







环境准备
1.CentOS取消打开文件数限制
sudo vim /etc/security/limits.conf
添加以下内容, 如果已经添加过, 则修改
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
2.CentOS取消SELINUX
sudo vim /etc/sysconfig/selinux
SELINUX=disabled
3.关闭防火墙
如果已经关闭, 跳过该步骤
查看防火墙状态
sudo firewall-cmd --state
关闭防火墙
sudo systemctl stop firewalld
关闭开机自启动(因为防火墙是服务, 所以开启会自启, 需要关闭)
sudo systemctl disable firewalld
Clickhouse单机安装
1.安装依赖的工具
sudo yum -y install yum-utils initscripts
2.1使用yum安装(需要网络)
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
sudo yum -y install clickhouse-server clickhouse-client
2.2使用rmp离线安装(不需要网络)
注意: 使用yum和使用rmp二选一
准备离线安装包
下载地址: https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/
需要下面3个安装包
clickhouse-client-20.4.5.36-2.noarch.rpm
clickhouse-common-static-20.4.5.36-2.x86_64.rpm
clickhouse-server-20.4.5.36-2.noarch.rpm
使用rpm安装
sudo rpm -ivh clickhouse-common-static-20.4.5.36-2.x86_64.rpm
sudo rpm -ivh clickhouse-client-20.4.5.36-2.noarch.rpm
sudo rpm -ivh clickhouse-server-20.4.5.36-2.noarch.rpm
3.修改配置文件
sudo vim /etc/clickhouse-server/config.xml
把注释打开,允许: 来自任何地方的客户端连接当前服务器.(ipv4和ipv6都可以)
<listen_host>::</listen_host>
4.启动Clickhouse
#启动ClickhouseServer
sudo systemctl start clickhouse-server
#启动ClickhouseClient
连接本机服务器的9000端口
clickhouse-client -m
连接远程服务器
clickhouse-client --host=node1 -m
5.退出Clickhouse
node2 :) exit;
6.关闭clickhouse-server开机自启动
sudo systemctl disable clickhouse-server
Clickhouse高可用
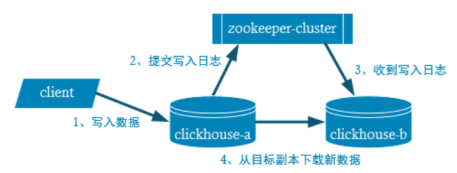
1.副本的目的主要是保障数据的高可用性,即使一台clickhouse节点宕机,那么也可以从其他服务器获得相同的数据。
2.clickhouse的副本严重依赖zookeeper, 用于通知副本server状态变更
3.副本是表级别的,不是整个服务器级的。所以,服务器里可以同时有复本表和非复本表。
1.复本写入流程
2.配置规划
| node1 | node2 | node3 |
|---|---|---|
| zookeeper | zookeeper | zookeeper |
| clickhouse | clickhouse |
3.在node2上安装clickhouse
同上安装步骤一样
4.创建配置文件: metrika.xml
分别在node1和node2创建配置文件metrika.xml, 配置zookeeper地址
sudo vim /etc/clickhouse-server/config.d/metrika.xml
<?xml version="1.0"?>
<yandex>
<zookeeper-servers>
<node index="1">
<host>node1</host>
<port>2181</port>
</node>
<node index="2">
<host>node2</host>
<port>2181</port>
</node>
<node index="3">
<host>node3</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
5.告诉clickhouse 刚刚创建的配置文件的地址,在node1和node2添加如下配置
sudo vim /etc/clickhouse-server/config.xml
找到节点, 在下面添加如下内容

<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
6.在node1和node2上重启clickhouse-server
sudo systemctl restart clickhouse-server
7.分别在node1和node2上建表
clickhouse的复本是表级别的. 有些语句不会自动产生复本, 有些语句会自动产生复本
1)对于 INSERT 和 ALTER 语句操作数据会在压缩的情况下被复制
2)而 CREATE,DROP,ATTACH,DETACH 和 RENAME 语句只会在单个服务器上执行,不会被复制
所以建表的时候, 需要在2个节点上分别手动建表
在node1建表
create table rep_t_order_mt2021 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/01/rep_t_order_mt2021','rep_node1')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
在node2上建表
create table rep_t_order_mt2021 (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/01/rep_t_order_mt2021','rep_node2')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
说明
ReplicatedMergeTree(’/clickhouse/tables/01/rep_t_order_mt2021’,‘rep_node1’)
参数1: 该表在zookeeper中的路径.
/clickhouse/tables/{shard}/{table_name} 通常写法,
shard表示表的分片编号, 一般用01,02,03…表示
table_name 一般和表明保持一致就行
参数2: 在zookeeper中的复本名. 相同的表, 复本名不能相同
在node1上插入数据
insert into rep_t_order_mt2021
values(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 12:00:00'),
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),
(105,'sku_003',600.00,'2020-06-02 12:00:00');
分别在node1和node2查询,都能查询到数据


