








遥感代码星球的第002篇代码分享
今天给大家分享的是:
Theil-Sen Median趋势分析
+
Mann-Kendall显著性检验
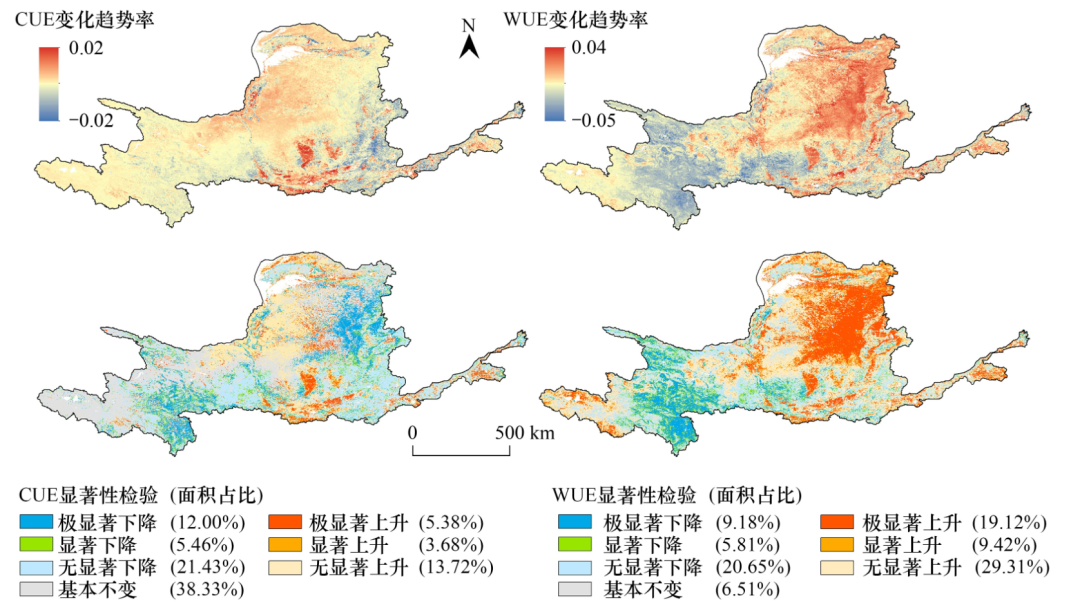
基于遥感数据的植被碳水利用效率时空变化和归因分析[J].生态学报,2024,44(01):377-391.DOI:10.20103/j.stxb.202207232112.
在研究气候变化、环境变化、生态变化等领域时,如何准确分析时间序列数据的趋势是一个重要的课题。Theil-Sen Median趋势分析(简称Sen分析)和Mann-Kendall显著性检验(简称MK检验)是两种常用的非参数方法,它们在处理气候、环境、生态等领域的趋势分析中有着广泛的应用。本文将详细介绍这两种方法的基本原理,并探讨它们如何结合使用以提高趋势分析的准确性。同时结尾附完整代码及案例数据供大家学习使用。
01 原理及公式
1. Theil-Sen Median 趋势分析(Sen分析)
Theil-Sen Median 趋势分析是一种稳健的非参数统计方法,适用于具有异常值或缺失值的时间序列数据。该方法通过计算数据的中位数斜率(即Sen斜率)来评估时间序列的趋势。不同于传统的最小二乘法,Sen分析通过中位数的方式计算斜率,使其对异常值和极端值不敏感,从而能够更稳健地捕捉数据中的长期趋势。
具体的计算方法为(本文以ET为例):
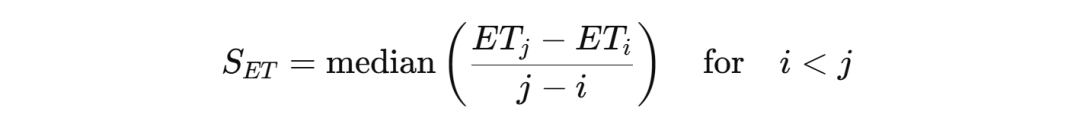
其中,ETi和ETj分别为时间序列中不同时间点的数据值Sen为中位数斜率。
若Sen>0,则表示数据存在上升趋势;若Sen<0,则表示数据存在下降趋势。
2. Mann-Kendall 显著性检验(MK检验)
Mann-Kendall检验是一种用于检测时间序列趋势的非参数统计方法。与Sen分析不同,MK检验的目的是判断时间序列的趋势是否显著,它不要求数据服从任何特定的分布。MK检验通过对时间序列中每对数据点进行比较,计算出趋势的符号,并利用统计量评估数据的趋势方向和显著性。
MK检验的基本步骤如下:
-
对时间序列中所有的每对数据点进行比较,得到每对数据的符号(升序为1,降序为-1,相等为0);
-
计算符号函数的累加和,得到统计量S:
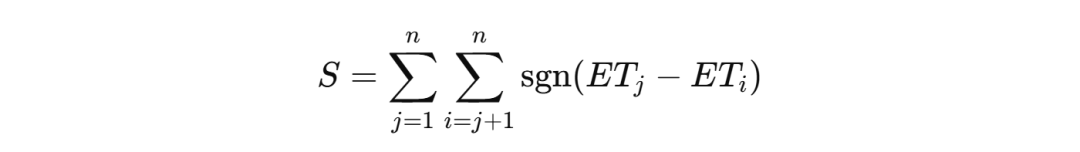
其中,sgn(ETj−ETi)为符号函数。
-
MK检验的检验统计量S反映了时间序列的总体趋势。根据S值的大小及其方差,可以进一步计算出Z值,用于判断ET变化的显著性。计算S的方差,进一步得到Z值,用于判断趋势的显著性:
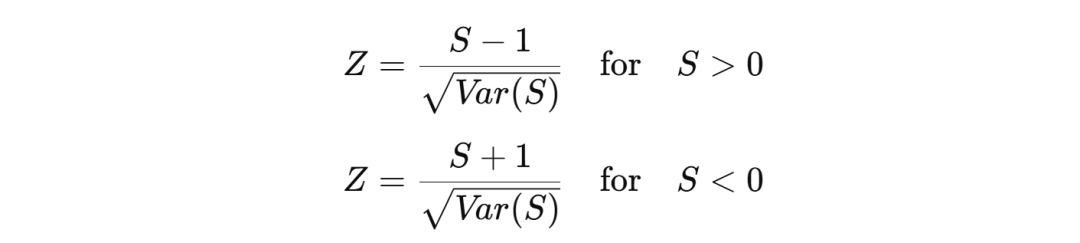
Z值越大,表示趋势越显著。
3. MK显著性检验结果的划分
在进行MK检验时,Z值的大小决定了趋势的显著性水平。在常见的0.05置信水平下,MK检验的显著性结果可以通过Z值来判断:
