







数据的标准化(standardization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的归一化(normalization)处理,即将数据统一映射到[0,1]区间上,常见的数据归一化的方法有:
(1)最大最小标准化(Min-Max Normalization)
这个过程使得特征的范围在[0,1]内。首先计算每个数值特征的最小值个最大值,然后对特征的每个值均进行以下变换 :
def MaxMinNormalization(x):
"""[0,1] normaliaztion"""
x = (x - np.min(x)) / (np.max(x) - np.min(x))
return x
import numpy as np
def MaxMinNormalization(x):
"""[0,1] normaliaztion"""
x = (x - np.min(x)) / (np.max(x) - np.min(x))
return x
height=[188,176,170,165,168,174]
height_new=MaxMinNormalization(height)
print(height_new)
# -*- coding: utf-8 -*-
"""
@Time : 2022/10/3 23:34
@Author : Xu Yong Kang
"""
from sklearn import preprocessing
import pandas
data={
'height':[188,176,170,165,168,174]}#用字典来存放数据
price_frame=pandas.DataFrame(data)#把字典类型转化为dataframe对象
min_max_normalizer=preprocessing.MinMaxScaler(feature_range=(0,1))
#feature_range设置最大最小变换值,默认(0,1)
scaled_data=min_max_normalizer.fit_transform(price_frame)
#将数据缩放到设置固定区间
price_frame_normalized=pandas.DataFrame(scaled_data)
#将变换后的数据转换为dataframe对象
print(price_frame_normalized)
结果:
0 1.000000
1 0.478261
2 0.217391
3 0.000000
4 0.130435
5 0.391304
(2)Z-分数标准化(Z-Score Normalization):当数据包含离群值时,最大最小标准化并不是首选。在存在离群值的情况下,随着数据范围的增加,数值将不断接近零。Z-Score常用于标准化技术。Z-Score遵循统计学原理,使数据平均值为0,标准差为1。
这种标准化我在第一篇文章时间序列的预处理中使用过
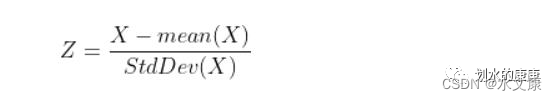
def ZscoreNormalization(x):
"""Z-score normaliaztion"""
x = (x - np.mean(x)) / np.std(x)
return x
height 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









