









Paper List
- Going Deeper with Convolutions
- Rethinking the Inception Architecture for Computer Vision
- Deep Residual Learning for Image Recognition
- Inception-v4,Inception-ResNet and the Impact of Residual Connections on Learning
- Identity Mappings in Deep Residual Networks
- Deep Networks with Stochastic Depth
- Generative Adversarial Nets
- Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
- Improved Techniques for Training GANs
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
- Generative Adversarial Text to Image Synthesis
- Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Going Deeper with Convolutions
本文主要提出了一个新的框架,旨在加宽神经网络,从而增强神经网络能力。
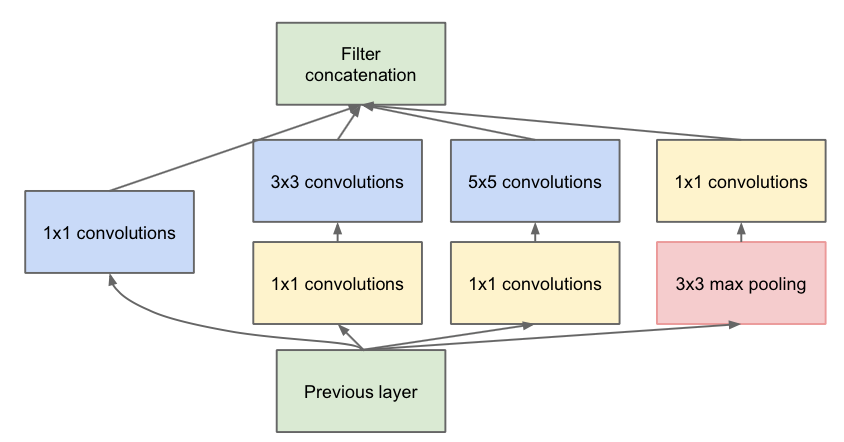
其中1x1是用来进行降维的。不同的卷积核大小是为了增加网络对尺度的适应性。
Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift
这篇论文主要是提出了BN的方法,用于归一化数据,论文中说能使用BN可以使用更高的学习率,降低L2的权重系数,取消LRN(这个貌似如今都不用了)等。此外提出了使用2个3x3卷积替代5x5卷积的方法。不过3x3的卷积(加入了padding)也可以用2个2x2(其中一个加padding,另一个不加padding)来替代。不过当用2x2时效果一般不明显,甚至变差。
Rethinking the Inception Architecture for Computer Vision
本论文提出了InceptionV3模型,主要是讲卷积进行对称分解的操作。即将3x3分解成1x3和3x1。
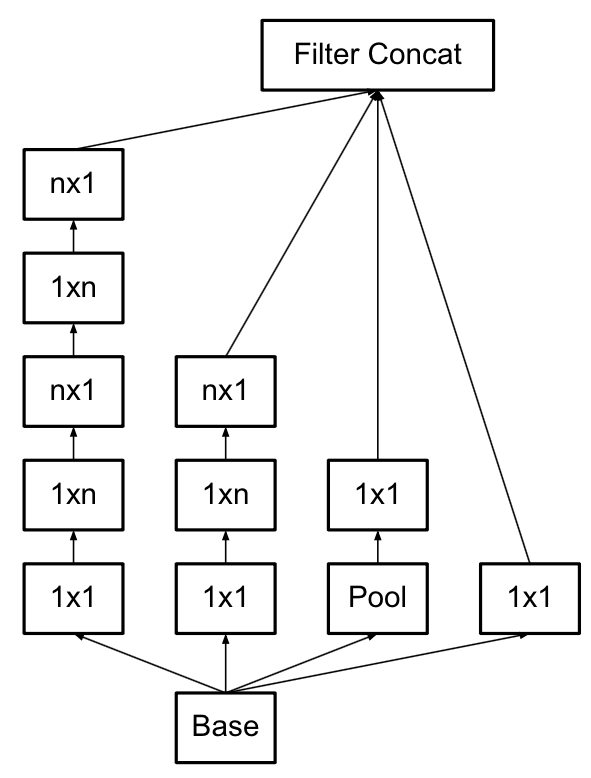
