









酷狗音乐top500榜单链接:http://www.kugou.com/yy/rank/home/1-8888.html
观察每页的url,将第一页url中home/后的1改成2,就恰好是第二页的url。
首先导入相应的库,同时设定好浏览器的header:
import requests
from bs4 import BeautifulSoup
import time
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'
}接下来写获取网页信息的函数,这里需要事先加载lxml包,否则会报错。

我们要爬取的信息有4项:排名、歌手、歌曲名、时长,分别右键每个部分,选择【查看元素】,可以找到它们的源码分别如下:
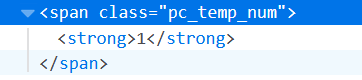
使用soup.select()函数时,括号里是‘标签名.类别名’,比如对于【排名】(ranks)这一项,括号里就应该是'span.pc_temp_num',而如果只写最小的标签的类别名无法爬取时,可以由大标签开始一层一层写到小标签,中间用大于号链接(注意,大于号的前后都要打上空格,否则错误),比如下面的【名称】(titles)这一项,soup.select()函数的括号里就是'div.pc_temp_songlist > ul > li > a',从母标签一层一层写到我们所需要的a标签。
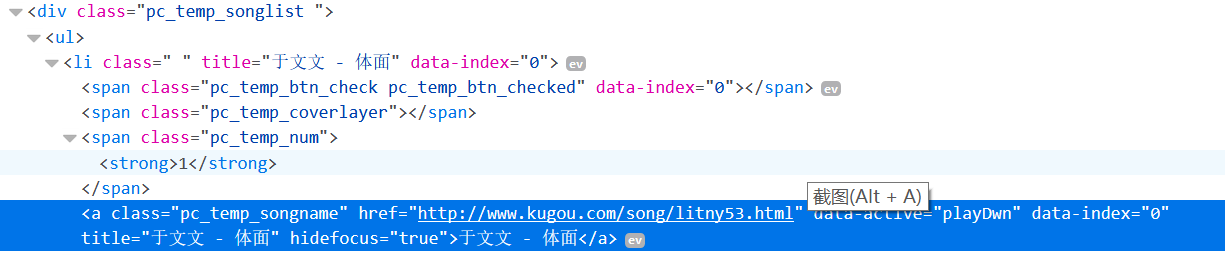
【时长】(times)的写法也是同样的道理,书上是从大的那个span的标签开始写的,我试了一下直接用'span.pc_temp_time'也是可以的。

做好了lxml方法下的网页解析,接下来就用一个循环,来将每一条数据设置成字典的形式:
for rank,title,time in zip(ranks,titles,times):
data={
'rank':rank.get_text().strip(),
'singer':title.get_text().split('-')[0],
'song':title.get_text().split('-')[1],
'time':time.get_text().strip()
}
print(data)
最后一波是构造多页的url,同时对每一页调用之前写的网页解析的函数,对于构造多页url这件事,一句话就能搞定:
urls=['http://www.kugou.com/yy/rank/home/{}-8888.html'.format(str(i)) for i in range(1,24)]综合上面的分析,完整的代码如下:
import requests
from bs4 import BeautifulSoup
import time
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'
}
def get_info(url):
urldata=requests.get(url,headers=headers)
soup=BeautifulSoup(urldata.text,'lxml')
ranks=soup.select('span.pc_temp_num')
titles=soup.select('div.pc_temp_songlist > ul > li > a')
times=soup.select('span.pc_temp_time')
for rank,title,time in zip(ranks,titles,times):
data={
'rank':rank.get_text().strip(),
'singer':title.get_text().split('-')[0],
'song':title.get_text().split('-')[1],
'time':time.get_text().strip()
}
print(data)
if __name__ =='__main__': #程序主入口
urls=['http://www.kugou.com/yy/rank/home/{}-8888.html'.format(str(i)) for i in range(1,24)]
for url in urls:
get_info(url)
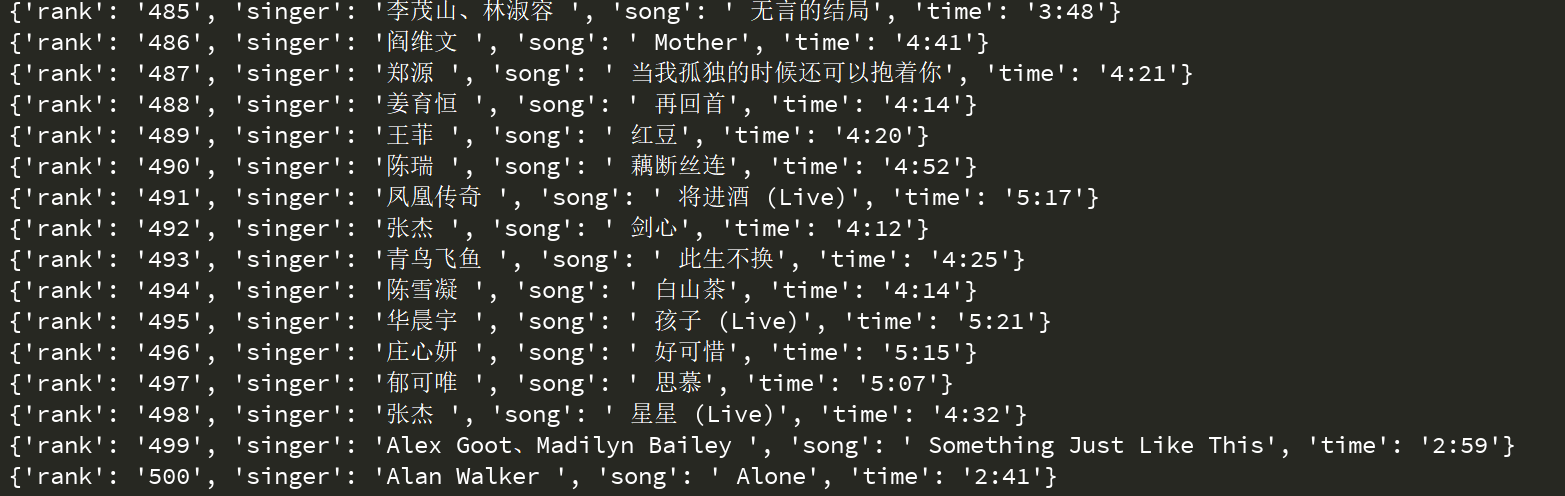
time.sleep(1)好啦~大功告成,得到了五百条数据,就像这样:















 1701
1701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









