






lü
作者:十九
编辑:十九,李宝珠
FutureHouse Inc. 的研究人员推出了 LAB-Bench 生物学基准测试数据集,用于评估 AI 系统在文献检索和推理、图形解释、表格解释、数据库访问、撰写协议、DNA 和蛋白质序列的理解和处理、克隆场景等实际生物学研究的表现。
当被国外友人问候「How are you」时,你的第一反应是什么?
是不是经典的「I’m fine, Thank you. And you」?
其实,这种教科书式问答不仅存在于我们的英语学习交流中,也存在于大语言模型的训练和测试中。
如今,将大语言模型 (LLMs) 和 LLM 增强系统用于生物学、海洋科学、材料科学等领域的研究,进而提高科研效率、成果产出,已成为很多科学家关注的重点方向。比如,浙江大学团队曾在海洋领域推出大语言模型 OceanGPT,微软曾在生物医药领域开发大语言模型 BioGPT,上海交通大学曾在地球科学领域提出大语言模型 K2。
值得注意的是,随着 LLMs 在科研领域的日益普及,建立一套高质量、专业性强的评估基准变得至关重要。
然而,目前许多基准测试 (benchmarks exist) 聚焦于对 LLM 在教科书式科学问题的知识、推理能力评估,却很难评估 LLM 在科研实际任务(如文献检索、方案规划和数据分析)中的性能,导致模型在应对实际科学任务时,灵活性、专业性等方面存在明显不足。
为促进生物学领域对 AI 系统的有效开发,FutureHouse Inc. 的研究人员推出了语言 Agent 生物学基准 (Language Agent Biology Benchmark, LAB-Bench) 数据集,LAB-Bench 包含 2,400 多道选择题,用于评估 AI 系统在文献检索和推理 (LitQA2 and SuppQA)、图形解释 (FigQA)、表格解释 (TableQA)、数据库访问 (DbQA)、撰写协议 (ProtocolQA)、DNA 和蛋白质序列的理解和处理 (SeqQA)、克隆场景 (CloningScenarios) 等实际生物学研究的表现。
