






目录
- (零)这篇博客在干什么
- (一)内生安全与香农信道编码定理
- (二)基本定义
- (三)编码信道存在定理
-
* (三.壹)编码信道存在第一定理- (三.贰)编码信道存在第二定理
- (三.叁)编码信道存在第三定理
- (四)总结
(零)这篇博客在干什么
由于本篇博客可能会涉及到较多数学方面的东西,所以我们在一开始先确定一下本文究竟想要做一个什么事情,以便于大家(以及我自己)对整体有一个较强的把握,而不至于被淹没在不知所云的符号之海之中。
从一个high level的角度来讲,《网络空间内生安全:拟态防御与广义鲁棒控制》一书中所提到的所谓 编码信道数学模型 就干了这么一个事儿:
从理论上证明了DHR架构可以作为实现内生安全的一种方法 。
那么具体是怎么证明的呢,这就是我们接下来整篇博客所要 试图 讲清楚的东西。
(一)内生安全与香农信道编码定理
在上一篇博文网络空间内生安全数学基础(1)——背景中,我们已经了解到了信息系统安全防御和香农可靠通信之间的关联,那么为什么要建立这种关联呢?原因是:
网络空间内生安全的基本问题可以描述为 如何在一个存在非随机噪声的可重构有记忆信道上正确地处理和传输信息 。
注意,这个地方的描述是【非随机噪声、有记忆信道】,而香农可靠通信假设的是【随机噪声、无记忆信道】( 把握住对于噪声和信道的假设很重要
,正如我们在网络空间内生安全数学基础(1)——背景中提醒大家注意的那样)。
那么利用这种抽象表达,就建立起了内生安全与香农信道编码定理之间的关系——对于网络攻击所导致的信息处理和传输、可靠性与通信噪声等错误都可以采用纠错编码思路进行解决。但是需要注意的是,经典香农通信模型假设
无记忆信道 ,而信息系统可以被抽象为一种有处理能力的 可重构有记忆信道 ;经典香农通信模型假设 噪声随机
,而网络攻击具有明显的非随机性,可以抽象为 广义不确定扰动 (包括随机通信噪声、随机物理失效、人为攻击噪声等)。
有了这种联系,《网络空间内生安全:拟态防御与广义鲁棒控制》一书发展了香农信道编码理论,在其基础上提出了编码信道理论(这个名字起得有点随意的……),相较于前者,编码信道理论导入了一些新的因素,例如
非随机噪声在有记忆可重构结构信道上的随机性变化分析 ,再次从一个high
level的角度来讲(但是没有开篇那么high),这个编码信道理论其实就是证明了这样一个事情:
基于概率论形式化证明了对于离散有记忆信道上的任何随机和非随机扰动,存在一种内源性的 动态异构冗余消记忆
的信道构造与编码方案,能够使平均译码错误概率任意小。
这个表述是不是有点熟悉,和香农第二定理很像是吧,香农第二定理其实就是编码信道理论(上面的这段话)在随机噪声无记忆信道条件下的一种特例。
(二)基本定义
在介绍数学模型之前呢,肯定是要介绍一些基本定义和假设了,编码信道理论里面的这部分内容主要就是针对 漏洞、后门 这种攻击方可以利用的东西和
结构编码、元信道、纠错译码
这些信息系统内生安全模型里面的结构进行的定义和假设,具体的结构在网络空间内生安全数学基础(1)——背景最后一张图里面有所提及,我们在这里再加深一下印象。
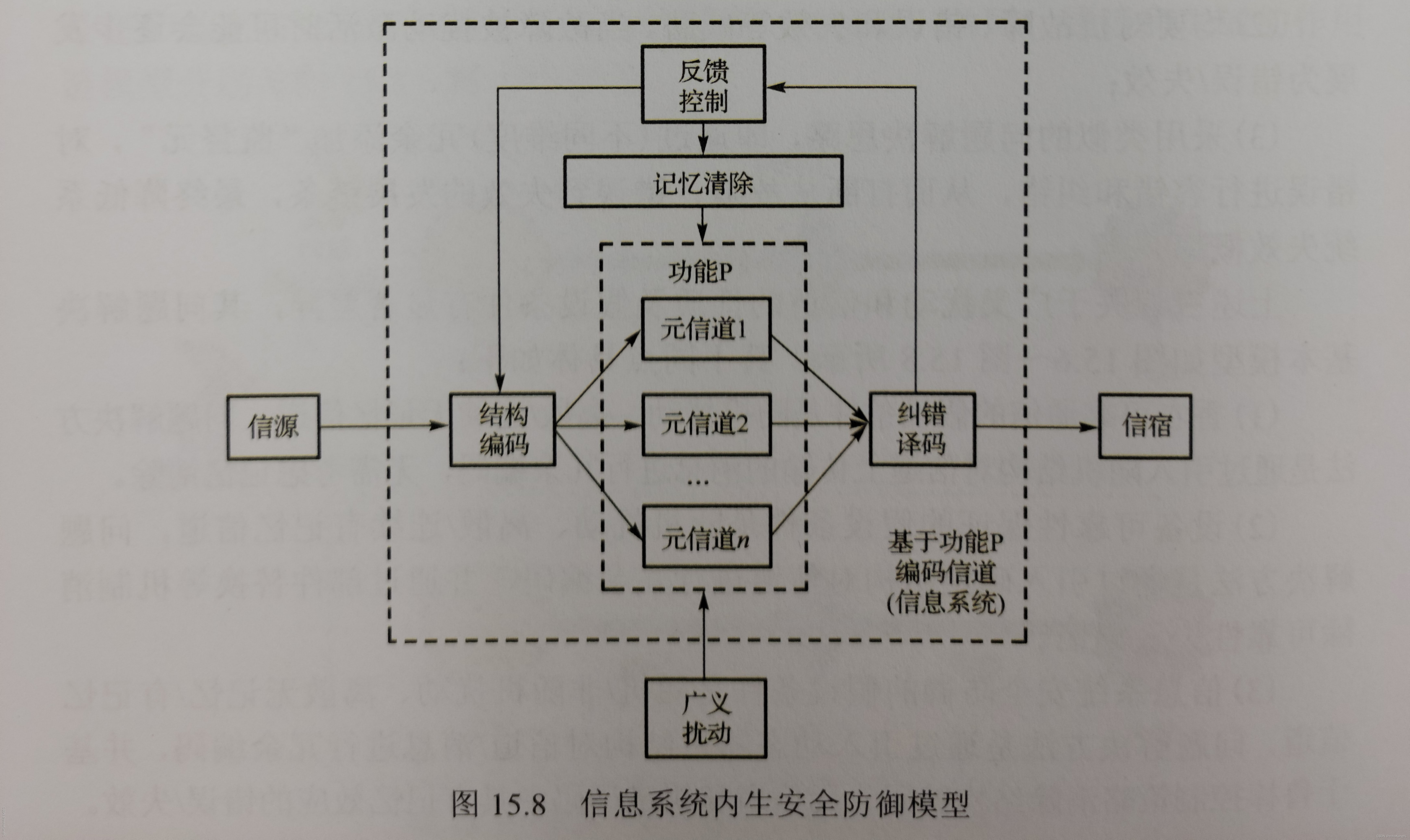
挑重点来说,我们可以从上图中看到,信源发出的信号依次经过 结构编码、元信道和纠错译码
,元信道有n个是因为DHR架构本身就有动态异构冗余的特性,而且因为该模型假设信道有记忆,所以上面有一个 记忆清除模块 ,下面的 广义扰动
就是指随机或非随机扰动,这个是为了适应信息系统所面临的威胁在传统的香农定理上扩展出来的,前文也已经提到过了。
主体结构大概就是这五个部分,那么我们接下来开始正式介绍定义与假设:
假设1:
对于单个漏洞,攻击方通过扰动激活漏洞并产生信道错误需要的时间 T s > 0 T_s>0 Ts>0;对于协同漏洞,由于元信道的异构性,攻击方需要时间
T i > 0 T_i>0 Ti>0 来协同漏洞并产生信道错误。
