







作者简介
我是摘星,一名专注于云计算和AI技术的开发者。本次通过华为云MaaS平台体验DeepSeek系列模型,将实际使用经验分享给大家,希望能帮助开发者快速掌握华为云AI服务的核心能力。

目录
1. 引言
随着人工智能技术的快速发展,大语言模型(LLM)应用已成为企业数字化转型的重要工具。然而,对于许多开发者和企业来说,搭建高可用的LLM应用平台仍然面临着技术门槛高、部署复杂、维护成本高等挑战。本文将详细介绍如何利用华为云Flexus X实例和DeepSeek大模型,一键部署Dify高可用版,帮助企业快速构建自己的AI应用开发平台。
Dify作为一款融合后端即服务(BaaS)和LLMOps理念的开源平台,能够帮助开发者快速构建、部署和监控生成式AI应用。通过华为云提供的一键部署方案,我们可以在短时间内搭建起一个高可用、高性能的Dify平台,大幅降低技术门槛,提升开发效率。
2. 技术架构与方案概述
2.1 Dify平台简介
Dify是一款开源的大语言模型(LLM)应用开发平台,提供了包括可视化工作流编排、多模型调用、知识库问答、智能体开发等功能,使开发者能够以低代码甚至零代码的方式快速构建AI应用。
2.2 部署架构
本文将介绍两种部署架构:单机版和高可用版。
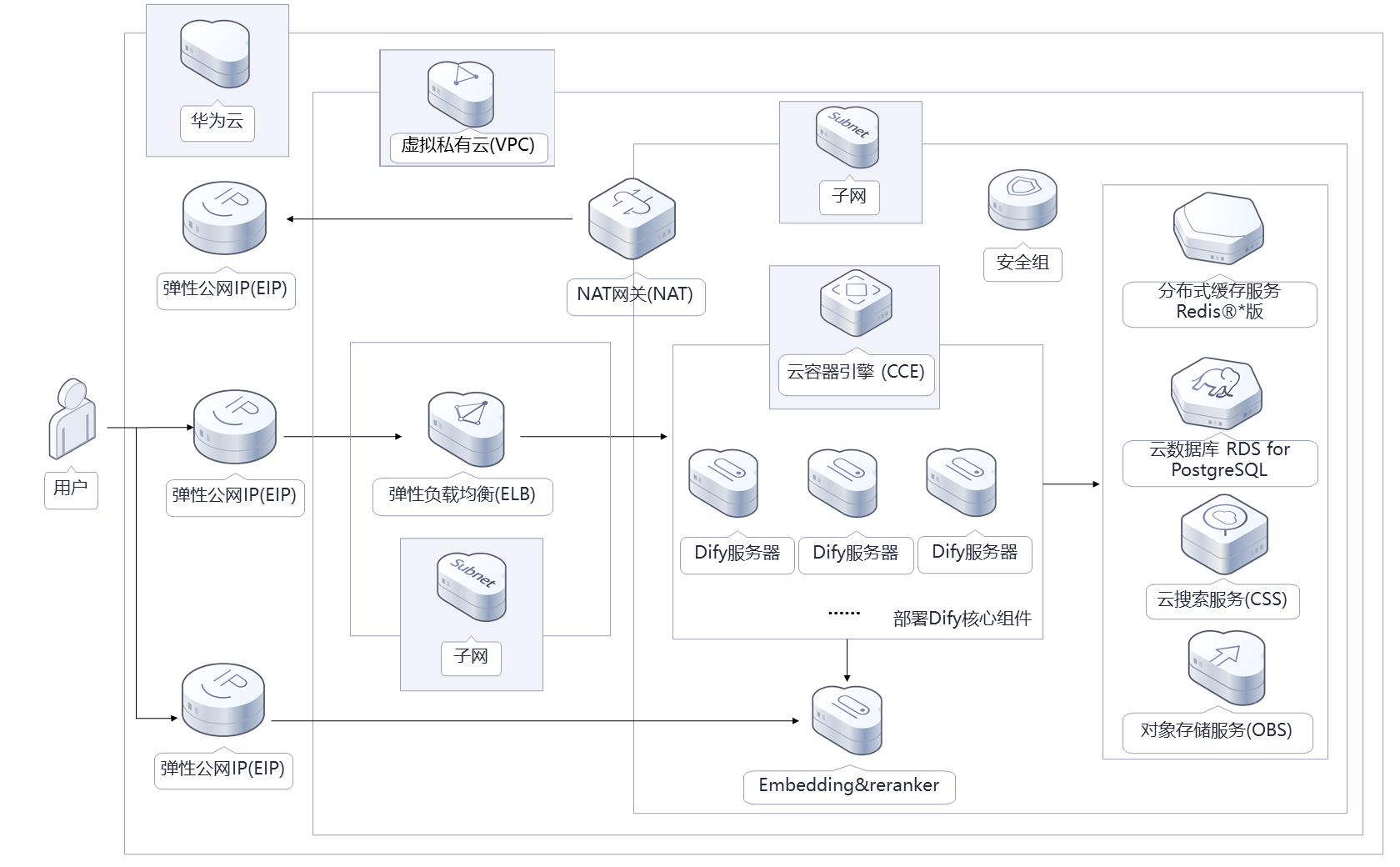
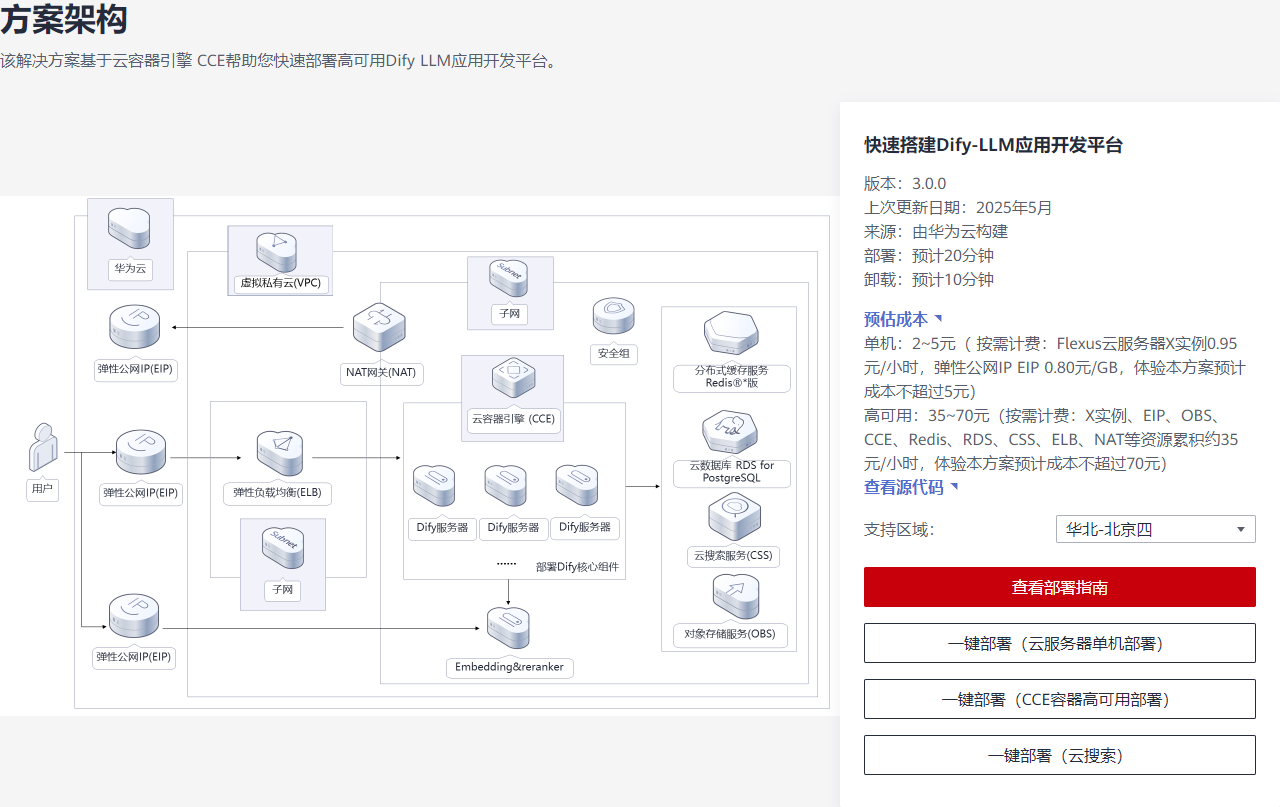
图1:Dify平台部署架构图
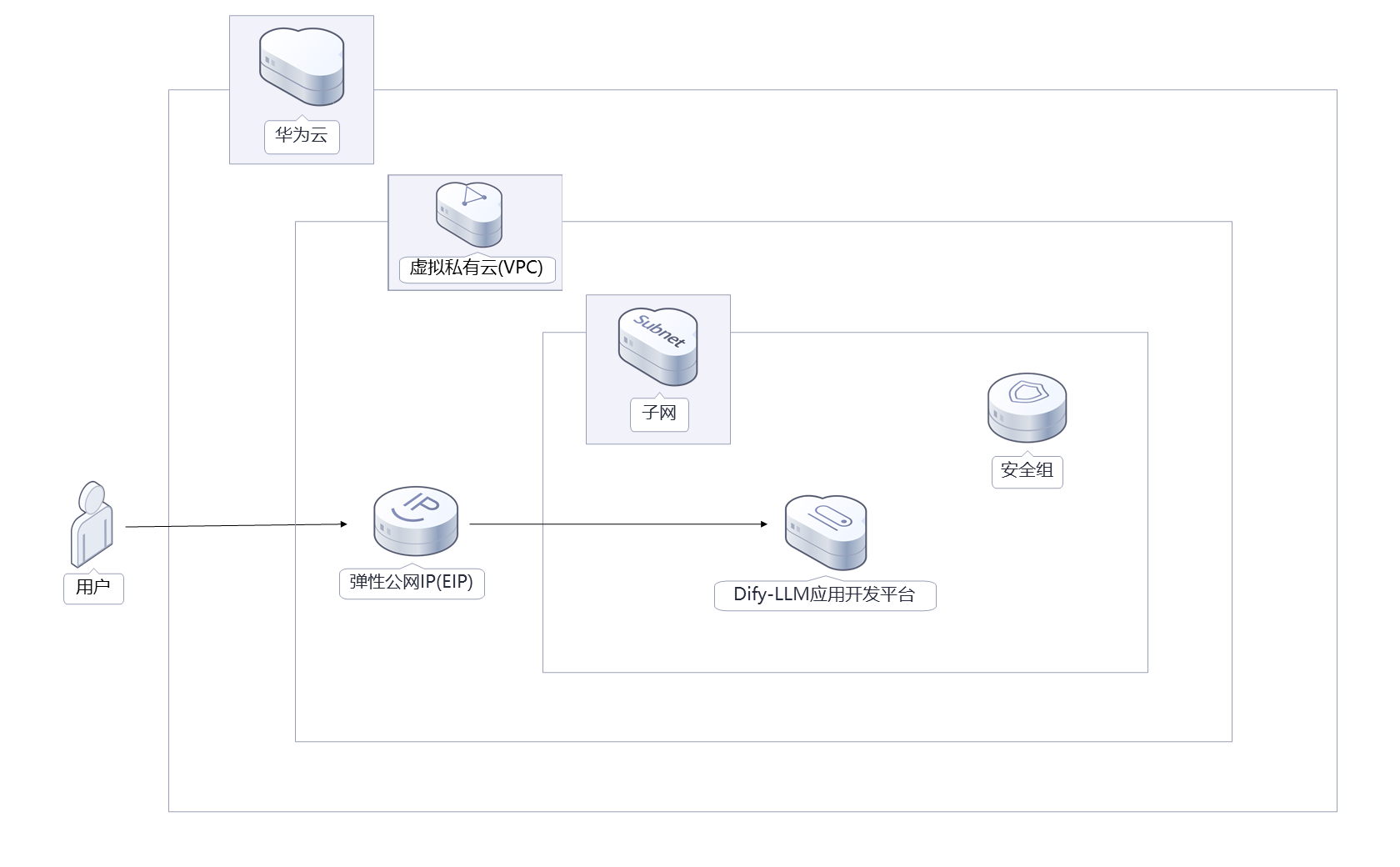
2.2.1 单机版架构
单机版适合个人开发者或小型团队使用,部署在单台Flexus X实例上,包含以下组件:
- Dify Web服务:提供用户交互界面
- Dify API服务:提供应用开发接口
- PostgreSQL:存储应用数据
- Redis:缓存和会话管理
- Weaviate:向量数据库,用于知识库检索
-
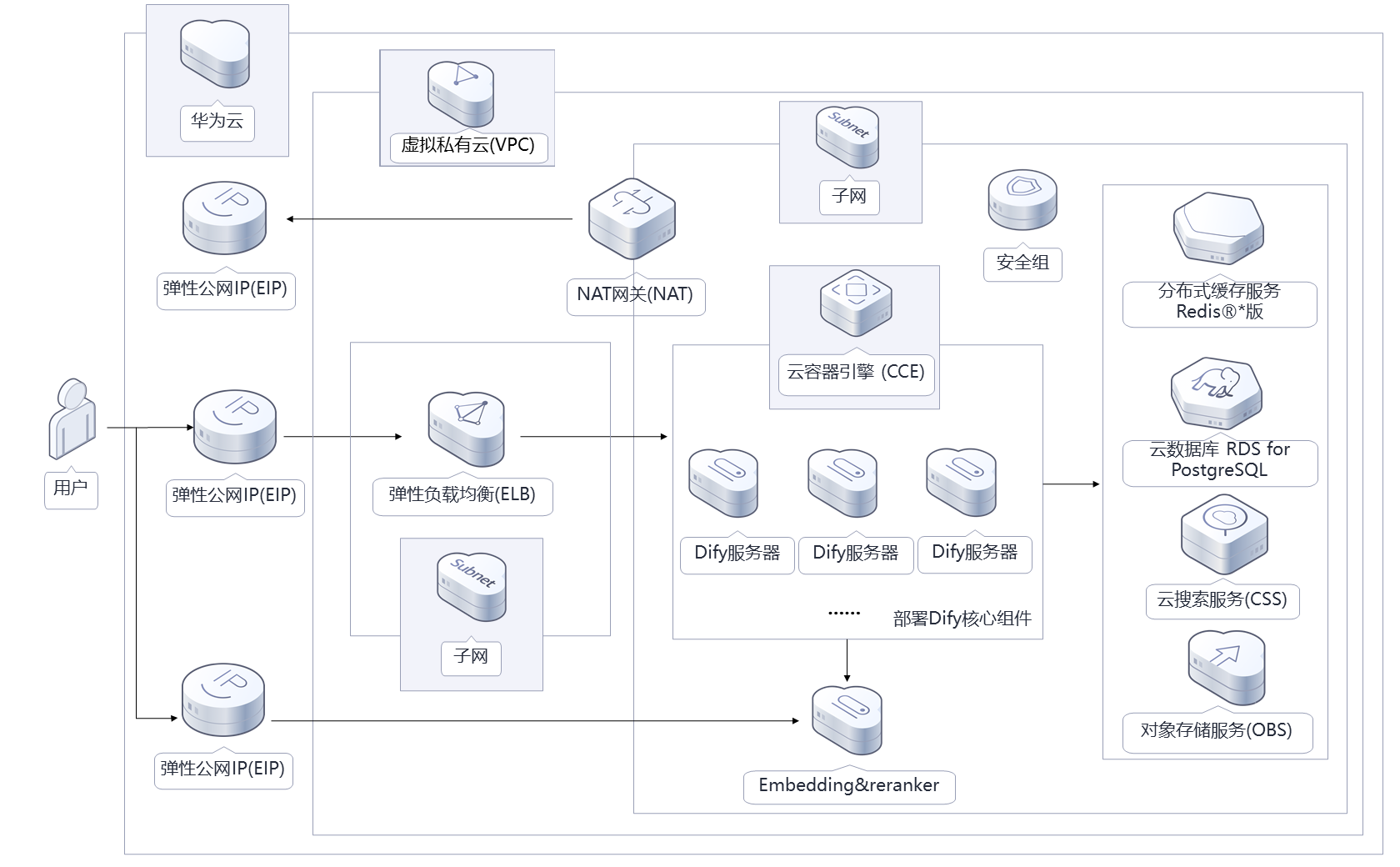
2.2.2 高可用版架构
高可用版适合企业级生产环境,基于华为云CCE(云容器引擎)部署,主要包含以下组件:
- 负载均衡:华为云ELB(弹性负载均衡),实现流量分发和服务高可用
- 多实例部署:多个Dify服务实例,支持横向扩展
- 分布式存储:RDS PostgreSQL集群和Redis集群
- 对象存储:OBS(对象存储服务),用于存储用户上传的文件
- 高可用向量库:分布式部署的Weaviate集群
-
2.3 Flexus X实例优势
华为云Flexus X实例作为Dify平台的基础设施,具有以下优势:
- 高性能:采用基于ARM架构的鲲鹏处理器,单核性能比传统x86实例提升60%,特别适合运行AI推理等计算密集型任务。
- 柔性算力:提供多种CPU和内存配比,满足不同应用场景需求,支持按需计费,降低企业成本。
- 高可靠性:提供99.99%的高可用性保障,满足企业级应用的可靠性要求。
- 成本优化:相比同规格x86实例,价格更具竞争力,性价比更高。
3. 环境准备与前置条件
3.1 账号准备
- 注册并登录华为云账号
- 开通以下服务权限:
-
- Flexus云服务器
- CCE(云容器引擎)
- ELB(弹性负载均衡)
- RDS(关系型数据库)
- OBS(对象存储服务)
-
3.2 DeepSeek模型服务开通
DeepSeek模型服务开通可以参考:华为云Flexus+DeepSeek征文 | DeepSeek-V3/R1商用服务开通体验全流程及使用评测_华为云 孟杰-CSDN博客
DeepSeek模型是本方案推荐的大语言模型,需要在华为云ModelArts Studio中开通:
# DeepSeek模型API调用示例
curl -X POST "https://modelarts-studio.cn-north-4.myhuaweicloud.com/v1/endpoint/service/inference" \
-H "Content-Type: application/json" \
-H "X-Auth-Token: YOUR_AUTH_TOKEN" \
-d '{
"model_id": "deepseek-v3-r1",
