









目录
为什么要有头文件?
C/C++编译采用的是分离编译模式。在一个项目中,有多个源文件存在,但是它们总会有一些相同的内容,比如用户自定义类型、全局变量、全局函数的声明等。将这些内容抽取出来放到头文件中,提供给各个源文件包含,就可以避免想相同内容的重复书写,提高编程效率和代码安全性。
所以,设立头文件的目的主要是:提供全局变量、全局函数的声明或公用数据类型的定义,从而实现分离编译和代码复用。、
实验一:
创建两个cpp文件:main.cpp cal.cpp , 其中main.cpp定义:
int add(int a , int b)
{
return a+b;
}
int main(){
}cal.cpp:
int add(int a , int b)
{
return a+b;
}
当我们执行以下命令将两个.cpp(源文件)编译成一个源文件:
g++ main.cpp cal.cpp -o demo.exe执行命令后可以发现出现了重定义的情况,即两个源文件中都有 add() 函数的定义:

将main.cpp中的add()函数写成声明的方式:
int add(int a , int b);
int main(){
add(1,2);
}再次使用以上命令进行编译,则编译运行成功。如果把声明去掉了,会发现编译还是不成功。
当mian函数里调用 add()函数时,如果发现了有 add() 函数的声明,则在链接的时候会告诉链接器去找 add() 函数的定义,搜到了即告诉main函数里它的定义实现。
实验二:
继续深入,再新创建一个 test.cpp文件加入编译,如果 test.cpp文件也要用到 add()函数的话,又要重新写一遍 add()函数的声明,会很繁琐!因此头文件就应运而生了:
新建一个 cal.h 头文件,头文件里只写 add()函数的声明,同时保持 cal.cpp中 add()函数的定义:
int add(int a , int b);
当我们在 main.cpp文件里想用到 add()函数, 包含一下头文件即可:
#include"cal.h"
int main(){
add(1,2);
}这个过程到底发生了什么? 实际上这是预处理器干的事情,当main.cpp文件里包含了 cal.h头文件,预处理器会将 cal.h 头文件里的内容都完全复制粘贴过 main.cpp文件中:
#include"cal.h"
int add(int a , int b); //纯复制粘贴
int main(){
add(1,2);
}因此,头文件产生的最初目的,就是拓展用的。
头文件保护符有什么用?
#ifndef 、#defin 、#endif 为什么经常出现在源代码中 ?
实验:
基于以上实验,在 cal.h 头文件中加上一个struct 结构体的定义(要注意区分定义和声明):
struct Person{
};
int add(int a , int b);
写上声明在头文件后,main.cpp 等文件就可以正常使用该结构体了:
#include"cal.h"
int main(){
add(1,2);
Person p1;
}但是如果在 main.cpp 文件中,再次#include 一下cal.h头文件,然后进行编译:
#include"cal.h"
#include"cal.h"
int main(){