这里先解释一下什么是协同漏洞,上面的图所描述的系统里面有 n n n 个 异构 元信道,这时针对其中某个元信道 k k k
的单一漏洞进行可能无法对整个系统噪声影响(因为毕竟还有剩余 n − 1 n-1 n−1 个信道),那么如果想对整个系统造成影响的话,可能需要同时对系统中的
⌈ n 2 ⌉ \lceil\frac{n}{2}\rceil ⌈2n⌉
个元信道所具有的漏洞同时利用(如果用大数裁决的话),那么这种对多个元信道所具有的漏洞同时利用的方式就被称为协同漏洞。
上述 假设1 说明了 单个漏洞 和 协同漏洞 的利用均需要一定的时间。
假设2:
对于单个后门,攻击方通过扰动激活后门并产生信道错误需要的时间 T s = 0 T_s=0 Ts=0;对于协同后门,由于元信道的异构性,攻击方需要时间
T i > 0 T_i>0 Ti>0 来协同后门并产生信道错误。
(协同后门的概念和上述协同漏洞类似)
上述 假设 2 说明了 单个后门 的利用无需时间(可以看作系统内部的攻击),而 协同后门 的利用需要一定的时间。
假设3:
对于元信道,假设其中可以同时存在漏洞和后门,可以有记忆或无记忆,对广义扰动造成元信道错误或失效的记忆可消除。
上述 假设 3 说明了系统可以通过“ 记忆清除 ”模块进行 记忆消除 (如上图),若系统在 t t t 时刻进行了
记忆消除 ,且 t 0 < t < t 1 t_0<t<t_1 t0<t<t1,那么任意 t 0 t_0 t0
时刻发生的信道错误将不影响任意 t 1 t_1 t1 时刻的信息传递。
定义1:
无记忆元信道是指元信道 M C 0 , M C 1 , ⋯ , M C n M{C_0},M_{C_1},\cdots,M_{C_n}
MC0,MC1,⋯,MCn 在 T s T_s Ts 时刻受到的不确定性扰动不会影响时刻 t + T s , ( t > 0 )
t+T_s,(t>0) t+Ts,(t>0)。有传输概率:_
∀ t ≥ 0 , P ( y ≠ x ∣ x ) = p , \forall t\geq 0, \mathbb{P}(y\neq x|x)=p,
∀t≥0,P(y=x∣x)=p,
其中 x x x 为信源信息, y y y 为译码后信宿收到的信息。
定义2:
有记忆元信道是指元信道 M C 0 , M C 1 , ⋯ , M C n M{C_0},M_{C_1},\cdots,M_{C_n}
MC0,MC1,⋯,MCn 在 T s T_s Ts 时刻受到不确定性扰动的影响在时刻 t + T s , ( t > 0 )
t+T_s,(t>0) t+Ts,(t>0) 一直保持。有传输概率:_
∃ T s , ∀ t ≥ T s , P ( y ≠ x ∣ x ) = 1 , \exists T_s, \forall t\geq T_s,
\mathbb{P}(y\neq x|x)=1, ∃Ts,∀t≥Ts,P(y=x∣x)=1,
其中 x x x 为信源信息, y y y 为译码后信宿收到的信息。
上述 定义1、定义 2 可与 假设 3 互相进行理解:
无记忆信道中,无论在何时刻受到了扰动,传输概率不受影响( _ 定义1_ );有记忆信道中,扰动影响传输概率( _ 定义2_ );而上图中的
记忆清除 模块可以擦除这种元信道对扰动的“记忆”( _ 假设 3_ )。
(三)编码信道存在定理
如下的三个编码信道存在定理分别在不同条件下由浅入深地给出了“ 信道出错概率可以任意小
”这一结论——对标香农第二定理,对具体证明部分不感兴趣的朋友们记住前面加粗这个部分的结论和对应的条件(在下文三个子标题的定理部分会给出)就可以了。
在接下来的三个子标题中,都是先给定理再给解释。
注:下面三个定理中的一些名词的具象化解释可以在上文 第(二)部分:基本定义 中的图中找到。
(三.壹)编码信道存在第一定理
元信道噪声(扰动)随机到达,结构编码和纠错译码无扰动和无记忆,记离散无记忆元信道为 [ P ( y ∣ x ) ] [P(y|x)]