"prompt": "请简要介绍一下华为云Flexus X实例的优势",
"max_tokens": 1000,
"temperature": 0.7
}'3.3 资源规格推荐
根据不同的使用场景,推荐以下资源配置:
| 部署方式 | 使用场景 | 推荐配置 |
| 单机版 | 开发测试、小团队使用 | Flexus X实例:kc1.8xlarge.4(32核128GB) |
| 高可用版 | 企业生产环境 | Flexus X实例:kc1.8xlarge.4 * 3台RDS:PostgreSQL 4核16GBRedis:4核8GBELB:共享型 |
3.4 部署方式推荐
3.4.1 云服务器单机部署:
- 创建1台华为云Flexus云服务器X实例,用于搭建Dify-LLM应用开发平台。
- 创建1个弹性公网IP EIP并关联FlexusX实例,提供访问公网和被公网访问能力。
- 创建1个安全组,通过配置安全组规则,为云服务器提供安全防护。
3.4.2 CCE容器高可用部署:
- 创建3个弹性公网IP EIP,提供访问公网和被公网访问能力。
- 创建1个弹性负载均衡 ELB,并绑定EIP,将访问流量自动分发到不同后端服务,扩展应用系统对外的服务能力,实现强大的应用容错性能。
- 创建1个NAT网关 NAT,并绑定EIP。配置SNAT规则,提供安全可靠的公网NAT网关和私网NAT网关服务,保护私有网络信息不对外暴露。
- 创建3台FlexusX实例,用于安装部署Dify5个核心插件。
- 创建1个云容器引擎 CCE Turbo集群,创建节点池并将上述3台FlexusX实例纳管为集群的Node节点。
- 创建1个华为云Flexus云服务器X实例,用于部署Embedding(bge-m3)及Reranker(bge-reranker-v2-m3)模型。
- 使用对象存储服务OBS服务,用于将Dify的知识库挂载在对象存储服务 OBS桶上。
- 创建1个分布式缓存服务Redis®*版,兼容Redis,为用户提供高性能、低成本NoSQL数据库,同时数据流转过程中数据的一致性。
- 创建1个云数据库 RDS for PostgreSQL实例,主备分区部署,具备跨可用区故障容灾的能力。
- 创建1个云搜索服务 CSS OpenSearch集群,提供在线分布式搜索及语义搜索等功能。
- 创建4个安全组,通过配置安全组规则,为云服务提供安全防护。
4. 高可用版Dify一键部署步骤
4.1 创建CCE集群(可选)
首先,我们需要创建一个CCE集群作为Dify服务的运行环境:
# 以下是使用华为云CLI创建CCE集群的命令示例
hcloud cce cluster create \
--name dify-cluster \
--flavor cce.s2.medium \
--vpc-id vpc-xxxx \
--subnet-id subnet-xxxx \
--container-network-mode vpc-router \
--authentication-mode rbac \
--region cn-north-4 \
--az cn-north-4a创建CCE集群的关键参数说明:
--name:集群名称--flavor:集群规格,建议选择标准版或以上--vpc-id和--subnet-id:VPC网络信息--container-network-mode:容器网络模式,推荐vpc-router--authentication-mode:认证模式,推荐rbac
4.2 使用一键部署功能
华为云提供了一键部署功能,极大简化了部署流程。具体步骤如下:
- 登录华为云快速搭建Dify-LLM控制台
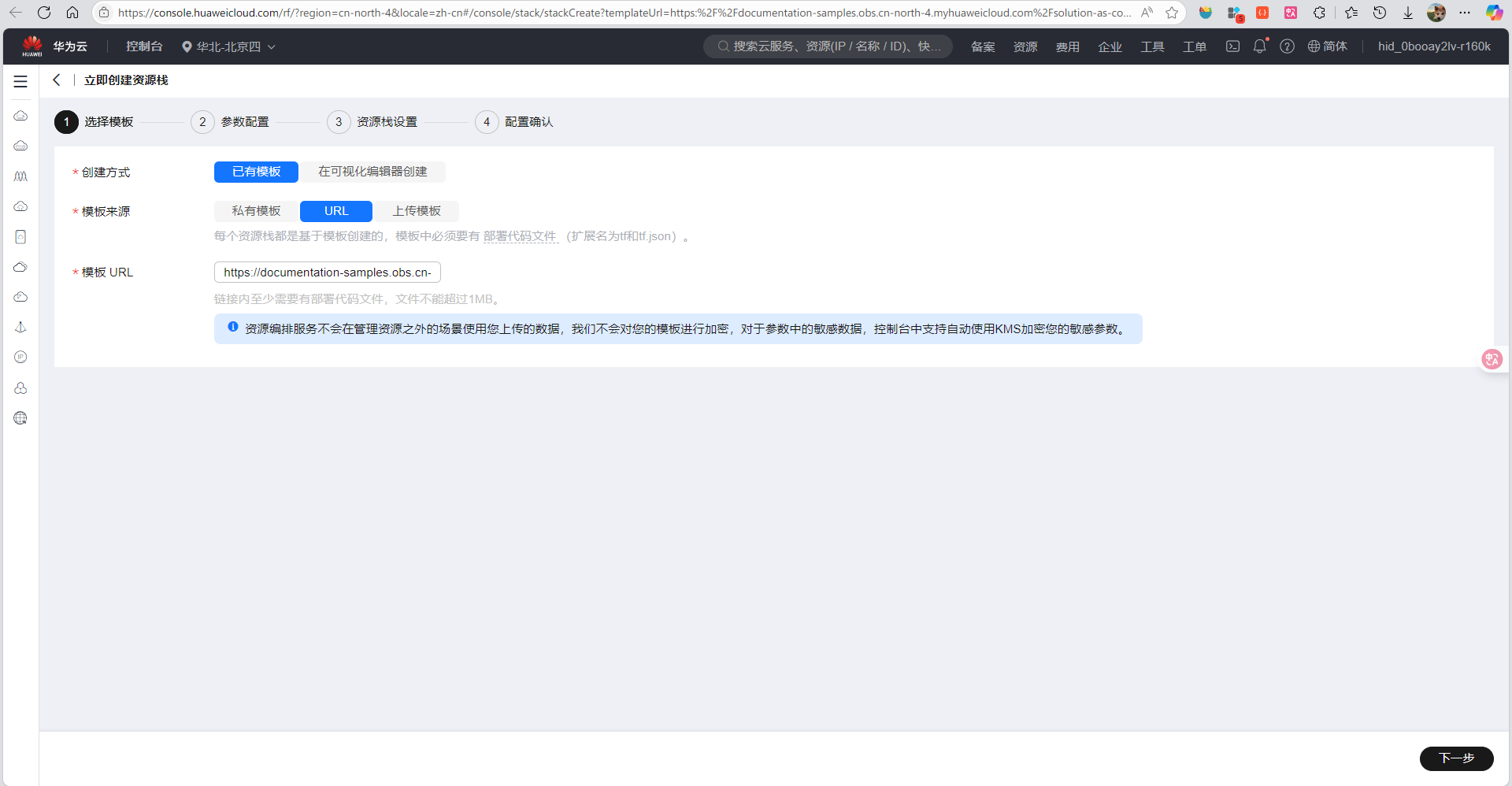
- 进入"解决方案 > 一键部署"页面,选择"快速搭建Dify-LLM应用开发平台(高可用版)"
- 点击"下一步"按钮,进入部署配置页面
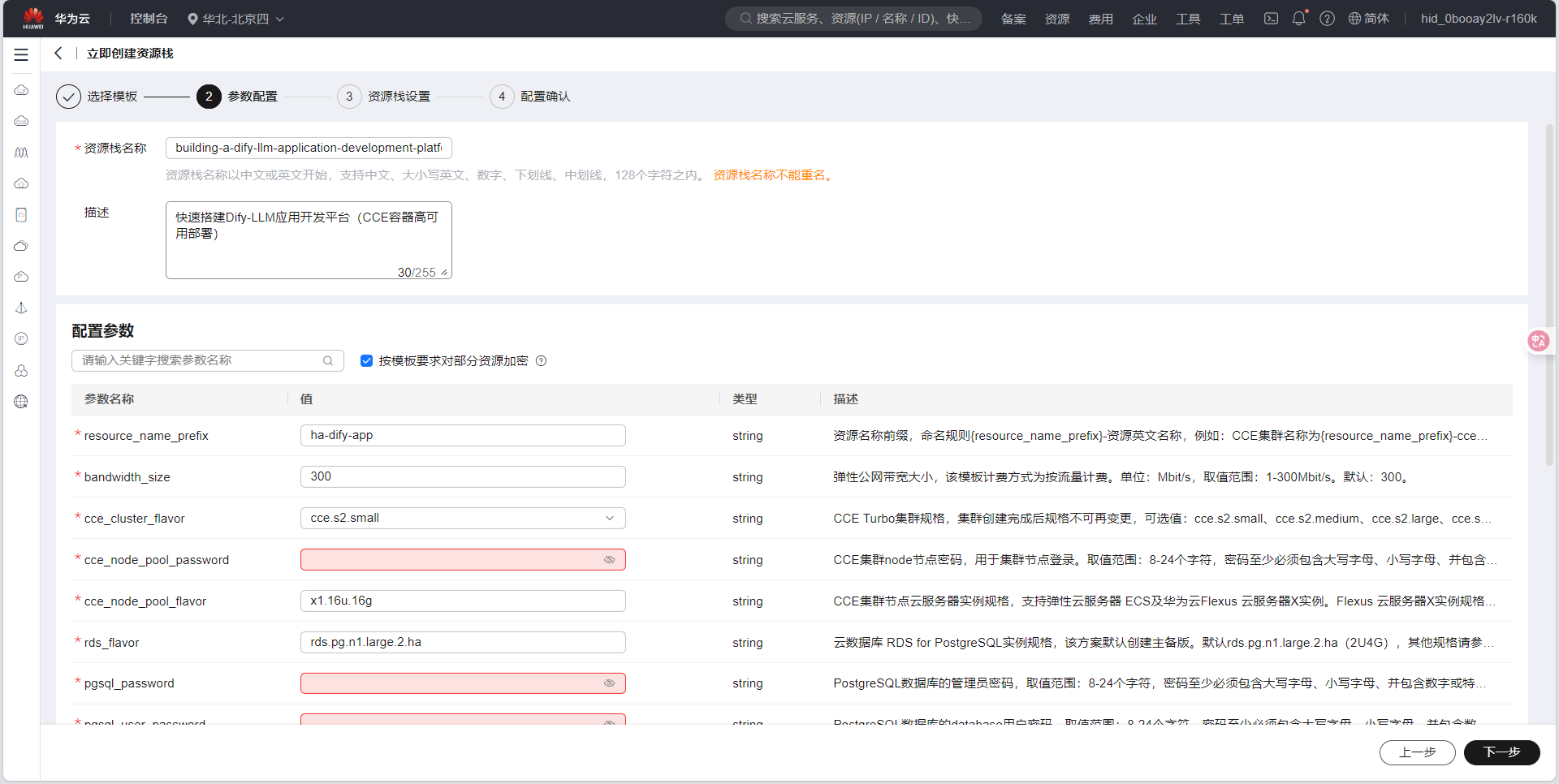
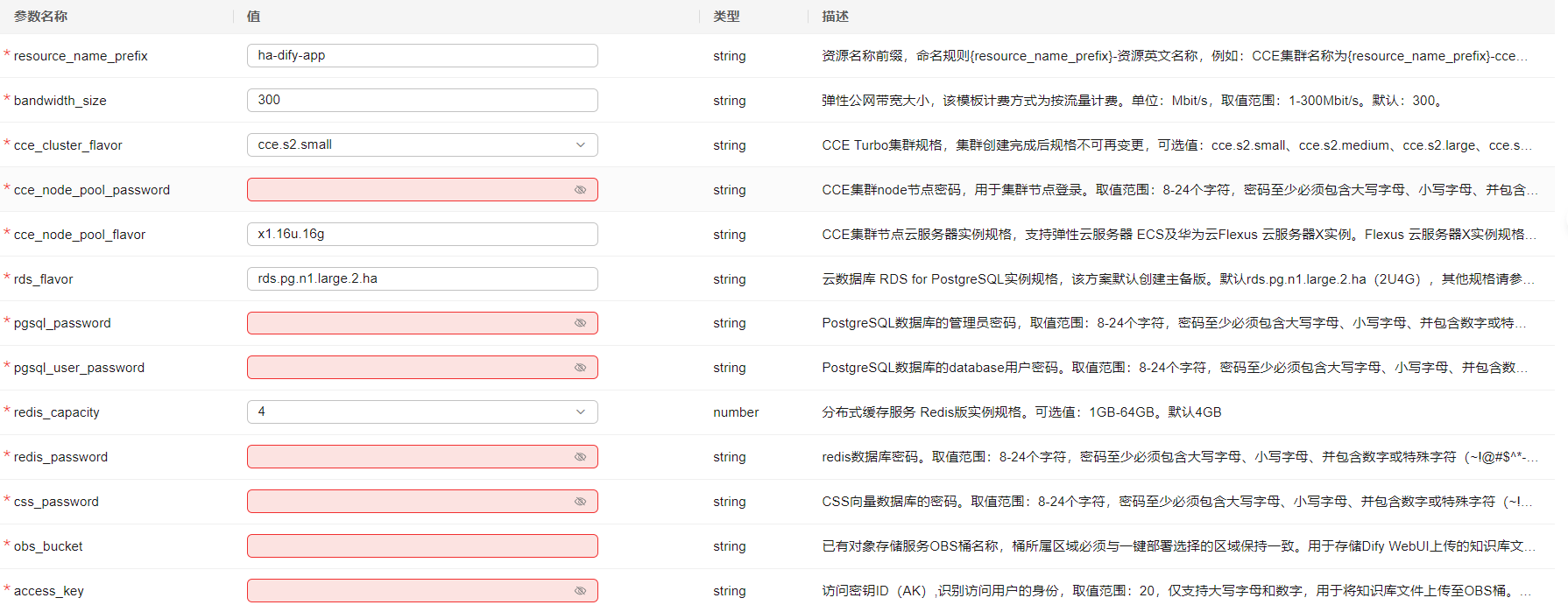

- 确定好配置信息之后点击下一步,来到资源栈设置
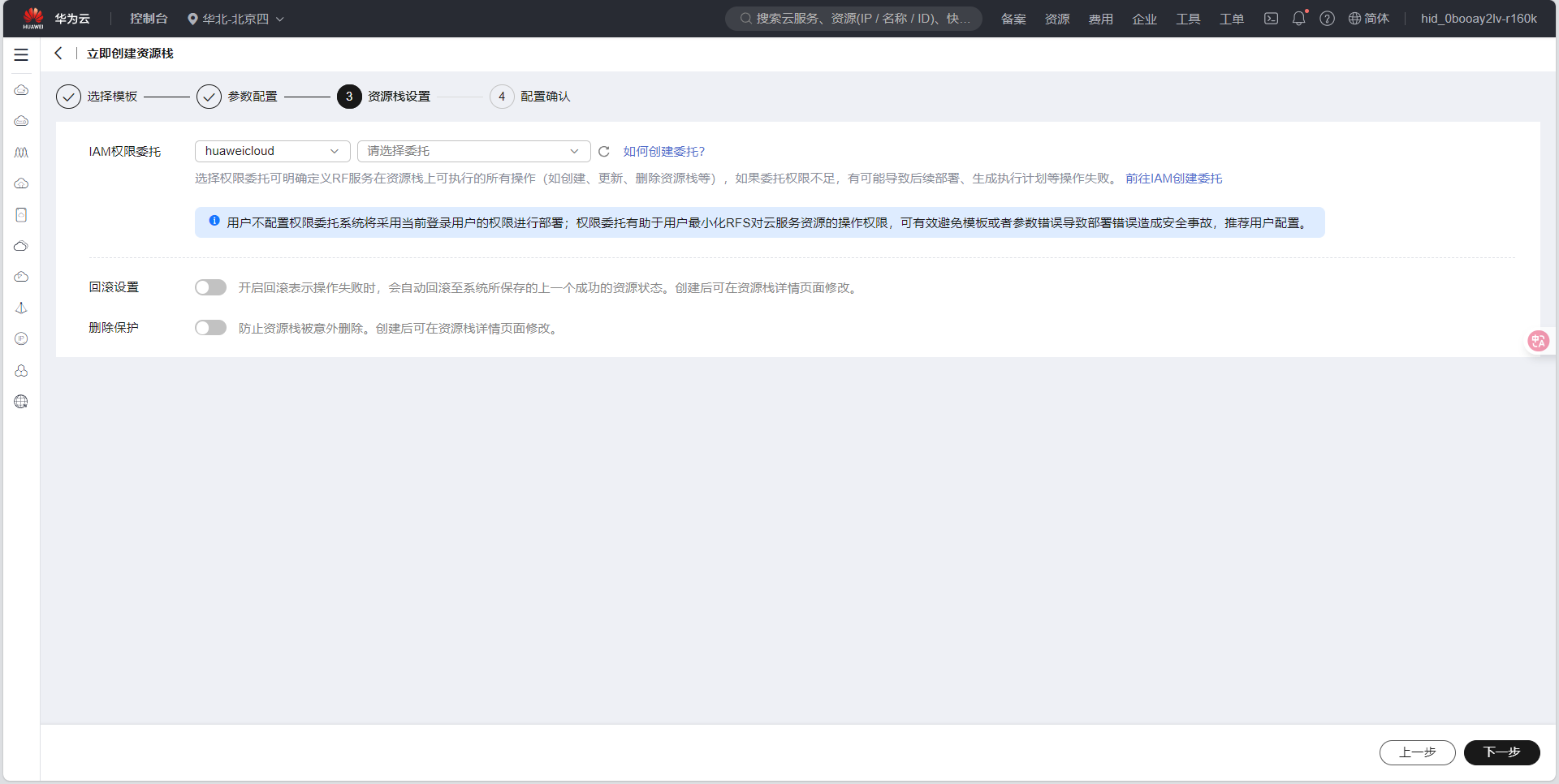
- 选择资源栈设置点击下一步来到创建页面
