







概要
在本篇博客中,我们将通过一个实际的案例,演示如何使用Python进行数据清洗和可视化,以分析国际旅游收入数据。我们将使用Python中的Pandas库来进行数据处理和清洗,然后使用Matplotlib库来绘制饼图,展示各地区2017年至2019年国际旅游收入总和的占比情况。

整体流程
- 将表头统一为一行。
- 将地区字符串中的符号“?”,“ ”去除。
- 删除空白行。
- 删除重复行。
- 表格中第二列数据(B列)等于第三四五列之和,将第二、三、四、五列中的空值填充。
- 使用mean()填充第六列空值。
- 使用中位数法填充第7列空值。
- 使用四分位法对第8列数据进行异常值处理,并将异常值设置为该列均值。
- 使用除均值和中位数法以外的方法将第9和10列的空值填充。
- 结果保留一位小数
- 对数据绘制可视化饼图
名词解释
数据分析是指利用统计学和计算机科学的方法,对收集到的数据进行分析、解释和探索,从而发现数据中的模式、趋势和关联性,提取有用的信息和知识,并为决策和问题解决提供支持。数据分析可以应用于各个领域,包括商业、科学、工程、医疗等,帮助人们更好地理解数据、发现问题和机会,并制定合适的策略和方案。
数据分析的主要目标包括:
- 描述性分析:对数据进行汇总和描述,包括统计量的计算、图表的绘制等,以便对数据有一个整体的了解。
- 探索性分析:通过可视化和探索性数据分析(EDA),探索数据中的模式、趋势和关系,发现数据中的隐藏信息和规律。
- 预测性分析:利用统计和机器学习方法,建立模型来预测未来的趋势和行为,帮助做出更准确的预测和决策。
- 解释性分析:对模型和结果进行解释,理解模型背后的原理和机制,从而深入理解数据背后的规律和关联性。
数据分析通常涉及多种技术和工具,包括数据清洗、数据可视化、统计分析、机器学习等。通过对数据进行系统和深入的分析,可以发现数据中的价值和见解,为组织和个人提供更好的决策支持和业务洞察。
NumPy
- NumPy 是 Python 中用于科学计算的核心库之一,提供了高性能的多维数组对象和各种数学函数。它是许多其他数据分析工具的基础,如 Pandas 和 SciPy。
- NumPy 的核心是 ndarray(N-dimensional array)对象,可以用来存储和处理多维数组数据。它提供了各种函数和方法,可以进行数组的创建、索引、切片、数学运算、线性代数运算等操作。
Pandas
- Pandas 是 Python 中用于数据分析的核心库之一,提供了快速、灵活且高效的数据结构和数据操作工具。它的主要数据结构是 Series(一维数组)和 DataFrame(二维表格),可以轻松处理结构化数据。
- Pandas 提供了丰富的函数和方法,可以进行数据的加载、清洗、转换、分组、聚合等操作。它还支持对缺失值和异常值的处理,以及数据的合并和拆分等高级操作。
Matplotlib
- Matplotlib 是 Python 中用于创建可视化图表的主要库之一,提供了广泛的功能和灵活性。它可以创建各种类型的静态图表,如折线图、散点图、直方图等。
- Matplotlib 的设计灵感来自于 MATLAB,因此其语法和用法与 MATLAB 相似。它支持绘制高质量的图表,并且可以通过设置不同的样式和参数来定制图表的外观和风格。
re
- re 是 Python 中用于正则表达式操作的标准库,提供了强大的文本模式匹配和处理功能。正则表达式是一种强大的文本搜索和处理工具,可以用来查找、替换、分割等。
- re 库提供了各种函数和方法,可以用来编译和执行正则表达式,以及进行各种文本操作。它通常用于处理复杂的文本数据,如日志文件、网络数据等。
