用“均匀采样(Uniformly sampling)”,虽然这种方法在DQN算法中取得了不错的效果并登顶Nature,但其缺点仍然值得探讨,本文提出了一种 “优先级经验回放(prioritized experience reolay)” 技术去解决采样问题,并将这种方法应用在DQN中实现了state-of-the-art的水平。

结论表明,该方法不仅可以提升效果,还可以 加速学习速度。下面开始正文
1. 问题阐述
1.1 均匀采样缺点
在诸如DQN算法的强化学习中经常遇到两个问题:
- 基于梯度的更新打破了数据之间的独立同分布(i.i.d.) 假设问题
- 快速忘记了一些罕见重要的、以后使用的经验数据
而经验回放的广泛使用解决了上述痛点,其过程分为两个阶段,存放和利用(如何采样抽取),传统的采样使用均匀的方式随机的从下表中获取mini-bathch的数据进行学习。
| transition |
|---|
| < s 1 s_{1} s1, a 1 a_{1} a1, r 1 r_{1} r1, s 2 s_{2} s2> |
| < s 2 s_{2} s2, a 2 a_{2} a2, r 2 r_{2} r2, s 3 s_{3} s3> |
| … |
| < s n s_{n} sn, a n a_{n} an, r n r_{n} rn, s n + 1 s_{n+1} sn+1> |
所以问题归结于"如何从上表中的experience中以mini-batch的方式选取数据学习呢?",即 如何采样(sampling)?
作者拿一个具体的例子来说明均匀采样有什么问题,假设有一个如下图所示的environment,它有 n n n个状态,2个动作,初始状态为1,状态转移如箭头所示,当且仅当沿绿色箭头走的时候会有1的reward,其余情况的reward均为0。那么假如采用随机策略从初始状态开始走n步,我们能够获得有用的信息(reward非0)的可能性为 1 2 n \frac{1}{2^{n}} 2n1。也就是说,假如我们把各transition都存了起来,然后采用均匀采样来取transition,我们仅有 1 2 n \frac{1}{2^{n}} 2n1的概率取到有用的信息,这样的话学习效率就会很低。
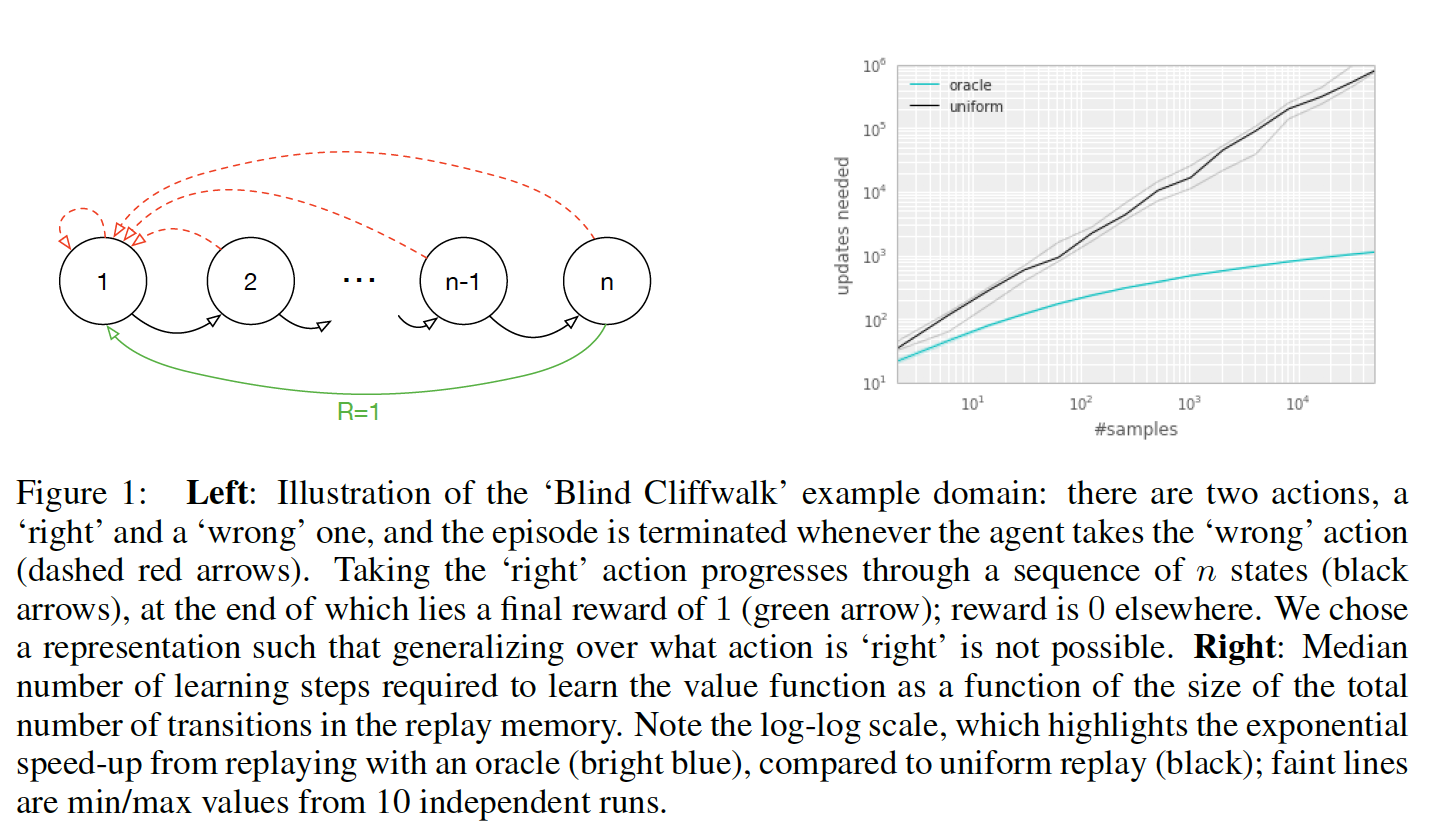
实验结果如图右方所示所示:说明transition的选取顺序对学习效率有很大的影响。下图横轴代表experience replay的大小,纵轴表示学习所需的更新次数。黑色的线表示采用均匀采样得到的结果,绿色的线表示每次都选取”最好“的transition的结果。可以看到,这个效率提升是很明显的。
1.2 衡量指标 TD-error
作者首先给出了一个衡量指标:“TD-error”,随后贪心地选”信息量“最大的transition,然而这种方法存在以下缺陷:
- 由于考虑到算法效率,不会每次critic更新后都更新所有transition的TD-error,我们只会更新当次取到的transition的TD-error。因此transition的TD-error对应的critic是以前的critic(更准确地说,是上次取到该transition时的critic)而不是当前的critic。也就是说某一个transition的TD-error较低,只能够说明它对之前的critic“信息量”不大,而不能说明它对当前的critic“信息量”不大,因此根据TD-error进行贪心有可能会错过对当前critic“信息量”大的transition。