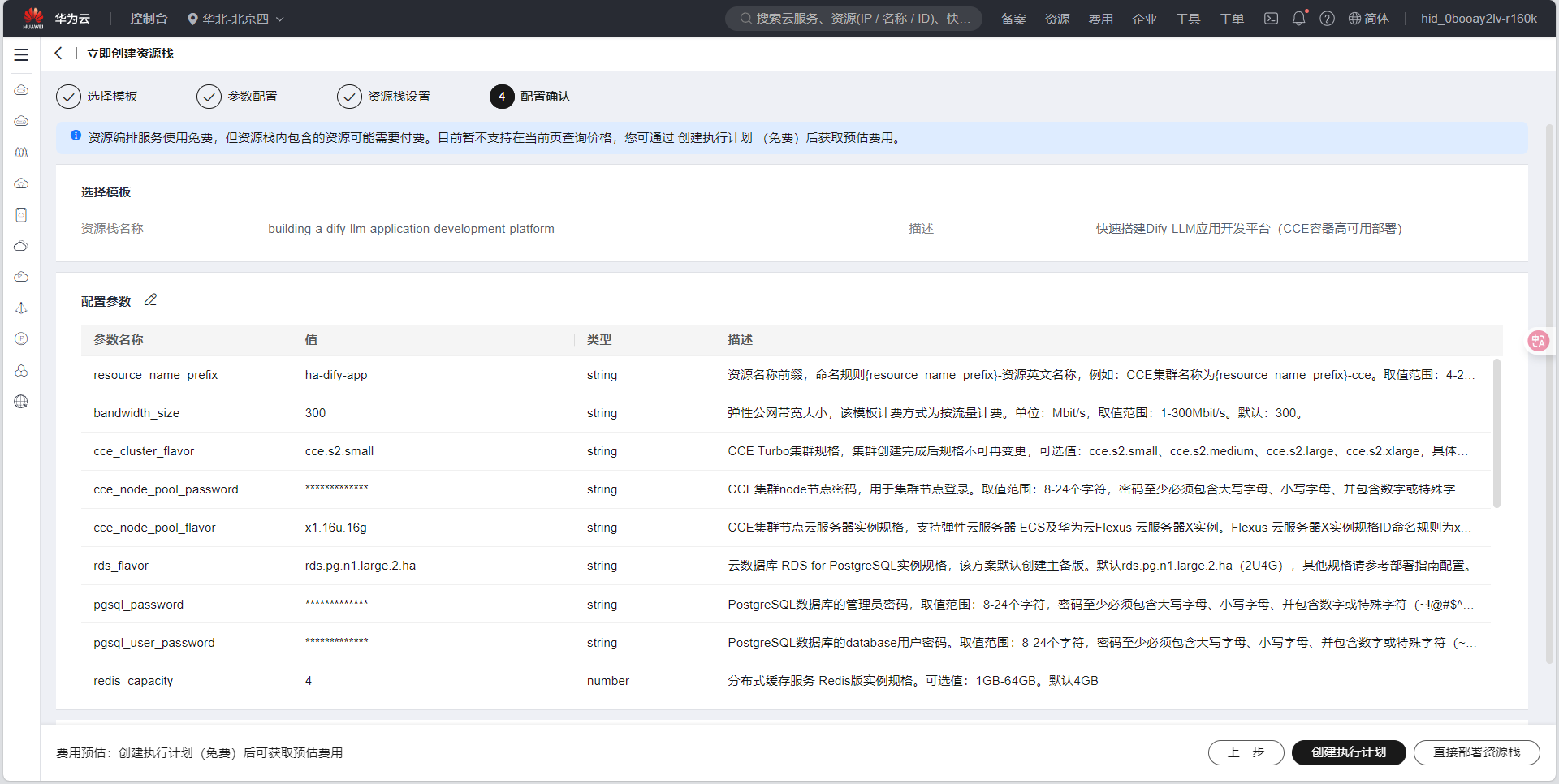
- 我们首先选择创建执行计划
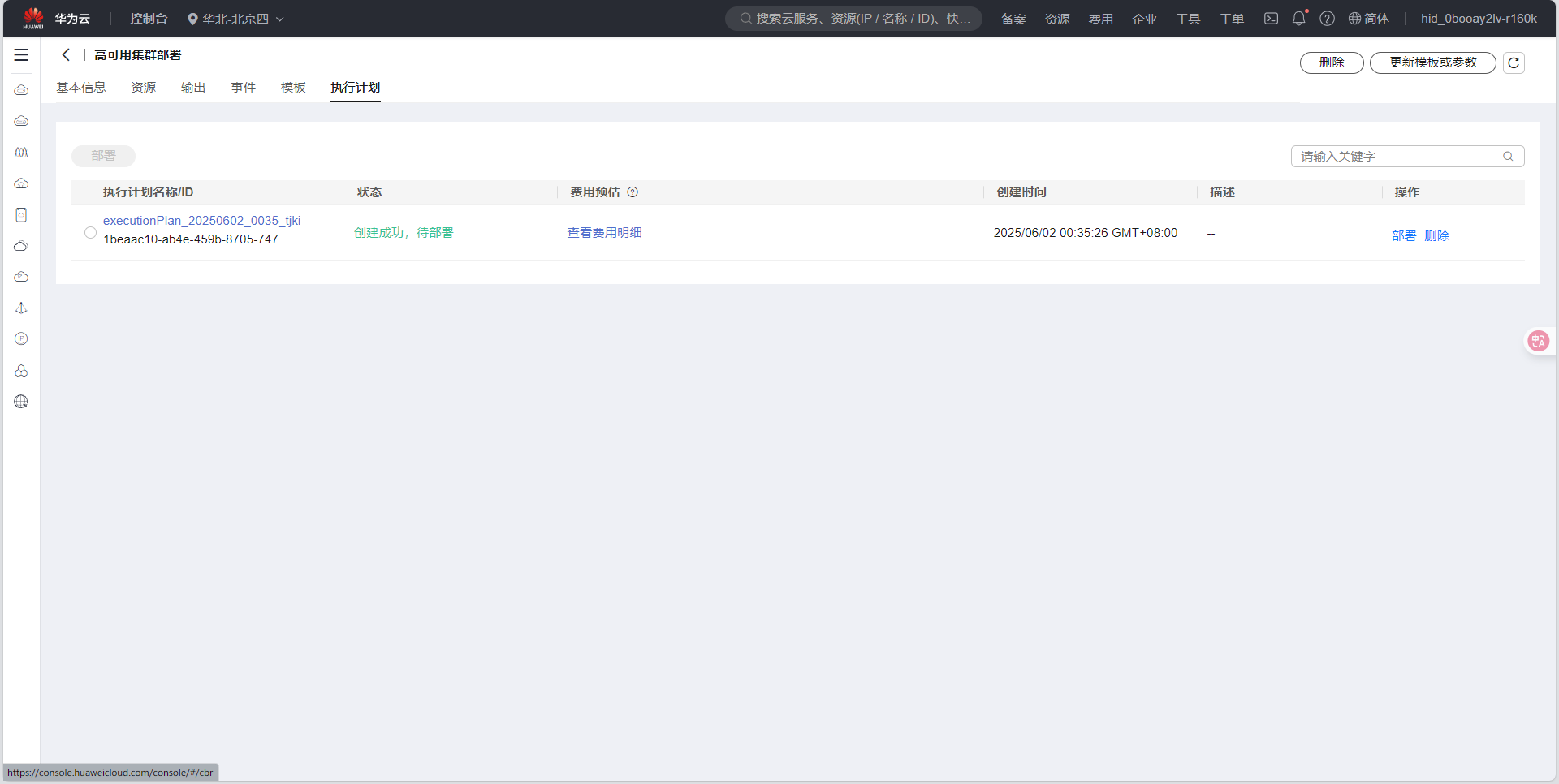
- 状态为创建成功,待部署之后,点击部署
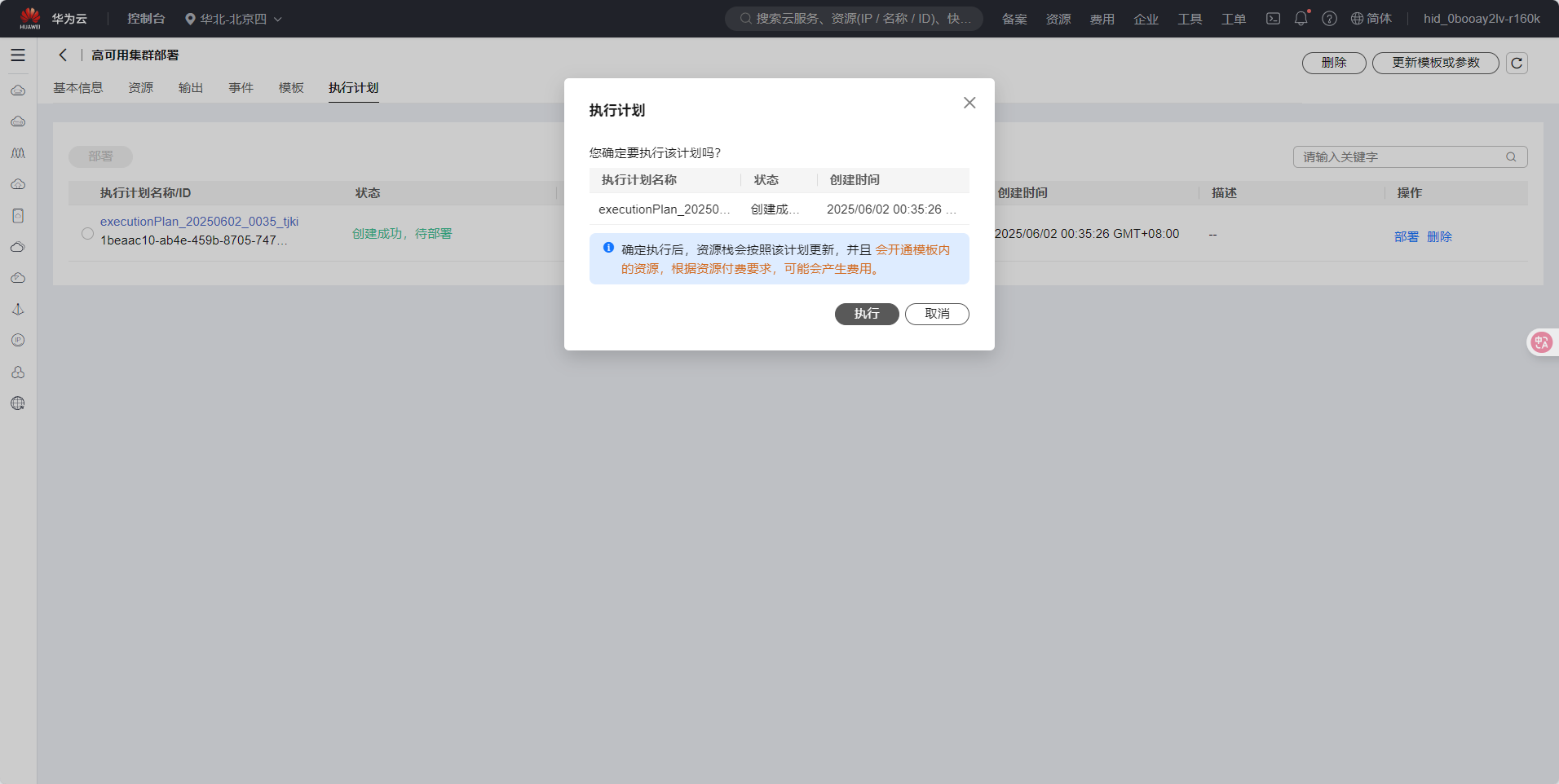
- 点击"部署"按钮后,系统将自动执行部署流程。部署过程可能需要15-30分钟,您可以在部署详情页查看部署进度:
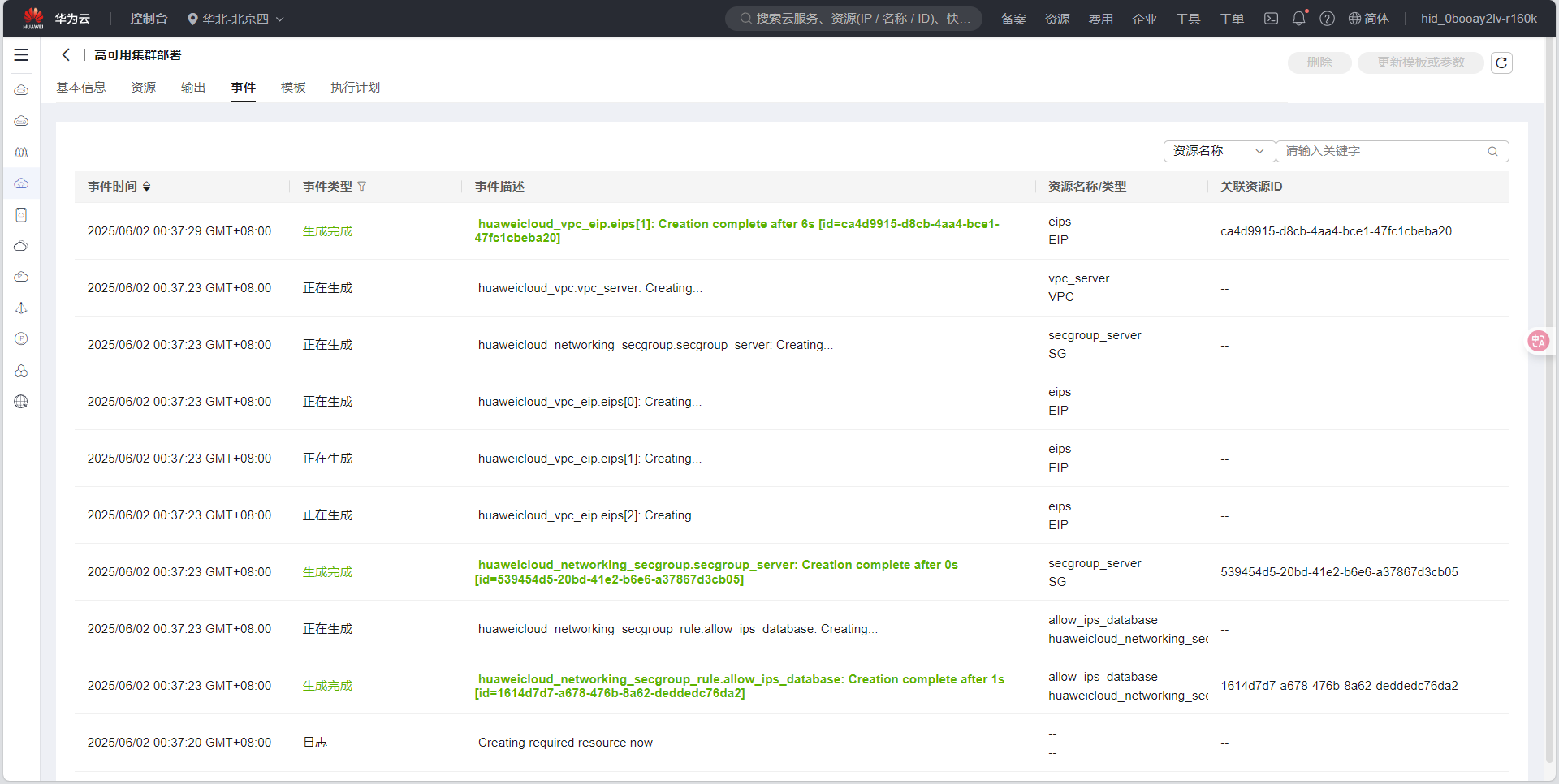
部署完成后,系统会提供访问地址,通常是以下两个地址:
- Dify管理后台:
https://{ELB_IP}/admin - Dify API接口:
https://{ELB_IP}/api
5. Dify平台初始化与配置
5.1 首次访问与管理员设置
首次访问Dify管理后台时,需要创建管理员账号:
// 管理员账号创建示例代码
const createAdmin = async () => {
try {
const response = await fetch('https://{ELB_IP}/api/setup', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
name: '管理员',
email: 'admin@example.com',
password: 'Admin@123456',
confirm_password: 'Admin@123456'
})
});
const result = await response.json();
if (result.success) {
console.log('管理员账号创建成功');
} else {
console.error('创建失败:', result.message);
}
} catch (error) {
console.error('请求错误:', error);
}
};
createAdmin();5.2 模型配置
登录管理后台后,需要配置AI模型。推荐配置DeepSeek模型:
- 进入"Settings > AI Providers"页面
- 点击"Add Provider",选择"DeepSeek"
- 填写以下配置信息:
-
- Provider名称:DeepSeek
- API Key:从ModelArts Studio获取的DeepSeek API Key
- Base URL:
https://modelarts-studio.cn-north-4.myhuaweicloud.com/v1/endpoint/service/inference - 模型列表:添加"deepseek-v3-r1"等模型
5.3 知识库配置
Dify的知识库功能依赖向量数据库,高可用版本中使用分布式部署的Weaviate:
# 知识库配置和测试代码
import requests
import json
def test_knowledge_base_connection():
# Dify API认证信息
api_key = "your_dify_api_key"
base_url = "https://{ELB_IP}/api/v1"
# 创建一个简单的知识库
create_kb_payload = {
"name": "测试知识库",
"description": "用于测试高可用Dify部署的知识库",
"vector_db_type": "weaviate",
"embedding_model": {
"provider_name": "openai",
"model_name": "text-embedding-ada-002"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
# 创建知识库
response = requests.post(
f"{base_url}/knowledge-bases",
headers=headers,
data=json.dumps(create_kb_payload)
)
if response.status_code == 200:
kb_id = response.json()["data"]["id"]