这些库在数据分析领域发挥着重要的作用,通过它们的组合,可以完成从数据加载到数据可视化的整个数据分析过程。
技术细节
首先安装Python🚪和Jupyter Lab,如果已经安装了这两个的话可以直接打开jupyter lab进行下一步
// 安装:
pip3 install jupyterlab
安装完成之后,可以查看版本号看安装是否成功
然后打开cmd命令行,进到你要打开的文件夹目录下,输入jupyter lab打开,通过以上步骤,你就可以成功安装和启动 Jupyter Lab,并开始使用它进行数据分析、机器学习、编程等工作了。
数据清洗
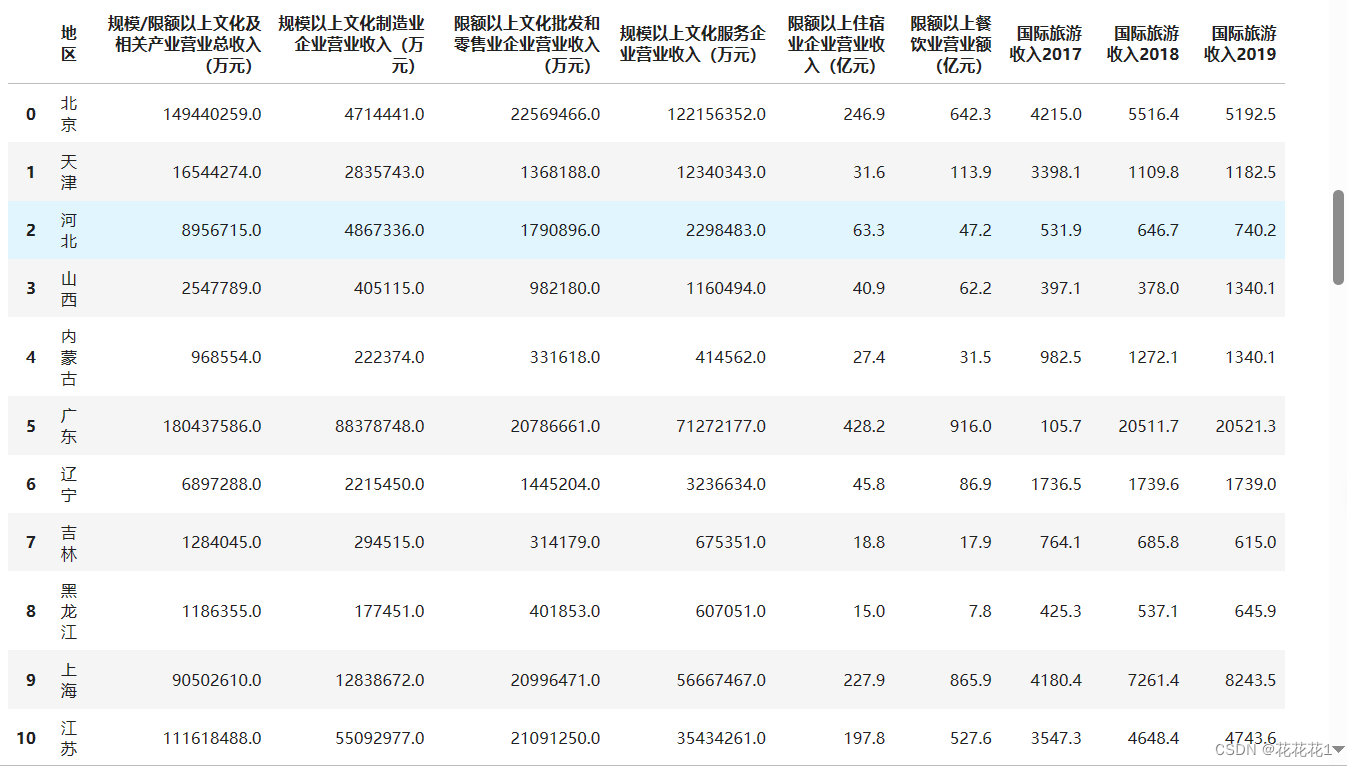
首先导入需要用来数据分析的依赖numpy,Pandas,Matplotlib.pyplot,re。再从excel文件中读取Excel 文件数据,并将读取的数据存储在名为 data 的 DataFrame 中。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re
path = 'chuji.xlsx'
data = pd.read_excel(path, engine='openpyxl') # 数据读取
将表头统一为一行:将data的列名(表头)设置为指定的列表,列表中的每个元素对应一个列名,再删除第一行数据,索引为 0 的行
data.columns = ['地区','规模/限额以上文化及相关产业营业总收入(万元)','规模以上文化制造业企业营业收入(万元)','限额以上文化批发和零售业企业营业收入(万元)','规模以上文化服务企业营业收入(万元)','限额以上住宿业企业营业收入(亿元)','限额以上餐饮业营业额(亿元)','国际旅游收入2017','国际旅游收入2018','国际旅游收入2019']
data = data.drop(0)
将地区字符串中的符号“?”,“ ”去除:使用了正则表达式模块 re 中的 sub() 函数来替换字符串中的匹配项。lambda x: re.sub(r'\s+', '', str(x)) if not pd.isna(x) else x 是一个匿名函数,这个函数首先检查元素是否为 NaN(缺失值),如果不是,则使用正则表达式 re.sub() 将字符串中的所有空格(\s+)替换为空字符串,从而去除空格。如果元素是NaN,则返回原始值。最后,使用 .apply() 函数将这个匿名函数应用于地区列中的每个元素,从而实现去除符号“?”和空格的操作。
data.iloc[:, 0] = data.iloc[:, 0].apply(lambda x: re.sub(r'\s+', '', str(x)) if not pd.isna(x) else x)
删除空白行和重复行:dropna() 方法来删除包含空值(NaN)的行,axis=0 参数指定了操作的轴向,这里设为 0 表示按行进行操作。how=‘all’ 参数指定了删除行的条件,这里设为 ‘all’ 表示当行中所有元素都是空值(NaN)时才删除该行。drop_duplicates() 方法来删除重复行,inplace=True 参数表示在原始 DataFrame 上进行操作,不创建新的 DataFrame。
data.dropna(axis=0, how='all', inplace=True)
data.drop_duplicates(inplace=True)