add(1,2);
Person p1;
}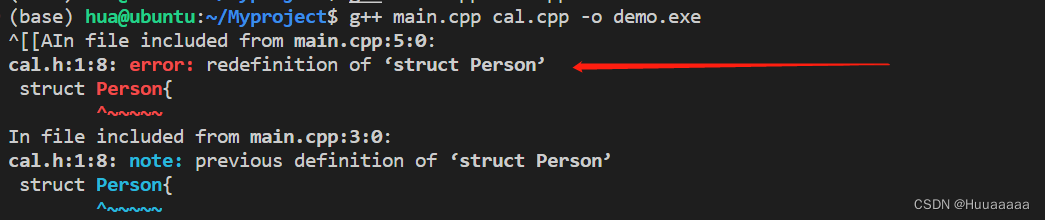
可以看到又出现了重定义(声明可以多次,定义只能有一次)的情况,出现重定义即证明该结构体定义了两次,根据上面的实验结果,包含头文件其实就是复制粘贴头文件的内容,到源文件上,所以可以理解main.cpp 中发生了这样的情况:
//#include"cal.h"
struct Person{
};
int add(int a , int b);
//#include"cal.h"
struct Person{
};
int add(int a , int b);
int main(){
add(1,2);
Person p1;
}也就是粘贴复制了两遍struct 结构体的定义,这必然是导致重定义发生的原因。
引入头文件保护符:
我们在cal.h 头文件中,加入头文件保护符:
#ifndef myprotect
#define myprotect
struct Person{
};
int add(int a , int b);
#endif 加入保护符后, 我们再看看此时 main.cpp发生了什么:
//#include"cal.h"
#ifndef myprotect
#define myprotect
struct Person{
};
int add(int a , int b);
#endif
//#include"cal.h"
#ifndef myprotect
#define myprotect
struct Person{
};
int add(int a , int b);
#endif
int main(){
add(1,2);
Person p1;
}还是照常执行粘贴复制,看看执行的过程,预处理器发现 myprotect 内的语句没有被定义过,因此照常复制粘贴过来:
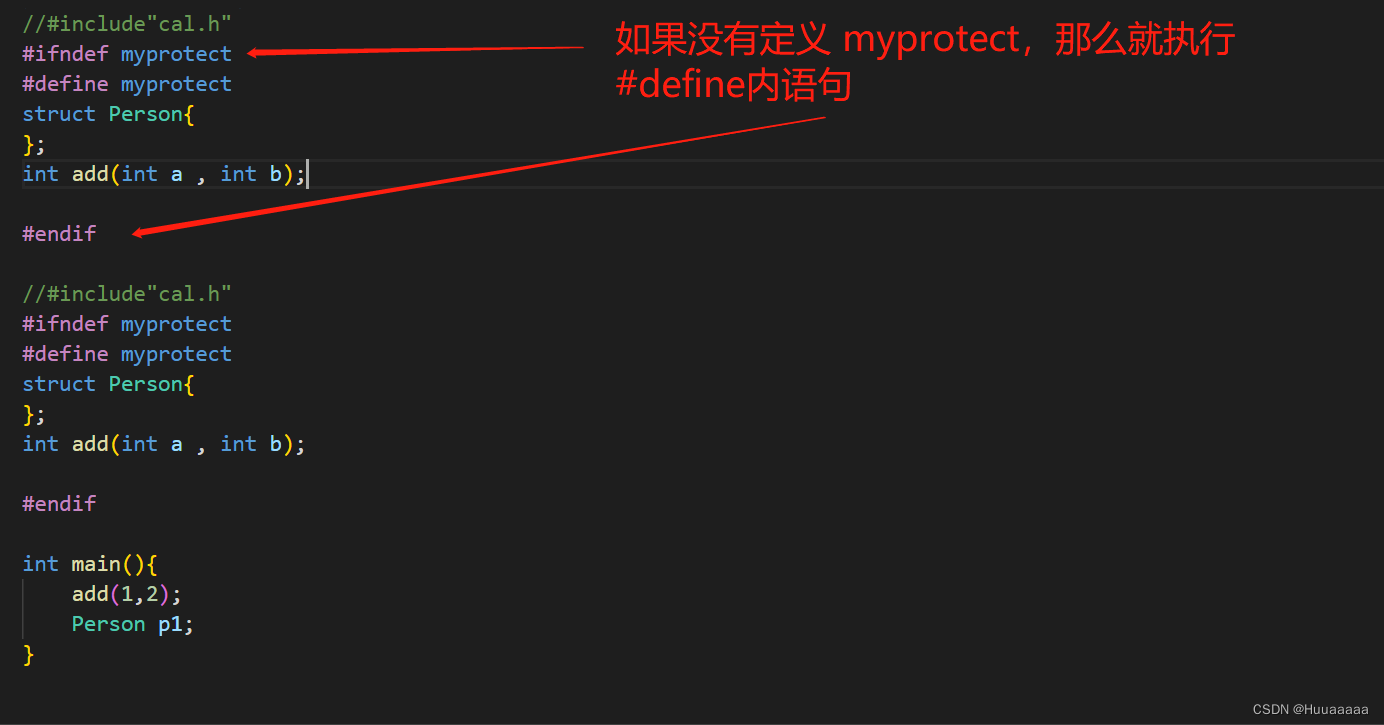
接着往下,预处理器到达了第二个 #ifndef myprotect :

其实就相当于把下面一块的定义都注释掉了:
//#include"cal.h"
#ifndef myprotect
#define myprotect
struct Person{
};
int add(int a , int b);
#endif
// //#include"cal.h"
// #ifndef myprotect
// #define myprotect
// struct Person{
// };
// int add(int a , int b);
// #endif
int main(){
add(1,2);
Person p1;
}从而就解决了重定义的问题,保护符的出现就是防止源文件重复包含同样的头文件问题。
头文件为什么不要用普通变量,函数的定义?
从上面两个实验就可以很明显的知道,头文件不写普通变量,或者函数的定义,就是为了防止重定义的发生!
两个源文件都包含了头文件,头文件又写了 普通变量,或者函数的定义,当将两个源文件放在一起编译时,都是粘贴复制头文件的内容,必然会导致重定义的发生!















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