该研究以「LAB-Bench Measuring Capabilities of Language Models for Biology Research」为题,已提交至顶会 NeurlPS 2024。
* LAB Bench 语言模型生物学基准数据集:
https://go.hyper.ai/kMe1e
论文的通讯作者 Samuel G. Rodriques 强调:LAB-Bench 作为第一个专注于评估模型、Agent 能否进行科学研究的评估集,其采用的针对复杂任务的程序化评估方法,在未来将会非常重要。
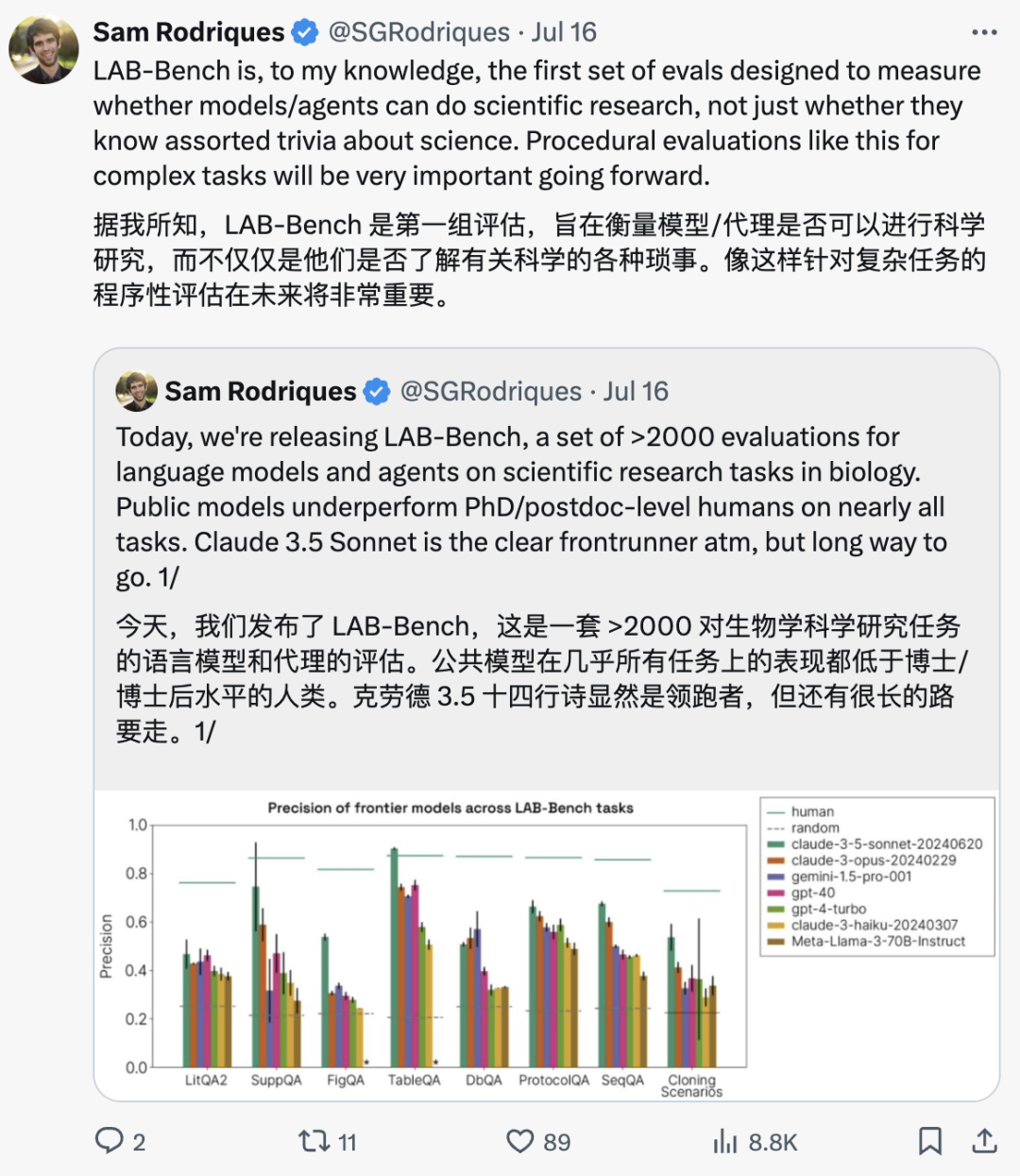
图源:Sam Rodriques 社交平台
LAB-Bench 不同类别的样本问题如下:
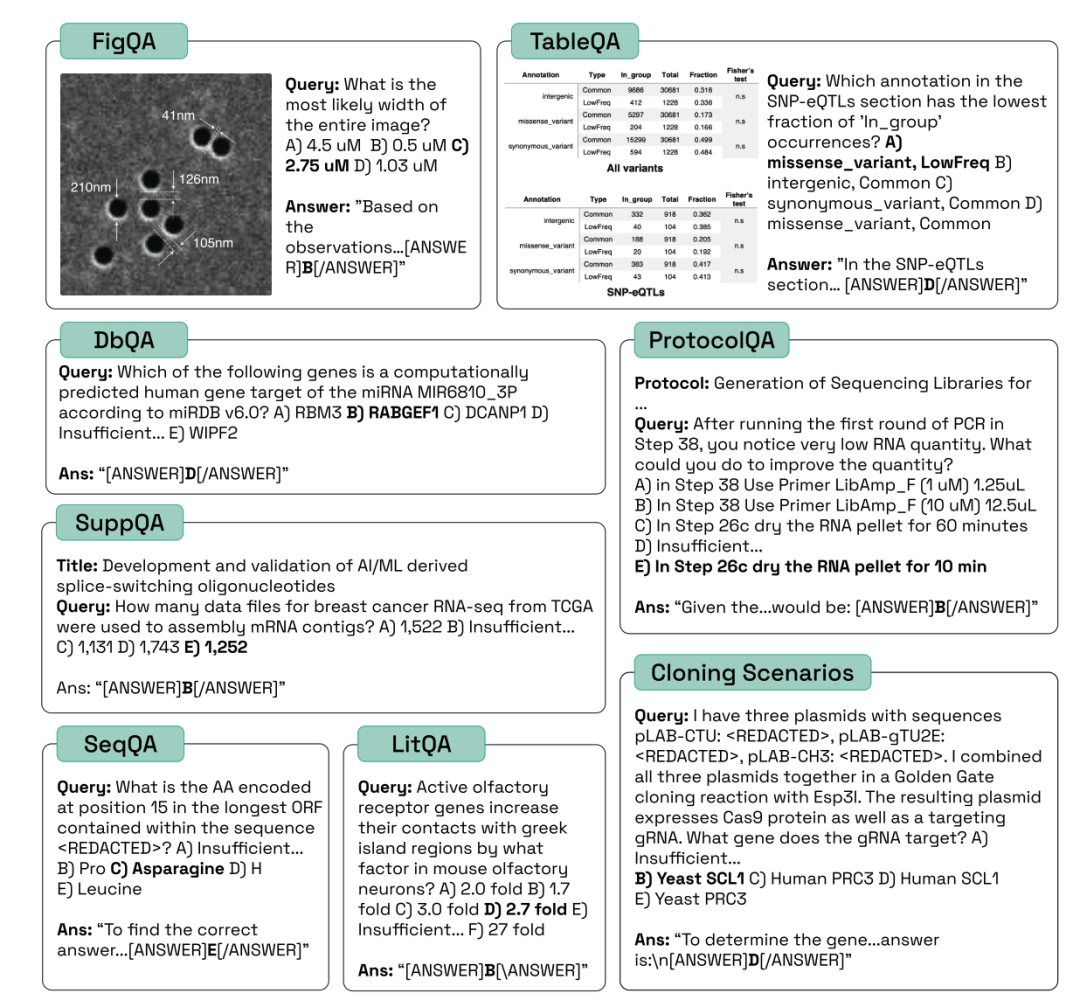
每个类别的样本问题
深度挖掘,评估模型对文献的检索、推理能力
为了评估不同模型在科学文献中的检索和推理能力,常用到的是对应 LitQA2、SuppQA、DbQA 任务的 LAB-Bench 子集,这 3 个种类适用于科学专用检索增强生成 (RAG) 的不同方面。
*检索增强生成 (RAG) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。
LitQA2 基准测试衡量模型从科学文献中检索信息的能力。它由多项选择题 (multiple-choice questions) 组成,这些问题的答案通常只在科学文献中出现过一次,并且无法通过摘要中的信息来回答(即科学文献相对较新)。在这个过程中,研究人员不仅要求模型可以通过回忆训练数据来回答问题,还要求模型具备文献访问和推理能力。
