








 本文介绍了五种常用的数据标准化方法,包括0-1标准化、Z-Score标准化、最大值绝对值标准化、RobustScaler标准化,以及它们的应用场景和特点。
本文介绍了五种常用的数据标准化方法,包括0-1标准化、Z-Score标准化、最大值绝对值标准化、RobustScaler标准化,以及它们的应用场景和特点。
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。
去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权
最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import preprocessing
% matplotlib inline0-1标准化
又叫Max-Min标准化,公式:
x′=x−minmax−min
x
′
=
x
−
m
i
n
m
a
x
−
m
i
n
# 创建数据
df = pd.DataFrame({'value1':np.random.rand(100)*10,
'value2':np.random.rand(100)*100})
print(df.head())
print('---------------')
def maxmin (df,*cols):
df_m = df.copy()
for col in cols:
ma = df[col].max()
mi = df[col].min()
df_m[col + '_m'] = (df[col] - mi) / (ma - mi)
return df_m
df1 = maxmin(df,'value1','value2')
print(df1.head()) value1 value2
0 7.363287 15.749935
1 5.713568 33.233757
2 6.108123 21.522650
3 0.804442 85.003204
4 6.387467 21.264910
---------------
value1 value2 value1_m value2_m
0 7.363287 15.749935 0.740566 0.151900
1 5.713568 33.233757 0.574296 0.329396
2 6.108123 21.522650 0.614062 0.210505
3 0.804442 85.003204 0.079521 0.854962
4 6.387467 21.264910 0.642216 0.207888
# 使用 sklearn中的 scale 函数
minmax_scaler = preprocessing.MinMaxScaler() # 创建 MinMaxScaler对象
df_m1 = minmax_scaler.fit_transform(df) # 标准化处理
df_m1 = pd.DataFrame(df_m1,columns=['value1_m','value2_m'])
df_m1.head()| value1_m | value2_m | |
|---|---|---|
| 0 | 0.740566 | 0.151900 |
| 1 | 0.574296 | 0.329396 |
| 2 | 0.614062 | 0.210505 |
| 3 | 0.079521 | 0.854962 |
| 4 | 0.642216 | 0.207888 |
Z-Score
也叫z分数,是一种具有相等单位的量数。它是将原始分数与团体的平均数之差除以标准差所得的商数,是以标准差为单位度量原始分数离开其平均数的分数之上多少个标准差,或是在平均数之下多少个标准差。
- 它是一个抽象值,不受原始测量单位的影响,并可接受进一步的统计处理
- 处理后的数值服从均值为0,方差为1的标准正态分布。
- 一种中心化的方法,会改变原数据的数据分布,不适用于对稀疏数据做处理
z=x−μσ z = x − μ σ
def data_Znorm(df, *cols):
df_n = df.copy()
for col in cols:
u = df_n[col].mean()
std = df_n[col].std()
df_n[col + '_Zn'] = (df_n[col] - u) / std
return(df_n)
# 创建函数,标准化数据
df_z = data_Znorm(df,'value1','value2')
u_z = df_z['value1_Zn'].mean()
std_z = df_z['value1_Zn'].std()
print(df_z.head())
print('标准化后value1的均值为:%.2f, 标准差为:%.2f' % (u_z, std_z))
