







1、 长短期记忆
LSTM 中引入了3个门,即输入门(input gate)、遗忘门(forget gate)和输出门(output gate),以及与隐藏状态形状相同的记忆细胞(某些文献把记忆细胞当成一种特殊的隐藏状态),从而记录额外的信息。
1.1 输入门、遗忘门和输出门
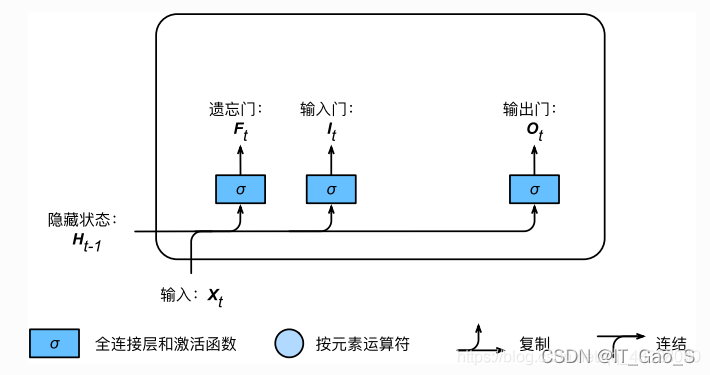
I
t
=
s
i
g
m
o
i
d
(
X
t
W
x
i
+
H
t
−
1
W
h
i
+
b
i
)
I_t=sigmoid(X_tW_{xi}+H_{t-1}W{hi}+b_i)
It=sigmoid(XtWxi+Ht−1Whi+bi)
F
t
=
s
i
g
m
o
i
d
(
X
t
W
x
f
+
H
t
−
1
W
h
f
+
b
f
)
F_t=sigmoid(X_tW_{xf}+H_{t-1}W{hf}+b_f)
Ft=sigmoid(XtWxf+Ht−1Whf+bf)
O
t
=
s
i
g
m
o
i
d
(
X
t
W
x
o
+
H
t
−
1
W
h
o
+
b
o
)
O_t=sigmoid(X_tW_{xo}+H_{t-1}W{ho}+b_o)
Ot=sigmoid(XtWxo+Ht−1Who+bo)
1.2 候选记忆细胞
接下来,长短期记忆需要计算候选记忆细胞
C
t
^
\hat{C_t}
Ct^ 。它的计算与上面介绍的3个门类似,但使用了值域在 [−1,1]的tanh函数作为激活函数

C
t
^
=
t
a
n
h
(
X
t
W
x
c
+
H
t
−
1
W
h
c
+
b
c
)
\hat{C_t}=tanh(X_tW_{xc}+H_{t-1}W_{hc}+b_c)
Ct^=tanh(XtWxc+Ht−1Whc+bc)
1.3 记忆细胞
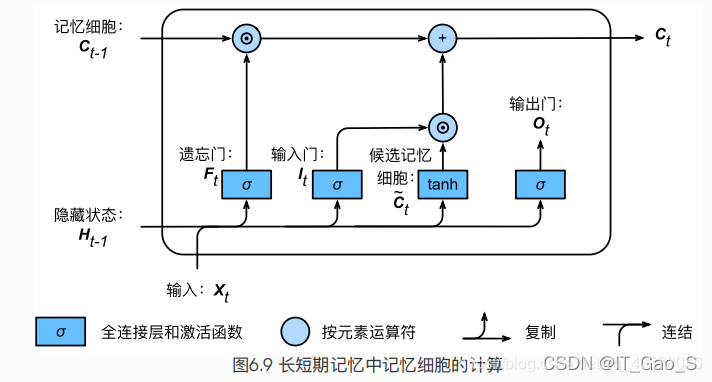
C
t
=
F
t
∗
C
t
−
1
+
I
t
∗
C
t
^
C_t=F_t*C_{t-1}+I_t*\hat{C_t}
Ct=Ft∗Ct−1+It∗Ct^
1.4 隐藏状态
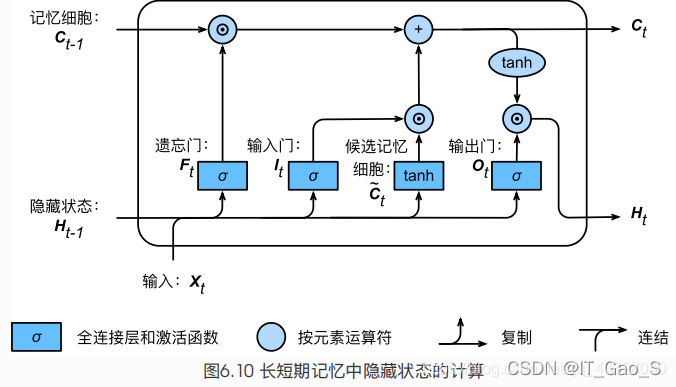
H
t
=
O
t
∗
t
a
n
h
(
C
t
)
H_t=O_t*tanh(C_t)
Ht=Ot∗tanh(Ct)
2、代码定义模型
- 初始化参数
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
print('will use', device)
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32)
return torch.nn.Parameter(ts, requires_grad=True)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
torch.nn.Parameter(torch.zeros(num_hiddens, device=device, dtype=torch.float32), requires_grad=True))
W_xi, W_hi, b_i = _three() # 输入门参数
W_xf, W_hf, b_f = _three() # 遗忘门参数
W_xo, W_ho, b_o = _three() # 输出门参数
W_xc, W_hc, b_c = _three() # 候选记忆细胞参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32), requires_grad=True)
return nn.ParameterList([W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q])
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
- 模型定义
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid(torch.matmul(X, W_xi) + torch.matmul(H, W_hi) + b_i)
F = torch.sigmoid(torch.matmul(X, W_xf) + torch.matmul(H, W_hf) + b_f)
O = torch.sigmoid(torch.matmul(X, W_xo) + torch.matmul(H, W_ho) + b_o)
C_tilda = torch.tanh(torch.matmul(X, W_xc) + torch.matmul(H, W_hc) + b_c)
C = F * C + I * C_tilda
H = O * C.tanh()
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H, C)
















 6648
6648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









