










相比于一般贝叶斯而言,朴素贝叶斯设定一个naive assumption:Assume that each feature xi is conditionally independent of every feature xj for i is unequal to j, given the category C.
简单一点来说,比如现在要通过颜色、形状、半径来推断一个水果是苹果还是香蕉(当然这里界限比较明显,并不是一个好例子),对于苹果这个类别来说,它的颜色、形状、半径三者是独立的(可以想象,一个大的红苹果和一个小的红苹果出现的可能性是几乎一样的)。但对于所有水果来说,这三个变量并不是独立的。比如,如果一个水果颜色=红色,那么它的形状更可能等于圆形(苹果),而如果颜色=黄色,形状更可能是船型(香蕉)。这就是朴素贝叶斯的前提假设,即:在C的每个类别下,X的各个维度是相互独立的,这种独立需要以类别C作为条件,是一种条件独立。
【案例】
现有各类人群是否会买电脑的例子,数据有14条见下图:

用朴素贝叶斯公式,那些年轻人、收入为中等水平、学生、信用等级为fair的人群会选择买电脑的概率为:
P1=P(buy|youth,medium,student,fair)
=P(buy)*P(youth|buy)*P(medium|buy)*P(student|buy)*P(fair|buy)
各个概率可以由R语言直接算出,使用语句:
library(klaR)
res <- NaiveBayes(buys_computer~., computer)
res得到各个条件概率如下:
grouping no yes 0.3571429 0.6428571 grouping middle-aged senior youth
no 0.0000000 0.4000000 0.6000000
yes 0.4444444 0.3333333 0.2222222
grouping high low medium
no 0.4000000 0.2000000 0.4000000
yes 0.2222222 0.3333333 0.4444444
grouping no yes
no 0.8000000 0.2000000 yes 0.3333333 0.6666667 grouping excellent fair no 0.6000000 0.4000000 yes 0.3333333 0.6666667
使用R给出的数据,P(buy|youth,medium,student,fair)=0.2222*0.4444*0.6667*0.6667*0.6429=0.02822
同理,年轻人&中等收入&是学生&信用评级为fair 的人不买电脑的概率:
P2=P(not_buy|youth,medium,student,fair)=0.6*0.4*0.2*0.4*0.3571=0.00686
另外,如果要求【年轻人&中等收入&是学生&信用评级为fair】这类人出现的概率:
P(youth,medium,student,fair)=P1+P2=0.02822+0.00686=0.0351
【注1】如果直接认为P(youth,medium,student,fair)=P(youth)*P(medium)*P(student)*P(fair),会得出明显不同的结果,那正是因为,朴素贝叶斯只是假设在同一类别下(选择买电脑的人或不买电脑的人)他们的各个属性是相互独立的,而不能直接认为各属性相互独立。
【注2】上面的方法是基于MLE公式,在朴素贝叶斯中还有一种参数估计是基于拉普拉斯方法,公式如下图:
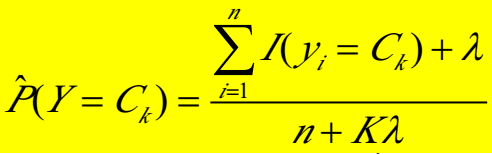
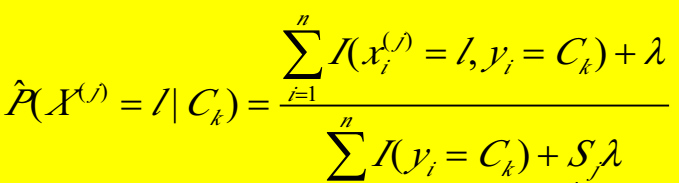
此例如果使用拉普拉斯公式来做参数估计,设置lambda=1:
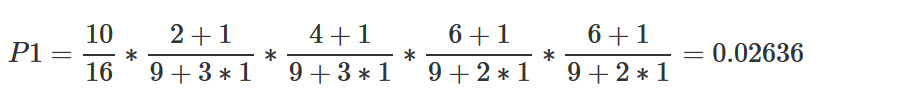
在P(buy)计算中,9是买电脑人的个数,14是观测值个数,2是buy_computer这个变量的类别数(只有yes和no两种)。
在P1的计算中,以P(youth|buy)为例,分子2是买电脑的人中年龄为youth的人的个数,在分母中,9是buy_computer=yes的观测值个数,3是age这个变量自身的别数,这里age有三个类别,所以是K=3.
下面继续在R中完成建模预测,给出混淆矩阵,并计算错判率,代码如下:
res <- NaiveBayes(buys_computer~., computer)
res
pre1 <- predict(res,computer[,-5])
table(computer[,5],pre1$class) #混淆矩阵
error <- sum(as.numeric(as.numeric(pre1$class)!=as.numeric(computer[,5])))/nrow(computer)
error #错判率得到的混淆矩阵为:
no yes
no 4 1
yes 0 9错判率为
:0.0714
。这部分内容较多,part1只写粗浅一点的部分,更多的后面补上~















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









