









K近邻算法一般而言有4步:定下K值-->变量标准化-->计算测试样本到每个训练样本的距离-->加权或不加权地进行预测。下面用打高尔夫球的例子做具体计算。数据如下,共14条数据,以第一条数据作为测试样本。其中,temperature表示当天温度,humidity表表示当天湿度,play是要预测的变量,即是否打高尔夫。选择K=3,下面计算距离。

明氏距离:
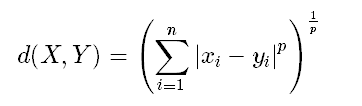
这里为了方便计算,取p=1.那么第一个观测值到第2、第3个训练样本的明氏距离为:
dis1=|85-80|+|85-90|=10,dis2=|85-83|+|85-86|=3。
其他的计算方法相同,可以用R计算出每个训练样本离测试样本的距离:
library(kknn)
golf <- read.csv("golf.csv",header=T)
golf.train <- golf[-1,c(2:3,5)]
golf.test <- golf[1,2:3]
golf.kknn <- kknn(Play~.,golf.train,golf.test,k=3,scale=F,distance=1,kernel= "rectangular")
golf.kknn$CL #邻居的类别
golf.kknn$D #邻居与它的距离
golf.kknn$C #邻居的观测值号kknn函数的参数依次为:formula,训练集,测试集,邻居的个数K,是否标准化(一般标准化,这里先不标准化),明氏距离中的参数p的值(这里设定p=1),加权方法(这里是rectangular,表示等权重,即不加权)。查看kknn选择的3个邻居的类别、距离以及所属的观测值编号:
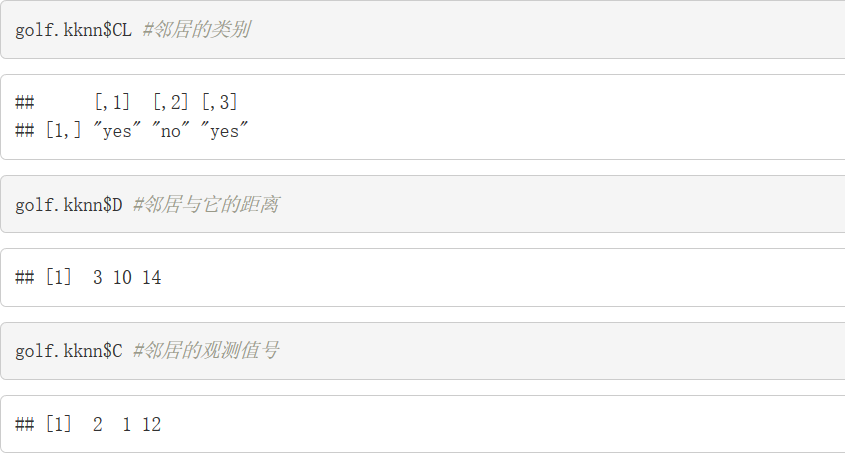
可见,与测试样本距离最近的三个邻居分别是(删去了第一行测试数据了以后的)第2个、第1个和第12个观测值,其与测试样本的明氏距离分别为3,10和14,所属类别分别为yes,no,yes。在不加权时,各个邻居权重相等,那么很显然测试样本的分类应该听邻居中的“大多数”的,即选择yes这一类。如果选择加权呢?
加权的方式有很多种,R中提供的有:Possible choices are "rectangular" (which is standard unweighted knn), "triangular", "epanechnikov" (or beta(2,2)), "biweight" (or beta(3,3)), "triweight" (or beta(4,4)), "cos", "inv", "gaussian", "rank" and "optimal".
这里先用triangular法演示计算过程,三角加权函数的公式为:
其中,为使u处于-1到1之间,需要对u进行调整,R中使用的调整方式为:第i个邻居到测试样本的距离/排在第k+1远的邻居到它的距离,即:
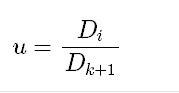
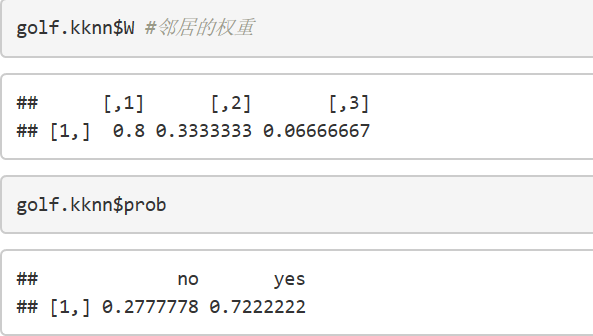
在这里,最近的邻居的u1=3/15=0.2,其中15是计算出的第4远的邻居距测试样本的距离,则K(u1)=1-0.2=0.8,第二远的邻居u2=10/15=0.667,K(u1)=1-0.667=0.333,第三远的邻居u3=14/15=0.933,K(u3)=1-0.933=0.067,因此三者的权重分别为:0.8/(0.8+0.333+0.067)=0.67,0.333/(0.8+0.333+0.067)=0.28,0.067/(0.8+0.333+0.067)=0.05.所以测试样本被归为yes类的概率是0.67+0.05=0.72,而被归为no类的概率为0.28.可以看到,此结果与R的预测结果几乎相同。
golf.kknn <- kknn(Play~.,golf.train,golf.test,k=3,scale=F,distance=1,kernel= "triangular")
golf.kknn$CL #邻居的类别
golf.kknn$W #邻居的权重
golf.kknn$prob #分类结果
此外,R的kknn包中还有可以自动选择最优参数的函数:train.kknn和cv.kknn,前者采用留一交叉验证做参数选择,后者采用交叉验证做参数选择(可以自己选择折数),可以用下面的代码进行:
#取distance=2
golf.tkknn <- train.kknn(Play~.,golf[,c(2:3,5)],kernel = c("rectangular", "triangular", "epanechnikov", "optimal"),distance=2,scale=T)
plot(golf.tkknn)
golf.tkknn$MISCLASS #显示错误率
golf.tkknn #输出最优参数情况golf.tkknn <- train.kknn(Play~.,golf[,c(2:3,5)],kernel = c("rectangular", "triangular", "epanechnikov", "optimal"),distance=1,scale=T)
plot(golf.tkknn)
golf.tkknn$MISCLASS
golf.tkknn
两者选择结果相同,最小错误率均为0.36,最好的加权方法都选择了不加权。
Minimal misclassification: 0.3571429
Best kernel: rectangular
Best k: 9















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