-
显著变化: 上升趋势(Z>1.96)或下降趋势(Z<−1.96)
-
不显著变化:(−1.96≤Z≤1.96)
4. Sen+MK方法的优势与应用
-
稳健性强:Sen分析能够有效处理含有异常值或缺失值的时间序列数据,适用于多种复杂环境下的数据分析。
-
显著性检验:MK检验能够评估趋势的显著性,确保得到的趋势结果是有统计学意义的。
-
适用范围广泛:Sen+MK方法在气候变化、环境监测、生态变化等领域中广泛应用,尤其适用于无法满足正态分布假设的时间序列数据。
02 代码复现
1. 代码可实现:
✅逐像元栅格进度可视化
✅只需要改动标注有✏️的位置
✅可1比1复刻
2. 文件夹结构:

3.具体代码:
import os
import rasterio
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
from pathlib import Path
# 获取当前工作目录
base_path = os.getcwd()
# 定义数据和结果路径
data_path = os.path.join(base_path, 'data') # ✏️
result_path = os.path.join(base_path, 'results') # ✏️
# 创建结果目录(如果不存在)
os.makedirs(result_path, exist_ok=True)
# 定义年份范围
start_year = 2000 # ✏️
end_year = 2020 # ✏️
cd = end_year - start_year + 1 # 时间跨度
try:
# 读取第一个栅格文件以获取元数据和尺寸信息
first_file = os.path.join(data_path, f'{start_year}.tif')
with rasterio.open(first_file) as src:
a = src.read(1) # 读取栅格数据
transform = src.transform # 栅格的空间转换信息
metadata = src.meta.copy() # 获取元数据,包括GeoTIFFTags
# 修复:更新元数据中的数据类型为float32,解决dtype不匹配问题
metadata.update({
'dtype': 'float32',
'nodata': np.nan # 设置空值为NaN
})
# 获取栅格尺寸
m, n = a.shape
print(f"栅格尺寸: {m} x {n}")
# 创建空数组来存储所有年份的数据
# 使用三维数组以避免展平和重塑操作
all_data = np.full((m, n, cd), np.nan)
# 加载每一年的数据
print("正在加载每一年的栅格数据...")
