







概述
字符串是多个字符连接起来组合成的字符序列。字符串分为可变的字符串和不可变的字符串两种。
(1)不可变的字符串:当字符串对象创建完毕之后,该对象的内容(上述的字符序列)是不能改变的,一旦内容改变就会创建一个新的字符串对象。Java中的String类的对象就是不可变的。
(2)可变的字符串:StringBuilder 类和 StringBuffer 类的对象就是可变的;当对象创建完毕之后,该对象的内容发生改变时不会创建新的对象,也就是说对象的内容可以发生改变,当对象的内容发生改变时,对象保持不变,还是同一个。

String、StringBuffer、StringBuilder 都实现了 CharSequence 接口,字符串在底层其实就是char[],虽然它们都与字符串相关,但是其处理机制不同。
String 类为什么要设计为不可变的
1)便于实现字符串池(String pool)
2)多线程安全
3)避免安全问题
4)加快字符串处理速度
String 真的不可变吗?
String 类是用 final 关键字修饰的,不可被继承,仅此而已。
我们通过阅读源码知道,字符串是由字符组成,字符存在 value 数组中。
private final char value[];
Value 被 final 修饰,只能保证引用不被改变,但是 value 所指向的堆中的数组,才是真实的数据,只要能够操作堆中的数组,依旧能改变数据。而且 value 是基本类型构成,那么一定是可变的,即使被声明为 private,我们也可以通过反射来改变。所以 String 的不可变性仅仅是正常情况下的不可变,但绝非完全的不可变。
一、String 类(字符串常量)
String 类表示不可变的字符串,当前 String 类对象创建完毕之后,该对象的内容(字符序列)是不变的,因为内容一旦改变就会创建一个一个新的对象。
String 类是 final 类,不可以继承。对 String 类型最好的重用方式是组合而不是继承。
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
}
1、String 类实例的创建
方式一:
通过字面量赋值创建,需要注意这里是双引号:"",区别与字符char类型的单引号:’’;String s1 = "laofu";方式二:
通过构造器创建:new 一个 String 对象的时候如果字符串常量池里边有该字面量那么就不会放,如果字符串常量池没有就会放该字面量到字符串常量池中。String s2 = new String(“laofu”);
两种方式的区别:
1)方式一:String s1 = “456”;
有可能只创建一个String对象,也有可能创建不创建String对象;如果在常量池中已经存在”456”,那么对象s1会直接引用,不会创建新的String对象;否则,会先在常量池先创建常量”456”的内存空间,然后再引用。
2)方式二:String s2 = new String(“456”);
在堆内存中单独开辟出一个内存空间存放“456”对象,使 s2 指向它。如果常量池中没有 “456” 则在字符串常量池中创建该字面量,如果有则不创建。
该种方式会创建 1 个或者 2 个对象:常量池有 “456” 字段是 1 个,常量池没有 “456” 字段则是 2 个。
上图中的常量池:用于存储常量的地方内存区域,位于方法区中。常量池又分为编译常量池和运行常量池两种:
编译常量池:当把字节码加载进 JVM 的时候,其中存储的是字节码的相关信息(如:行号等)。
运行常量池:其中存储的是代码中的常量数据。
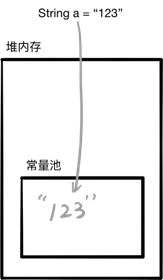

① 使用字符串字面量创建的字符串,也就是单独使用""引号创建的字符串都是直接量,在编译期就会将其存储到常量池中;
② 使用 new String("") 创建的对象会存储到堆内存中,在运行期才创建;
③ 使用只包含直接量的字符串连接符如"aa" + "bb"创建的也是直接量,这样的字符串在编译期就能确定,所以也会存储到常量池中;
④ 使用包含String直接量的字符串表达式(如"aa" + s1)创建的对象是运行期才创建的,对象存储在堆中,因为其底层是创新了StringBuilder对象来实现拼接的;
2、String 对象的比较
① 使用 ”==” 号:用于
比较对象引用的内存地址是否相同
② 使用 equals 方法:在Object类中和”==”号相同,但在自定义类中,建议覆盖equals方法去实现比较自己内容的细节;由于String类覆盖已经覆盖了equals方法,所以其
比较的是字符串内容。
3、String对象的空值
① 对象引用为空, 此时s1没有初始化,也在JVM中没有分配内存空间。
String s1 = null;② 对象内容为空字符串, 比如: 此时对象s2已经初始化,值为“”,JVM已经为其分配内存空间。
String s2 = "";
4、字符串拼接
Java 中的字符串可以通过是 “+” 实现拼接,那么代码中字符串拼接在JVM中又是如何处理的呢?我们通过一个例子说明:通过比较拼接字符串代码编译前后的代码来查看JVM对字符串拼接的处理。