print(f"知识库创建成功,ID: {kb_id}")
return kb_id
else:
print(f"知识库创建失败: {response.text}")
return None
# 调用测试函数
test_knowledge_base_connection()6. Dify高可用特性验证
6.1 负载均衡测试
验证ELB负载均衡效果,确保请求能够均衡分配到各个Dify实例:
# 负载均衡测试脚本
import requests
import time
import concurrent.futures
import matplotlib.pyplot as plt
import numpy as np
def send_request(url):
try:
start_time = time.time()
response = requests.get(url)
end_time = time.time()
return {
"status_code": response.status_code,
"response_time": end_time - start_time,
"server": response.headers.get("X-Server-ID", "unknown")
}
except Exception as e:
return {
"status_code": 0,
"response_time": 0,
"server": "error",
"error": str(e)
}
def load_test(url, num_requests=100, concurrency=10):
results = []
with concurrent.futures.ThreadPoolExecutor(max_workers=concurrency) as executor:
future_to_url = {executor.submit(send_request, url): i for i in range(num_requests)}
for future in concurrent.futures.as_completed(future_to_url):
results.append(future.result())
# 统计结果
status_codes = {}
response_times = []
servers = {}
for result in results:
status = result["status_code"]
status_codes[status] = status_codes.get(status, 0) + 1
if result["response_time"] > 0:
response_times.append(result["response_time"])
server = result["server"]
servers[server] = servers.get(server, 0) + 1
# 打印统计信息
print(f"总请求数: {num_requests}")
print(f"状态码统计: {status_codes}")
print(f"平均响应时间: {np.mean(response_times):.3f}秒")
print(f"服务器分布: {servers}")
# 绘制服务器分布图
plt.figure(figsize=(10, 6))
plt.bar(servers.keys(), servers.values())
plt.title("请求分布在不同服务器上的情况")
plt.xlabel("服务器ID")
plt.ylabel("请求数")
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig("load_balance_test.png")
return results
# 执行负载测试
load_test("https://{ELB_IP}/api/status", num_requests=1000, concurrency=50)6.2 故障转移测试
模拟一个Dify实例故障,验证系统的自动故障转移能力:
# 模拟故障的kubectl命令
# 获取Dify API Pod列表
kubectl get pods -n dify-namespace -l app=dify-api
# 模拟其中一个Pod故障
kubectl delete pod dify-api-76f8d8d5b7-abcd1 -n dify-namespace
# 观察Pod重建过程
kubectl get pods -n dify-namespace -l app=dify-api -w
# 监控服务可用性
while true; do
curl -s -o /dev/null -w "%{http_code}\n" https://{ELB_IP}/api/status
sleep 1
done6.3 性能测试
使用JMeter或Locust等工具进行性能测试,验证系统在高并发下的表现:
# Locust性能测试脚本示例
from locust import HttpUser, task, between
class DifyUser(HttpUser):
wait_time = between(1, 3)
def on_start(self):
# 登录获取token
response = self.client.post("/api/auth/login", json={
"email": "admin@example.com",
"password": "Admin@123456"
})
self.token = response.json()["data"]["token"]
self.headers = {"Authorization": f"Bearer {self.token}"}
@task(1)
def get_dashboard(self):
self.client.get("/api/dashboard", headers=self.headers)
@task(3)
def list_apps(self):
self.client.get("/api/apps", headers=self.headers)
@task(5)
def chat_completion(self):
self.client.post("/api/chat-completion", json={
"messages": [
{"role": "user", "content": "你好,请介绍一下华为云Flexus X实例的优势"}
],
"model": "deepseek-v3-r1",
"temperature": 0.7
}, headers=self.headers)
# 运行命令: locust -f locust_script.py --host=https://{ELB_IP}7. 监控与运维
7.1 监控体系搭建
为了确保Dify平台的稳定运行,建议搭建以下监控体系:
图4:高可用Dify平台监控系统架构图
// Prometheus监控配置示例
const prometheusConfig = `
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'dify-web'
kubernetes_sd_configs:
- role: pod
namespaces:
names: ['dify-namespace']
selectors:
- role: pod
label: 'app=dify-web'
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- job_name: 'dify-api'
kubernetes_sd_configs:
- role: pod
namespaces:
names: ['dify-namespace']
selectors:
- role: pod
label: 'app=dify-api'
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
`;
// Grafana监控面板示例
const grafanaDashboard = {
"title": "Dify高可用平台监控",
"panels": [
{
"title": "CPU使用率",
"type": "graph",
