







导读:在日常生活中,我们经常会遇见线上/线下商家推出各类打折、满减、赠品、新人价、优惠券、捆绑销售等促销活动。一次成功的促销对于消费者和商家来说是双赢的。一方面,促销活动能让消费者买到低价的商品;另一方面,促销活动也能为商家带来可观的利润。因此,对于商家来说,如何科学合理地制定促销策略是必须仔细思考的问题。
作者2:向杜兵,算法专家,某制造业龙头
大家好!我们是IndustryOR团队,致力于分享业界落地的OR+AI技术。欢迎关注微信公众号/知乎【运筹匠心】 。本期我们来谈一谈《促销定价背后的算法技术》。促销活动五花八门、玩法多变,但其底层的核心商业逻辑是“价格”。因此,本期案例将选择某零售商超“促销定价”场景,共分5篇文章依次讲解:(1)业务问题拆解;(2)数据预处理生成;(3)数据挖掘分析;(4)模型算法实现-价格弹性模型;(5)模型算法实现-运筹决策模型。
本篇文章讲解(2)数据预处理生成。
共分为5个部分,依次为:
01 数据探查
02 数据清洗
03 数据聚合
04 数据补全
05 小结
注:本案例数据改编自【2019年全国大学生数学建模E题】公开数据集。
01 数据探查
本案例主要用到销售流水表1/2(附件1/2)和商品信息表(附件4),表结构如下:
- 销售流水表
| 字段 | 含义 |
|---|---|
| order_id | 订单ID |
| is_finished | 订单是否完成 |
| sku_id | 商品ID |
| sku_name | 商品名称 |
| sku_prc | 门店价 |
| sku_sale_prc | 销售价 |
| sku_cost_prc | 成本价 |
| sku_cnt | 销售数量 |
| upc_code | UPC码 |
| create_dt | 创建时间 |
- 商品信息表
| 字段 | 含义 |
|---|---|
| skuid | sku名称 |
| skuname | sku名称 |
| first_category_id | 一级类目id |
| second_category_id | 二级类目id |
| third_category_id | 三级类目id |
| first_category_name | 一级类目名称 |
| second_category_name | 二级类目名称 |
| third_category_name | 三级类目名称 |
1)数据加载
# 读取订单明细表、sku明细表
order_detail_df1 = pd.read_csv('附件1.txt', sep=',', encoding='utf8')
order_detail_df2 = pd.read_csv('附件2.txt', sep=',', encoding='utf8')
sku_detail_df = pd.read_csv('附件4.txt', sep=',', encoding='utf8')
注:原数据文件是excel,笔者将其转成的txt,同学在复现时需要注意一下这里
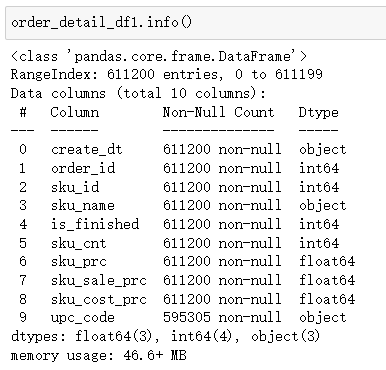
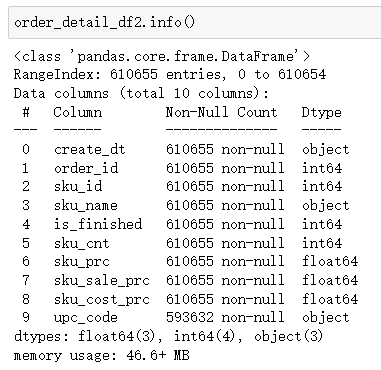
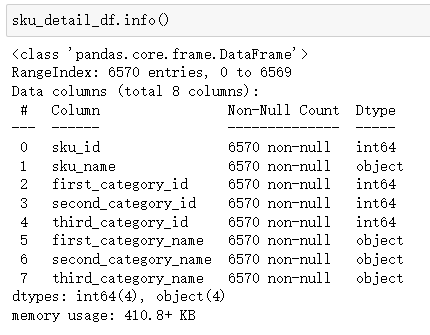
2)数据概览
< ,
, ,
, >
>
我们发现:销售流水表upc_code字段部分缺失,其他字段不缺失。商品信息表无缺失字段。
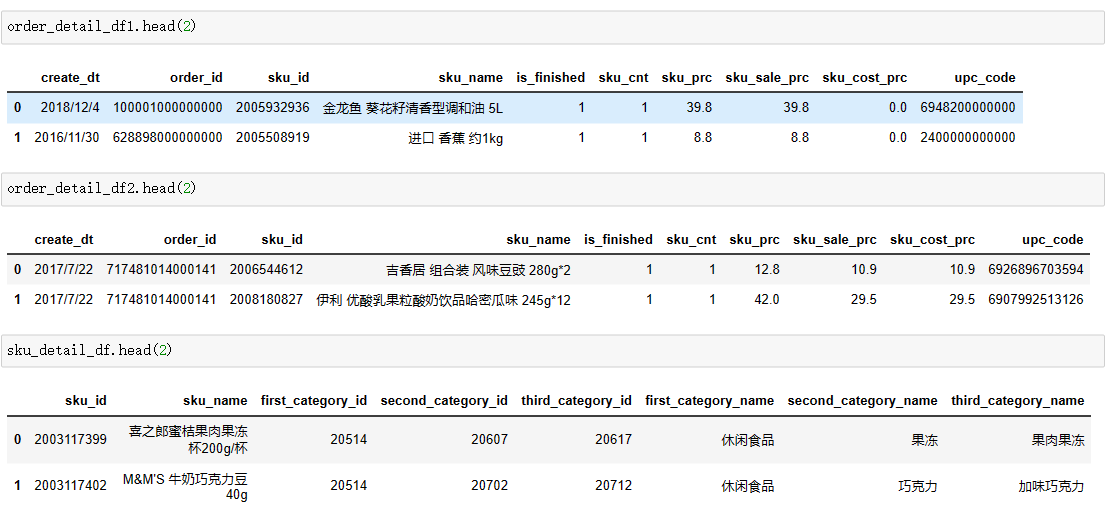
3)数据细节
02 数据清洗
1)合并销售流水表,并拼接商品信息表
# 合并订单明细表
order_detail_df = pd.concat(objs=[order_detail_df1, order_detail_df2], axis=0)
# 拼接sku明细表
data_df = pd.merge(left=order_detail_df, right=sku_detail_df, on=['sku_id','sku_name'], how='left')
2)合并之后探查整体数据
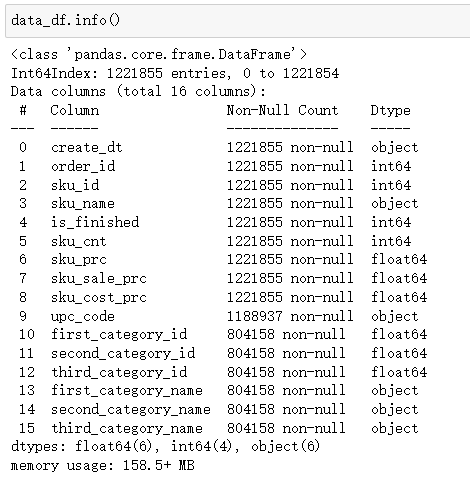
我们发现:销售流水表共有1221855条订单商品(SKU)流水信息,有类目信息的有804158条。
3)异常样本过滤
首先过滤掉类目为空的SKU,再剔除掉未完单的样本,最后剔除销量、门店价、销售价、成本价为负的样本。代码如下:
# 异常样本过滤
data_df = data_df[~data_df['third_category_id'].isnull()] # 过滤类项目信息为空的sku
data_df = data_df[data_df['is_finished'] == 1] # 剔除未完单样本
data_df = data_df[(data_df['sku_cnt'] >= 0) & (data_df['sku_sale_prc'] >= 0) & \