for i, year in enumerate(tqdm(range(start_year, end_year + 1), desc="加载年度数据")):
filename = os.path.join(data_path, f'{year}.tif')
with rasterio.open(filename) as src:
all_data[:, :, i] = src.read(1)
# 创建结果数组
sen_result = np.full((m, n), np.nan)
# 使用Sen's Slope方法计算趋势
# 这是计算最耗时的部分,使用tqdm显示进度
print("正在计算Sen's Slope趋势...")
valid_pixels = 0
# 优化:仅处理有效像素(至少有一个非空值的像素)
valid_mask = np.any(all_data > 0, axis=2)
total_valid = np.sum(valid_mask)
for i in tqdm(range(m), desc="计算Sen's Slope"):
for j in range(n):
if valid_mask[i, j]:
data = all_data[i, j, :]
if np.all(~np.isnan(data)) and np.min(data) > 0: # 检查数据是否包含有效值
slopes = []
for k1 in range(1, cd):
for k2 in range(k1):
# 计算变化率
slope = (data[k1] - data[k2]) / (k1 - k2)
slopes.append(slope)
# 取中位数作为最终斜率值
if slopes: # 确保slopes不为空
sen_result[i, j] = np.median(slopes)
valid_pixels += 1
print(f"有效像素数: {valid_pixels}/{total_valid} (共{m*n}像素)")
# 设置输出路径并将Sen's Slope结果保存为GeoTIFF
sen_output_path = os.path.join(result_path, '基于sen的ET变化趋势.tif') # ✏️
# 确保结果为float32类型
sen_result = sen_result.astype('float32')
# 保存Sen's Slope结果
with rasterio.open(sen_output_path, 'w', **metadata) as dst:
dst.write(sen_result, 1)
print('Sen\'s Slope处理完成! 结果已保存至:', sen_output_path)
# 计算Mann-Kendall检验
print("正在计算Mann-Kendall检验...")
mk_result = np.full((m, n), np.nan)
for i in tqdm(range(m), desc="计算Mann-Kendall检验"):
for j in range(n):
if valid_mask[i, j]:
data = all_data[i, j, :]
if np.all(~np.isnan(data)) and np.min(data) > 0: # 检查数据是否包含有效值
sgnsum = []
for k1 in range(1, cd):
for k2 in range(k1):
# 计算符号差异
sgn = np.sign(data[k1] - data[k2])
sgnsum.append(sgn)
# 计算符号差异的总和
mk_result[i, j] = np.sum(sgnsum)
# 计算Z值
print("正在计算Z值...")
vars_mk = cd * (cd - 1) * (2 * cd + 5) / 18
z_scores = np.full((m, n), np.nan)
# 处理不同情况的Z值计算
z_scores[~np.isnan(mk_result) & (mk_result == 0)] = 0
z_scores[~np.isnan(mk_result) & (mk_result > 0)] = (mk_result[~np.isnan(mk_result) & (mk_result > 0)] - 1) / np.sqrt(vars_mk)
z_scores[~np.isnan(mk_result) & (mk_result < 0)] = (mk_result[~np.isnan(mk_result) & (mk_result < 0)] + 1) / np.sqrt(vars_mk)
# 保存Mann-Kendall检验结果
mk_output_path = os.path.join(result_path, 'MK检验结果.tif') # ✏️
z_scores = z_scores.astype('float32')
with rasterio.open(mk_output_path, 'w', **metadata) as dst:
dst.write(z_scores, 1)
print('Mann-Kendall检验处理完成! 结果已保存至:', mk_output_path)
# 对Sen's slope和MK检验结果进行重分类
print("正在进行重分类...")
