








原理回顾
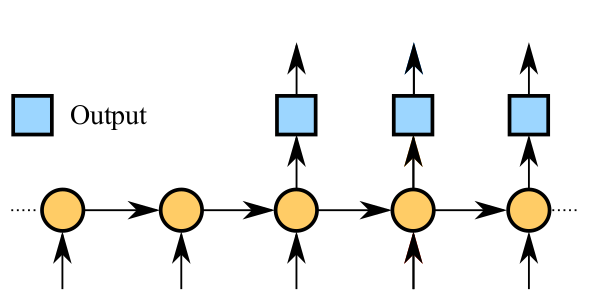
序列 A 中的每一个单词通过 word_embedding 操作以后,作为 input 进入编码器,编码器可以是一个多层 RNN 结构,编码器输出一个向量;
训练时,解码器的输入跟编码器的输入是一样的,然后解码器的输出与序列 B 之间的交叉熵作为模型的目标函数;
生成的时候,首先给定一个种子序列作为编码器的输入,并且解码器的上一时刻的输出作为下一时刻的输入,如此循环往复,直到生成给定数量的序列。
模型代码设计
天青色等烟雨 而我在等你
├── analysis
│ └── plot.py
├── data
│ ├── context.npy
│ ├── lyrics.txt
│ ├── origin.txt
│ ├── parse.py
│ └── vocab.pkl
├── log
│ ├── 2016-12-1022:11:22.txt
│ └── 2016-12-1022:11:22.txt.png
├── preprocess.py
├── README.md
├── result
│ └── sequence
├── sample.py
├── save
│ ├── checkpoint
│ ├── config.pkl
│ ├── model.ckpt-223
│ ├── model.ckpt-223.meta
│ └── words_vocab.pkl
├── seq2seq_rnn.py
├── train.py
└── utils.py
主目录下面的 utils.py 是公共函数库,preprocess.py 是数据预处理代码, seq2seq_rnn.py 是模型代码,sample.py 是抽样生成过程,train.py 是训练过程;
log 目录中存储的是训练过程中的日志文件;
save 目录中存储的是训练过程中的模型存储文件;
data 目录中存放的是原始歌词数据库以及处理过的数据库;
result 目录中存放的是生成的序列;
analysis 目录中存放的是用于可视化的代码文件;
数据预处理
c = reg.sub(' ',unicode(c))
reg = re.compile(ur"[^\u4e00-\u9fa5\s]")
c = reg.sub('',unicode(c))
c = c.strip()
''' parse all sentences to build a vocabulary
dictionary and vocabulary list
'''
with codecs.open(self.input_file, "r",encoding='utf-8') as f:
data = f.read()
wordCounts = collections.Counter(data)
self.vocab_list = [x[0] for x in wordCounts.most_common()]
self.vocab_size = len(self.vocab_list)
self.vocab_dict = {x: i for i, x in enumerate(self.vocab_list)}
with codecs.open(self.vocab_file, 'wb',encoding='utf-8') as f:
cPickle.dump(self.vocab_list, f)
self.context = np.array(list(map(self.vocab_dict.get, data)))
np.save(self.context_file, self.context)
'''
Split the dataset into mini-batches,
xdata and ydata should be the same length here
we add a space before the context to make sense.
'''
self.num_batches = int(self.context.size / (self.batch_size * self.seq_length))
self.context = self.context[:self.num_batches * self.batch_size * self.seq_length]
xdata = self.context
ydata = np.copy(self.context)
ydata[:-1] = xdata[1:]
ydata[-1] = xdata[0]
self.x_batches = np.split(xdata.reshape(self.batch_size, -1), self.num_batches, 1)
self.y_batches = np.split(ydata.reshape(self.batch_size, -1), self.num_batches, 1)
self.pointer = 0
''' pointer for outputing mini-batches when training
'''
x, y = self.x_batches[self.pointer], self.y_batches[self.pointer]
self.pointer += 1
if self.pointer == self.num_batches:
self.pointer = 0
return x, y
编写基于 LSTM 的 seq2seq 模型
确定编码器和解码器中 cell 的结构,即采用什么循环单元,多少个神经元以及多少个循环层;
将输入数据转化成 TensorFlow 的 seq2seq.rnn_decoder 需要的格式,并得到最终的输出以及最后一个隐含状态;
将输出数据经过 softmax 层得到概率分布,并且得到误差函数,确定梯度下降优化器;
cell_fn = rnn_cell.BasicRNNCell
elif args.rnncell == 'gru':
cell_fn = rnn_cell.GRUCell
elif args.rnncell == 'lstm':
cell_fn = rnn_cell.BasicLSTMCell
else:
raise Exception("rnncell type error: {}".format(args.rnncell))
cell = cell_fn(args.rnn_size)
self.cell = rnn_cell.MultiRNNCell([cell] * args.num_layers)
decoder_inputs: A list of 2D Tensors [batch_size x input_size].initial_state: 2D Tensor with shape [batch_size x cell.state_size].
