






- 解释性语言(javascript、python)
- 不需要预编译
- 每次使用都要重新解释代码
- python中没有内置常量类型;默认只有变量
- 一般将大写的变量作为常量来用
-
变量命名规则
- 字母、数字、下划线、中文等(做好别用中文)
- 数字不能打头
- 不能使用关键字作为变量名
- 变量中间不能有空格
-
输入输出函数
- input()
- print()
-
注释符号
- #:单行注释
- '''123''':多行注释(三个单引号或者三个双引号)
- 可以起到注释作用
- 也可以代表多行字符串
- a='''zheshishui''' :a的内容为zheshishui(只保留中间的内容;可以用于表示多行字符串)
-
基本数据类型
-
数值类型(Numbers)
- int
- 书写大数时可用_进行分组
- a=15_128_235 ---> a的实际值为15218235
- py版本>=3.6可用
- float
- bool
- long
- complex(复数类型)
- a=1+2j
- int
-
字符串类型
- 字符串以Unicode编码进行存储;字符串中的中英文都表示一个字符
- 字符串中含有引号等特殊符号时需要进行转义处理
- a="zhhfeijfi" 或者 a='jflsjdkfjklds'
- a="zheji\"huoduo\"ushiai"
- 转义符号
-
-
切片序列
- a[2:5] ---->a[2] a[3] a[4]
- a[::2] --->从开头到结尾,步长为2
- a[::-2] --->从结尾到开头;步长为2
- a[:] --->读取整个字符串
- a[::-1] --->逆序读取整个字符串
-
内建函数
- 利用格式
- a.isalnum()
- 判断类型
- isalnum() :字母或数字
- isalpha() : 字母
- isdigit() :数字
- islower() :小写字母
- isupper() :大写字母
- istitle() :标题,每个首字母大写
- isspace() :空格
- isdecimal() :是否十进制字符
- 形式转换
- lower() :小写转换
- upper() :大写转换
- title() :标题格式
- swapcase() :大小写反转
- capitalize() :首字母大写,其他字母小写
- 开头/结尾匹配
- startswith() :以什么字符串开头
- endswith() :以什么字符串结尾
- 冗余删除
- strip() :删除字符串开头和结尾的空格
- lstrip() :删除字符串开头的空格
- rstrip() :删除字符串结尾的空格
- replace(a,b) :用b替换字符串中的a
- 位置调整
- center(width,fillchar) :居中对齐,长度为width,填充内容为fillchar
- ljust(width,fillchar) :左对齐,长度为width
- rjust(width,fillchar) :右对齐,长度为width
- 搜索统计
- find(str,start,end)
- str:要搜索的子字符串
- start:查找开始位置,默认为0
- end:查找的结束位置,默认为字符串长度
- 返回值为匹配到字符串的开始位置;或者-1(没找到)
- index(str,start,end) :返回str出现的位置;没有则报错
- count(str,start,end) :str字符串出现的次数
- find(str,start,end)
- 分离拼接
- split('a') :以a为分隔符切片字符串;默认时空格
- splitlines() :以回车为分隔符对字符串进行分割
- join() :以什么为连接符将多个字符串拼接成一个字符串;
- '+'.join(['ni','hao','123','456']) ------->ni+hao+123+456
- 只能有一个参数
- 参数真能是元素全为字符串类型的list列表
- 利用格式
- format()
- 格式:"{}你是谁呀".format('花椒') ------> 花椒你是谁呀
- {} 相当于替换参数
- 格式控制标记;可组合使用;可选

