









STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation
魏云超(TPAMI 15)
通过显著性物体检测的结果,自动地生成语义分割的标签。通过low-level vision得到的约束能够帮助我们在弱监督的语义分割的学习中,减少对人工标注的依赖。具体将这项工作所做的贡献总结如下:(1)提出了一个简单到复杂的(STC)框架,能够以弱监督的方式有效地训练分割DCNN(即,仅提供图像级标签)。所提出的框架是通用的,并且可以结合任何最先进的全监督网络结构来学习分割网络。(2)引入了一个多标签交叉熵损失函数来训练基于显著图的分割网络,其中每个像素能够以不同的概率自适应地归结于前景类别和背景。(3) 在PASCAL VOC 2012分割基准上评估我们的方法。 实验结果很好地证明了STC框架的有效性,达到了最先进的实验结果。
首先用简单图像的显著图(即,具有单个类别的主要对象和干净背景的那些)的显著图来训练初始分割网络Initial-DCNN。这些显著图可以通过现有的自下而上的显著物体检测技术自动获得,其中不需要监督信息。然后,基于Initial-DCNN以及图像级注释,在预测的简单图像的分割掩模的监督下学习一个称为Enhanced-DCNN的更好的网络。最后,利用Enhanced-DCNN和图像级注释推导出复杂图像(背景杂乱的两类或多类物体)的更多像素级分割掩模作为监督信息学习Powerful-DCNN语义分割。

Initial DCNN:
其实可以把它当作是一个有显著性检测功能的CNN,但“它”能够知道显著性的物体是什么。具体实现是由DRFI(Salient Object Detection: A Discriminative Regional Feature Integration Approach )方法生成Saliency Map,再结合Image level label,通过多标签交叉熵损失函数来训练分割网络来训练网络。

Enhanced DCNN:
这一层主要是用来refine每一个物体的分割模版。由于I-DCNN在训练过程中,使用DRFI会有很大噪声,这个DCNN就是对上一个DCNN的refine。
Powerful DCNN:
简单图像的分割之后,对复杂的多目标的图像进行分割,这时候,以E-DCNN生成的结果作为P-DCNN的GroundTruth来训练P-DCNN。


Augmented Feedback in Semantic Segmentation Under Image Level Supervision(香港中文大学)
图像级监督下语义增强的语义分割

提出了新的图像级标签的语义分割框架,It unifies semantic segmentation and object localization with important proposal aggregation and selection modules.
four parts. Part (a) 全卷积分割网络 Part (b)目标定位网络. Part (c) is the proposal aggregation module. It aggregates the proposal localization result for segmentation training. Part (d) is the proposal selection module. It selects positive and negative proposals for training of the object localization branch. Our network is updated iteratively. In part (d), the green and red bounding boxes mark positive and negative samples. (Color figure online)
语义分割和目标定位有aggregation and proposal selection 两部分连接,两个分支互相提供反馈,在训练过程中逐渐纠正错误。语义分割是一个全卷积网络,以图像为输入,输出每类的scoremap,部分预测label,被聚合成前景和背景,然后将该信息与先前的目标定位预测相结合,以选择相应的正、负目标proposal ,用于当前迭代监督。
Built-in Foreground/Background Prior for Weakly-Supervised Semantic Segmentation(ANU)
以前景和背景先验的弱监督语义
对抗擦除的框架
我们基于VGG16训练图像的分类网络,将最后两个全连接层替换为卷积层,CAM被用来定位标签相关区域。在生成的location map(H)中,属于前20%最大值的像素点被擦除。我们具体的擦除方式是将对应的像素点的值设置为所有训练集图片的像素的平均值。
分割
一个能提取目标特征的训练过的识别模型。关注预训练好的VGG-16第4,5巻积层,相比前三层提供了高层次的深度特征。利用全连接条件随机场对信息进行平滑处理,得到前景背景mask,监督网络学习。

Object Region Mining with Adversarial Erasing: A Simple Classification to Semantic Segmentation Approach(魏云超,冯佳时,颜水成)基于对抗擦除的目标区域挖掘
目前我们注意到研究人员们提出了一些自上而下的attention方法(CAM, EP)。这类方法可以利用训练好的分类CNN模型自动获得同图像标签最相关的区域。如图2所示,我们给出了通过CAM方法获取的attention map。可以看出对于一个图像分类模型,往往物体的某个区域或某个instance对分类结果的贡献较大。因此这类attention方法只能找到同标签对应的某个物体最具判别力的区域而不是物体的整个局域。如何利用分类网络定位物体的整个区域,对语义分割任务具有重要意义。

将第一张图片以及它对应的标签“person”输入到网络中进行训练。继而,网络会尝试从图中发现一些证据来证明图中包含了“person”。一般来讲,人的head是最具判别力的部位,可以使此图被正确地判别为“person”。若将head从图片中移除(如第二张图中的橙色区域),网络会继续寻找其它证据来使得图像可以被正确分类,进而找到人的body区域。重复此操作,人的foot区域也可以被发现。由于训练本身是为了从图片中发现对应标签的证据而擦除操作则是为了掩盖证据,因此我们称这种训练-擦除-再训练-再擦除的方式为对抗擦除(adversarial erasing)。