cell: rnn_cell.RNNCell defining the cell function and size.
loop_function: If not None, this function will be applied to the i-th output
in order to generate the i+1-st input, and decoder_inputs will be ignored,
except for the first element ("GO" symbol). This can be used for decoding,
but also for training to emulate http://arxiv.org/abs/1506.03099.
Signature -- loop_function(prev, i) = next
* prev is a 2D Tensor of shape [batch_size x output_size],
* i is an integer, the step number (when advanced control is needed),
* next is a 2D Tensor of shape [batch_size x input_size].
softmax_w = build_weight([args.rnn_size, args.vocab_size],name='soft_w')
softmax_b = build_weight([args.vocab_size],name='soft_b')
word_embedding = build_weight([args.vocab_size, args.embedding_size],name='word_embedding')
inputs_list = tf.split(1, args.seq_length, tf.nn.embedding_lookup(word_embedding, self.input_data))
inputs_list = [tf.squeeze(input_, [1]) for input_ in inputs_list]
prev = tf.matmul(prev, softmax_w) + softmax_b
prev_symbol = tf.stop_gradient(tf.argmax(prev, 1))
return tf.nn.embedding_lookup(embedding, prev_symbol)
self.logits = tf.matmul(output, softmax_w) + softmax_b
self.probs = tf.nn.softmax(self.logits)
loss = seq2seq.sequence_loss_by_example([self.logits],
[tf.reshape(self.targets, [-1])],
[tf.ones([args.batch_size * args.seq_length])],
args.vocab_size)
# average loss for each word of each timestepself.cost = tf.reduce_sum(loss) / args.batch_size / args.seq_length
self.var_trainable_op = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, self.var_trainable_op),
args.grad_clip)
optimizer = tf.train.AdamOptimizer(self.lr)
self.train_op = optimizer.apply_gradients(zip(grads, self.var_trainable_op))
self.initial_op = tf.initialize_all_variables()
self.saver = tf.train.Saver(tf.all_variables(),max_to_keep=5,keep_checkpoint_every_n_hours=1)
self.logfile = args.log_dir+str(datetime.datetime.strftime(datetime.datetime.now(),'%Y-%m-%d %H:%M:%S')+'.txt').replace(' ','').replace('/','')
self.var_op = tf.all_variables()
编写抽样生成函数
for word in start:
x = np.zeros((1, 1))
x[0, 0] = words[word]
feed = {self.input_data: x, self.initial_state:state}
[probs, state] = sess.run([self.probs, self.final_state], feed)
argmax 型:即找出 probs 中最大值所对应的索引,然后去单词表中找到该索引对应的单词即为最佳单词;
weighted 型:即随机取样,其工作流程如下:首先,计算此 probs 的累加总和 S ;其次,随机生成一个 0~1 之间的随机数,并将其与 probs 的总和相乘得到 R;最后,将 R 依次减去 probs 中每个数,直到 R 变成负数的那个 probs 的索引,即为我们要挑选的最佳单词;
combined 型:这里我把 argmax 和 weighted 结合起来了,即每次遇到一个空格(相当于一句歌词的结尾),就使用 weighted 型,而其他时候都使用 argmax 型;
def weighted_pick(weights):
t = np.cumsum(weights)
s = np.sum(weights)