- 具体示例


- 格式:"{}你是谁呀".format('花椒') ------> 花椒你是谁呀
-
列表(list)
- a=[1,2,3,4]
- a.append('name') :结尾追加单个元素
- a.append([1,2,3]) :结尾追加列表
- a.extend('name') 同上
- a.extend([1,2,3]) :将列表元素加入到a列表中
- a.insert(index,object) :在index位置插入元素
- 删除元素
- del a[0] :删除a[0]元素;通过索引查找
- a.pop() :删除最后一个元素
- a.remove(7) :删除元素7;通过值查找;如果有多个相同值则删除最前面的
- a.clear() :清空a列表中的所有元素
- a[2:5]=[] :通过切片方式删除元素
- a.index(x) :查找元素x的位置
- a.index(x,1,5) :在区间【1,5】内查找元素x的位置
- a.count(x) 统计元素x出现的次数
- a.reverse() :反转列表
- a.sort() :对列表进行排序
-
元组(tuple)
- 不能对元组进行修改
- a=(1,2,3)
- tuple()
- len(a)
- max(a)
- min(a)
- list(reversed(a)) :反转元组,以列表显示
- sum(a,8) :变量内部元素相加+8
- sorted() :变量内部排序
- a.count(1) :统计1出现的次数
- a.index(1) :返回1出现的索引值
-
字典(dict)
- 键值对;{key:value}
- a={'name':'zhangsan','123':'huajie',5:15}
- a.keys() a.values()
- 相关函数
- dict.clear()
- dict.copy()
- dict.fromkeys(seq[,val]) :创造一个新的字典,以seq作为键,val作为值
- dict.get(key,default) :返回指定键的值,如果键不存在则返回default的值
- a.get('ni','hao') :如果键名ni不存在则打印字符串hao;否则打印ni对应的值
- dict.has_key(key) :如果键在dict中返回true,否则返回false
- dict.items() :以列表形式返回可遍历的(键,值)元组数组
- dict.keys() :以列表返回字典中的所有键
- dict.values() :以列表返回字典中的所有值
- dict.setdefault(key,default=None) :使用方法同get(),但是键名不存在时会直接将键名和默认值作为数据添加到字典中
- dict.update(dict2) :把字典dict2中的键值对更新到dict中
- dict.pop(key[,default]) :删除字典中键名为key的数据,如果没有在返回default的值,如果有则返回该键名对应的值
- popitem() :返回并删除字典中的最后一个键值对
-
集合
- 不能对集合元素进行索引;因为集合是无序的
- 集合会自动删除多余的重复元素;集合元素具有唯一性
- 利用{}创建,或者set()函数创建
- 空集合只能用set()函数进行创建;a=set()
- test ={1,2,3}或者test=set('123')
- 集合元素操作
- 添加元素
- 可以添加元组 test.add((1,2,3))
- test.add(123) : 添加单个元素
- update(‘789’,'123') : 可添加多个元素,输入格式必须为字符/字符串形式
- 添加到集合中为:'1' '2' '3' '7' '8' '9'
- 删除元素
- test.remove(‘1’) 如果没有该元素则报错
- test.clear()
- discard(‘2’) 和remove相同;删除指定元素;如果没有该元素不报错
- pop()
- 查询元素
- 差集
- difference()
- a.difference(b)---->a和b的差集:a-b
- 只输出不更新a集合
- difference_update()
- 会把执行后的结果赋值给a;相当于a=a-b
- difference()
- 交集
- intersection()
- intersection_update()
- 并集
- union()
- 对称差分:交集的补集
- symmetric_difference()
- symmetric_difference_update()
- 判断
- isdisjoint() 两个集合是否有相同元素 true 是没有 false是有
- issubset()
- a.issubset(b) a集合元素是否全部在b集合中 true 是 false不是
- issuperset() 判断该方法的函数是否为指定集合的子集
- 差集
- len(test) 返回集合元素个数
- x in test
- x not in test
- 添加元素
-
范围序列
- range(start,end,step)
- start:开始数字,必须有
- end:结束数字,不包含
- step:步长,默认为1,可以为负数
- 无法直接打印;必须借助list();如list(range(1,5,1))
- range(start,end,step)
-
-
运算符
-

