







论文阅读笔记(四)——ESPNetV2::A Light-weight Power Efficient and General Purpose Convolutional Neural Network
前言
这几天要改论文,大修…。改完还要写论文…u1s1,我觉得改论文比写论文难多了,毕竟一个只负责瞎吹比,另外一个解决审稿意见,太难了

1 论文简介
1.1 关于文章
论文名称:ESPNetv2–A Light-weight, Power Efficient, and General Purpose Convolutional Neural Network
1.2 关于模型
为了计算更加高效:
- 将原来ESPNet的point-wise conv逐点卷积 替换为group point-wise conv组逐点卷积;
- 将原来ESPNet的dilated convolutions 空洞卷积替换为depth-wise dilated convolution深度空洞卷积;
- HFF加在depth-wise dilated separable conv深度空洞卷积 和 point-wise (or 1 × 1) 逐点卷积之间,去除Gridding Artifacts ;
- 使用中一个 group point-wise conv组逐点卷积 替换K 个point-wise conv逐点卷积 ;
- 将depth-wise dilated conv 深度空洞卷积加入下采样操作;
- 加入平均池化(average pooling ),将输入图片信息加入EESP中;
- 使用级联(concatenation) 取代对应元素加法操作(element-wise addition operation );
2 文章正文
2.1 摘要
我们引入了一种轻量级,高效,通用的卷积神经网络ESPNetv2,用于对可视数据和顺序数据进行建模。 我们的网络使用成组的点方向和深度方向的可扩展卷积来学习具有较大FLOP和参数的大型有效接收场的表示形式。 我们在四个不同的任务上评估了我们网络的性能:
(1)分类(2)语义分割(3)目标检测(4)语言模型
通过对这些任务的实验,包括ImageNet上的图像分类和PenTree库数据集上的语言建模,证明了我们的方法优于最新方法的性能。 我们的网络性能比ESPNet高出4-5%,并且在PASCAL VOC和Cityscapes数据集上的FLOP减少了2-4倍。 与MS-COCO对象检测上的YOLOv2相比,ESPNetv2的精度提高了4.4%,而FLOP却减少了6倍。 我们的实验表明,ESPNetv2的电源效率比现有的最新高效方法(包括ShuffleNets和MobileNets)高得多。 我们的代码是开源的,可从https://github.com/sacmehta/ ESPNetv2获得。
2.2 Motivation&Contributions
PS: 这一段主要是方便我们以后写Introduction与Related Work
2.2.1 Motivation