# 标准化数据
# 经过处理的数据符合标准正态分布,即均值为0,标准差为1
# 什么情况用Z-score标准化:
# 在分类、聚类算法中,需要使用距离来度量相似性的时候,Z-score表现更好 value1 value2 value1_Zn value2_Zn
0 7.363287 15.749935 0.744641 -1.164887
1 5.713568 33.233757 0.196308 -0.550429
2 6.108123 21.522650 0.327450 -0.962008
3 0.804442 85.003204 -1.435387 1.268973
4 6.387467 21.264910 0.420298 -0.971066
标准化后value1的均值为:-0.00, 标准差为:1.00
# Z-Score标准化
zscore_scale = preprocessing.StandardScaler()
df_z1 = zscore_scale.fit_transform(df)
df_z1 = pd.DataFrame(df_z1,columns=['value1_z','value2_z'])
df_z1.head()| value1_z | value2_z | |
|---|---|---|
| 0 | 0.748393 | -1.170755 |
| 1 | 0.197297 | -0.553202 |
| 2 | 0.329100 | -0.966855 |
| 3 | -1.442619 | 1.275366 |
| 4 | 0.422416 | -0.975959 |
MaxAbs
最大值绝对值标准化,和MaxMin方法类似,将数据落入一定的区间[-1,1],但是MaxAbs具有不破坏数据结构的特点,可以用于稀疏数据,或者
是系数的CSR(行压缩)和CSC(列压缩)矩阵(为矩阵的两种储存格式)
x′=x|max|
x
′
=
x
|
m
a
x
|
# MaxAbs标准化
maxbas_scaler = preprocessing.MaxAbsScaler()
df_ma = maxbas_scaler.fit_transform(df)
df_ma = pd.DataFrame(df_ma,columns=['value1_ma','value2_ma'])
df_ma.head()| value1_ma | value2_ma | |
|---|---|---|
| 0 | 0.740969 | 0.158626 |
| 1 | 0.574957 | 0.334715 |
| 2 | 0.614661 | 0.216766 |
| 3 | 0.080951 | 0.856112 |
| 4 | 0.642772 | 0.214170 |
RobustScaler
在某些情况下,假如数据中有离群点,我们可以使用Z-Score进行标准化,但是标准化后的数据并不理想,因为异常点的特征往往在标准化后容易失去离群特征,此时就可以用RobustScaler 针对离群点做标准化处理。
此方法对数据中心话和数据的缩放健壮性有更强的参数控制能力
————《Python数据分析与数据化运营》
# RobustScaler标准化
robustscaler = preprocessing.RobustScaler()
df_r = robustscaler.fit_transform(df)
df_r = pd.DataFrame(df_r,columns=['value1_r','value2_r'])
df_r.head()| value1_r | value2_r | |
|---|---|---|
| 0 | 0.360012 | -0.644051 |
| 1 | 0.055296 | -0.303967 |
| 2 | 0.128174 | -0.531764 |
| 3 | -0.851457 | 0.703016 |
| 4 | 0.179770 | -0.536777 |
绘制标准化散点图
data_list = [df, df_m1, df_ma, df_z1, df_r]
title_list = ['soure_data', 'maxmin_scaler',
'maxabs_scaler', 'zscore_scaler',
'robustscaler']
fig = plt.figure(figsize=(12,6))
for i,j in enumerate(data_list):
# 对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,
# 利用它可以同时获得索引和值,enumerate多用于在for循环中得到计数'''
plt.subplot(2,3,i+1)
plt.scatter(j.iloc[:,:-1],j.iloc[:,-1])
plt.title(title_list[i])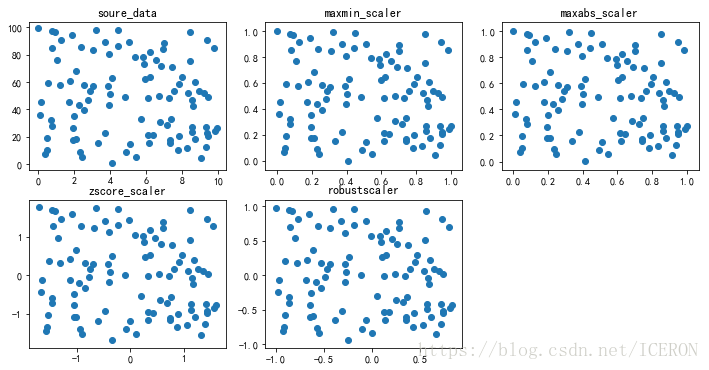

















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









