







本文由 Teven Le Scao、Patrick Von Platen、Suraj Patil、Yacine Jernite 和 Victor Sanh 共同撰写。
每个月,我们都会选择一个重点主题,阅读有关该主题的最近发表的四篇论文。然后,我们会写一篇简短的博文,总结这些论文各自的发现及它们呈现出的共同趋势,并阐述它们对于我们后续工作的指导意义。2021 年 1 月的主题是 稀疏性和剪枝,本月 (2021 年 2 月),我们的主题是 transfomer 模型中的长程注意力。
引言
2018 年和 2019 年,大型 transformer 模型兴起之后,两种技术趋势迅速崛起,意在降低这类模型的计算需求。首先,条件计算、量化、蒸馏和剪枝解锁了计算受限环境中的大模型推理; 我们已经在 上一篇阅读小组帖子 中探讨了这一话题。随后,研究人员开始研究如何降低预训练成本。
特别地,大家的工作一直围绕一个核心问题: transformer 模型的内存和时间复杂度与序列长度呈二次方关系。为了高效地训练大模型,2020 年发表了大量论文来解决这一瓶颈,这些论文成果斐然,年初我们训练 transformer 模型的默认训练序列长度还是 512 或 1024,一年之内的现在,我们已经突破这个值了。
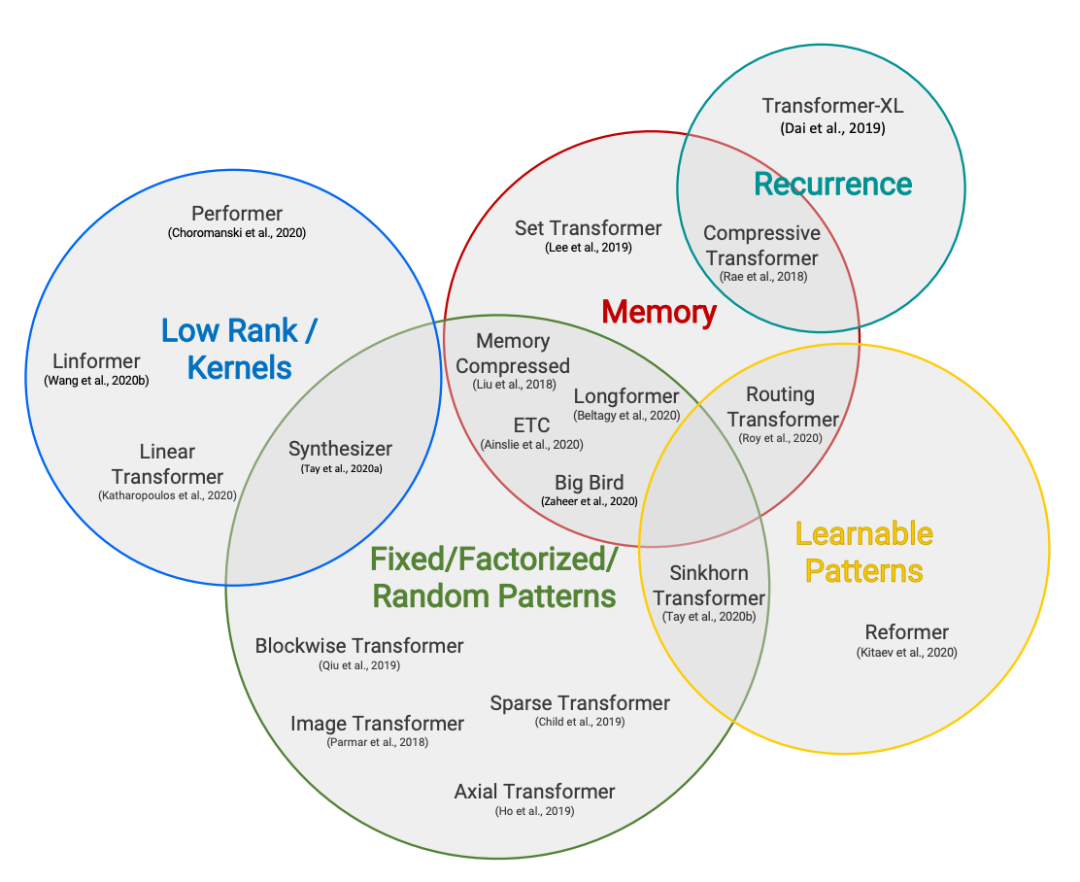
长程注意力从一开始就是我们研究和讨论的关键话题之一,我们 Hugging Face 的 Patrick Von Platen 同学甚至还专门为 Reformer 撰写了一篇 由 4 部分组成的博文。本文,我们不会试图涵盖每种方法 (太多了,根本搞不完!),而是重点关注四个主要思想:
自定义注意力模式 (使用 Longformer)
循环 (使用 Compressive Transformer)
低秩逼近 (使用 Linformer)
核逼近 (使用 Performer)
有关这一领域的详尽概述,可阅读 Efficient Transformers: A Survey 和 Long Range Arena 这两篇综述论文。
总结
Longformer - The Long-Document Transformer
作者: Iz Beltagy, Matthew E. Peters, Arman Cohan
Longformer 通过将传统的自注意力替换为滑窗注意力 + 局部注意力 + 稀疏注意力 (参见 Sparse Transformers (2019)) 以及全局注意力的组合以解决 transformer 的内存瓶颈,使其随序列长度线性缩放。与之前的长程 transformer 模型相反 (如 Transformer-XL (2019)、Reformer (2020), Adaptive Attention Span (2019)),Longformer 的自注意力层可以即插即用直接替换标准的自注意力层,因此在长序列任务上,可以直接用它对预训练的标准注意力 checkpoint 进行进一步更新训练和/或微调。
标准自注意力矩阵 (图 a) 与输入长度呈二次方关系:
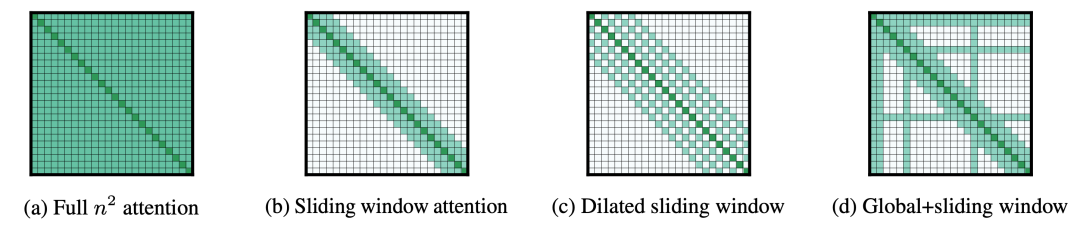
Longformer 使用不同的注意力模式执行自回归语言建模、编码器预训练和微调以及序列到序列任务。
对于自回归语言模型,通过将因果自注意力 (如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









