







练习数据准备

demo.xlsx中的工作表Sheet1显示上述的数据,Sheet2没有数据
我们可以使用Pandas中的read_excel()方法读取Excel格式的数据文件,生成DataFrame数据框进行数据分析处理
基本语法格式
import pandas as pd
pd.read_excel(io, sheet_name=0, header=0, names=None, dtype=None)参数说明
| 常用参数 | 描述说明 |
| io | 文件路径 |
| sheet_name | 访问Excel指定的工作表,默认读取第一个工作表 |
| header | 指定数据的标题行,也就是数据的列名(如果不指定,默认第一行作为标题行) |
| names | 指定列名 |
| dtype | 指定某字段的数据类型 |
下面我们对上述常用的参数进行实际运用与讲解
1.io参数
io为第一个参数,没有默认值,也不能为空,直接执行read_excel()函数会报错
import pandas as pd
# TypeError: read_excel() missing 1 required positional argument: 'io'
pd.read_excel()import pandas as pd
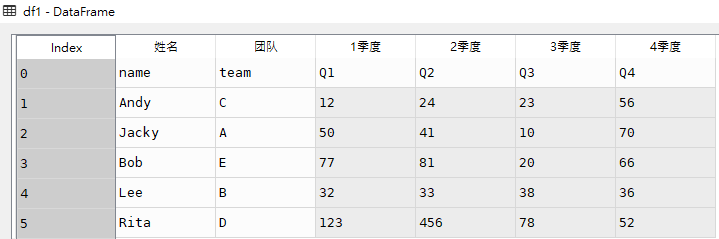
# 读取demo.xlsx文件数据
df1 = pd.read_excel(r'C:\Users\X2001565\Desktop\test\demo.xlsx')df1
2.sheet_name参数
sheet_name可以指定Excel文件读取哪个sheet,如果不指定,默认读取第一个sheet工作表
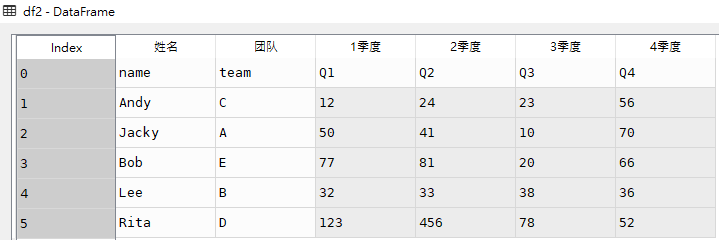
# 不指定sheetname,默认sheetname=0,读取第一个sheet工作表
# pd.read_excel(r'C:\Users\X2001565\Desktop\test\demo.xlsx')
df2 = pd.read_excel(r'C:\Users\X2001565\Desktop\test\demo.xlsx', sheet_name=0)df2
# 读取demo.xlsx第2个sheet工作表,由于该文件第2个工作表没有数据,所以生成的df3也没有数据
df3 = pd.read_excel(r'C:\Users\X2001565\Desktop\test\demo.xlsx', sheet_name=1)
'''
Empty DataFrame
Columns: []
Index: []
'''
print(df3)3.header参数
header参数是用来指定数据的标题行,也就是数据的列名。如果不指定,默认第一行作为标题行(默认header=0是使用第一行数据作为数据的列名)
# 第二行为表头
df4 = pd.read_excel(r'C:\Users\X2001565\Desktop\test\demo.xlsx', header=1)df4

header=1, df4指定使用第二行的英文列名
我们也可以将参数header的值设置为None,不设置表头
# 不设表头
df5 = pd.read_excel(r'C:\Users\X2001565\Desktop\test\demo.xlsx', header=None)df5

4.names参数
用names参数可指定列名,也就是表头的名称,如果不指定,默认为表头的名称
import pandas as pd
df6 = pd.read_excel(r'C:\Users\X2001565\Desktop\test\demo.xlsx',header=1)df6

如果数据已经有了列名,names参数将会替换掉原有的列名
import pandas as pd
df6 = pd.read_excel(r'C:\Users\X2001565\Desktop\test\demo.xlsx',header=1, names=list('ABCDEF')处理过后的df6

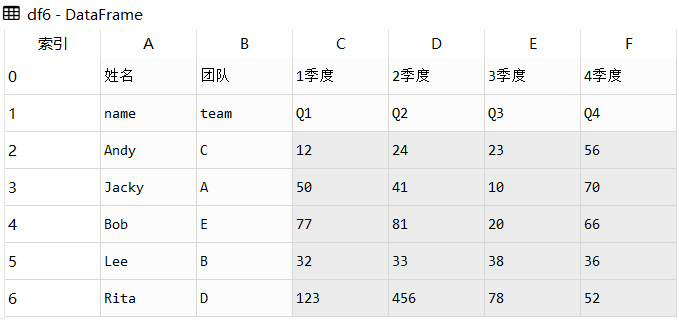
如果只想使用names,而又对源数据不做任何修改,我们可以指定header=None
import pandas as pd
df6 = pd.read_excel(r'C:\Users\X2001565\Desktop\test\demo.xlsx',header=None, names=list('ABCDEF')处理过后的df6
5.dtype参数
用dtype参数可指定某字段的数据类型
df7 = pd.read_excel(r'C:\Users\X2001565\Desktop\test\demo.xlsx', header=1)
# dtype('int64')
df7['Q2'].dtypedf7

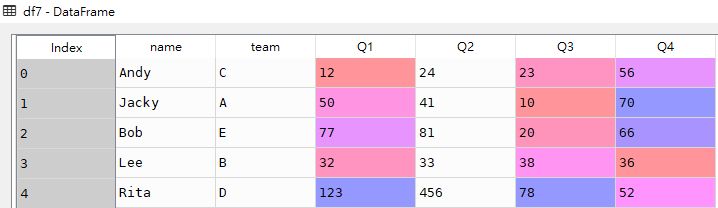
指定'Q2'字段的数据类型(更改为Object类型)
df7 = pd.read_excel(r'C:\Users\X2001565\Desktop\test\demo.xlsx', header=1, dtype={'Q2': str})
# dtype('O')
df7['Q2'].dtype处理过后的df7














 2253
2253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