[P(y∣x)],其中 x , y x,y x,y 分别为输入、输出,编码信道容量为 C C C,噪声随机到达,若编码信息传输率 R < C R<C
R<C,那么存在无记忆元信道 n n n 足够大的编码信道,总可以在输入集合找到 M ′ = 2 n R M’=2^{nR} M′=2nR
个码字组成的一个码集合(码长为 n n n),在一定译码规则下使得信道输出错误概率 P E ≤ ϵ P_{E}\leq\epsilon PE≤ϵ,其中
ϵ \epsilon ϵ 为任意小正数。
(……定理结束分割线……)
上文已经提到了,定理中的条件很重要,那么这个 编码信道存在第一定理 的条件是这样的:
- 噪声(扰动)随机到达
- 结构编码和纠错译码无扰动和无记忆
- 元信道离散无记忆
在这样的条件下,编码信道的 n n n个元信道构造满足香农第二定理信道噪声随机且信道 n n n次扩展无记忆条件的约束前提,因此该
编码信道存在第一定理 和 香农第二定理 等价,证明方式也相同。
作者通过这样的方式证明了上述第一定理。
(三.贰)编码信道存在第二定理
元信道噪声(扰动)非随机到达,结构编码和纠错译码无扰动和无记忆,记动态异构冗余与反馈消记忆构造后的离散有记忆编码信道为 [ P ( y ∣ x s f )
] [P(y|xsf)] [P(y∣xsf)],其中 x , y , s , f x,y,s,f x,y,s,f
分别为输入、输出、记忆状态、反馈消记忆状态,编码信道容量为 C C C 且对任意时刻 t t t 有 ∀ t > 0 , C ( t ) ∈ [ C
S , C 0 ] \forall t>0, C(t)\in[C_S,C_0] ∀t>0,C(t)∈[CS,C0],若时刻 t t t 编码信息传输率
R ( t ) < C ( t ) R(t)<C(t) R(t)<C(t),则只要码长与编码元信道构造数 n n n 足够大,总可以在输入集合找到 M
′ = 2 n R ( t ) M’=2^{nR(t)} M′=2nR(t) 个码字组成的一个码集合,在一定译码规则下使得信道输出错误概率 P E ( t
) ≤ ϵ P_{E}(t)\leq\epsilon PE(t)≤ϵ,其中 ϵ \epsilon ϵ 为任意小正数。
(……定理结束分割线……)
上述 编码信道存在第二定理 的条件是这样的:
- 噪声(扰动)非随机到达
- 结构编码和纠错译码无扰动和无记忆
- 编码信道离散有记忆
可以看到,相较于前文 第一定理 ,该 第二定理 放松了一些条件:噪声到达由随机推广至非随机(因为本书利用 广义扰动
将攻击、异常等扰动均放在了同一个框架下,所以很难将其建模为 随机噪声
)、编码信道无记忆推广至有记忆(有记忆信道的假设也比无记忆信道假设更加严苛,且更符合现实情况)。
在这样的条件下,作者给出了 编码信道存在第二定理 的证明。
【证明开始】
对于存在攻击扰动的离散有记忆信道 P ( y i + 1 ( t ) ∣ x i + 1 ( t ) s i ( t ) )
P(y_{i+1}(t)|x_{i+1}(t)s_i(t)) P(yi+1(t)∣xi+1(t)si(t)), s i ( t ) = 0
s_i(t)=0 si(t)=0 表示前一序列 i i i 正常输出 对 t t t 时刻 i + 1 i+1 i+1
序列的影响,其中攻击的影响会随着时间累积。 s i ( t ) = 1 s_i(t)=1 si(t)=1 表示前一序列 i i i 异常输出 ,
t t t 时刻 i + 1 i+1 i+1 序列将一直以概率 1 1 1 保持该异常状态。
不失一般性,假定在攻击到达之前的时间 t t t 内,攻击成功干扰元信道的记忆性表现为时间上的负指数分布,即:
1) 假设攻击以速率 λ \lambda λ 到达,则有:
P s ( t ) = 1 − e − λ t = p ( t ) . P_s(t)=1-e^{-\lambda t}=p(t).