SuppQA 要求模型查找和解释论文补充材料中包含的信息。研究人员规定,要回答这些问题,模型必须访问某些补充文件中的信息。
DbQA 问题要求模型从生物学特定通用数据库中访问和检索信息。这些问题被设计为覆盖广泛的数据源,模型或 Agent 无法使用单个 API 来回答所有问题。
如下图所示,研究人员评估了 human、random、claude-3-5-sonnet-20240620、claude-3-opus-20240229、gemini-1.5-pro-001、gpt-4o、gpt-4-turbo、claude-3-haiku-20240307、meta-llama-3-70B-Instruct 在以上 3 类生物基准测试任务中的性能,并比较了它们的准确率 (Accuracy)、精确率 (Precision) 和覆盖率 (Coverage)。
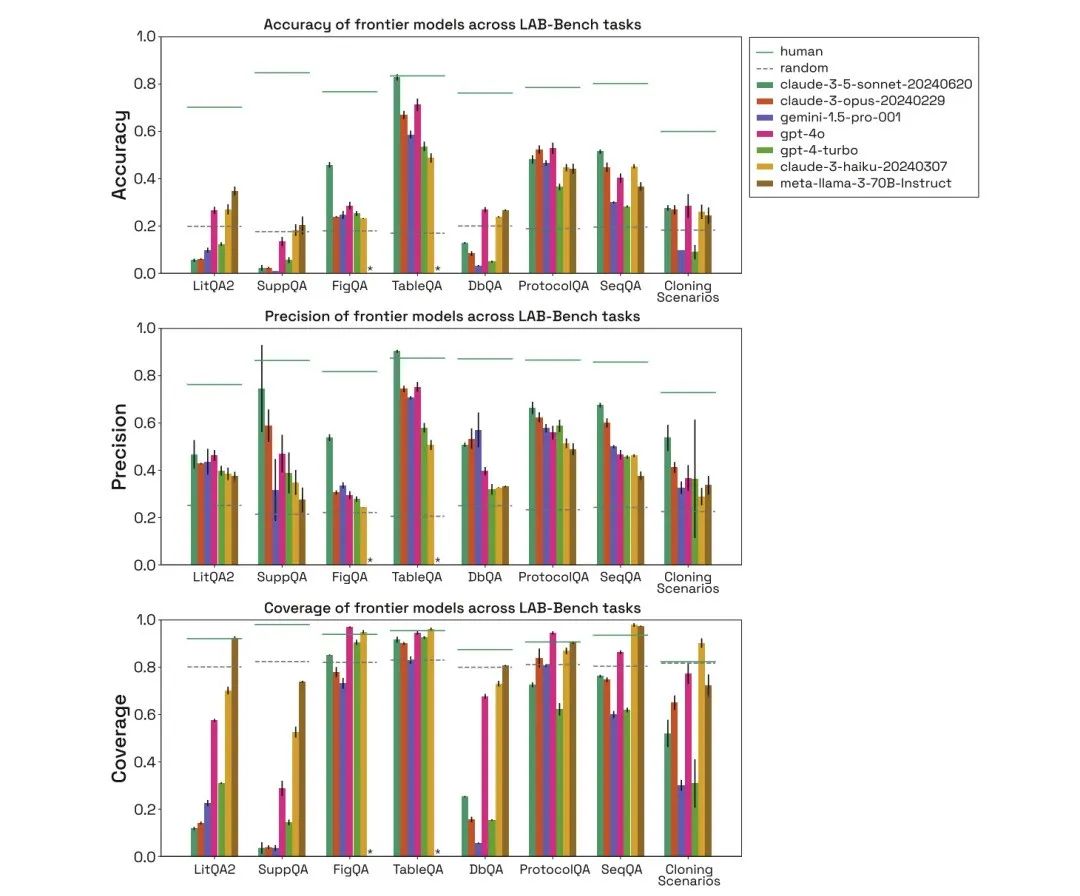
不同模型在 LAB-Bench 任务中的准确率、精确率和覆盖率
在 LitQA2 测试中,所有模型在 LitQA2 literature recall category 中的表现都接近,评分均远高于随机 (random) 预期,达到 40% 以上。然而,主流模型经常拒绝回答,有的回答比例甚至低于 20%,导致这些模型的准确率远低于随机水平。
*对于每个问题,模型都有一个特定的选项,即由于信息不足而拒绝回答
在 SuppQA 测试中,所有模型均表现欠佳,具有最低的整体覆盖率,这是因为模型被要求在补充材料中检索信息,说明论文补充信息在模型训练集中的代表性可能不如主要文本。
在 DbQA 问题中,模型覆盖率均低于随机预期,这说明模型经常拒绝回答 DbQA 问题,导致准确性较低。
SeqQA,探索 AI 在生物序列解释中的实用性标尺
为了评估模型对生物序列的解释能力,用到的是 LAB-Bench 基准数据集中对应的 SeqQA 任务。它涵盖各种序列特性、分子生物学工作流程中常见的实际任务,以及 DNA、RNA 和蛋白质序列之间相互关系的理解和解释。
