










TCPL(The C Programming Language)对自增和自减运算符的叙述并不多。在中文版的12页(英文版18页)和37页(英文版46页)中,只是简单地标明TCPL这本书会同意使用前缀形式,并用一段话解释了两者对值和值+1先后的区别。
之所以纠结这个,是因为用C语言写单片机的程序的时候,有的老师会强调++i和i++在使用的时候没有区别。那这这两个语句在汇编层到底是怎样的呢?
然后我就用简单的几行代码测试了一下,代码如下:
int main()
{
int a = 0, c = 0;
c = a++;
c = ++a;
printf("%d", a);
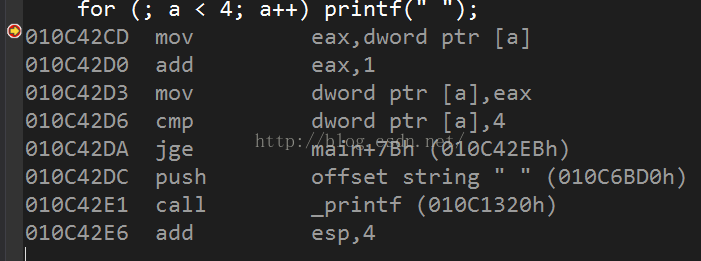
for (; a < 4; a++) printf(" ");
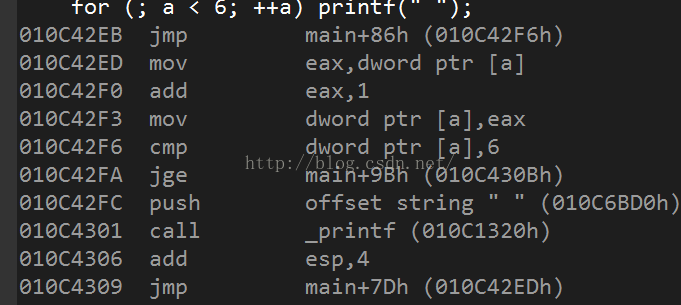
for (; a < 6; ++a) printf(" ");
getchar();
return 0;
}其中只要是单独出现的a++和++a。那么,他们的汇编语句就是一样的。不但行数一样,顺序也是相同的。
int a = 0;
0027179E mov dword ptr [a],0
a++;
002717A5 mov eax,dword ptr [a]
002717A8 add eax,1
002717AB mov dword ptr [a],eax
++a;
002717AE mov eax,dword ptr [a]
002717B1 add eax,1
002717B4 mov dword ptr [a],eax
在for循环中的前置语句和后置语句:
而当使用赋值语句的时候,前置和后置在汇编层就不一样了。
int a = 0, c = 0;
000F179E mov dword ptr [a],0
000F17A5 mov dword ptr [c],0
c = a++;
000F17AC mov eax,dword ptr [a]
000F17AF mov dword ptr [c],eax
000F17B2 mov ecx,dword ptr [a]
000F17B5 add ecx,1
000F17B8 mov dword ptr [a],ecx
c = ++a;
000F17BB mov eax,dword ptr [a]
000F17BE add eax,1
000F17C1 mov dword ptr [a],eax
000F17C4 mov ecx,dword ptr [a]
000F17C7 mov dword ptr [c],ecx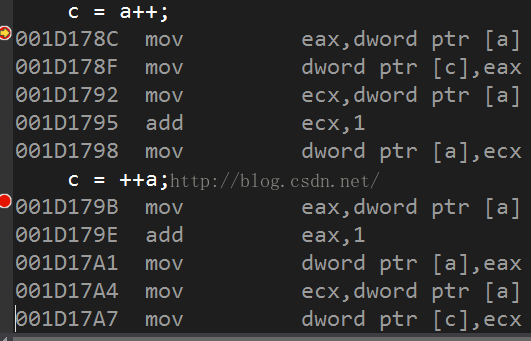
但我们仍然能看到,不管是前置语句,还是后置语句,在汇编层语句的数量上是一样的,占用的空间和时间相同。那么,在网上经常搜到的前置语句和后置语句的效率问题又是什么导致的呢?
答案是:运算符重载。
在第五版C++ Primer的502页(英文版566页)上是这样定义前置和后置自增:
class StrBlobPtr
{
public:
strBlobPtr& operator++();
};
StrBlobPtr& StrBlobPtr::operator++()
{
check(curr,"increment past end of StrBlobPtr");
++curr;
return *this;
}
class StrBlobPtr
{
public:
strBlobPtr& operator++(int);
};
StrBlobPtr& StrBlobPtr::operator++(int)
{
StrBlobPtr ret = *this;
++ *this;
return ret;
}而且书上强调了“定义自增自减的运算符的类,需要同时定义前置和后置两个版本。”所以效率问题应该是仅对比两者的定义。
前置中多了函数检验,但从传递和值的返回上来看,后置返回的形式是一个值而非引用。而且因为要解决普通重载形式无法区分两种情况(因为使用的是同一个符号),所以后置版本需要额外接受一个int形参(不过,这个仅仅是为了区分,并非真的参与运算)。这两个重载在汇编层面的语句就切切实实的分开了,于是后置在某些场景中的使用速度比前置要低。















 631
631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