Ps(t)=1−e−λt=p(t).
当引入反馈控制消记忆动作 f ( t ) f(t) f(t),假定防御方重构恢复(或攻击记忆消除)以可控速率 μ \mu μ 到达,则有:
P r ( t ) = 1 − e − μ t = p ( f ( t ) ) . P_r(t)=1-e^{-\mu t}=p(f(t)).
Pr(t)=1−e−μt=p(f(t)).
上述过程可由下图表示,其中 S 0 S_0 S0 为元信道初始无记忆初状态, S 1 S_1 S1 为元信道攻击记忆保持状态。

于是,对单个离散有记忆元信道,有译码错误概率:
P ( y i ( t ) ≠ x i ( t ) ∣ x i ( t ) ) = − λ λ + μ e − ( λ + μ ) t + λ λ
+ μ < 1. P(y_i(t)\neq
x_i(t)|x_i(t))=-\frac{\lambda}{\lambda+\mu}e^{-(\lambda+\mu)t}+\frac{\lambda}{\lambda+\mu}<1.
P(yi(t)=xi(t)∣xi(t))=−λ+μλe−(λ+μ)t+λ+μλ<1.
2) 若攻击在某时刻 T s T_s Ts 到达,系统将以概率 1 1 1 保持该攻击状态(上文 第(二)部分:基本定义 中的 定义二
)。在该种情况下,由于防御方以 μ \mu μ 速率实现重构恢复,则元信道在 t t t 时刻的失效概率满足:
∀ t , t ∈ ( 0 , ∞ ) , P s i ( t ) < 1 − ( 1 − e − μ t ) = e − μ t < 1 ,
\forall t, t\in(0,\infty), P_{si}(t)<1-(1-e^{-\mu t})=e^{-\mu t}<1,
∀t,t∈(0,∞),Psi(t)<1−(1−e−μt)=e−μt<1,
表明记忆具有不确定性。在离散有干扰有记忆元信道中,动态异构冗余架构和反馈控制消记忆动作 f ( t ) f(t) f(t) 的引入使得:
∀ t , P ( y i + 1 ( t ) ∣ x i + 1 ( t ) s i ( t ) f i + 1 ( t ) ) = p i +
1 ( t ) < 1 , \forall t,
P(y_{i+1}(t)|x_{i+1}(t)s_i(t)f_{i+1}(t))=p_{i+1}(t)<1,
∀t,P(yi+1(t)∣xi+1(t)si(t)fi+1(t))=pi+1(t)<1,
其中, f ( t ) = 0 f(t)=0 f(t)=0 表示 t t t 时刻反馈消记忆事件未到达, f ( t ) = 1 f(t)=1
f(t)=1 表示 t t t
时刻反馈消记忆事件到达。由非随机扰动在攻击未到达之前具有基类型,因此编码信道容量处于一定范围(而非固定值)。引入反馈可控消记忆动作 f ( t )
f(t) f(t) 后,编码信道容量将处于可控范围 [ C S , C 0 ] [C_S,C_0] [CS,C0]。
若攻击到达与反馈恢复时间服从上述负指数分布,整个编码信道存在稳态分布,此时 C S C_S CS 为编码信道稳态时的信道容量, C 0 C_0 C0
为初始信道容量。
【前面的部分都还比较容易理解,接下来这里涉及到了一个小复杂的概念:】
设编码信道 t t t 时刻输入序列为 x ( t ) = ( x 1 ( t ) , x 2 ( t ) , ⋯ , x n ( t ) ) ∈ X
n \bold{x}(t)=(x_1(t),x_2(t),\cdots,x_n(t))\in X^n
x(t)=(x1(t),x2(t),⋯,xn(t))∈Xn,译码输出为 y ( x ( t ) ) = ( y 1 ( x 1 ( t ) ) ,
y 2 ( x 2 ( t ) ) , ⋯ , y n ( x n ( t ) ) ) ∈ Y n
\bold{y}(\bold{x}(t))=(y_1(x_1(t)),y_2(x_2(t)),\cdots,y_n(x_n(t)))\in Y^n
y(x(t))=(y1(x1(t)),y2(x2(t)),⋯,yn(xn(t)))∈Yn。从 X n X^n Xn 种输入中随机选 M =
2 n R ( t ) M=2^{nR(t)} M=2nR(t) 个序列作为码字,设 X X X 为随机编码(所有元素独立、等概率出现),对于时刻 t