JVM会对字符串拼接做一些优化操作。
① 如果字符串字面量之间的拼接(如"aa" + “bb”),创建的也是直接量,这种情况
在编译期就能确定,所以也会存储到常量池中;
② 如果是对象之间拼接,或者是对象和字面量之间的拼接,亦或是方法执行结果参与拼接,String内部会使用StringBuilder先来获取对象的值,然后使用append方法来执行拼接。这种情况只能在运行期才能确定变量的值和方法的返回值。
二、StringBuilder 与 StringBuffer(字符串变量)
StringBuffer 和 StringBuilder都表示可变的字符串,两种的功能方法都是相同的。但唯一的区别:
1、StringBuffer
StringBuffer中的方法都使用了synchronized修饰符,表示同步操作,在多线程并发的时候可以保证
线程安全,但在保证线程安全的时候,对其性能有一定影响,会降低其性能。
public final class StringBuffer extends AbstractStringBuilder implements java.io.Serializable, CharSequence{
private transient char[] toStringCache;
static final long serialVersionUID = 3388685877147921107L;
}
(1)构造函数
StringBuffer() // 构造一个空的字符串缓冲区,并且初始化为 16 个字符的容量。
StringBuffer(int length) // 创建一个空的字符串缓冲区,并且初始化为指定长度 length 的容量。
StringBuffer(String str) // 创建一个字符串缓冲区,并将其内容初始化为指定的字符串内容 str,字符串缓冲区的初始容量为 16 加上字符串 str 的长度。
(2)常用方法



2、StringBuilder
StringBuilder中的方法都没有使用了synchronized修饰符,
线程不安全,正因为如此,其性能较高。
对并发安全没有很高要求的情况下,建议使用StringBuilder,因为其性能很高。
(1)构造函数