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
这篇论文主要是结合ResNet的思想,如下图所示:
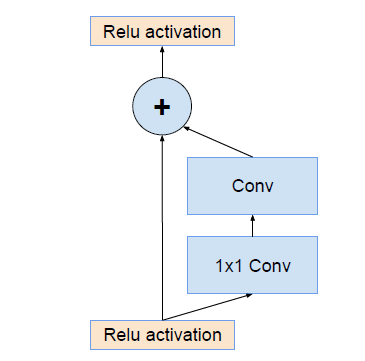
提出了Inception-ResNet结构,类似下图
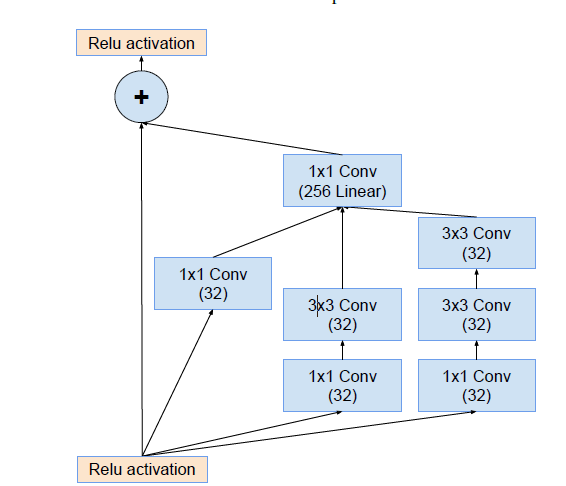
Inception总结
Inception的结构主要是改变最初卷积网络的简单堆叠层的方法。通过加宽网络,同时将不同的卷积核大小进行分解。还利用了1x1降维的方式。由于神经网络过于复杂,中间层提取的特征对于最终所需要的往往过量,而通过在每次卷积前进行降维,从而减少计算量。并且不会丢失关键性的特征。
Deep Residual Learning for Image Recognition
这篇论文的主要思想在与前一层到后一层设置了一个直接的通路。即shortcut connections。
这个类似HighWay network。在HighWay network中前一层到后一层的映射除了正常的方式之外,也有直接映射。只不过它将两种方式以学习的权重进行结合。在ResNet中,这种结合以相同权重方式进行。
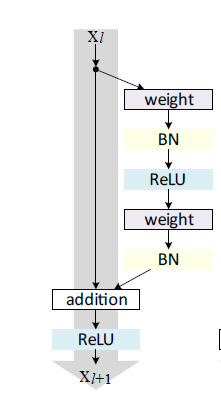
右侧的computation path是构建一个残差,如果能用几层网络去逼近一个复杂的非线性映射H(x),那么同样可以用这几层网络去逼近它的residual function:F(x)=H(x)−x,人们认为逼近残差会容易一些。在ResNet-152中,该结构右侧有3个卷积层。第一个weight变成1x1的卷积,单纯用来进行核心计算前的降维。中间的卷积层是核心计算层,主要进行复杂映射。最后一个卷积层用于升维,防止维度降得过低导致模型能力下降。这种方式构建的块成为一个bottlenet。如下图所示:

在核心计算为64层的bottlenet叠加3个后,再升维到核心计算为128维。再进行多个同等复杂度的bottlenet的叠加。第一组主要是拟合64维度的特征映射,第二组要拟合128维的映射,随着维度的升高,每组的bottlenet个数显著增加,这可能是因为随着维度的升高,更好的拟合需要更多的卷积叠加,以便获得更加精确的拟合效果。
Identity Mappings in Deep Residual Networks
这篇论文主要是将ResNet核心结构进行简单的改变。
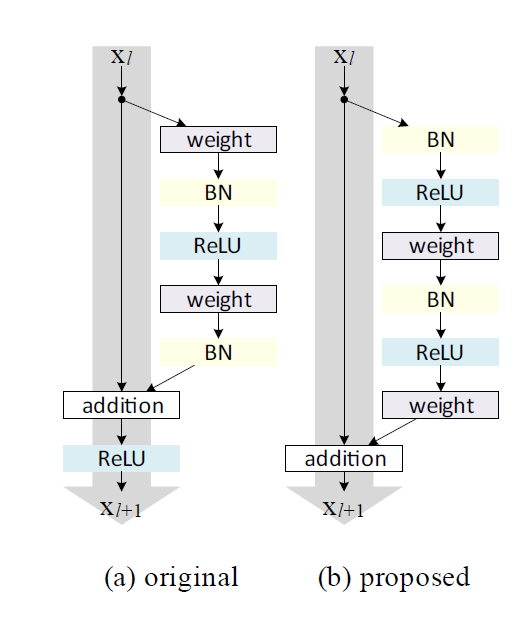
主要的变化是将BN和ReLU作为“预激活”,而不是“后激活”。文中分析,如果shortcut path是恒等映射,同时每个残差单元之间也用恒等映射,那么可以有下面公式:
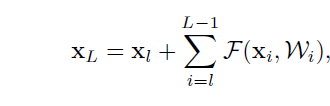
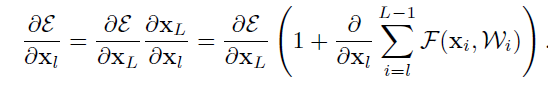
可以看出,前向传播变成了简单的加和形式,反向传播也类似。如此一来便能把信息从一单元传到网络中任意一个单元。文章中也尝试将加入constant scale,即两个path加入一个放缩系数,以及其他一些形式,比如weight path部分加入gating 机制,进而调节两条path的权重,或是加入Dropout或是在shortcut path部分用1x1卷积替代恒等映射,这些方式要么在 处引入参数,要么在 出引入参数,而当网络很深时,构成的网络会因为这些参数的连乘形式从而变的难以训练,无法“将一个单元的信息直接映射到任意一个单元”。
Deep Networks with Stochastic Depth
这篇文章主要是思想是训练时根据概率选择出要训练的网络部分,此时会随机跳过某些层,从而方便训练。测试时又将所有的层按照训练时各自的概率作为权重进行组合。这篇文章采用了ResNet的结构,称之为ResBlock。不同的ResBlock被赋予特定的概率。文中使用线性概率衰减的形式进行。
文章中指出Dropout是为了降低隐层单元成组产生“co-adaptation”效应,人们希望每个节点能产生有用的特征。这可以看成是集成学习的一种方法。类似的有DropConnect(随机让卷积核的某个元素为0)、Maxout(每个点只取该点对应所有通道的最大值)等等。随机深度网络可以看成是集成学习的一种方式。由于每次训练时网络的深度都是不一样的,因此用于集成的网络具有更大的差异性,从而提高整个模型的泛化能力。
可以看出,从最初的Dropout只是对单个神经元进行“采样”,再到DropConnect的对卷积核的采样,再到现在的对整个网络的采样。其主要目的就是训练时降低网络的复杂程度。
Generative Adversarial Nets
GAN的主要方式就是训练连个网络G和D,利用minimax方式进行训练。其中G是输入随机噪声
z
,生成图像
这给大家提供了一个非监督学习的新的方法。一开始一般是根据训练集估计样本分布
GAN的目标函数如下:
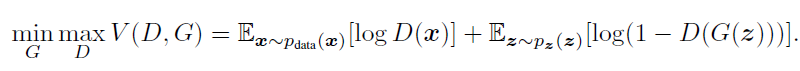
由于在初期时G的能力较弱,则D(G(z))接近于0,那么后一项的梯度饱和,因此在实际训练初期,不是最小化
log(1−D(G(z)))
,而是最大化
log(D(G(z)))
。
文章中说,每进行一次G训练,要进行k次D的训练,以便D能优化到最优解附件。然而实际训练中k=1.