- 容易overfitting:基于贪心的做法还容易“旱的旱死,涝的涝死”,因为从原理上来说,被选中的transition的TD-error在critic更新后会下降,然后排到后面去,下一次就不会选中这些transition),来来去去都是那几个transition,导致overfitting。
2. 算法原理和过程
作者在本文提出的优先级通过更加频繁的更新去衡量“TD-error”,然而优先级也会带来的多样性损失问题,作者则利用随机优先级采样、偏置和重要性采样来避免该问题。为了处理上述问题,作者提出stochastic prioritization,随机化的采样过程,“信息量”越大,被抽中的概率越大,但即使是“信息量”最大的transition,也不一定会被抽中,仅仅只是被抽中的概率较大。
Prioritized DQN能够成功的主要原因有两个:
- sum tree这种数据结构带来的采样的O(log n)的高效率
- Weighted Importance sampling的正确估计

2.1 随机优先级采样方法
为了解决贪心优先级造成的在函数逼近过程中频繁的有一个较高的error、过拟合等问题,一种结合纯贪心采样和和均匀分布采样的随机采样方法被提出。并确保在transition的优先级中采样的概率是单调的,同时即使对于最低优先级的transition也要保证非零概率。并定义采样的概率为:
P ( i ) = p i α ∑ k p k α P(i)=\frac{p_{i}^{\alpha}}{\sum_{k} p_{k}^{\alpha}} P(i)=∑kpkαpiα
其中 p i p_{i} pi为第 i i i个transition的priority, α \alpha α用于调节优先程度( α = 0 \alpha=0 α=0的时候退化为均匀采样),以下两种方案的区别在于对priority的定义不同。
2.1.1 第一种变体:proportional prioritization(比例优先级)
p i = ∣ δ i ∣ + ϵ p_{i}=|\delta_{i}|+\epsilon pi=∣δi∣+ϵ ,其中 δ i \delta_{i} δi为TD-error, ϵ \epsilon ϵ用于防止概率为0,实现的时候采用sum tree的数据结构。
SumTree方法
1.为什么使用SumTree?
假设有一个数据列表,并且需要从列表中随机抽取数据。您可以做的一件事是生成一个介于零和列表大小之间的随机整数,并从列表中检索数据
#!/usr/bin/python
# -*- coding: utf-8 -*-
data_list = np.array(np.random.rand(100))
#数据生成
index = np.random.randint(0,len(data_list))
data = data_list [index]
print(data)
使用这种方法,将能够以等价方式从列表中获取数据。如果需要从列表中获得更高优先级的数据,该怎么办? 有没有一种可以为某些高优先级数据提供较高的检索率方法呢?