我们首先利用原始图像训练一个分类网络,并利用自上而下的attention方法(CAM)来定位图像中最具判别力的物体区域。进而,我们将挖掘出的区域从原始图片中擦除,并将擦除后的图像训练另一个分类网络来定位其它的物体区域。我们重复此过程,直到网络在被擦除的训练图像上不能很好地收敛。最后将被擦除的区域合并起来作为挖掘出的物体区域。逐步用分类网络挖掘可判别的目标区域来处理若监督问题。提出了一种新的对抗擦除方法逐步获取目标局部区域和扩大目标区域。算法主要包括两个部分: adversarial erasing(AE) 和 online prohibitive segmentation learning (PSL)
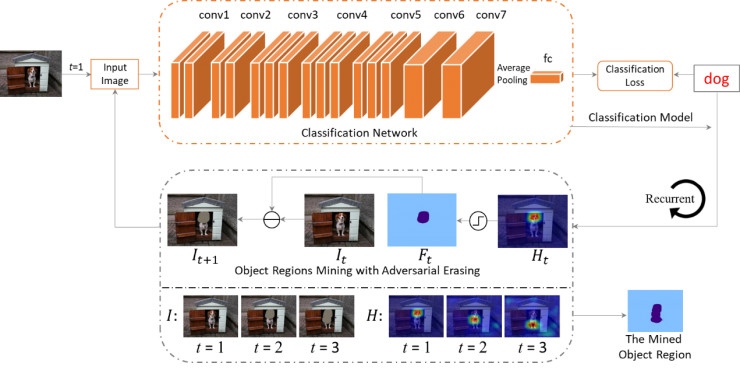
对抗擦除的框架
我们基于VGG16训练图像的分类网络,将最后两个全连接层替换为卷积层,CAM被用来定位标签相关区域。在生成的location map(H)中,属于前20%最大值的像素点被擦除。我们具体的擦除方式是将对应的像素点的值设置为所有训练集图片的像素的平均值。
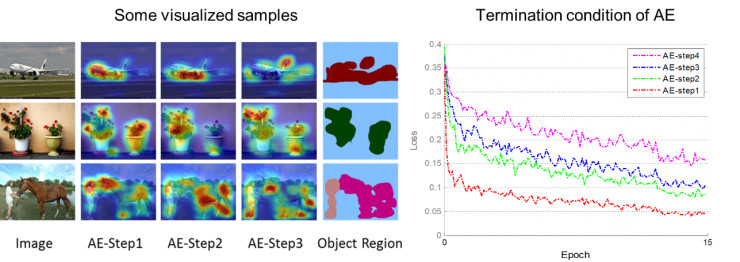
实施第四次擦除后,网络训练收敛后的loss值会有较大提升。主要原因在于大部分图片中的物体的区域已经被擦除,这种情况下大量的背景区域也有可能被引入。因此我们只合并了前三次擦除的区域作为图片中的物体区域。图6左给出部分训练图像在不同训练阶段挖掘出的物体区域,以及最后将擦除区域合并后的输出。

Online PSL for Semantic Segmentation

使用分类的置信度来调整对应类别的分割分数图。利用显著性检测技术生成的显著图生获取图像的背景信息,并同通过对抗擦除获得物体区域结合生成用于训练语义分割网络的segmentation mask(其中蓝色区域表示未指派语义标签的像素,这些像素点不参与训练)。由于在生成的segmentation mask中包含了一些噪声区域和未被标注的区域,为了更加有效地训练,我们提出了一种PSL方法训练语义分割网络,该方法引入了一个多标签分类的分支用于在线预测图像包含各个类别的概率值,这些概率被用来调整语义分割分支中每个像素属于各个类别的概率,并在线生成额外的segmentation mask作为监督信息。由于图像级的多标签分类往往具有较高的准确性,PSL方法可以利用分类信息来抑制分割图中的错误区域。随着训练的进行,网络的语义分割能力也会越来越强,继而在线生成的segmentation mask的质量也会提升,从而提供更加准确的监督信息。

