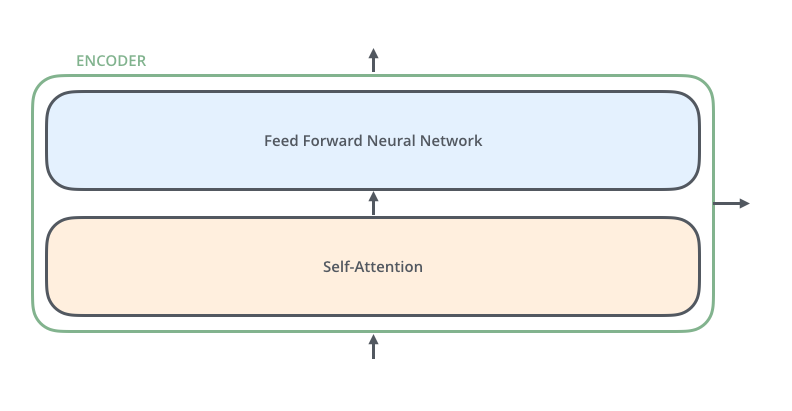
1、模型架构 大部分序列到序列(seq2seq)模型都使用编码器-解码器结构 (引用)。编码器把一个输入序列(𝑥1,...𝑥𝑛)(x1,...xn)映射到一个连续的表示𝑧=(𝑧1,...𝑧𝑛)z=(z1,...zn)中。解码器对z中的每个元素,生成输出序列(𝑦1,...𝑦𝑚)(y1,...ym)。解码器一个时间步生成一个输出。在每一步中,模型都是自回归的(引用),在生成下一个结果时,会将先前生成的结果加入输入序列来一起预测。 2、结构细节 2.1 Encoder 编码器的每层encoder包含Self Attention 子层和FFNN子层,每个子层都使用


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1358
1358