《1》 方法1: 尝试按优先级从高到低的顺序对数据列表进行排序。然后从生成器中获取一个随机数,该生成器有很大的机会给出接近零的数字,而当该数字远离零时则具有较低的机会。均值等于零的高斯随机数生成器可能会起作用。您可以相应地调整sigma。
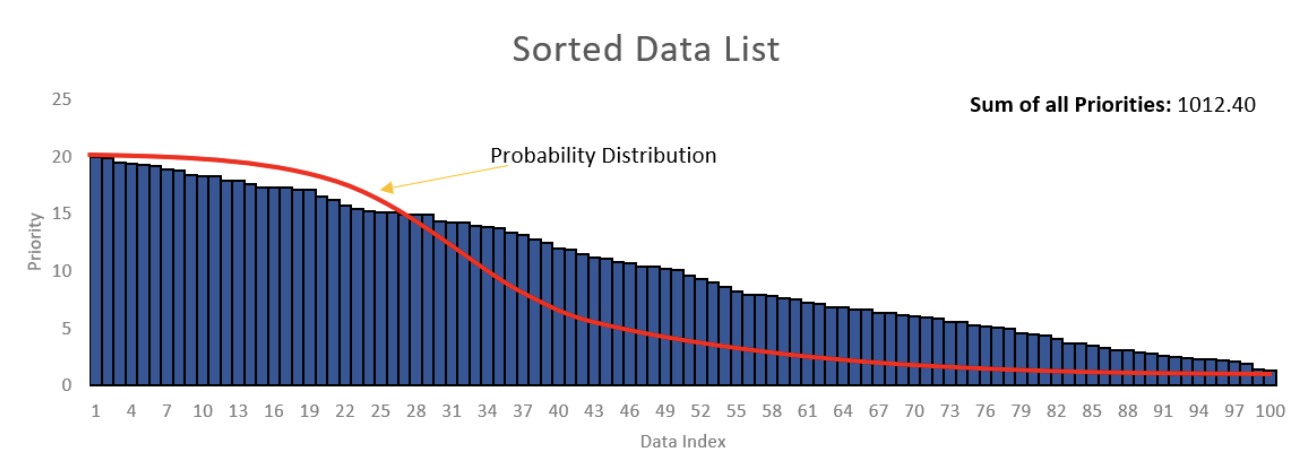
这里的主要问题是如何调整sigma以适合列表的大小。如果列表的大小增加了,那么您将需要再次调整sigma。另外,如果生成器提供的数字大于列表的大小,该怎么办?因此,该方法将不可行。
《2》 方法二:根据均匀分布在数据列表中的零和总优先级值之和之间生成一个随机数(在示例中为1012.4)。假设从随机数生成器获得了数字430.58。然后必须从左到右对列表的优先级值求和,直到总和超过430.58。
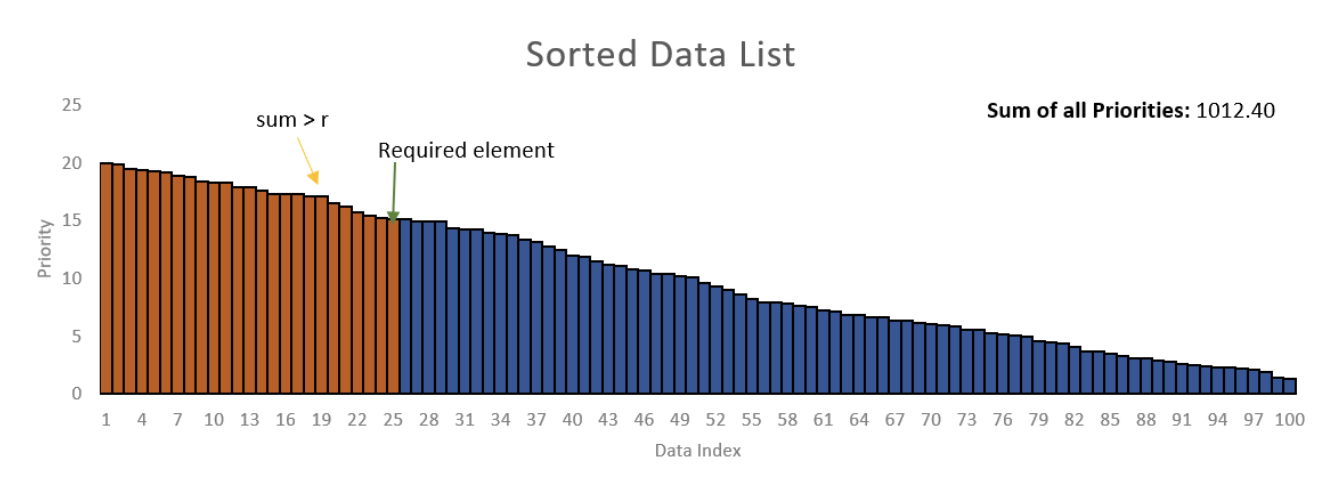
在上面的示例中,前24个元素427.7的总和为,而所有前25个元素的总和为442.8。因此,第25个元素是您需要从列表中检索的元素。但
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