return(int(np.searchsorted(t, np.random.rand(1)*s)))
if sampling_type == 'argmax':
sample = np.argmax(p)
elif sampling_type == 'weighted':
sample = weighted_pick(p)
elif sampling_type == 'combined':
if word == ' ':
sample = weighted_pick(p)
else:
sample = np.argmax(p)
return sample
for n in range(num):
x = np.zeros((1, 1))
x[0, 0] = words[word]
if not self.args.attention:
feed = {self.input_data: [x], self.initial_state:state}
[probs, state] = sess.run([self.probs, self.final_state], feed)
else:
feed = {self.input_data: x, self.initial_state:state,self.attention_states:attention_states}
[probs, state] = sess.run([self.probs, self.final_state], feed)
p = probs[0]
sample = random_pick(p,word,sampling_type)
pred = vocab[sample]
ret += pred
word = pred
编写训练函数
help='set size of RNN hidden state')
print('Restoring')
model.saver.restore(sess, ckpt.model_checkpoint_path)
else:
print('Initializing')
sess.run(model.initial_op)
feed = {model.input_data: x, model.targets: y, model.initial_state: state}
train_loss, state, _ = sess.run([model.cost, model.final_state, model.train_op], feed)
编写日志
or (e==args.num_epochs-1 and b==text_parser.num_batches-1):
checkpoint_path = os.path.join(args.save_dir, 'model.ckpt')
model.saver.save(sess, checkpoint_path, global_step = e)
print("model has been saved in:"+str(checkpoint_path))
ave_loss = np.array(total_loss).mean()
logging(model,ave_loss,e,delta_time,mode='train')
编写可视化函数
if 'validate' in line:
index2 = index2 + 1
cost = line.split(':')[2]
indexValidateList.append(index2)
validateCostList.append(float(cost))
elif 'train error rate' in line:
index1 = index1+1
cost = line.split(':')[2]
indexCostList.append(index1)
costList.append(float(cost))
title,indexCostList,costList = self.parse()
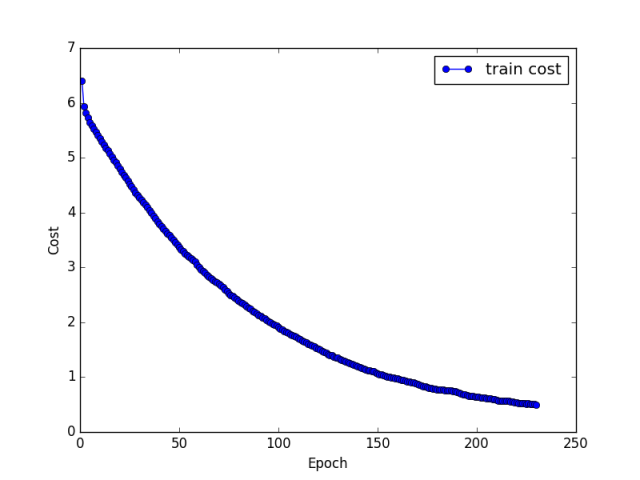
p1 = plt.plot(indexCostList,costList,marker='o',color='b',label='train cost')
plt.xlabel('Epoch')
plt.ylabel('Cost')
plt.legend()
plt.title(title)
if self.saveFig:
plt.savefig(self.logFile+'.png',dpi=100)
#plt.savefig(self.logFile+'.eps',dpi=100)
if self.showFig:
plt.show()
设置训练超参
结果展示

为什么我都会开错记忆不多
幸福搁抽勾
我只为大参城真 说越没有
简单一个音 最后的秘密
大人情了解境
再继续永远都不会痛
不知道很感 但它怕开地后想念你
怕你身边 把那一天
你最好了 鸣债不手切最后走的生活
好拥有 你想的兵水停
有什么回吻你都懂不到
谁说没有结果 我是不是多提醒你
好多永远隔着对 会心碎你走罪你
谁说用手语 想要随时想能打开
想要当然魅力太强被曾人迷人蛋
哈哈哈
从前进开封 出水芙蓉加了星
在狂风叫我的爱情 让你更暖
心上人在脑海别让人的感觉
想哭 是加了糖果
船舱小屋上的锈却现有没有在这感觉
你的美 没有在
我却很专心分化
还记得
原来我怕你不在 我不是别人
要怎么证明我没力气 我不用 三个马蹄
生命潦草我在蓝脸喜欢笑
中古世界的青春的我
而她被芒草割伤
我等月光落在黑蝴蝶
外婆她却很想多笑对你不懂 我走也绝不会比较多
反方向左右都逢源不恐 只能永远读着对白

本文转载自公众号:深度学习每日摘要,内容有部分改动;原作者:张泽旺。二次转载请联系原文作者。
扫描二维码,加入讨论群
获得优质数据集
回复「读者」自动入群


















 4158
4158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