t t 所对应的接受序列 y ( x ( t ) ) \bold{y}(\bold{x}(t)) y(x(t)) 给定,若存在唯一的 k ∈ [ 1 ,
2 n R ( t ) ] k\in[1,2^{nR(t)}] k∈[1,2nR(t)],使得:
( x k ( t ) , y ( x ( t ) ) ) ∈ T X Y ( n , ϵ ) ,
(\bold{x}k(t),\bold{y}(\bold{x}(t)))\in T{XY}(n,\epsilon),
(xk(t),y(x(t)))∈TXY(n,ϵ),
则将 y ( x ( t ) ) \bold{y}(\bold{x}(t)) y(x(t)) 译码为 x k ( t ) \bold{x}_k(t)
xk(t),即 F ( y ( x ( t ) ) ) = x k ( t )
F(\bold{y}(\bold{x}(t)))=\bold{x}k(t) F(y(x(t)))=xk(t),其中 T X Y ( n , ϵ )
T{XY}(n,\epsilon) TXY(n,ϵ) 表示序列对 ( x ( t ) , y ( x ( t ) ) )
(\bold{x}(t),\bold{y}(\bold{x}(t))) (x(t),y(x(t))) 是联合 ϵ \epsilon ϵ 典型序列。
【通俗一点,这里的意思就是“ 有典选典 ”: 如果能构成联合典型序列,那么就选能构成典型序列的译码方式 ,原因也很简单,因为
联合典型序列有很多好的性质 ,便于界定出错概率,典型序列的概念在这里不具体介绍,感兴趣的朋友们可以自行查阅相关资料。】
若发送消息为 x m ( t ) \bold{x}_m(t) xm(t),接收序列为 y ( x m ( t ) )
\bold{y}(\bold{x}m(t)) y(xm(t)),则很自然地,译码错误概率可以表示为:
P e m = P ( x k ( t ) ≠ x m ( t ) ∣ y ( x m ( t ) ) ) .
P{em}=P(\bold{x}_k(t)\neq\bold{x}_m(t)|\bold{y}(\bold{x}_m(t))).
Pem=P(xk(t)=xm(t)∣y(xm(t))).
我们接下来要研究的就是这个译码错误概率。
令事件:
E m ( t ) = { ( x m ( t ) , y ( x m ( t ) ) ) ∈ T X Y ( n , ϵ ) , m ∈ [ 1 , 2
n R ( t ) ] } . E_m(t)=\{(\bold{x}_m(t),\bold{y}(\bold{x}m(t)))\in
T{XY}(n,\epsilon), m\in[1,2^{nR(t)}]\}.
Em(t)={(xm(t),y(xm(t)))∈TXY(n,ϵ),m∈[1,2nR(t)]}.
如果设发送的第一个消息为 x 1 ( t ) \bold{x}_1(t) x1(t),那么译码错误概率可以被分为如下两个部分:
(1) 发送码字 x 1 ( t ) \bold{x}_1(t) x1(t) 与接收码字 y ( x 1 ( t ) )
\bold{y}(\bold{x}_1(t)) y(x1(t)) 不构成联合 ϵ \epsilon ϵ 典型序列,该事件记作 E 1 C ( t )
E_1^C(t) E1C(t)。
(2) 码字 x k ( t ) , k ≠ 1 \bold{x}_k(t), k\neq 1 xk(t),k=1 与接收码字 y ( x 1 (
t ) ) \bold{y}(\bold{x}_1(t)) y(x1(t)) 构成联合 ϵ \epsilon ϵ 典型序列。
【这两个部分我们在这里再用通俗一点的语言表达一下:第一个部分很容易理解,事件 E m E_m Em 在定义的时候就是根据联合 ϵ \epsilon ϵ
典型序列定义的,所以就取补集就可以了;第二个部分是这样的:因为另外的码字与接收码字构成联合 ϵ \epsilon ϵ
典型序列,所以根据上面“有典选典”的规则,直接选取了另外的码字,导致错了。】
第一个部分的译码错误概率为:
P ( E 1 C ( t ) ) = 1 − P ( E 1 ( t ) ) ≤ ϵ .
P(E_1^C(t))=1-P(E_1(t))\leq\epsilon. P(E1C(t))=1−P(E1(t))≤ϵ.