GPU的日益增长的可编程性和计算能力加速了用于建模视觉数据的深度卷积神经网络(CNN)的发展。 CNN正在现实世界中的视觉识别应用中使用,例如视觉场景理解和生物医学图像分析。 这些现实世界中的许多应用程序(例如自动驾驶汽车和机器人)都在资源受限的边缘设备上运行,并要求以低延迟对数据进行在线处理。现有的基于CNN的视觉识别系统需要大量的计算资源,包括内存和功能。 尽管它们在基于高端GPU的机器上(例如NVIDIA TitanX)实现了高性能,但对于资源受限的边缘设备(例如手机和嵌入式计算平台)而言,它们通常过于昂贵。 例如,ResNet-50是最著名的用于图像分类的CNN架构之一,具有2556万个参数(98 MB内存),并执行28亿次高精度操作以对图像进行分类。 对于更深的CNN,例如,这些数字甚至更高。 ResNet101。 这些模型很快使边缘设备上可用的有限资源(包括计算能力,内存和电池)负担过重。 因此,在边缘设备上运行的实际应用中的CNN应该轻巧高效,同时提供高精度。
建立轻量级网络的最新努力可大致分为:
- 基于网络压缩的方法可以消除预训练模型中的冗余,从而提高效率。 这些模型通常通过不同的参数修剪技术来实现。
- 基于低位表示的方法使用少量位而不是高精度浮点表示学习的权重。 这些模型通常不会改变网络的结构,并且可以使用逻辑门来实现卷积运算,以实现对CPU的快速处理。
- 轻量级的CNN通过考虑计算上昂贵的卷积运算来提高网络效率。 这些模型通过其设计在计算上是高效的,即基础模型结构学习的参数较少,浮点运算(FLOP)较少。
2.2.2 Contributions
本文的主要贡献是:
- 一种通用架构,可有效地对可视数据和顺序数据进行建模。 我们演示了网络在不同任务上的性能,从对象分类到语言建模。
- 我们提出的架构ESPNetv2扩展了ESPNet ,这是一种基于深度卷积的分段网络,具有深度可分离的卷积,一种有效的卷积形式,用于最先进的高效网络中,包括MobileNets和ShuffleNets。 与深度可分离卷积相比, Depth-wise dilated separable conv深度空洞可分离卷积将ESPNetv2的精度提高了1.4%。我们注意到,与ESPNet 中的 dilated conv空洞卷积(具有426个MFLOP的69.2)相比,ESPNetv2的FLOP更少,可以实现更高的精度(72.1,具有284个MFLOP)
- 我们的经验结果表明,ESPNetv2在图像分类任务上以更少的FLOPS提供了相似或更好的性能。 在ImageNet分类任务上,在效率和准确性方面,我们的模型优于所有以前的有效模型设计,尤其是在较小的计算预算下。 例如,在28个MFLOP的计算预算下,我们的模型比MobileNetv2胜2%。 对于在PASCAL VOC和Cityscapes数据集上的语义分割,ESPNetv2的性能比ESPNet]高4-5%,并且FLOP少2-4倍。对于目标检测,ESPNetv2优于YOLOv2 4.4%,FLOP减少6倍。 我们还研究了带有热重启的循环学习速率调度程序。 我们的结果表明,该计划程序比标准的固定学习率计划程序更有效。
Depth-wise dilated separable conv深度空洞可分离卷积
在MobileNet中引入了深度可分离卷积,它可以有效降低计算量,这里在深度可分离卷积的基础上在卷积上添加空洞系数,从而增大卷积的感受野,因而将原有
n
×
n
n\times n
n×n的感受野变为
(
n
−
1
)
⋅
r
+
1
( n − 1 ) ⋅ r + 1
(n−1)⋅r+1(这里
n
n
n,
r
r
r分别是卷积核的大小与膨胀系数)。不同卷积类型之间的计算量与感受野大小对比如表1所示:

EESPunit EESP单元
利用深度扩展可分卷积和群点卷积的优点,文章提出了一种新的单元EESP,即深度扩展可分卷积的高效空间金字塔(Extremely Efficient Spatial Pyramid),它是专门为边缘器件设计的。我们的网络设计是基于ESPNet架构,一种最先进的高效分割网络。ESPNet架构的基本构建块是ESP模块,如图1a所示。它基于reduce-split-transform-merge策略。ESP单元首先利用逐点卷积将高维输入特征映射映射到低维空间,然后利用不同扩张率的扩张卷积并行学习表示。这个单元是源自于v1版本中的ESP模块,回顾v1版本中的ESP模块,其是在输入特征上使用深度可分离卷积减少维度,之后对这些特征分组,在不同分组的特征上使用不同参数的膨胀卷积,之后使用HFF模块将这些特征融合起来(消除方格效应)。

在这篇文章中主要针对v1中的ESP模块进行改进,引入分组卷积从而衍生除了两个版本的EESP单元。
1)EESP-A,该模块为了使ESP模块的计算效率更高,我们首先用分组逐点卷积代替逐点卷积。然后,我们用高效的深度空洞可分离卷积代替3×3空洞卷积代替计算上昂贵的3×3空洞卷积,
为了消除由扩展卷积引起的网格伪影,我们使用计算效率高的层次特征融合(HFF)方法对特征图进行融合其结构见下图所示:
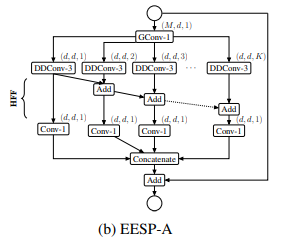
2)EESP,该模块在EESP-A的基础上将深度可分离空洞卷积替换为了组卷积,从而达到进一步减少参数与计算量的目的,其结构见下图所示:
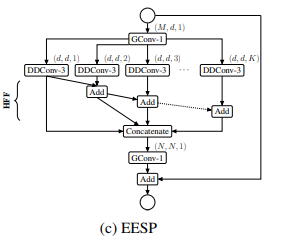
带有stride的EESP模块
为了在多个尺度上有效地学习表示,我们对图1c中的EESP块进行了以下更改:
1)用带有stride对应的空洞卷积替换深度空洞卷积
2)添加平均池化操作而不是identity connection,实现维度匹配
3)将相加的特征融合方式替换为concat形式,增加特征的维度。
4)融合原始输入图像的下采样信息,使得特征信息更加丰富。在下采样和卷积(滤波)操作期间,空间信息丢失。为了更好地编码空间关系并有效地学习表示,我们添加了输入图像和当前下采样单元之间的有效
l
o
n
g
−
r
a
n
g
e
s
h
o
r
t
c
u
t
long-range shortcut
long−rangeshortcut连接。这种连接首先对图像进行下采样,使其与特征图的大小相同,然后使用两个卷积的堆栈学习表示。第一个卷积是学习空间表示的标准3×3卷积,而第二个卷积是学习输入之间的线性组合并将其投影到高维空间的逐点卷积。如图2

网络结构
ESPNetv2网络是使用EESP单元构建的。在每一个空间层次上,ESPNetv2都会多次重复EESP单元,以增加网络的深度。在EESP单元中,我们在每个卷积层之后使用
b
a
t
c
h
n
o
r
m
a
l
i
z
a
t
i
o
n
batch normalization
batchnormalization和
P
R
e
L
U
PReLU
PReLU,但最后一个分组卷积层除外,其中PReLU在元素求和之后应用。为了在每个空间层次上保持相同的计算复杂度,在每次下采样操作之后,feature maps 都会加倍。
在我们的实验中,我们设定空洞率
r
r
r与EESP单位(K)中的分支数成比例。
EESP单位的有效感受野随K值的增加而增大,有些核,特别是在7×7等低空间水平上,其有效感受野可能大于feature maps 的大小。因此,这样的核可能对学习没有帮助。为了得到有意义的核,我们用空间维度
W
l
×
H
l
W^{l}×H^l
Wl×Hl限制每个空间水平l的有效感受野为:
n
d
l
(
Z
l
)
=
5
+
z
l
/
7
,
Z
l
∈
W
l
,
H
l
n^l_d(Z^l)=5+{z^l}/{7},Z^l∈{W^l,H^l}
ndl(Zl)=5+zl/7,Zl∈Wl,Hl,与最低空间水平(即7×7)对应的有效感受野(
n
d
×
n
d
n_d×n_d
nd×nd)为5×5。在之后,我们在实验中设置了K=4。此外,为了具有齐次结构,我们将群点卷积中的组数设置为平行分支数(g=K)。
不同计算复杂度下的整体ESPNetv2架构如下图所示。

