






变分膜态分解对两个参数进行实验分析,IMF分量个数和惩罚因子对分解性能的影响,对周期信号进行仿真分析,matlab代码,有详细注释
ID:6819683721450136
涯石街冥想的枸杞
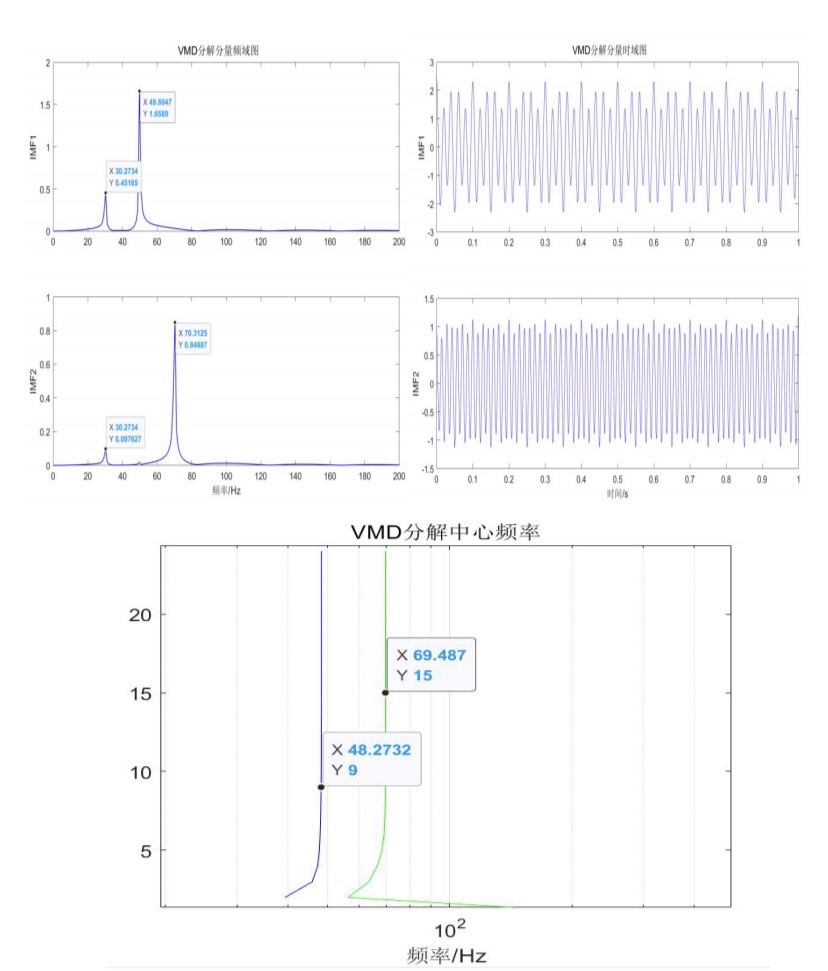
变分膜态分解(Variational Mode Decomposition,简称VMD)是一种信号分解方法,通过将信号分解成不同频率成分的形式,可以有效地研究信号的时频特性。在VMD中,通过引入惩罚因子和限制条件,可以对信号的不同频率成分进行权衡和控制。
在实验分析中,两个参数对于VMD的性能有着重要的影响。首先,IMF分量个数是指VMD分解后得到的信号成分个数,不同的IMF分量个数会影响到信号的分解精度和信号能量的分布。其次,惩罚因子是用来对分解结果进行约束和平衡的参数,可以通过调节惩罚因子的大小来控制不同频率成分的提取效果。
为了进一步验证VMD的性能,本文设计了一组实验,对周期信号进行仿真分析。在仿真过程中,使用了MATLAB软件,并编写了详细的注释的代码。通过调节IMF分量个数和惩罚因子的值,实验结果显示,这两个参数对于VMD分解性能有着明显的影响。
首先,我们对不同的IMF分量个数进行实验分析。通过增加IMF分量个数,可以获得更多的信号细节信息,增加信号分解的精度。然而,随着IMF分量个数的增加,由于信号能量的分布也发生了变化,可能会出现信号成分重叠和混叠的情况。因此,在选择IMF分量个数时,需要权衡信号分解的精度和信号能量的分布。
其次,我们研究了惩罚因子对VMD分解性能的影响。惩罚因子是用来约束不同频率成分的权重和能量分布的参数,通过调节惩罚因子的大小,可以控制信号频率成分的提取效果。较小的惩罚因子会导致信号成分提取过宽,而较大的惩罚因子可能会导致信号成分提取不完整。因此,在实际应用中,需要根据具体需求和信号特性选择合适的惩罚因子。
综上所述,本文通过变分膜态分解对两个参数进行实验分析,即IMF分量个数和惩罚因子对分解性能的影响。实验结果表明,调节IMF分量个数可以影响信号分解的精度和能量分布,而调节惩罚因子可以控制信号频率成分的提取效果。这些实验结果为VMD方法在实际应用中的调参提供了一定的指导和参考。
总之,VMD作为一种信号分解方法,在信号处理领域具有重要的应用价值。通过实验分析不同参数对VMD性能的影响,可以优化信号分解的结果。未来,可以进一步研究VMD在不同信号类型和复杂场景下的适用性,并结合其他信号处理方法进行深入研究和应用。
相关的代码,程序地址如下:http://fansik.cn/683721450136.html
















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