【上面提到联合 ϵ \epsilon ϵ 典型序列有很多好性质,这个就是根据其中一个好性质 P ( E 1 ( t ) ) ≥ 1 − ϵ
P(E_1(t))\geq1-\epsilon P(E1(t))≥1−ϵ 推出来的。】
第二个部分的译码错误概率为:
【因为 E m E_m Em 在定义的时候就是根据联合 ϵ \epsilon ϵ 典型序列定义的,所以直接取 k ≠ 1 k\neq1 k=1
时候的概率和就行了。】
P e 1 ( t ) = P ( x k ( t ) ≠ x 1 ( t ) ∣ x 1 ( t ) ) = ∑ k ≠ 1 P ( E k ( t )
∣ x 1 ( t ) ) ,
P_{e1}(t)=P(\bold{x}_k(t)\neq\bold{x}_1(t)|\bold{x}1(t))=\sum{k\neq1}P(E_k(t)|\bold{x}_1(t)),
Pe1(t)=P(xk(t)=x1(t)∣x1(t))=k=1∑P(Ek(t)∣x1(t)),
其中:
【该式就是简单根据定义直接写下来的】
P ( E k ( t ) ∣ x 1 ( t ) ) = ∑ j = 1 Y n P ( y j ( x 1 ( t ) ) ∣ x 1 ( t ) )
P ( ( x k ( t ) , y ( x 1 ( t ) ) ) ∈ T X Y ( n , ϵ ) ) = P ( ( x k ( t ) , y
( x 1 ( t ) ) ) ∈ T X Y ( n , ϵ ) ) , k ≠ 1.
P(E_k(t)|\bold{x}1(t))=\sum{j=1}{Yn}P(\bold{y}_j(\bold{x}_1(t))|\bold{x}_1(t))P((\bold{x}_k(t),\bold{y}(\bold{x}1(t)))\in
T{XY}(n,\epsilon))=P((\bold{x}_k(t),\bold{y}(\bold{x}1(t)))\in
T{XY}(n,\epsilon)), k\neq1.
P(Ek(t)∣x1(t))=j=1∑YnP(yj(x1(t))∣x1(t))P((xk(t),y(x1(t)))∈TXY(n,ϵ))=P((xk(t),y(x1(t)))∈TXY(n,ϵ)),k=1.
又当 x k ( t ) , y ( x 1 ( t ) ) , ( x k ( t ) , y ( x 1 ( t ) ) )
\bold{x}_k(t),\bold{y}(\bold{x}_1(t)),(\bold{x}_k(t),\bold{y}(\bold{x}_1(t)))
xk(t),y(x1(t)),(xk(t),y(x1(t)))均为 ϵ \epsilon ϵ 典型序列时,有:
P ( x k ( t ) ) ≤ 2 − n [ H ( X ) − ϵ ] ,
P(\bold{x}_k(t))\leq2^{-n[H(X)-\epsilon]}, P(xk(t))≤2−n[H(X)−ϵ],
P ( y ( x 1 ( t ) ) ) ≤ 2 − n [ H ( Y ) − ϵ ] ,
P(\bold{y}(\bold{x}1(t)))\leq2^{-n[H(Y)-\epsilon]}, P(y(x1(t)))≤2−n[H(Y)−ϵ],
∥ T X Y ( n , ϵ ) ∥ ≤ 2 − n [ H ( X Y ) + ϵ ] .
|T{XY}(n,\epsilon)|\leq2^{-n[H(XY)+\epsilon]}. ∥TXY(n,ϵ)∥≤2−n[H(XY)+ϵ].
【这三个式子也是根据 ϵ \epsilon ϵ 典型序列的性质来的】
因为 y ( x 1 ( t ) ) \bold{y}(\bold{x}_1(t)) y(x1(t)) 仅由 x 1 ( t )
\bold{x}_1(t) x1(t) 产生,与 x k ( t ) , k ≠ 1 \bold{x}_k(t), k\neq1
xk(t),k=1独立,因此:
P ( E k ( t ) ∣ x 1 ( t ) ) = ∑ x k ( t ) , y ( x 1 ( t ) ) , ( x k ( t ) , y
( x 1 ( t ) ) ) ∈ T X Y ( n , ϵ ) P ( x k ( t ) ) P ( y ( x 1 ( t ) ) ) , k ≠
1.
P(E_k(t)|\bold{x}1(t))=\sum{\bold{x}_k(t),\bold{y}(\bold{x}_1(t)),(\bold{x}_k(t),\bold{y}(\bold{x}1(t)))\in
T{XY}(n,\epsilon)}P(\bold{x}_k(t))P(\bold{y}(\bold{x}_1(t))), k\neq1.
P(Ek(t)∣x1(t))=xk(t),y(x1(t)),(xk(t),y(x1(t)))∈TXY(n,ϵ)∑P(xk(t))P(y(x1(t))),k=1.
结合上面三个式子,有:
【用到了互信息的性质: I ( X Y ) = H ( X ) + H ( Y ) − H ( X Y ) I(XY)=H(X)+H(Y)-H(XY)
I(XY)=H(X)+H(Y)−H(XY)】
P ( E k ( t ) ) ≤ 2 − n [ I ( X Y ) − 3 ϵ ] .
