









欢迎加入学习交流QQ群:657341423
PyOCR是一个用于python的光学字符识别(OCR)工具包装器。也就是说,它有助于使用Python程序中的OCR工具。
安装:pip install pyocr
还需安装PIL:pip install Pillow
PIL主要用于打开图片以及一些处理
此外最重要需要安装OCR引擎,官网原文:PyOCR可以用作google的Tesseract-OCR或Cuneiform 的包装器 。它可以读取Pillow支持的所有图像类型 ,包括jpeg,png,gif,bmp,tiff和其他。它还支持边界框数据。
下载Tesseract-OCR引擎,注意要3.0以上才支持中文哦,按照提示安装就行(window下安装)
Tesseract直接网上搜EXE安装包直接安装即可。
注意在 “Language data” 那个选项里,默认是只勾选了英文的,如果需要进行其他语言的识别,记得勾选对应的语言。
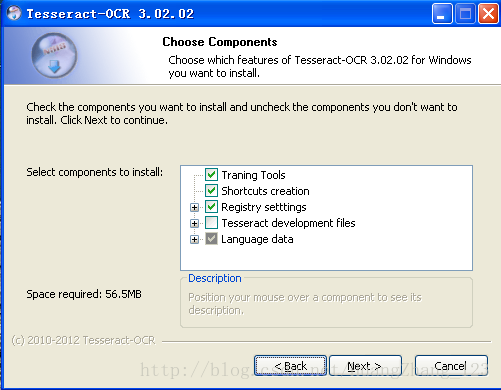
再一个是,如果需要进行相应的开发工作,建立把 “Tesseract development files” 这个选项也勾选。不过这个需要链接谷歌网址下载文件的。需跳墙。
识别中文,下载chi_sim.traineddata,然后直接放到C:\Program Files (x86)\Tesseract-OCR\tessdata文件夹下。
然后在chi_sim.traineddata(注意版本)文件目录下(…/Tesseract-OCR/tessdata),使用命令行执行:
combine_tessdata -e chi_sim.traineddata chi_sim.config
执行完后,在目录下出现chi_sim.config的文件,打开该文件;
在allow_blob_division F这一行的前面加#,注释掉
即:# allow_blob_division F
然后,在执行命令行:
combine_tessdata -o chi_sim.traineddata chi_sim.config
Python代码:
# coding=utf-8
import sys
import os
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
try:
from pyocr import pyocr
from PIL import Image
except ImportError:
raise SystemExit
#导入库
tools = pyocr.get_available_tools()[:]
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
#查找OCR引擎
print ("Using '%s'" % (tools[0].get_name()))
print (tools[0].image_to_string(Image.open('E:\\bb.png'),lang='chi_sim'))
#lang='chi_sim'为OCR的识别语言库。C:\Program Files (x86)\Tesseract-OCR\tessdata
由于中文识别效果不太理想,可以通过中文训练,具体参考:
http://www.cnblogs.com/wzben/p/5930538.html
参考资料:pyocr:https://github.com/jflesch/pyocr
欢迎加入学习交流QQ群:657341423















 1686
1686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