(2)常用方法




三、String、StringBuilder 与 StringBuffer
由于 String 类的操作是产生新的 String 对象,而 StringBuilder 和 StringBuffer 只是一个字符数组的扩容而已,所以 String 类的操作要远慢于 StringBuffer 和 StringBuilder。
大部分情况下:StringBuilder > StringBuffer > String
String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象, 因此在每次对 String类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象。每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,那速度是一定会相当慢的。
而如果是使用 StringBuffer 类则结果就不一样了,每次结果都会对 StringBuffer 对象本身进行操作,而不是生成新的对象,再改变对象引用。
1、使用选择
使用 String 类的场景:
在字符串不经常变化的场景中可以使用 String 类,例如常量的声明、少量的变量运算。
使用 StringBuffer 类的场景:在频繁进行字符串运算(如拼接、替换、删除等),并且运行在多线程环境中,则可以考虑使用 StringBuffer,例如 XML 解析、HTTP 参数解析和封装。
使用 StringBuilder 类的场景:在频繁进行字符串运算(如拼接、替换、和删除等),并且运行在单线程的环境中,则可以考虑使用 StringBuilder,如 SQL 语句的拼装、JSON 封装等。
2、相互转换
(1)String 转换为 StringBuilder、StringBuffer:
public StringBuilder(String s); // 通过构造方法就可以实现把String转换为StringBuilder
public StringBuffer(String s); // 通过构造方法就可以实现把String转换为StringBuffer
(2) StringBuilder、StringBuffer 转换为String:
public String toString() //通过toString()就可以实现把 StringBuilder 、StringBuffer 转换为String。
四、字符串在 JVM 中的存放位置
1、字符串常量池
字符串常量池用于存储编译期间存在的所有字符串实例的引用,以及运行时动态添加的引用。字符串常量池是全局的,只有一个。当我们以 String str = "123"形式创建字符串实例时,首先会去判断字符串常量池中是否有引用指向相同内容的实例,如果有则返回该实例。否则在堆中创建 String 对象并将引用驻留在字符串常量池中。
两个常量池:
(1)Class 文件常量池:存储了字面量以及符号引用1)字面量:文本字符串,例如类中有这样一行代码 private String str = “123”,那么常量池中会出现 str、123、 Ljava/lang/String(类的描述方式:L + 全限定名)等字面量。
2)符号引用:包含 类和接口的全限定名 、字段的简单名称及描述符 、方法的简单名称及描述符;(2)运行时常量池
运行时常量池在 jdk8 ,位于元空间内。用于存储从 class 文件中读取的信息,包括常量池。当类被加载时,虚拟机会将 Class 文件中的静态数据转化为运行时常量池中的运行时数据。至于由常量转化成了什么,以及对常量做了什么操作,下面第六节会进行讲解。运行时常量池对于 Class 文件常量池的重要特征是具有动态性。Java 中的常量不单单能在编译期间产生,也可以在运行期间动态加入。例如 String##intern。
(1)字符串常量池的实现原理
字符串常量池实现的基础是 String 类的不可变性。字符串常量池使用了一个固定长度的哈希表 Hashtable 来存储字符串 (数组 + 链表),在 JDK 8,默认哈希桶容量为 60031。可以通过启动参数 -XX:+PrintStringTableStatistics 查看哈希桶的实际用量。如果数据过多,频繁出现哈希冲突,导致链表过长,降低查询效率。可以通过启动参数 -XX:StringTableSize= 进行调整哈希桶容量。
(2)String 的 intern 方法
当字符串对象调用 intern 方法时,需要判断该字符串内容是否在字符串常量池中 “首次出现”。
1)如果已经有相同内容的字符串实例,则直接返回字符串常量池中这个实例的引用。
2) 如果之前没有相同内容的字符串实例:JDK6:当调用 intern() 方法时,如果字符串常量池先前已创建出该字符串对象,则返回池中的该字符串的引用。否则,将此字符串对象添加到字符串常量池中,并且返回该字符串的引用;
JDK6+:当调用 intern() 方法时,如果字符串常量池先前已创建出该字符串对象,则返回池中的该字符串的引用。否则,如果该字符串对象已经存在于 Java 堆中,则将堆中此对象的引用添加到字符串常量池中,并且返回该引用;如果堆中不存在,则在池中创建该字符串并返回其引用。(跟1.6的区别是常量池不再存放对象,只存放引用。)
2、字符串常量池在 JVM 中的变化
字符串池是运行时常量池。
(1)在 JDK1.6 中,它在方法区中,属于“永久代”。

在JDK1.7及以后,它被移除方法区,放在java堆中。
在JDK1.8中,取消了“永久代”,字符串池仍在堆中。

3、不同 JDK 中 String.intern() 的区别
(1)JDK1.6 及以前
在 JDK 1.6中,字符串常量池位于永久代,字符串对象实例位于堆中,调用 intern() 方法尝试将向字符串常量池添加字符串:
如果字符串常量池中存在相等的字符串,则返回字符串常量池中的字符串地址;如果字符串常量池中没有相等的字符串,则会将字符串的内容复制一份到池中,然后返回池中的字符串地址。

String a = "123";
String m = a.intern();
System.out.println(a == m); //true
String b = new String("456");
String n = b.intern();
System.out.println(b == n); //false
由于两种创建对象的方法都会在常量池中有一份字符串,所以直接返回常量池对象的引用。区别在于,返回的引用地址不同。