实验 Experiments
图像分类
数据集::mageNet-1000分类数据集,包含128万张用于训练的图像和50万张用于验证的图像。我们使用单个裁剪top-1分类精度来评估我们的网络的性能,即我们在尺寸为224×224的中心裁剪视图上计算精度
训练:
pytoch
CUDA 9.0
cuDNN
SGD
学习率:
T=5是周期,max=0.5,min=0.1为范围
batch size 512
300 epoch
在以下时间间隔将学习率衰减2倍:{50、100、130、160、190、220、250、280}。我们使用标准的数据增强策略。
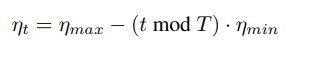
结果
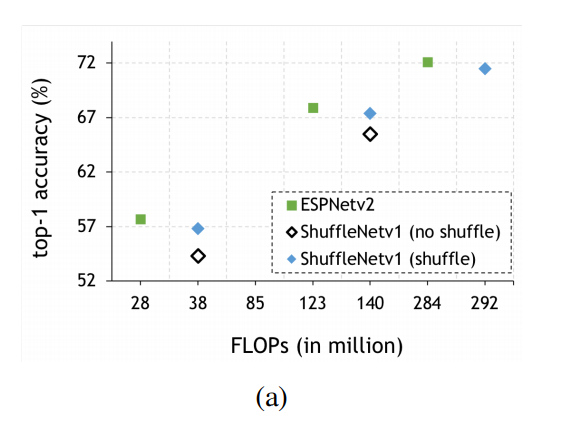

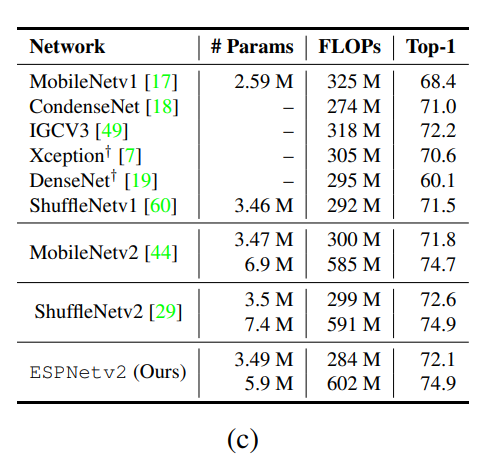
多标签分类
为了评估迁移学习的可推广性,文章还在MSCOCO多目标分类任务中评估了我们的模型。该数据集由82783个图像组成,这些图像分为80个类,每个图像有2.9个对象标签。在之后,我们在验证集(40504个图像)上使用类和总体F1分数评估了我们的方法。我们使用与ImageNet数据集相同的数据增强和训练设置,对100个时期的ESPNetv2(2.84亿次FLOPs)和Shufflenetv2[29](2.99亿次FLOPs)进行微调,除了ηmax=0.005,ηmin=0.001,学习率在第50和80个时期衰减2。我们使用二元交叉熵损失进行优化**。结果如图所示。ESPNetv2比ShuffleNetv2有很大的优势,尤其是在896×896的图像分辨率下进行测试时,表明EESP单位的大有效感受野有助于ESPNetv2学习更好的表征**。

性能分析
边缘设备具有有限的计算资源和有限的能量开销。一个用于此类设备的高效网络应该消耗更少的功率,并且具有低延迟和高精度。文章在两个不同的设备上测量了我们的网络ESPNetv2以及其他最先进的网络(MobileNets和ShuffeNets)的效率:1)高端图形卡(NVIDIA GTX 1080 Ti)和2)嵌入式设备(NVIDIA Jetson TX2)。为了公平比较,文章使用PyTorch作为一个深度学习框架。