(data_df['sku_prc'] >= 0 ) & (data_df['sku_cost_prc'] >= 0 )] # 剔除销量、价格<=0样本
03 数据聚合
1)将SKU流水数据合并到天,销量取和,价格取均值
# 订单聚合至sku日流水
data_df = data_df.\
groupby(['create_dt', 'sku_id', 'sku_name', 'first_category_id', 'second_category_id', 'third_category_id', 'first_category_name', 'second_category_name', 'third_category_name']).\
agg({'sku_cnt':'sum', 'sku_prc':'mean', 'sku_sale_prc':'mean'}).reset_index()
2)将日期格式转换为YYYY-MM-DD格式,以便于排序
# create_dt日期格式转换
data_df['create_dt'] = data_df.apply(func=IOR_DP.date_style_convert, axis=1)
3)对数据进行排序,以便观察
# 排序
data_df = data_df.sort_values(by=['sku_id', 'create_dt'], ascending=[True,True]).reset_index(drop=True,inplace=False)
4)避开长假,截取2018-03-01至2018-09-30的数据进行研究
# 截取非长假半年时间段
data_df = data_df[(data_df['create_dt'] >= '2018-03-01') & (data_df['create_dt'] <= '2018-09-30')]
5)对数据统一进行重命名
# 列原名太长,重命名
data_df = data_df.rename(columns={'first_category_id':'cate1_id', 'first_category_name':'cate1_name', \
'third_category_id':'cate3_id', 'third_category_name':'cate3_name', \
'sku_prc':'ori_prc','sku_sale_prc':'sale_prc', 'sku_cnt':'sale_cnt', 'create_dt': 'sale_dt'})
04 数据补全
1)由于成本价缺失严重,因此进行补全操作
根据数据集提示:零售商的毛利率大概在0.2-0.4之间。因此,可先生成毛利率,然后用门店价(原价)、销售价(折扣价)反推成本价。步骤如下:
- 假设原价相较成本价的毛利率符合正态分布 N ( 0.3 , 0.05 ) N(0.3, 0.05) N(0.3,0.05),最大值为0.4,最小值为0.2;
- 假设折扣价相较成本价的毛利率符合正态分布 N ( 0.2 , 0.05 ) N(0.2, 0.05) N(0.2,0.05),最大值为0.05,最小值为0.35;
- 成本价 = m i n min min(原价反推的成本价,折扣价反推的成本价)
注:实际业务中,价格大概率不符合正态分布,需要用真实数据。
# 原数据成本价异常(大部分缺失,未缺失的与折扣价相同),无法使用,需要重新制作
## 一个sku历史一个成本价,暂不考虑波动,简化处理
cost_prc_df = data_df[['sku_id', 'ori_prc', 'sale_prc']].\
groupby(['sku_id']).agg({'ori_prc':'mean', 'sale_prc':'mean'}).reset_index()
## 正态分布造原价毛利N(0.3,0.05)、折扣价毛利N(0.2,0.05)
ori_prc_profit_ratio_array = IOR_DP.generate_norm_data(mean = 0.3, std = 0.05, x_min = 0.2, x_max = 0.4, n = len(cost_prc_df))
sale_prc_profit_ratio_array = IOR_DP.generate_norm_data(mean = 0.2, std = 0.05, x_min = 0.05, x_max = 0.35, n = len(cost_prc_df))
## 制作成本价,保证要比折扣价低,不能赔本卖
cost_prc_df['ori_prc_profit_ratio'] = ori_prc_profit_ratio_array
cost_prc_df['sale_prc_profit_ratio'] = sale_prc_profit_ratio_array
cost_prc_df['ori_prc_cost_prc'] = cost_prc_df['ori_prc'] / (cost_prc_df['ori_prc_profit_ratio'] + 1) # 原价反推的成本价
