







强烈推荐,刷PTA的朋友都认识一下柳神–PTA解法大佬
本文由参考于柳神博客写成
还有就是非常非常有用的 算法笔记 全名是
算法笔记 上级训练实战指南 //这本都是PTA的题解
算法笔记
PS 今天也要加油鸭

题目原文
Given a non-empty tree with root R, and with weight W**i assigned to each tree node T**i. The weight of a path from *R* to *L* is defined to be the sum of the weights of all the nodes along the path from R to any leaf node L.
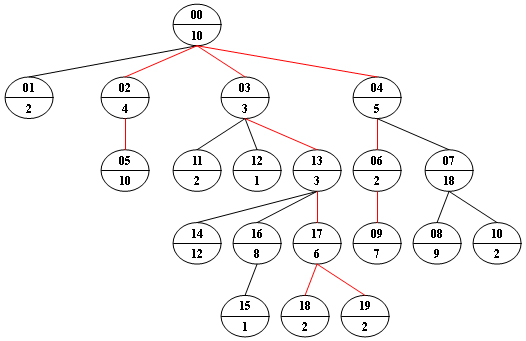
Now given any weighted tree, you are supposed to find all the paths with their weights equal to a given number. For example, let’s consider the tree showed in the following figure: for each node, the upper number is the node ID which is a two-digit number, and the lower number is the weight of that node. Suppose that the given number is 24, then there exists 4 different paths which have the same given weight: {10 5 2 7}, {10 4 10}, {10 3 3 6 2} and {10 3 3 6 2}, which correspond to the red edges in the figure.
Input Specification:
Each input file contains one test case. Each case starts with a line containing 0<N≤100, the number of nodes in a tree, M (<N), the number of non-leaf nodes, and 0<S<230, the given weight number. The next line contains N positive numbers where W**i (<1000) corresponds to the tree node T**i. Then M lines follow, each in the format:
ID K ID[1] ID[2] ... ID[K]
where ID is a two-digit number representing a given non-leaf node, K is the number of its children, followed by a sequence of two-digit ID's of its children. For the sake of simplicity, let us fix the root ID to be 00.
Output Specification:
For each test case, print all the paths with weight S in non-increasing order. Each path occupies a line with printed weights from the root to the leaf in order. All the numbers must be separated by a space with no extra space at the end of the line.
Note: sequence {A1,A2,⋯,A**n} is said to be greater than sequence {B1,B2,⋯,B**m} if there exists 1≤k<min{n,m} such that A**i=B**i for i=1,⋯,k, and A**k+1>B**k+1.
Sample Input:
20 9 24
10 2 4 3 5 10 2 18 9 7 2 2 1 3 12 1 8 6 2 2
00 4 01 02 03 04
02 1 05
04 2 06 07
03 3 11 12 13
06 1 09
07 2 08 10
16 1 15
13 3 14 16 17
17 2 18 19
Sample Output:
10 5 2 7
10 4 10
10 3 3 6 2
10 3 3 6 2
Special thanks to Zhang Yuan and Yang Han for their contribution to the judge’s data.
生词如下:
correspond 一致
figure 图形
PS:吐槽,一开始是没看懂来着,但是题目都做了那么多了,加上自己猜猜看,意识也就基本猜出来了.
题目大意:
给你一颗带质量的树.
然后给你一个质量 S,
要你算出有多少种分支,就是根节点到叶子节点. 他们的质量之和是等于S的
可能有多种分支,要你排序.
就是{A1,A2,⋯,A**n} 和{B1,B2,⋯,B**m}
A(K+1)>B(K+1) K+1是下标
我的思路如下:
就是多一个vector然后排序的事
还是可以用DFS做.
PS:主要是因为我BFS用的不是很多.没有DFS会
失败了.我的思路,我还是不懂递归.
柳神的思路:
分析:对于接收孩子结点的数据时,每次完全接收完就对孩子结点按照权值进行排序(序号变,根据权值变),这样保证深度优先遍历的时候直接输出就能输出从大到小的顺序。