P(E_k(t))\leq2^{-n[I(XY)-3\epsilon]}. P(Ek(t))≤2−n[I(XY)−3ϵ].
对其进行求和,有:
∑ k ≠ 1 P ( E k ( t ) ) ≤ ( 2 n R ( t ) − 1 ) 2 − n [ I ( X Y ) − 3 ϵ ] .
\sum_{k\neq1}P(E_k(t))\leq(2{nR(t)}-1)2{-n[I(XY)-3\epsilon]}.
k=1∑P(Ek(t))≤(2nR(t)−1)2−n[I(XY)−3ϵ].
由于互信息即信道容量( I ( X Y ) = C ( t ) I(XY)=C(t) I(XY)=C(t)),上式可写为:
∑ k ≠ 1 P ( E k ( t ) ) ≤ 2 n [ R ( t ) − C ( t ) + 3 ϵ ] .
\sum_{k\neq1}P(E_k(t))\leq2^{n[R(t)-C(t)+3\epsilon]}.
k=1∑P(Ek(t))≤2n[R(t)−C(t)+3ϵ].
∀ η = 3 ϵ > 0 , R ( t ) < C ( t ) − η , n → ∞ \forall \eta=3\epsilon>0,
R(t)<C(t)-\eta, n\rightarrow\infty ∀η=3ϵ>0,R(t)<C(t)−η,n→∞,有:
∑ k ≠ 1 P ( E k ( t ) ) → 0. \sum_{k\neq1}P(E_k(t))\rightarrow0.
k=1∑P(Ek(t))→0.
于是在 t t t 时刻,译码错误概率:
【前文译码错误概率的两个组成部分,前一部分被 ϵ \epsilon ϵ 界定住,后一部分趋近于 0 0 0】
P e ( t ) = P ( E 1 C ( t ) ) + P e 1 ( t ) ≤ ϵ ,
P_e(t)=P(E_1^C(t))+P_{e1}(t)\leq\epsilon, Pe(t)=P(E1C(t))+Pe1(t)≤ϵ,
即译码错误概率 P e ( t ) P_e(t) Pe(t) 可为任意小。
【证毕】
(三.叁)编码信道存在第三定理
元信道、结构编码和纠错译码噪声(扰动)非随机到达,结构编码和纠错译码有记忆且记忆可消,记动态异构冗余与反馈消记忆构造后的离散有记忆编码信道为 [ P (
y ∣ x s f ) ] [P(y|xsf)] [P(y∣xsf)],其中 x , y , s , f x,y,s,f x,y,s,f
分别为输入、输出、记忆状态、反馈消记忆状态,编码信道容量为 C C C 且对任意时刻 t t t 有 ∀ t > 0 , C ( t ) ∈ [ C
S , C 0 ] \forall t>0, C(t)\in[C_S,C_0] ∀t>0,C(t)∈[CS,C0],若时刻 t t t 编码信息传输率
R ( t ) < C ( t ) R(t)<C(t) R(t)<C(t),则只要码长与编码元信道构造数 n n n 足够大,总可以在输入集合找到 M
′ = 2 n R ( t ) M’=2^{nR(t)} M′=2nR(t) 个码字组成的一个码集合,在一定译码规则下使得信道输出错误概率 P E ( t
) ≤ ϵ P_{E}(t)\leq\epsilon PE(t)≤ϵ,其中 ϵ \epsilon ϵ 为任意小正数。
(……定理结束分割线……)
上述 编码信道存在第三定理 的条件是这样的:
- 噪声(扰动)非随机到达
- 元信道、结构编码和纠错译码均有扰动和记忆
- 编码信道离散有记忆
可以看到,相较于前文 第二定理 ,该 第三定理
放松了一些条件:将无噪声无记忆结构编码和纠错译码推广至有噪声和记忆的情况下,比第二定理更加严苛,且更符合现实情况。
在这样的条件下,作者给出了 编码信道存在第三定理 的证明,证明分为两个部分:
- 讨论随机扰动的情况
- 讨论非随机扰动的情况
在这两个部分中,由于第三定理中的编译码执行体 元信道 、动态异构的 结构编码 分路器、动态异构可消记忆的 纠错译码
表决器均会遭到扰动,因此也是分别将这三个部分拆开来进行证明的。
【证明开始】
(一)首先讨论 随机扰动 的情况
(1)编译码执行体元信道的输出错误概率
章节三.贰 中已经证明了,元信道输出错误概率 P e ( t ) ≤ ϵ P_e(t)\leq\epsilon Pe(t)≤ϵ,其中 ϵ
\epsilon ϵ 为任意小正数。
(2)结构编码分路器与纠错译码表决器的物理失效问题
∀ t \forall t ∀t,随机噪声成功造成结构编码分路器或纠错译码表决器输出出错的概率 P e ( t ) P_e(t) Pe(t) 满足:
0 < P e ( t ) < 1. 0<P_e(t)<1. 0<Pe(t)<1.