"datasource": "Prometheus",
"targets": [
{
"expr": "sum(rate(container_cpu_usage_seconds_total{namespace=\"dify-namespace\"}[5m])) by (pod)",
"legendFormat": "{{pod}}"
}
]
},
{
"title": "内存使用率",
"type": "graph",
"datasource": "Prometheus",
"targets": [
{
"expr": "sum(container_memory_usage_bytes{namespace=\"dify-namespace\"}) by (pod)",
"legendFormat": "{{pod}}"
}
]
},
{
"title": "API请求量",
"type": "graph",
"datasource": "Prometheus",
"targets": [
{
"expr": "sum(rate(http_requests_total{namespace=\"dify-namespace\"}[5m])) by (method, path)",
"legendFormat": "{{method}} {{path}}"
}
]
},
{
"title": "响应时间",
"type": "graph",
"datasource": "Prometheus",
"targets": [
{
"expr": "histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket{namespace=\"dify-namespace\"}[5m])) by (le, method, path))",
"legendFormat": "{{method}} {{path}}"
}
]
}
]
};7.2 日志管理
配置集中式日志管理,便于问题排查和分析:
# ELK日志收集配置示例
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: dify-namespace
data:
filebeat.yml: |-
filebeat.inputs:
- type: container
paths:
- /var/log/containers/dify-*.log
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
output.elasticsearch:
hosts: ['elasticsearch-service:9200']
index: "dify-logs-%{+yyyy.MM.dd}"
username: "${ELASTICSEARCH_USERNAME}"
password: "${ELASTICSEARCH_PASSWORD}"
setup.kibana:
host: "kibana-service:5601"7.3 备份与恢复
为确保数据安全,需要配置定期备份机制:
# PostgreSQL数据库备份脚本
#!/bin/bash
# 备份配置
BACKUP_DIR="/backup/postgres"
DATE=$(date +%Y%m%d_%H%M%S)
RDS_HOST="postgres-xxxx.rds.huaweicloud.com"
RDS_PORT="5432"
RDS_USER="dify_admin"
RDS_PASSWORD="********"
RDS_DATABASE="dify"
# 创建备份目录
mkdir -p $BACKUP_DIR
# 执行备份
PGPASSWORD=$RDS_PASSWORD pg_dump -h $RDS_HOST -p $RDS_PORT -U $RDS_USER -d $RDS_DATABASE -F c -f $BACKUP_DIR/dify_$DATE.dump
# 上传到OBS备份
/usr/local/bin/obsutil cp $BACKUP_DIR/dify_$DATE.dump obs://dify-backup/postgres/