由于之前删除了空白行和重复行,所以要重设索引,使用 DataFrame 的 reset_index() 方法重新设置索引。参数 drop=True 表示丢弃原始索引,而不保留在 DataFrame 中作为新的列。重新设置索引后,DataFrame 的索引会按照从 0 开始的顺序重新排列。
data.reset_index(drop=True, inplace=True) # 重置索引
填充二三四五列数据:对第二列进行处理:data.iloc[:, 1].isnull().any():检查第二列是否存在空值。如果存在空值,则使用 fillna() 方法填充空值。填充值为第三、四、五列之和,使用 data.iloc[:, 2] +data.iloc[:, 3] + data.iloc[:, 4] 计算。同时使用 astype(data.iloc[:, 1].dtype) 将填后的数据类型转换为第二列原始的数据类型,以保持数据一致性。其它三列也是相同的处理方法
# 如果第二列为空值,求和第三四五列
if data.iloc[:, 1].isnull().any():
data.iloc[:, 1] = data.iloc[:, 1].fillna(data.iloc[:, 2] + data.iloc[:, 3] + data.iloc[:, 4]).astype(data.iloc[:, 1].dtype)
# 对第三列进行空值判断
if data.iloc[:, 2].isnull().any():
data.iloc[:, 2] = data.iloc[:, 2].fillna(data.iloc[:, 1] - data.iloc[:, 3] - data.iloc[:, 4]).astype(data.iloc[:, 2].dtype)
# 对第四列进行空值判断
if data.iloc[:, 3].isnull().any():
data.iloc[:, 3] = data.iloc[:, 3].fillna(data.iloc[:, 1] - data.iloc[:, 2] - data.iloc[:, 4]).astype(data.iloc[:, 3].dtype)
# 对第五列进行空值判断
if data.iloc[:, 4].isnull().any():
data.iloc[:, 4] = data.iloc[:, 4].fillna(data.iloc[:, 1] - data.iloc[:, 2] - data.iloc[:, 3]).astype(data.iloc[:, 4].dtype)
第六列数据:使用 mean() 方法获取列的均值,使用 fillna() 方法填充第六列的空值。填充值为前面计算得到的均值 mean_value
mean_value = data.iloc[:, 5].mean()
data.iloc[:, 5].fillna(mean_value, inplace=True)
第七列数据:使用 median() 方法获取列的中位数,使用 fillna() 方法填充第七列的空值。填充值为前面计算得到的中位数 median_value
median_value = data.iloc[:, 6].median()
data.iloc[:, 6].fillna(median_value, inplace=True)
第八列数据:首先,计算第八列数据的四分位数和 IQR = Q3 - Q1(四分位间距):计算第八列数据的第一四分位数(25th percentile)。计算第八列数据的第三四分位数(75th percentile)。接着,计算异常值的上下界,使用 np.where() 函数将超出异常值范围的值替换为该列的均值
Q1 = data.iloc[:, 7].quantile(0.25)