记录路径采取这样的方式:首先建立一个path数组,传入一个nodeNum记录对当前路径来说这是第几个结点(这样直接在path[nodeNum]里面存储当前结点的孩子结点的序号,这样可以保证在先判断return的时候,path是从0~numNum-1的值确实是要求的路径结点)。
然后每次要遍历下一个孩子结点的之前,令path[nodeNum] = 孩子结点的序号,这样就保证了在return的时候当前path里面从0~nodeNum-1的值就是要输出的路径的结点序号,输出这个序号的权值即可,直接在return语句里面输出。
注意:当sum==target的时候,记得判断是否孩子结点是空,要不然如果不空说明没有到底部,就直接return而不是输出路径。。。(这对接下来的孩子结点都是正数才有用,负权无用)
代码如下:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int target;
struct NODE {
int w;
vector<int> child;
};
vector<NODE> v;
vector<int> path;
void dfs(int index, int nodeNum, int sum) {
if (sum > target) return;
if (sum == target) {
if (v[index].child.size() != 0) return; //不到叶子节点,质量就满了
for (int i = 0; i < nodeNum; i++)
printf("%d%c", v[path[i]].w, i != nodeNum - 1 ? ' ' : '\n');
return;
}
for (int i = 0; i < v[index].child.size(); i++) {
int node = v[index].child[i];
path[nodeNum] = node; //用path[nodeNum]来存储我们放的节点,存的也都是下标
dfs(node, nodeNum + 1, sum + v[node].w); //一般的巧妙
}
}
int cmp1(int a, int b) {
return v[a].w > v[b].w; //这个cmp原来是这样写的
}
int main() {
int n, m, node, k;
scanf("%d %d %d", &n, &m, &target); //吐槽,这个target就用的比我的好.英语也要加强
v.resize(n), path.resize(n); //经典的resize(n)
for (int i = 0; i < n; i++)
scanf("%d", &v[i].w); //保存质量
for (int i = 0; i < m; i++) {
scanf("%d %d", &node, &k);
v[node].child.resize(k);
for (int j = 0; j < k; j++)
scanf("%d", &v[node].child[j]);
sort(v[node].child.begin(), v[node].child.end(), cmp1);
}
dfs(0, 1, v[0].w);
return 0;
}
算法笔记的代码:
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
const int MAXN = 110;
struct node {
int weight;
vector<int> child;
}Node[MAXN];
bool cmp1(int a, int b) {
return Node[a].weight > Node[b].weight;
}
int n, m, S, path[MAXN];
void DFS(int index, int numNode, int sum) {
if (sum > S) return;
if (sum == S) {
if (Node[index].child.size() != 0) return;
for (int i = 0; i < numNode; ++i) {
printf("%d", Node[path[i]].weight);
if (i < numNode - 1) printf(" ");
else printf("\n");
}
return;
}
for (int i = 0; i < Node[index].child.size(); ++i) {
int child = Node[index].child[i];
path[numNode] = child;
DFS(child, numNode + 1, sum + Node[child].weight);
}
}
int main() {
scanf("%d%d%d", &n, &m, &S);
for (int i = 0; i < n; ++i) scanf("%d", &Node[i].weight);
int id, k, child;
for (int i = 0; i < m; ++i) {
scanf("%d%d", &id, &k);
for (int j = 0; j < k; ++j) {
scanf("%d", &child);
Node[id].child.push_back(child);
}
sort(Node[id].child.begin(), Node[id].child.end(), cmp1);
}
path[0] = 0;
DFS(0, 1, Node[0].weight);
return 0;
}
思路都是一样的讲.
总结:
我还需要一段时间,才能写出柳神一样的代码,她的代码非常的优美,还有简洁.
如果这篇文章对你有张帮助的话,可以用你高贵的小手给我点一个免费的赞吗
相信我,你也能变成光.

如果你有任何建议,或者是发现了我的错误,欢迎评论留言指出.















 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