# 保留最近30天备份,删除旧备份
find $BACKUP_DIR -name "*.dump" -type f -mtime +30 -delete
echo "Backup completed: $BACKUP_DIR/dify_$DATE.dump"8. 性能优化与最佳实践
8.1 数据库优化
针对PostgreSQL数据库的性能优化建议:
-- 创建常用查询的索引
CREATE INDEX idx_conversation_app_id ON conversation(app_id);
CREATE INDEX idx_message_conversation_id ON message(conversation_id);
CREATE INDEX idx_knowledge_file_kb_id ON knowledge_file(knowledge_base_id);
-- 设置适当的自动清理参数
ALTER SYSTEM SET autovacuum_vacuum_scale_factor = 0.05;
ALTER SYSTEM SET autovacuum_analyze_scale_factor = 0.025;
ALTER SYSTEM SET autovacuum_naptime = '1min';
-- 优化连接池配置
ALTER SYSTEM SET max_connections = 500;
ALTER SYSTEM SET shared_buffers = '4GB';
ALTER SYSTEM SET effective_cache_size = '12GB';
ALTER SYSTEM SET work_mem = '32MB';8.2 应用层优化
针对Dify应用的优化建议:
# Dify应用层优化配置
# 在kubernetes deployment中设置资源限制
resources = {
"requests": {
"cpu": "2000m",
"memory": "4Gi"
},
"limits": {
"cpu": "4000m",
"memory": "8Gi"
}
}
# 配置应用层缓存
cache_config = {
"CACHE_TYPE": "redis",
"CACHE_REDIS_HOST": "redis-service",
"CACHE_REDIS_PORT": 6379,
"CACHE_REDIS_PASSWORD": "********",
"CACHE_DEFAULT_TIMEOUT": 300 # 5分钟缓存过期时间
}
# 优化工作线程数量
worker_config = {
"worker_class": "gevent",
"workers": 4,
"threads": 2,
"timeout": 120,
"keepalive": 5
}8.3 网络优化
优化网络配置,提高访问速度和稳定性:
# 配置CDN加速静态资源
# 在华为云CDN控制台创建加速域名
domain="dify.example.com"
origin_address="{ELB_IP}"
origin_protocol="https"
cache_rules='[
{"rule_type":"suffix","rule_value":["jpg","png","css","js"],"ttl":86400},
{"rule_type":"path","rule_value":["/static/*"],"ttl":86400}
]'
# 使用华为云API创建CDN加速域名
curl -X POST "https://cdn.myhuaweicloud.com/v1.0/cdn/domains" \
-H "Content-Type: application/json" \
-H "X-Auth-Token: $TOKEN" \
-d '{
"domain": {
"name": "'$domain'",
"sources": [{
"ip_or_domain": "'$origin_address'",
"origin_type": "ipaddr",
"active": 1,
"enable_obs_web_hosting": false
}],
"protocol": "https",