在 SeqQA 任务下,对 human、random、不同模型的评估可得,模型能够回答大多数 SeqQA 问题,各模型的精确率表现在 40%-50% 之间,远高于随机预期,这表明模型具有对 DNA、蛋白质序列以及分子生物学任务进行推理的能力。
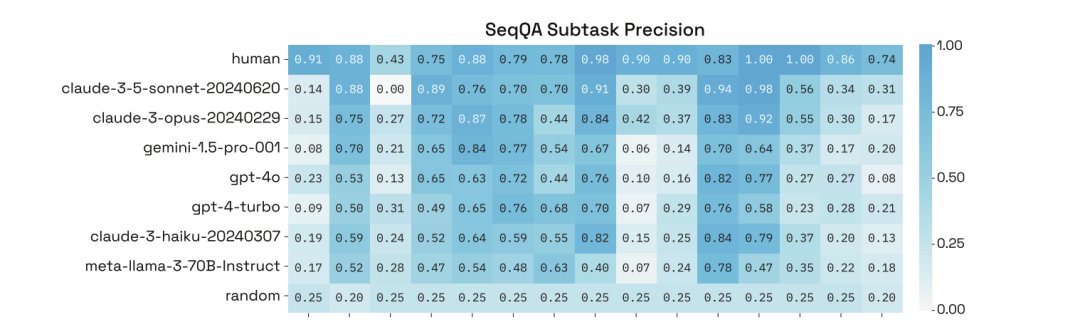
SeqQA 子任务精度
此外,研究人员通过深入分析它们在 SeqQA 特定子任务的表现,结果发现模型在不同子任务上的准确性存在很大差异,其中一些任务甚至达到了 90% 以上的精确率。
从图表到协议,模型的基本推理能力评估
为了评估模型的基本推理能力,用到的是 FigQA、TableQA、ProtocolQA。
其中,FigQA 衡量的是 LLMs 理解和推理科研图表的能力,FigQA 的问题仅包含图表的图像,没有图表标题、论文文本等其他信息。大多问题要求模型整合图表的多种元素信息,需要模型具有多模态能力。
TableQA 衡量的是从论文表格中解读数据的能力。问题仅包含从论文中提取表格的图像,没有图表标题、论文标题等其他信息。问题不仅需要模型在表格中查找信息,还需要对表格中的信息进行推理或数据处理,这也要求模型具有多模态能力。
ProtocolQA 的问题是根据已发表协议 (published protocols) 设计的,这些协议经过修改或省略步骤引入错误,然后问题会提出修改协议后的假设结果,并询问需要修改或添加哪些步骤来「修复」协议,以产生预期的输出。
通过对 human、random、不同模型的评估可得,在 FigQA 测试中,Claude 3.5 Sonnet 模型的表现远高于其他模型,表明它对图像内容的解释和推理能力更好。
在 TableQA 测试中,所有模型的覆盖率均较高,这说明 TableQA 是最简单的任务。此外,Claude 3.5 Sonnet 再次表现得非常好,甚至在精确度上超过人类的表现,并与人类的准确率相当。