-
算术运算符
- + - * / % **(幂运算;指数) //(向下取整)
- 2**3=8
- 5//2=2
- + 可用于字符串的拼接
- a=hello b=world a+b=helloworld
- + - * / % **(幂运算;指数) //(向下取整)
-
赋值运算符
- = ;+=;-=;*=;/=;%=
- a,b,c=1,2,3 同步赋值法
-
关系运算符
- >; >=; <; <=; !=; ==
-
逻辑运算符
- and
- or
- not
-
集合运算符
- & 交集
- | 并集
- - 差集
- ^ 交集的补集
- < <= > >= = 集合比较运算
-
按位运算符
- & 按位与
- | 按位或
- ~ 按位取反
- ~x=-x-1
- ^ 按位异或
- << 左移
- >> 右移
-
成员运算符
- in
- not in
-
身份运算符
- is
- 判断两个变量是否指向同一地址的内容
- id():获取变量的地址()
- -5~256的整数存放地址是相同的
- a=256 b=256 a is b---->true
- a=257 b=257 a is b---->false
- is not
- is
-
-
内置函数
- str() 转化为字符串的函数
- type() 识别变量数据类型的函数
- tuple() 转换为元组的函数
- list() 转换为列表的函数
- int()
- float()
- complex(a,b) a+bj
- bool()
- repr(x) 将x对象转化成供解释器读取的形式 ;即字符串类型
- 感觉就是加了个双引号或单引号;变成字符串了
- eval(str) 将字符串转换为对象并返回表达式的结果
- str='pow(2,3)'
- eval(str) --->8
- abs() 取绝对值
- divmod(5,3)
- (1,2) 商1余2
- pow(2,3) ===8 幂运算
- round() 四舍五入
- hex() 十六进制
- oct() 八进制
- chr(x) 将整数转化为ascii码对应字符
- ord() 获取一个字符的ascii值
- ascii对照表:ASCII码对照表 (oschina.net)
- zip(x,y) 将x,y两个序列一一对应组成一个个元组
- x='123456' y='nihaoxiansheng'
- c=zip(x,y) list(c) ------>[('1', 'n'), ('2', 'i'), ('3', 'h'), ('4', 'a'), ('5', 'o'), ('6', 'x')]
- 遍历:for a,b in c: print(a,b)
- enumerate(a) 和zip()函数效果相似;用数字给a序列添加相对应的下标
- a='nihaoshijie' list(enumerate(a)) ------->[(0, 'n'), (1, 'i'), (2, 'h'), (3, 'a'), (4, 'o'), (5, 's'), (6, 'h'), (7, 'i'), (8, 'j'), (9, 'i'), (10, 'e')]
-
列表推导式
- 返回的是一个列表
- 分为两部分:表达式 + 变量的取值区间
- b = [x**2 for x in range(10) if x%2==0]
- b=x**2
- x in []--->0~10之间的偶数
- for循环
- for 元素in 集合:
- do something
- for 元素in 集合:
- 分支语句 if elif else
- 三目运算符操作
- 结果1 if 条件 else 结果2
- 条件为真则执行结果1;条件为假则执行结果2
- 结果1 if 条件 else 结果2
- 三目运算符操作
-
自定义函数
- def sum(a,b):return a+b
- pass用法 定义空函数:def sum():pass
- 函数基本语法
- def sum(a,b,c):return a+b+c
-
函数种类
- 可变函数
- 函数内部对输入元素修改会影响外部元素的使用
- 传入参数类型为列表、字典、集合
- 不可变函数
- 函数内部对输入元素修改不会影响外部元素的使用
- 传入参数类型为数字、字符串类型、元组
- 可变函数
-
传参类型
- 如 def sum(a,b,c,d=10):return a+b+c+d
- 注意:位置实参必须在关键字实参前面,否则会报错
- 位置实参
- sum(1,2,3,5) :位置对应赋值
- 关键字实参
- sum(1,c=2,b=3,d=5) :
- 默认值实参
- sum(1,2,3) :使用d的默认值
- 任意数量实参(*表示)
- def sum(*info):for i in info:print(i)
- 普通参数必须在任意参数之前
- def sum(name,*info)
- 任意数量关键字实参(**表示)
- def sum(**info):for i in info:print("{}>>{}".format(i,info.get(i)))
- 当*参数和**参数共有时,*参数必须放在前面;否则会报错
- def sum(*key,**info)
-
匿名函数
- filter 和 map类型的数据只能用一次;取出后就不存在了
- lambda x:x+1
- filter(lambda x:x%3==0,range(0,21)) :过滤函数
- map(lambda i:i*2+1, range(0,12)) :映射函数
- reduce(lambda x,y:x+y,range(0,12)) :递归函数
- 每次执行后把执行结果替换输入的值;相当于集合中每次减少一个数,直到最后只剩下一个数
- 相当于x=x+y;y重新从区间中取值
-
模块
- 独立的py文件
- 引入模块
- from 模块名 import *
- 引入模块中的所有函数;通过模块名.函数名进行调用,.如db.sum()
- import 模块名
- from 模块名 import 函数名1,函数名2.。。。
- from 模块名 import 函数名 as 函数别名
- import 模块名 as 模块别名
- from 模块名 import *
-
类
- 基本语法
- 所有类内函数在创建的时候必须带有self参数;要不然会报错

- 所有类内函数在创建的时候必须带有self参数;要不然会报错
- __age
- 私有成员;通过开头双下划线识别
- height
- 共有成员
- __lean()
- 私有函数;通过__识别
- __init__
- 特殊函数;固定好的;通过__1__识别
- 继承
- class Monitor(Student):
- 多继承
- class Monitor(Srudent,Person)
- 多继承调用构造函数时可用super()
- 通过类对象调用 Person.__init__(参数) :简单,但是多继承时会出现始祖类多次调用的情况

