







这是一篇论文,https://arxiv.org/abs/1803.00933
其概念主要是对传统DQN ,DDPG使用分布式actor获取replay memory数据并进行优先经验回放方法,从而使强化学习网络训练得更有效率(现在强化学习NN训练难度确实很高,效率低,所以要尽可能提升效率,所以这篇文章还是有帮助的),作者主要以atari训练实验来证明其方法的优越性。(毕竟并行化获取经验)
主要架构如下
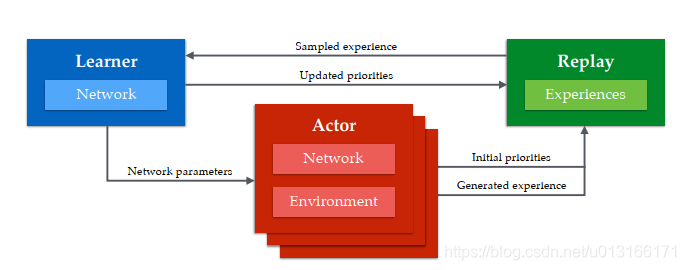
有多个actor,每隔一段时间同时从learner那获取actor和critic参数(从而更好决策),使用的greedy ε 探索参数不同(实验得出这样更好),然后在环境中act 并获得TD error(就是往后看n步)(见后文),计算经验优先级(见后文),存入replay中。然后每隔一段时间learning去取batch数据,更新网络参数,并根据经验新的“惊艳度”td-error更新经验优先值。

作者运用这个架构在dqn和ddpg上的实验效果明显,另外发现在增加不同探索参数actor总 数目的情况下,探索效率呈正比提升,而每个时间t内,收集的replay memory 单位大小选取2百万和2.5百万效果差距不大。
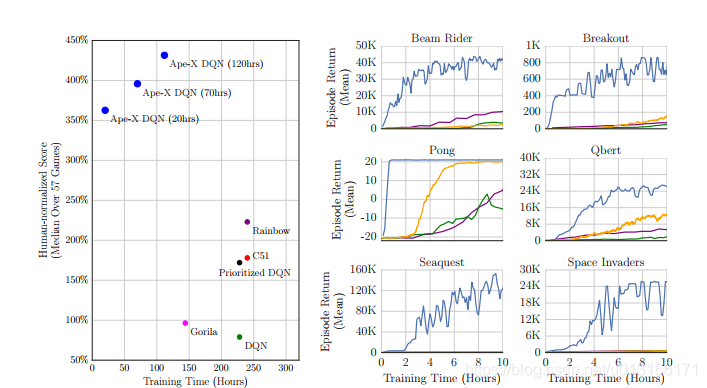
实验中有几个需要明白的细节,
-
随机梯度下降
随机梯度下降https://www.cnblogs.com/nolonely/p/6184196.html
就是随机抽取一部分样例进行梯度下降,性能提升且降低数据间相关度。
-
TDerror

因为loss中需要考虑用真实的价值前去估计的价值,真实的价值使用n步行为获取的reward及缓更新的q值替代,或能更精准更快收敛。
-
优先经验回放
https://www.cnblogs.com/wangxiaocvpr/p/5660232.html
文中就是根据tderror-惊奇度(我估计和实际Q值区别)来决定数据的优先级大小(惊奇度越大优先级越高,具体取法看上连接),另外加个e常数保证在开始训练时数据间差距不大时有近似均等的优先级,之后才逐渐产生优先级。















 1518
1518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