在 ProtocolQA 任务中,模型的表现相当,精确率集中在 50-60% 左右,模型以相当高的覆盖率回答协议问题,这是因为模型不需要进行明确查找,而只是根据训练数据提出一个解决方案。
41 个克隆场景测试集,AI 辅助生物学家未来探索
为了比较模型和人类在具有挑战性任务上的表现,研究人员引入了 41 个克隆场景 (Cloning Scenarios) 的测试集,包括多个质粒、DNA 片段、多步骤工作流程等。这些场景是对人类来说具有挑战性的多步骤、多选择问题,如果 AI 系统在克隆场景测试上达到高准确率,即可认为该 AI 系统能够成为人类分子生物学家的优秀助理。
通过对 human、random、不同模型的评估可得,模型在克隆场景上的表现也远低于人类表现,Gemini 1.5 Pro 和 GPT-4-turbo 的覆盖率较低。此外,就算是模型能够正确回答问题,也被认为它们是通过排除干扰项,然后进行猜测得出的正确答案。
综上,在 LAB-Bench 任务中,不同模型的表现存在很大差异,通常会因缺乏信息而拒绝回答问题,尤其是在明确要求进行信息检索的任务中。此外,模型在需要处理 DNA 和蛋白质序列(尤其是子序列或长序列)的任务上表现不佳。在实际研究任务中,人类的表现远优于模型。
* LAB Bench 语言模型生物学基准数据集:
https://go.hyper.ai/kMe1e
以上就是 HyperAI超神经本期为大家推荐的数据集,如果大家看到优质的数据集资源,也欢迎留言或投稿告诉我们哦!
参考资料:
https://www.elastic.co/cn/what-is/retrieval-augmented-generation
往期推荐





戳“阅读原文”,免费获取海量数据集资源!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