cost_prc_df['sale_prc_cost_prc'] = cost_prc_df['sale_prc'] / (cost_prc_df['sale_prc_profit_ratio'] + 1) # 折扣价反推的成本价
cost_prc_df['cost_prc'] = cost_prc_df.apply(func=lambda x: min(x['ori_prc_cost_prc'], x['sale_prc_cost_prc']), axis=1) # 取小者
data_df = pd.merge(left=data_df, right=cost_prc_df[['sku_id', 'cost_prc']], on=['sku_id'], how='left') # 拼接回主表
2)最后修改特征字段类型并输出至csv
# 修改列类型、小数点后位数、展示顺序
data_df['sku_id'] = data_df['sku_id'].astype('int')
data_df['cate1_id'] = data_df['cate1_id'].astype('int')
data_df['cate2_id'] = data_df['cate2_id'].astype('int')
data_df['cate3_id'] = data_df['cate3_id'].astype('int')
data_df['sale_cnt'] = data_df['sale_cnt'].astype('int')
data_df['ori_prc'] = data_df['ori_prc'].astype('float').round(2)
data_df['sale_prc'] = data_df['sale_prc'].astype('float').round(2)
data_df['cost_prc'] = data_df['cost_prc'].astype('float').round(2)
data_df = data_df[['sku_id', 'sku_name', 'ori_prc', 'sale_prc', 'cost_prc', 'sale_cnt', 'cate1_id', 'cate2_id', 'cate3_id', 'cate1_name', 'cate2_name', 'cate3_name', 'sale_dt']]
# 输出
data_df.to_csv('promotional_pricing_data1.csv', sep=',', encoding='utf8', index=False)
05 小结
第一篇(业务问题拆解):我们把一个实际的促销定价问题拆解成了一系列的数学问题。
本篇(数据预处理生成):我们选择了一份公开的促销定价数据集,将其加工成了可分析求解的数据。
下一篇(数据挖掘分析):我们将介绍如何对数据进行全方位的挖掘和分析。敬请期待~~~
06 代码获取方式
大家将推文转发朋友圈获X赞,截图发后台,管理员会定期回复数据代码连接哈~~~
获5赞 :获取 第一篇数据地址
获15赞 :获取 第一篇数据+本篇代码地址
我们是**【运筹匠心】** ,咱们下期见~~~
07 加粉丝群方式
粉丝1群二维码:

加不了群,请加管理员微信:IndustryOR

参考文献
- Hua J, Yan L, Xu H,et al. Markdowns in E-Commerce Fresh Retail: A Counterfactual Prediction and Multi-Period Optimization Approach[J]. arxiv, 2021.(https://arxiv.org/pdf/2105.08313.pdf)
- Kui Zhao, Junhao Hua, Ling Yan, et al. A Unified Framework for Marketing Budget Allocation[J]. arxiv, 20.(https://arxiv.org/pdf/1902.01128.pdf)
- 用相关系数进行Kmeans聚类,利用利润率、打折率、销售额、毛利润得到商品价格弹性标签,建立价格折扣力度模型(https://blog.csdn.net/weixin_45934622/article/details/114382037)
- 2019全国大学生数学建模竞赛讲评:“薄利多销”分析(https://dxs.moe.gov.cn/zx/a/hd_sxjm_sxjmstjp_2019sxjmstjp/210604/1699445.shtml)
- 策略算法工程师之路-基于线性规划的简单价格优化模型(https://zhuanlan.zhihu.com/p/145192690)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









