







堆排序
堆排序可以达到O(NlogN)的最佳运行时间,实践中却慢于Sedgewick序列的希尔排序。
建立N个元素的二叉堆的的花费时间是O(N),然后执行N次DeleteMin操作,按顺序最小的元素先离开堆,将这些元素记录到第二个数组再将数组拷贝回来,得到N个元素的排序,每次DeleteMin花费时间O(logN),因此总的运行时间O(NlogN).
该算法主要问题在于使用了一个附加数组,存储需求增加一倍。避免使用附加数组的方法是在每次DeleteMin之后,将堆中最后的单元用来存放刚刚删去的元素,这样可以得到从大到小的数组。
在下面的实现中使用一个数组实现堆,因为实际的ADT较慢。第一步以线性时间建立一个堆,通过将堆中最后和第一个元素交换,缩减堆的大小并进行下滤,来执行N-1次DeleteMax操作,当算法终止,数组元素变为有序。如下图所示,输入序列为:31,41,59,26,53,58,97
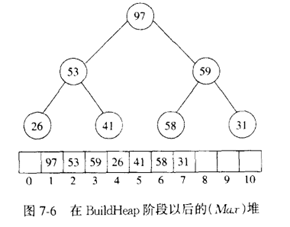
从堆中DeleteMax操作以后,堆数组放97那部分不再属于该堆。
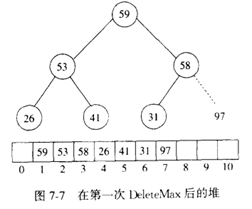
注意此处堆排序与二叉堆不同点在于此处数组包含了位置0处的数据。
代码:
#define LeftChild(i) (2*(i)+1)
void PercDown(int A[],int I,int N)
{
int Child;
int Tmp;
for(Tmp=A[i];LeftChild(i)<N;i=Child)
{
Child=LeftChild(i);
if(Child!=N-1&&A[Child+1]>A[Child])
Child++;
if(Tmp<A[Child])
A[i]=A[Child];
else
break;
}
A[i]=Temp;
}
void Heapsort(int A[],int N)
{
int i;
for(i=N/2;i>=0;i--)
PercDown(A,I,N);
for(i=N-1;i>0;i--)
{
Swap(&A[0],&A[i]);
PercDown(A,0,i);
}
}
堆排序的分析
第一阶段构建堆最多用到2N次比较,第二阶段第i次DeleteMax最多用到2[logi]次比较,最坏情况下为2NlogN-O(N)次比较。
经验指出堆排序是一个非常稳定的算法:平均使用的比较次数只比最坏情形下指出略少。
定理5:对N个互异项的随机排列进行堆排序,所用的平均比较次数为2NlogN-O(NloglogN)















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