# 创建重分类结果数组
S2 = np.full((m, n), np.nan)
M2 = np.full((m, n), np.nan)
# 重分类Sen's slope结果
S2[np.isnan(sen_result)] = -9999
S2[~np.isnan(sen_result) & (sen_result <= -0.0005)] = -1
S2[~np.isnan(sen_result) & (sen_result >= 0.0005)] = 1
S2[~np.isnan(sen_result) & (sen_result > -0.0005) & (sen_result < 0.0005)] = 0
# 重分类MK检验结果
M2[z_scores > 1.96] = 2
M2[~np.isnan(z_scores) & (z_scores <= 1.96)] = 1
# 计算最终重分类结果
reclassify = (S2 * M2).astype(np.int16)
# 设置输出路径并将重分类结果保存为GeoTIFF
reclass_output_path = os.path.join(result_path, '重分类结果.tif') # ✏️
# 更新元数据中的数据类型为int16
metadata.update({
'dtype': 'int16',
'nodata': -9999
})
# 保存重分类结果
with rasterio.open(reclass_output_path, 'w', **metadata) as dst:
dst.write(reclassify, 1)
print('重分类处理完成! 结果已保存至:', reclass_output_path)
except Exception as e:
print(f"处理过程中发生错误: {str(e)}") 4. 可视化进度