String a = new String("1")+new String("2");
String b = a.intern();
System.out.println(a == b); //false
一步一步来分析,首先第一行 String a = new String(“1”)+new String(“2”); 中应分为三步来完成:分别在堆内存和常量池创建 “1” 字符串,分别在堆内存和常量池创建 “2” 字符串,运算加法,在堆内存中创建 “12” 字符串(注意:由StringBuffer 实现,并不会在常量池中创建)。
此时,走到第二步 a.intern(); 根据 JDK1.6 时的流程是在常量池中拷贝一份“12”字符串,然后将字符串返回给b。可以清楚的看到 a 和 b 的引用地址并不一样,所以返回 false。
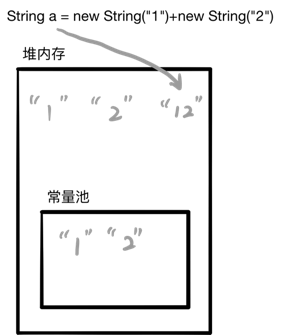
(2)JDK1.7 及以后
从 JDK 1.7 开始,字符串常量池从永久代移动到了Java 堆中,通过 new 新建的字符串对象也位于 Java 堆中,调用 intern() 方法尝试将向字符串常量池添加字符串:
如果字符串常量池中没有相等的字符串,则会将Java堆中字符串的地址复制一份到池中,然后返回池中的字符串的地址,也就是说,此时 intern 方法返回的就是 Java 堆中字符串对象的地址;如果字符串已经在常量池中的话,则返回字符串常量池中的字符串地址,和 JDK1.6 及以前没有任何区别。

String a = "123";
String m = a.intern();
System.out.println(a == m); //true
String b = new String("456");
String n = b.intern();
System.out.println(b == n); //false
当常量池中没有字符串时情况就发生了变化:
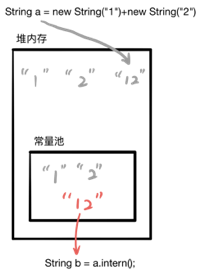
String a = new String("1")+new String("2");
String b = a.intern();
System.out.println(a == b); //true
当执行到 String b = a.intern(); 时就发生了变化:
可以看到,JDK1.6及以前是将堆内存的对象拷贝一份到常量池中,JDK1.6 以后是将此对象的引用放入常量池中。 所以 JDK1.6 以后,实际上 b 指向的是堆内存中的“12”,即和 a 指向是相同的,所以返回 true。
因此,JDK1.6以后的intern()方法可以有效的减少内存的占用,提高运行时的性能。
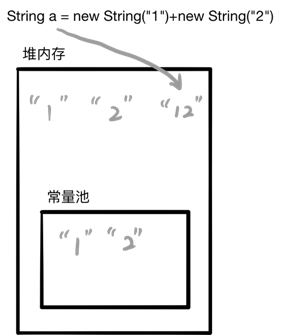

总结
为了避免浪费内存,JDK 1.7 及以后的 String.intern() 和 JDK 1.6的有所差异:
不存在字符串时,不再复制内容,而是直接复制对象的引用(Java堆中对象的地址)。
4、编译期字符串字面量
编译器字面量:在未执行 intern() 方法的情况下,编译期能确定的字符串字面量将自动被放入字符串常量池中。此时,String 引用指向将是字符串常量池中的地址。
注意: 一定得是未执行 intern() 方法的情况下,不然在 JDK 1.7 及以后,String 引用看起来获取的字符串常量池中的地址,但实际指向的是 Java 对中的对象地址。
哪些是编译期能确定的字符串字面量?
(1)
使用双引号括起来的" "的字符串
在这里插入代码片public static void main(String[] args) { String str1 = new String("hello"); // 编译期的字符串字面量hello,将自动放入池中 String str2 = str1.intern(); // intern() 方法时,池中已有相等的字符串 System.out.println("str1 == str2: " + (str1 == str2)); // 返回false }上面的 new String() 其实将创建两个hello 字符串,一个是编译期的字符串字面量,被自动放入字符串常量池中;一个是 new String() 后,在 Java 堆中的创建 String 对象。
(2)
字符串拼接时,只要不是引用和字符串字面量的拼接,最终都可以在编译期确定public static void main(String[] args) { String str1 = new String("hello, " + "world"); // 编译期,拼接出字符串字面量 hello, world System.out.println(str1.intern() == str1); // 返回 false String str3 = new String("test") + "Method"; // 编译期,只能确定 test 和 Method 两个字符串字面量 System.out.println(str3.intern() == str3); // 返回 true }(3)特殊情况:
如果引用指向的是 final 类型(编译期常量),则带引用的字符串拼接在编译期可以确定public static void main(String[] args) { final String string = "hello, "; String str3 = new String(string + "world"); // string为final类型,编译期的值是确定的,等价于 "hello, " + "world"的拼接 System.out.println(str3.intern() == str3); // 返回false }















 1519
1519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