分片集群(高并发)
1.复本虽然能够提高数据的可用性,降低丢失风险,但是对数据的横向扩容没有解决。每台机子实际上必须容纳全量数据。
2.要解决数据水平切分的问题,需要引入分片的概念。
3.通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上。在通过Distributed表引擎把数据拼接起来一同使用。
4.Distributed表引擎本身不存储数据,有点类似于MyCat之于MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
1.读写原理

2.分片集群规划
规划一个即分片, 有复本的集群.
| node1 | node2 | node3 |
|---|---|---|
| distribute | ||
| shard1 replica1 | shard1 replica2 | shard2 replica1 |
说明:
1.shard1 一共两个复本(node1, node2)
2.shard2 只有一个复本(node3)
3.在node3上安装clickhouse
同上
4.配置分片集群
在node1上, 编辑配置文件:
sudo vim /etc/clickhouse-server/config.d/metrika.xml
<?xml version="1.0"?>
<yandex>
<clickhouse_remote_servers>
<clickhouse_cluster> <!-- 集群名称-->
<shard> <!--集群的第一个分片-->
<internal_replication>true</internal_replication>
<replica> <!-- 该分片的第一个副本 -->
<host>node1</host>
<port>9000</port>
</replica>
<replica> <!-- 该分片的第二个副本-->
<host>node2</host>
<port>9000</port>
</replica>
</shard>
<shard> <!--集群的第二个分片-->
<internal_replication>true</internal_replication>
<replica> <!-- 该分片的第一个副本-->
<host>node3</host>
<port>9000</port>
</replica>
</shard>
</clickhouse_cluster>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>node1</host>
<port>2181</port>
</node>
<node index="2">
<host>node2</host>
<port>2181</port>
</node>
<node index="3">
<host>node3</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!-- 宏: 将来建表的时候, 可以从这里自动读取, 每个机器上的建表语句就可以一样了 相当于变量 -->
<macros>
<shard>01</shard> <!-- 不同机器放的分片索引不一样, node2,node3 -->
<replica>node1</replica> <!-- 不同机器放的副本数不一样, node2,node3需要更改, 以主机命名比较方便-->
</macros>
</yandex>
5.分发这个文件并修改
sudo /home/linux/bin/xsync /etc/clickhouse-server/config.d/metrika.xml
node2上修改配置文件
<!-- 宏: 将来建表的时候, 可以从这里自动读取, 每个机器上的建表语句就可以一样了 相当于变量 -->
<macros>
<shard>01</shard> <!-- 不同机器放的分片索引不一样, node2,node3需要更改 -->
<replica>node2</replica> <!-- 不同机器放的副本数不一样, node2,node3需要更改, 以主机命名比较方便-->
</macros>
node3上修改配置文件
<!-- 宏: 将来建表的时候, 可以从这里自动读取, 每个机器上的建表语句就可以一样了 相当于变量 -->
<macros>
<shard>02</shard> <!-- 不同机器放的分片索引不一样, node2,node3需要更改 -->
<replica>node3</replica> <!-- 不同机器放的副本数不一样, node2,node3需要更改, 以主机命名比较方便-->
</macros>
注意:node3上clickhouse配置文件另外要引用这个文件,同上
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
6.每台机器重启clickhouse-server服务
sudo systemctl restart clickhouse-server
7.在各个节点创建数据库
分别在node1,node2,node3上创建数据库cluster
create database cluster;
use cluster;
8.任意节点创建本地表
选择任意一节点创建本地表, 会自动同步到其他节点
本地表只负责存储自己的切片数据!
create table st_order_mt_gmall on cluster clickhouse_cluster (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/cluster/{shard}/st_order_mt_gmall','{replica}')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
9.创建分布式表st_order_mt_gmall_all
在任意一台机器上创建分布式表,都会自动同步到其他节点,这边在node1创建分布式表
create table st_order_mt_gmall_all on cluster clickhouse_cluster
(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
)engine = Distributed(clickhouse_cluster,cluster,st_order_mt_gmall,hiveHash(sku_id));
10.通过分布式表添加数据
insert into st_order_mt_gmall_all
values(201,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(202,'sku_002',2000.00,'2020-06-01 12:00:00'),
(203,'sku_004',2500.00,'2020-06-01 12:00:00'),
(204,'sku_002',2000.00,'2020-06-01 12:00:00'),
(205,'sku_003',600.00,'2020-06-02 12:00:00');
11.查询数据
通过分布式表查询,可以查询到所有数据!
select * from st_order_mt_gmall_all;

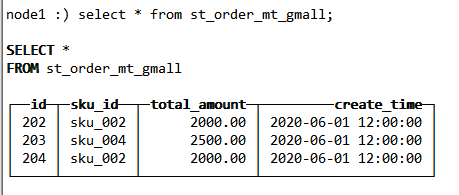
通过本地表查询,只能查到当前节点的分片数据
select * from st_order_mt_gmall;
















 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