语义分割
数据集:
- Cityscapes
- 由5000个精细注释的图像组成(训练/验证/测试:2975/500/1525)
- VOC2012
- 具有1.4K训练、1.4K验证和1.4K测试图像
训练
- 具有1.4K训练、1.4K验证和1.4K测试图像
第一阶段:
256x256 VOC2012
512x256 Cityscapes
100epoch
SGD
初始学习率 0.007
第二阶段
384x384 VOC2012
1024x512 Cityscapes
100epoch
SGD
初始学习率 0.003
以上两个阶段前50epochT=5,后50个阶段采用衰减学习率
结果
ESPNetv2提供了一个有竞争力的性能,而现有的方法是非常有效的。在相似的计算约束条件下,ESPNetv2算法大大优于现有的ENet和ESPNet算法。
值得注意的是,ESPNetv2的准确率比其他高效网络(如ICNet、ERFNet和ContextNet)低2-3%,但少9-12倍FLOPS。
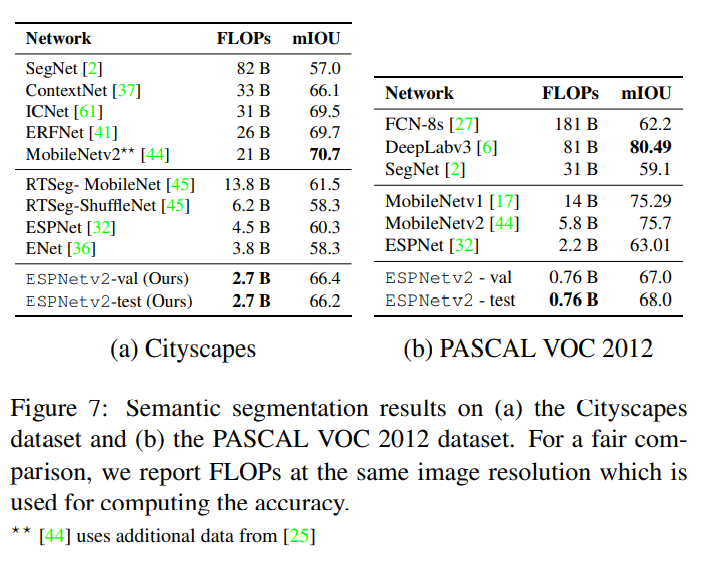
目标检测
数据集:
- MS-COCO
- VOC2007
- VOC2012
训练
评估标准:MAP
结果

语言模型
数据集:
- PTB
训练
基础LSTM
dropout 0.5
结果
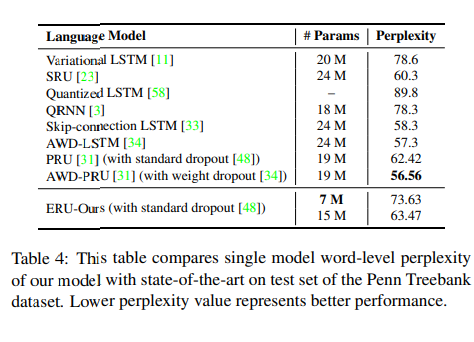
总结
文章介绍了一种重量轻、功耗低的网络ESPNetv2,它通过从一个大的有效感受野中学习表征来更好地编码图像中的空间信息。我们的网络是一个通用的网络,具有良好的泛化能力,可用于广泛的任务,包括序列建模。我们的网络在不同的任务(如对象分类、检测、分割和语言建模)中提供了最先进的性能,同时提高了能效。
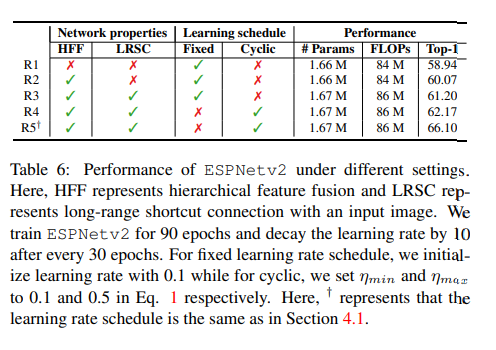
收获
- 不同卷积比较

- 层次特征融合HFF
- HFF将分类性能提高了约1.5%,同时对网络的复杂性没有影响。
- 消除了由扩张卷积引起的网格伪影
- 能够在EESP单元的不同分支之间共享信息,这使得它能够学习丰富和强大的表示
- long-range shortcut 连接对输入的影响
- 这些连接是有效和高效的,性能提高了约1%,对网络的复杂性影响很小
- Fixed vs cyclic学习周期















 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