"cache_config": '$cache_rules'
}
}'9. 常见问题与解决方案
9.1 部署失败问题排查
如果一键部署失败,可以通过以下步骤排查:
# 查看部署日志
kubectl logs deployment/deployment-controller -n dify-deployment
# 检查资源状态
kubectl get pods -n dify-namespace
kubectl describe pod [pod-name] -n dify-namespace
# 检查服务连通性
kubectl exec -it [pod-name] -n dify-namespace -- curl -v [service-name]:[port]常见错误及解决方案:
- 数据库连接失败:检查RDS账号密码是否正确,网络安全组是否放通
- Redis连接失败:检查Redis密码配置,网络连通性
- 资源不足:提高CCE节点规格或增加节点数量
- Docker镜像拉取失败:检查网络连接或配置镜像加速器
9.2 性能问题解决
如果系统出现性能问题,可以从以下几个方面排查:
# 性能问题诊断脚本
import psutil
import requests
import time
def diagnose_performance():
# 系统资源使用情况
cpu_percent = psutil.cpu_percent(interval=1)
memory_percent = psutil.virtual_memory().percent
disk_io = psutil.disk_io_counters()
network_io = psutil.net_io_counters()
print(f"CPU使用率: {cpu_percent}%")
print(f"内存使用率: {memory_percent}%")
print(f"磁盘IO: 读取{disk_io.read_bytes/1024/1024}MB, 写入{disk_io.write_bytes/1024/1024}MB")
print(f"网络IO: 接收{network_io.bytes_recv/1024/1024}MB, 发送{network_io.bytes_sent/1024/1024}MB")
# API响应时间测试
api_endpoints = [
"/api/status",
"/api/apps",
"/api/users"
]
print("\nAPI响应时间测试:")
for endpoint in api_endpoints:
start_time = time.time()
response = requests.get(f"https://{ELB_IP}{endpoint}")
end_time = time.time()
print(f"{endpoint}: {(end_time - start_time) * 1000:.2f}ms, 状态码: {response.status_code}")
# 执行诊断
diagnose_performance()常见性能问题及解决方案:
- CPU使用率过高:增加Dify实例数量,启用自动扩缩容
- 内存泄漏:检查应用日志,排查内存泄漏问题,必要时重启服务
- 数据库慢查询:优化SQL,添加适当索引
- 网络延迟高:检查网络配置,考虑使用CDN加速
10. 总结与展望
本文详细介绍了如何利用华为云Flexus X实例一键部署Dify高可用版,包括架构设计、部署步骤、配置优化、监控运维等方面的内容。通过本方案,企业可以快速搭建自己的AI应用开发平台,降低技术门槛,提升开发效率。
随着大语言模型技术的不断发展,Dify平台也在持续迭代更新,未来将支持更多模型、更丰富的功能和更高的可扩展性。华为云Flexus X实例作为底层基础设施,将为Dify平台提供强大的算力支持,为企业AI应用开发保驾护航。
参考资料
希望本文能够帮助您成功部署Dify高可用平台,如有任何问题,欢迎在评论区留言讨论!

















 1203
1203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