5.输出结果
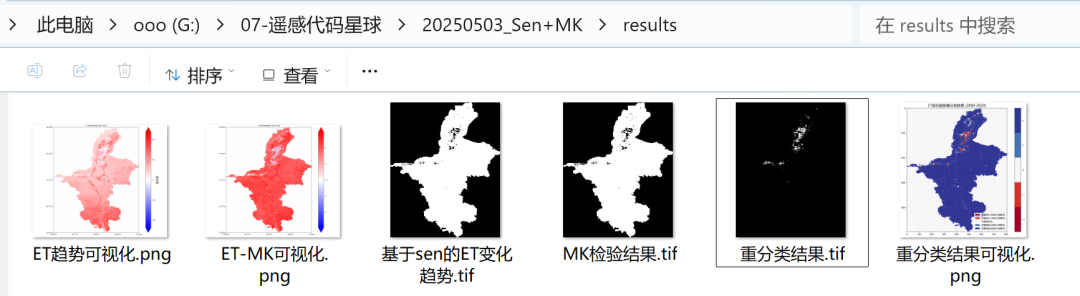
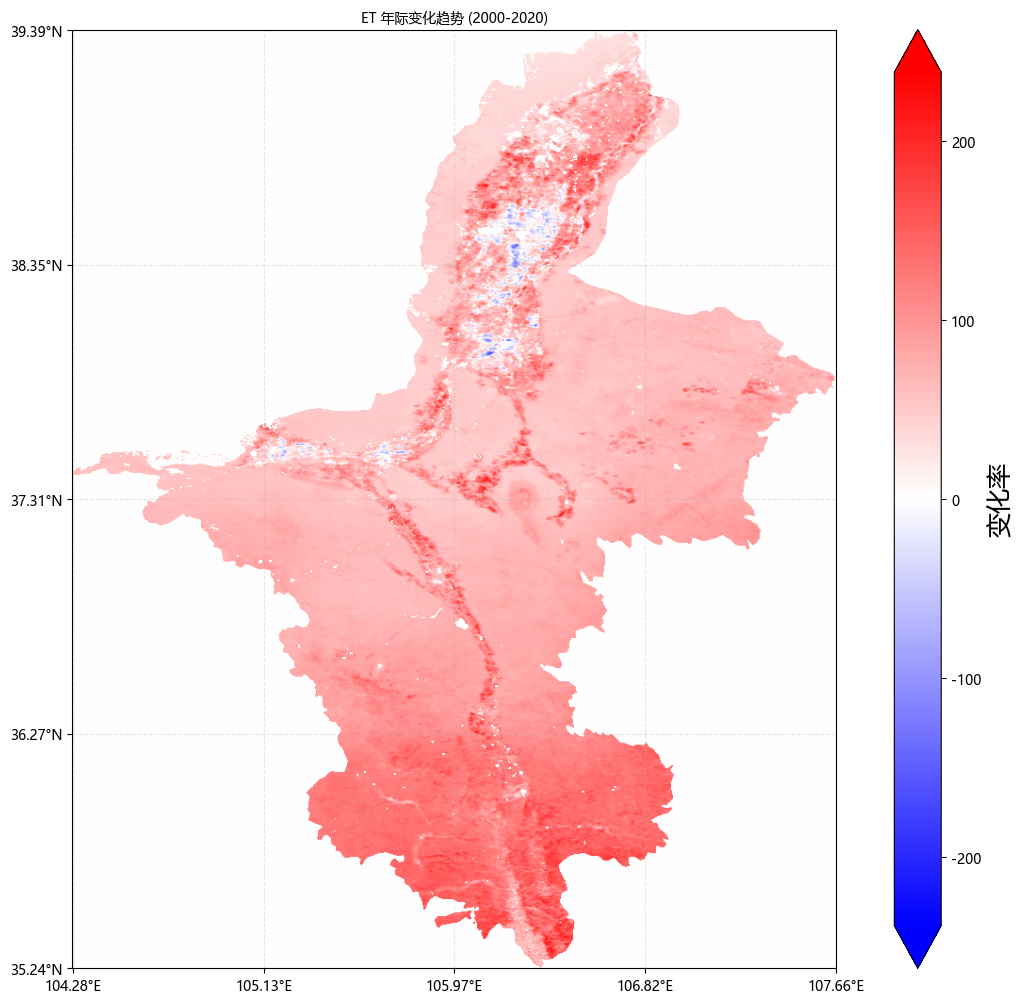
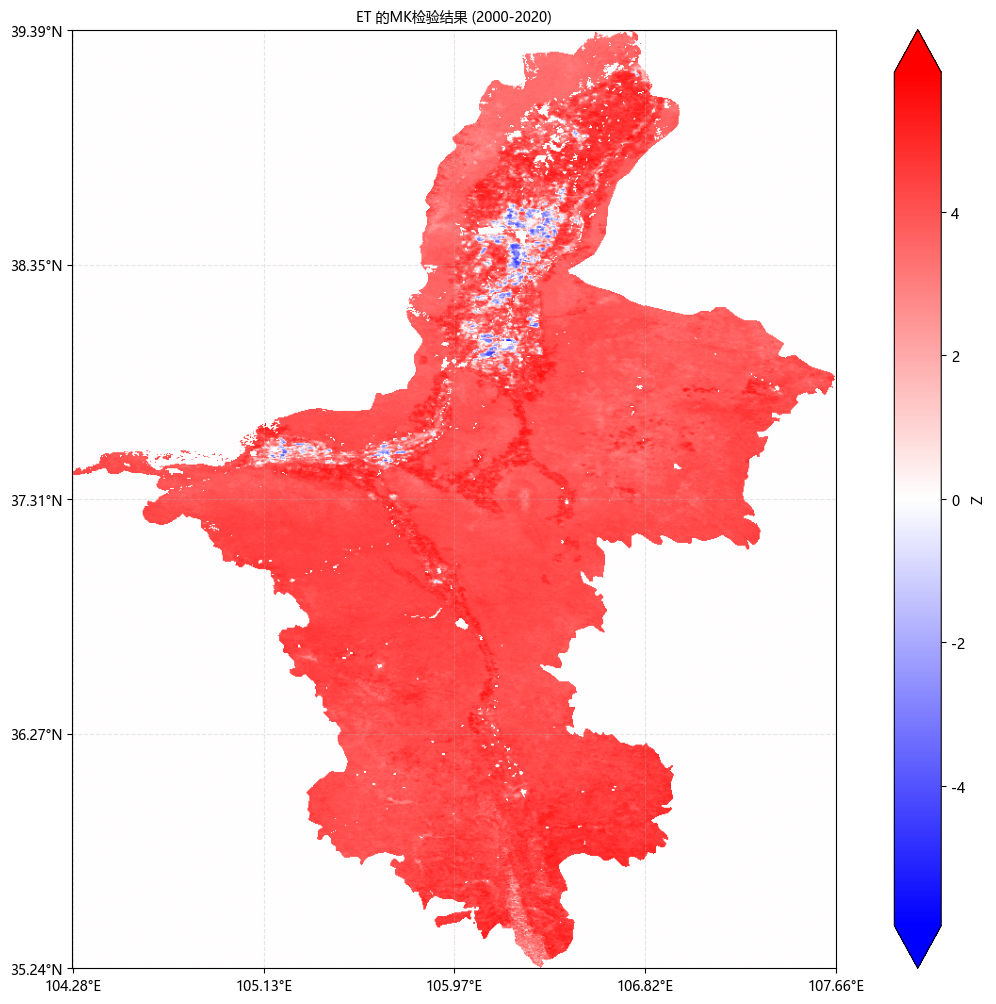
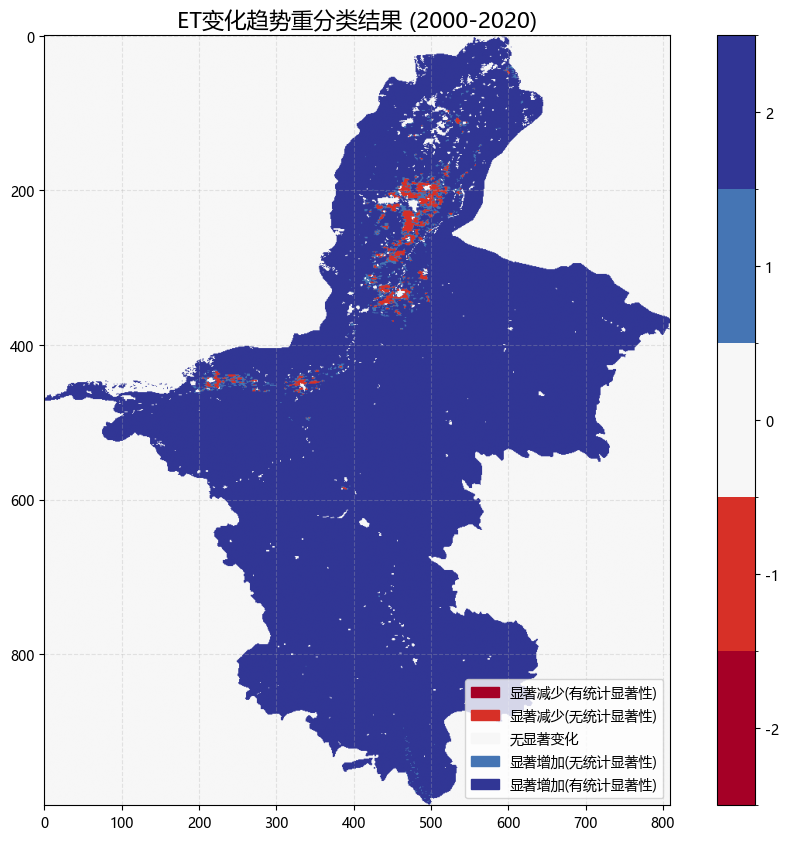
6. 本文示例数据:
MOD16A2H 2000-2020年宁夏部分
本文可视化部分的代码以 Jupyter Notebook的
.ipynb文件展现
你也可以将其中内容复制到新的.py文件中
本人代码能力有限
欢迎同学们指出错误或优化意见
我们一起成长进步
❤
关注遥感代码星球
~评论区回复 C002 获取代码及示例数据链接~

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