- super().__init__(需要用到的参数) :最好用可变长度类型传参,要不然容易报错;始祖类只会调用一次
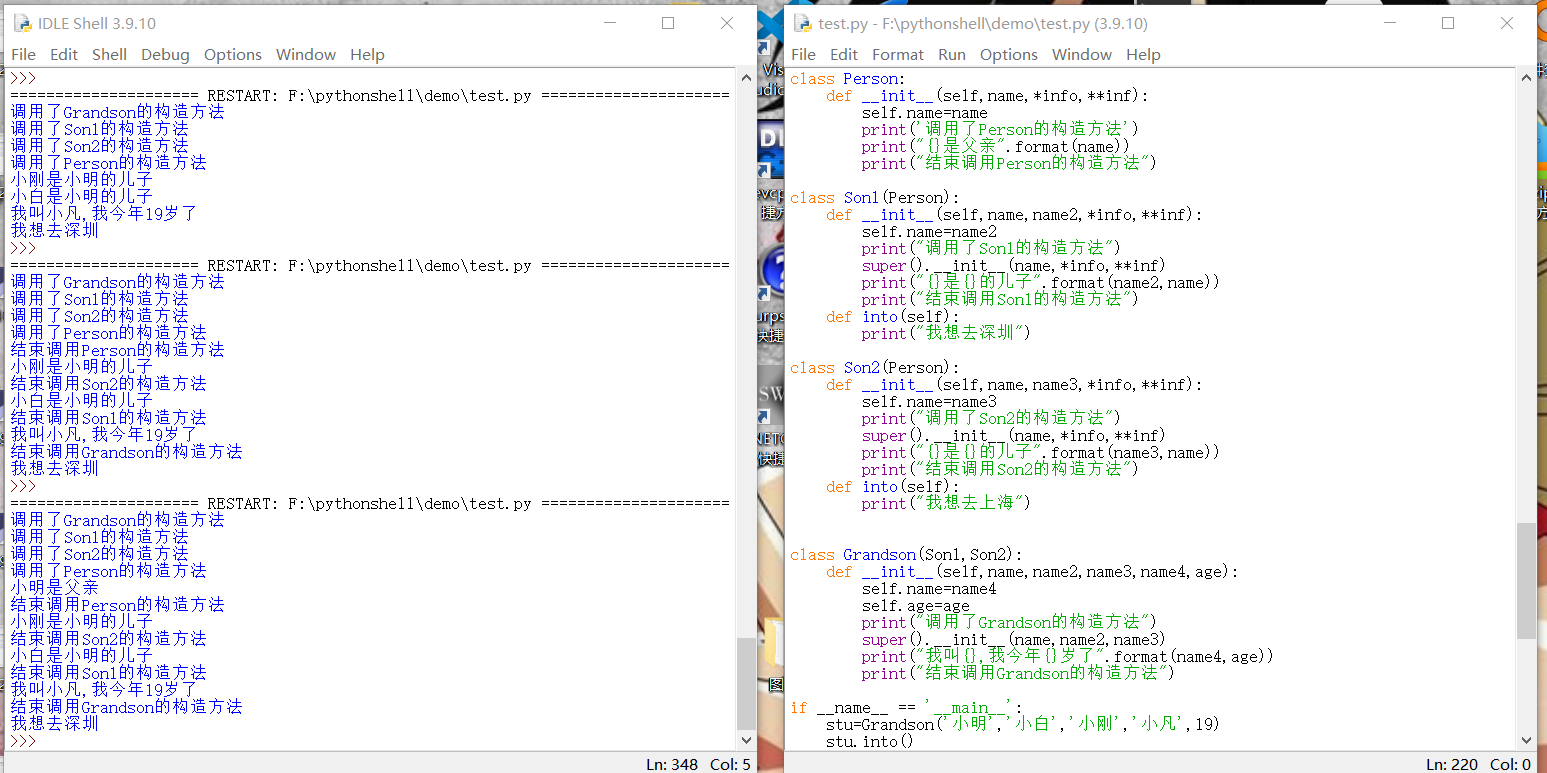
- 通过类对象调用 Person.__init__(参数) :简单,但是多继承时会出现始祖类多次调用的情况
- 调用私有函数的方法
- 通过在类中创建一个共有方法;如图中的learnpython()
- 通过object._类名__私有函数
- stu._Student__lean()
- stu._Monitor__lean()
- 返回值均为Bool类型
- issubclass(A,B)
- 判断A是否是B的子类
- isinstance(A,B)
- 判断A对象是否是B类的实例
- hasattr(object,name)
- 检测一个对象中是否包含给定的变量(属性):hasattr(stu1,'age')
- 属性包括变量和函数
- issubclass(A,B)
- getattr(object,name,error)
- 获取对象的属性值;没有的话返回error的内容,有的话返回对应的值
- getattr(stu1,'age','没有')------>有则返回age的值;没有则返回 ’没有‘
- 基本语法

10















 2785
2785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