图解:
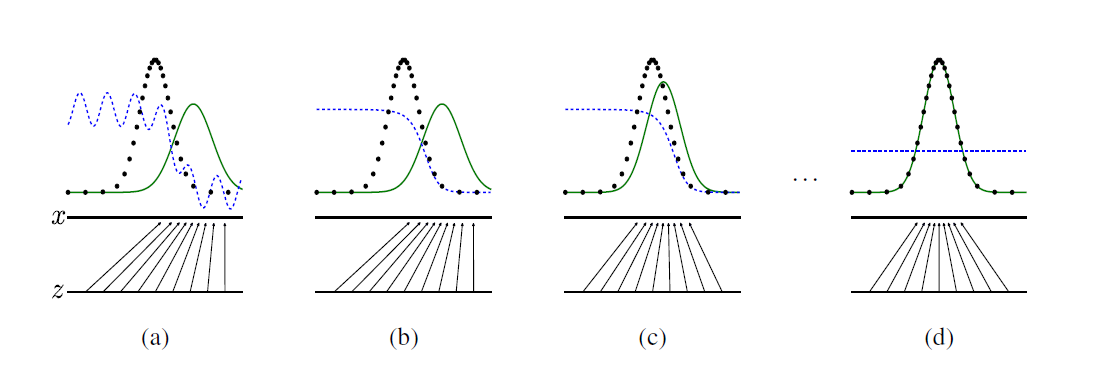
黑色断点线代表真实样本分布,蓝色断点线代表D的判别分布,而绿色实线代表G生成的样本分布。一开始,这些分布都差很大,如(a)所示。噪声z也映射到G的峰值附近。经过一次更新D时,判别分布被训练成可以判别两个分布,在图(b)中呈现类似经过y轴对称后的Sigmoid函数。再更新G,如(c)所示,G经过训练,峰值向真实样本分布的峰值靠拢,重叠部分增大。噪声z也映射到真实样本附近。如此交替更新,最终会成为(d)的情形,此时D无法分辨生成图片和真实图片,生成的分布与真实样本分布重合。
Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
这篇论文主要是利用了Laplacian Pyramid的方法,将合成混淆图转变成逐步进行。,在不同分辨率和尺度下进行逐步的生成。他们将一幅图像分解成下采样的图像部分以及高频残差。此时残差已经非常稀疏,很容易拟合。
训练过程如下:
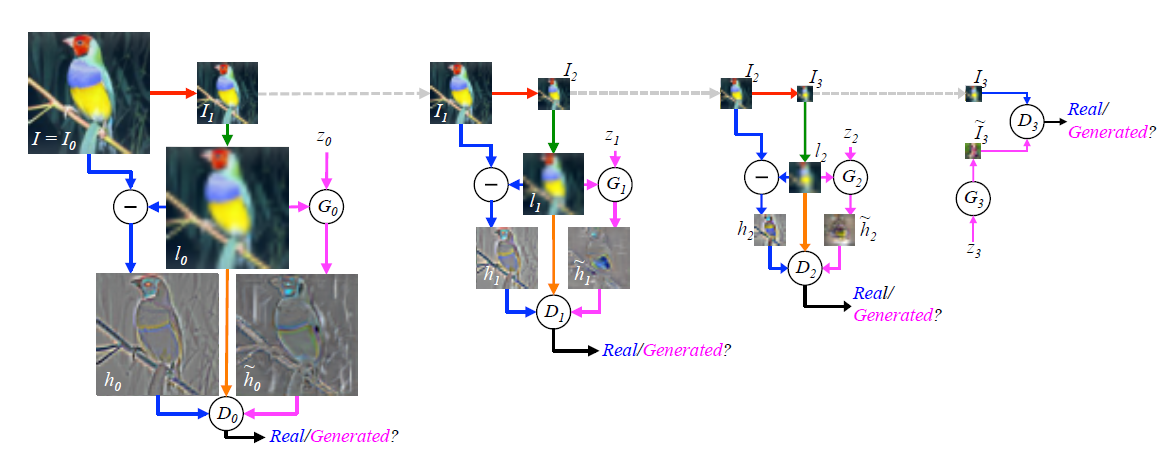
首先对于原图
I0
,模糊后进行下采样得到
I1
,
I1
再放大成
l0
,此时可以得到相应的残差
h0=I0−l0
,此时我们要拟合残差即可。通过
l0
作为引导图,采用CGAN,通过
G0(z0,l0)
得到
h˜0
。此时
D0
只要判别
h˜0
和
h0
即可。同理不断进行下去,直到达到最后一层,此处是
I3
,由于
I3
已经很稀疏,因此直接用噪声生成
I˜3=G3(z3)
即可。
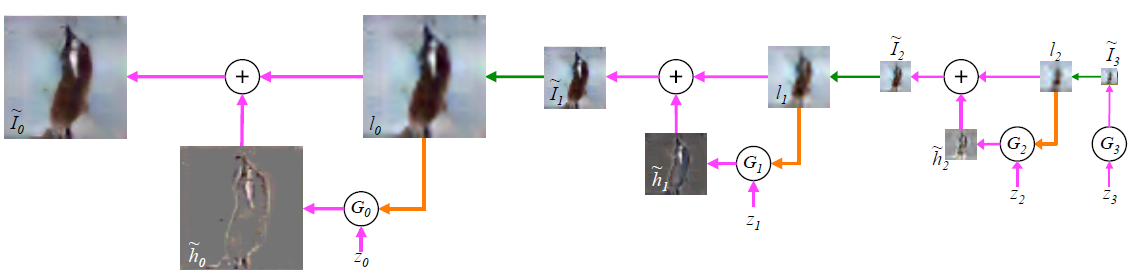
测试过程:
由于训练过程已经得到了
Gi
,此时只要从
z3
开始,得到
I˜3=G3(z3)
,再上采样得到
l2
,以此类推。最终得到
I˜0
。
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
论文中针对前人的GAN的一些问题,包括训练不稳定,训练出来的图片模糊等等这些问题。提出了一些针对GAN训练的建议。
主要有:
1. 将pooling替换为strided convolution层和fractional-strided convolution层。其认为如果人为的进行pooling,效果会比让网络用自身的空间下采样学习的方法差。
2. D和G都用BN
3. 去除全连接层
4. G的所有层用ReLu,而最终输出层用Tanh
5. D用LeakyReLu。
Improved Techniques for Training GANs
本文中主要介绍了几种提高收敛速度的方法。
1、 feature matching
这种思想来源于MMD,即不是直接最大化D的输出,而是希望G能生成和真实数据相同的数据特征。文章中通过比较真实数据和生成数据在D中的某一中间层的特征,从而更新网络。
∥∥Ex∼pdataf(x)−Ez∼pdataf(G(z))∥∥22
其中
f(x)
是D的中间层。
2、 Minibatch discrimination
由于先前的GAN是每次一张图片进行训练的,难免会出现训练不稳定的问题。这里采用Minibatch的方法进行训练。
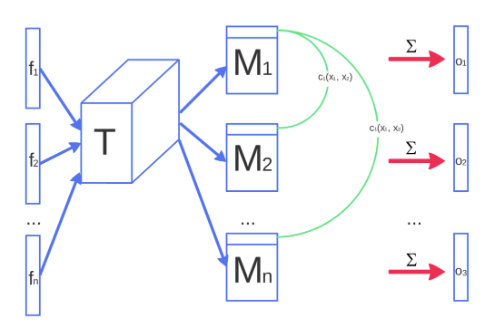
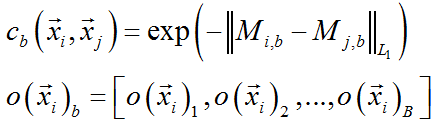
然后把
o(xi)
和
f(xi)
送入D中。这样做就是增加了一个判别项信息,从而能达到更好的效果。
3、 Historical averaging
在两个网络中各自的损失函数中增加一项
∥∥θ−1t∑ti=1θ[i]∥∥2
,其中
θ[i]
是第
i
时刻的参数值。如此一来每次更新时,会考虑到历史信息,并且赋予离本次更新越远的那些参数更大的权重。这是因为本次更新与上一次更新的损失可能相差很小,故而离本次更新时间越近的参数应该赋予更小的权值。
4、 One-sided label smoothing
这里只对正样本使用软标签,负样本依旧直接为0.
5、 Virtual batch normalization
对于某个样本















 1166
1166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