Q3 = data.iloc[:, 7].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
data.iloc[:, 7] = np.where((data.iloc[:, 7] < lower_bound) | (data.iloc[:, 7] > upper_bound), mean_value, data.iloc[:, 7])
第九、十列数据:参数 method='ffill' 表示使用前向填充法,即用前一个非空值填充当前空值。参数 method='bfill' 表示使用后向填充法,即用后一个非空值填充当前空值。
data.iloc[:, 8].fillna(method='ffill', inplace=True) # 前向填充第9列
data.iloc[:, 9].fillna(method='bfill', inplace=True) # 后向填充第10列
所有结果保留一位小数:使用 for 循环遍历索引范围从 0 到 10,即遍历所有列。round() 方法是 Python 中用于四舍五入的函数,参数 1 表示保留一位小数。
for i in range(0,10):
data.iloc[:, i] = data.iloc[:, i].round(1)
可视化
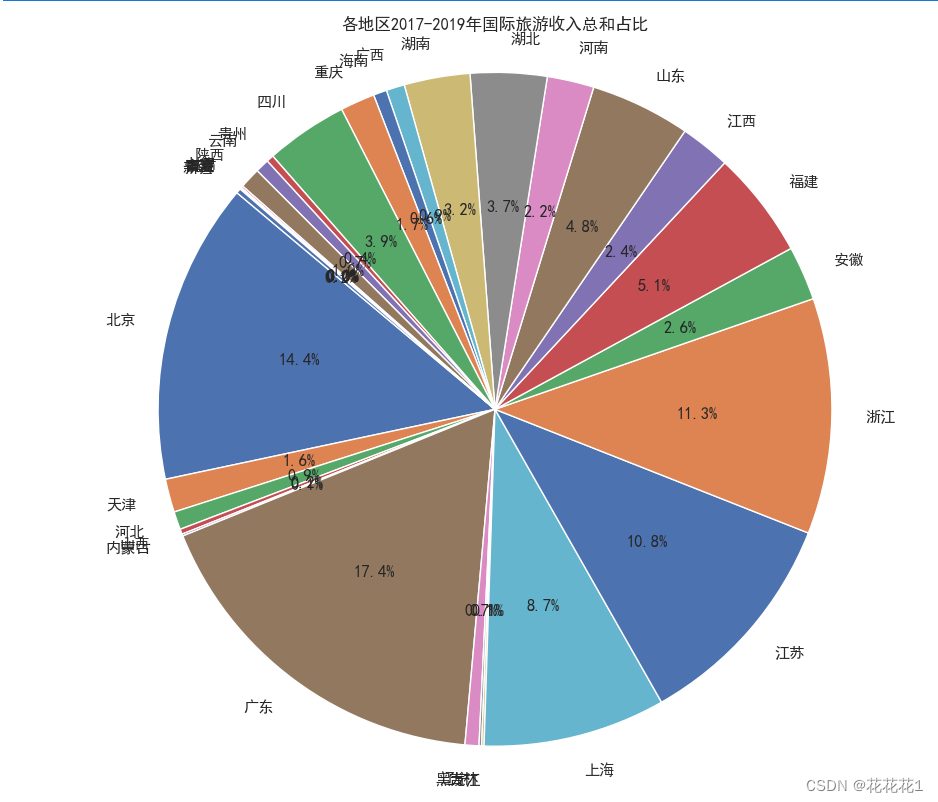
在清洗和预处理完数据之后,我们可以使用Matplotlib库来绘制饼图,展示各地区2017年至2019年国际旅游收入总和的占比情况。
设置中文显示:用于设置字体为中文,以及解决坐标轴负号显示问题
plt.rcParams['font.sans-serif'] = ['simHei']
plt.rcParams['axes.unicode_minus'] = False
将每个地区2017年至2019年国际旅游收入的总和计算出来,并存储在名为"总收入"的新列中
data['总收入'] = data.iloc[:, 1:].sum(axis=1)
创建了一个大小为10x8英寸的画布,用于绘制饼图
plt.figure(figsize=(10, 8))
绘制了饼图,其中data[‘总收入’]是各地区收入总和的数据,labels是各地区的标签,autopct='%1.1f%%'是指定了数据标签的显示格式,startangle=140是设置了起始角度为140度
plt.pie(data['总收入'], labels=data['地区'], autopct='%1.1f%%', startangle=140)
添加了饼图的标题
plt.title('各地区2017-2019年国际旅游收入总和占比')
调整了布局,使得图形更加美观
plt.tight_layout()
保持饼图的长宽比相等,然后plt.show()将绘制好的图形显示出来
plt.axis('equal')
plt.show()
小结
通过本篇博客,我们学习了如何使用Python进行数据清洗和可视化分析。首先,我们使用Pandas库对数据进行了清洗和预处理,然后利用Matplotlib库绘制了饼图,展示了各地区2017年至2019年国际旅游收入总和的占比情况。这个案例展示了Python在数据分析领域的强大应用和灵活性
希望本文能够帮助读者更好地了解的Python在数据分析方面的使用,如果有任何疑问或者建议,欢迎留言讨论🌹















 2070
2070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