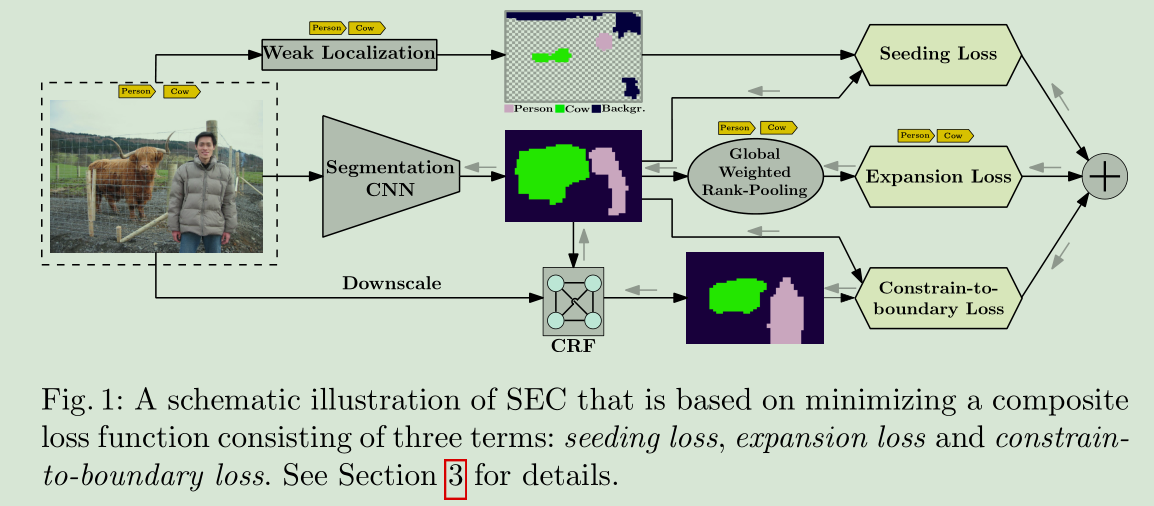
Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation
(IST Austria)
种子、展开与约束:弱监督图像分割的三个原则
提出了一个新的loss函数,基于三个原则:线索种子,图像中可能出现目标类别展开,边界约束
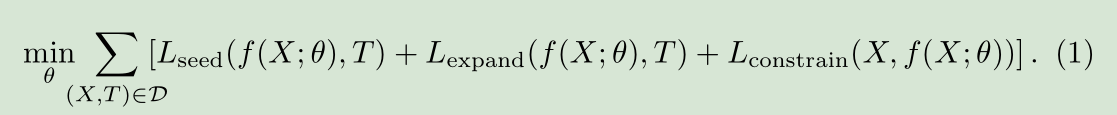


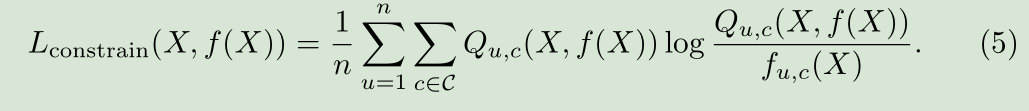
Exploiting Saliency for Object Segmentation from Image Level Labels
基于图像级标签的目标分割显着性研究
种子区域和显著性模型作为附加信息,并以此为先验。展示如何结合这两个信息源,恢复全监督的80%的分割精度。提出一种种子与显著性相结合的弱监督语义分割方法。
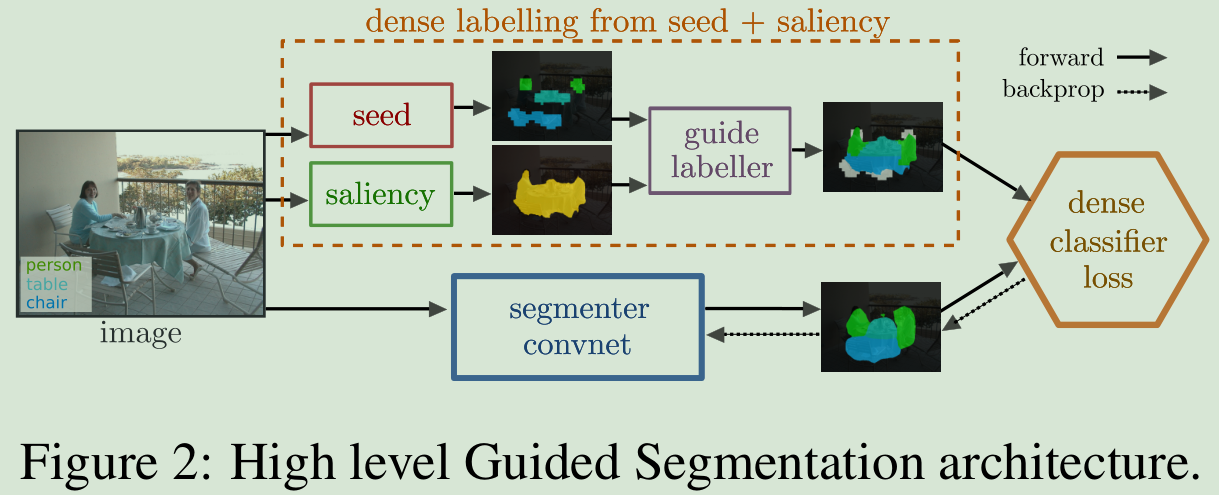
输入图像和图像级别标签,guide labeller结合seeder和saliency模块,产生一个粗糙的mask,把这个mask,全监督训练segmenter convnet,
Weakly-Supervised Semantic Segmentation Network with Deep Seeded Region Growing
华中科技大学,王兴刚
深种子区域生长的弱监督语义分割网络
将传统分割方法与深度网络结合,利用深度分类网络在图像级别的标签监督下定位可判别的的区域作为种子线索。没有提供语义和位置信息。一种可以判别的object region被保留在网络的深层,种子区域生长与深度网络结合,逐步实现对网络的实现像素级别的监督。种子区域生长模块集成在深度网络。详见ppt















 919
919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