不失一般性,设异构的结构编码分路器或纠错译码表决器可选余度为 n n n,且假设单个结构编码分路器或纠错译码表决器物理失效到达服从速率为 λ
\lambda λ 的负指数分布,单个结构编码分路器或纠错译码表决器修复服从速率为 μ \mu μ
的负指数分布,则单个结构编码分路器或纠错译码表决器状态与 章节三.贰 中的状态图相同,为了预期进行区分,将编码器或解码器初始状态和失效状态分别记作
s c 0 sc_0 sc0 和 s c 1 sc_1 sc1。
由此可求得稳态可用概率 P s c 0 P_{sc_0} Psc0 和失效概率 P s c 1 P_{sc_1} Psc1:
P s c 0 = μ λ + μ , P s c 1 = λ λ + μ .
P_{sc_0}=\frac{\mu}{\lambda+\mu},\quad P_{sc_1}=\frac{\lambda}{\lambda+\mu}.
Psc0=λ+μμ,Psc1=λ+μλ.
接下来的讨论分为两种情况:(1)纠错译码表决器修复速率 μ \mu μ 足够大;(2) μ , λ \mu,\lambda μ,λ 一定。
先讨论 μ \mu μ 足够大的情况:
P s c 0 = μ λ + μ → 1 − ϵ 0 . P_{sc_0}=\frac{\mu}{\lambda+\mu}\rightarrow
1-\epsilon_0. Psc0=λ+μμ→1−ϵ0.
然后讨论 μ , λ \mu,\lambda μ,λ 一定的情况:
由修复速率表达式:
U = lim t → 0 u ( t ) − u ( 0 ) t , U=\lim_{t\rightarrow
0}\frac{u(t)-u(0)}{t}, U=t→0limtu(t)−u(0),
当 n = 1 n=1 n=1 时,
U = lim t → 0 1 − e − μ t t = μ . U=\lim_{t\rightarrow 0}\frac{1-e^{-\mu
t}}{t}=\mu. U=t→0limt1−e−μt=μ.
当 μ \mu μ 与 λ \lambda λ 一定且 n > 1 n>1 n>1 时,至少有 n n n 余度同时修复以保证一个余度可用,于是有:
U ≥ lim t → 0 n ( 1 − e − μ t ) ( e − μ t ) n − 1 + O ( t ) t = n μ .
U\geq\lim_{t\rightarrow0}\frac{n(1-e^{-\mu t})(e^{-\mu
t})^{n-1}+O(t)}{t}=n\mu. U≥t→0limtn(1−e−μt)(e−μt)n−1+O(t)=nμ.
因此对于余度为 n n n 且 n n n 足够大(意味着修复速率 n μ n\mu nμ 足够大)的结构编码分路器或纠错译码表决器有:
P s c 0 = n μ λ + n μ → 1 − ϵ 0 ,
P_{sc_0}=\frac{n\mu}{\lambda+n\mu}\rightarrow 1-\epsilon_0,
Psc0=λ+nμnμ→1−ϵ0,
其中 ϵ 0 \epsilon_0 ϵ0 为任意小正数。
综上, 扰动随机 的情况下,当 纠错译码表决器修复速率 μ \mu μ 足够大或者余度 n n n
足够大时,结构编码分路器或纠错译码表决器异常概率为:
P e 1 = 1 − P s c 0 → ϵ 0 . P_{e1}=1-P_{sc_0}\rightarrow\epsilon_0.
Pe1=1−Psc0→ϵ0.
(二)再来讨论 非随机扰动 的情况
首先,在设计层面引入一些新的假设:
假设4:
对于结构编码单元,通过对其进行拟态化设计,可以将其划分为分路器和结构编码执行体。
(1) 分路器功能足够简化,只需完成状态无关的输入报文复制分发。
在采用分光器等物理器件实现时,(由于结构足够简单)假设分路器中既没有漏洞也没有后门,对于攻击等非随机扰动不具有记忆性;在采用逻辑固化/硬化/防篡改、每次处理前存储初始化等机制时,功能足够简化可进行形式化验证,假设分路器中有漏洞无后门,对于攻击等非随机扰动的记忆可消除。
(2) 结构编码单元除分路器之外的复杂功能由编码执行体实现。
结构编码执行体采用类似元信道方式实现,假设其中可以同时存在漏洞和后门,可以有记忆或无记忆,记忆可消除。
假设5:
对于纠错译码单元,通过对其进行拟态化设计,可以将其划分为表决器和纠错译码执行体。
(1) 表决器功能足够简化,只需完成状态无关的输出报文大数表决。
在采用逻辑固化/硬化/防篡改、每次处理前存储初始化等机制时,功能足够简化可进行形式化验证,假设表决器中有漏洞无后门,对于攻击等非随机扰动的记忆可消除。
(2) 纠错译码单元除表决器之外的复杂功能由纠错译码执行体实现。
纠错译码执行体采用类似元信道方式实现,假设其中可以同时存在漏洞和后门,可以有记忆或无记忆,记忆可消除。
【这两个假设主要是将结构编码或纠错译码单元分别划分为了两个部分,其中一个部分 结构足够简单
,以至于不存在后门(对于分光器等物理器件而言,甚至不存在漏洞);另一个部分 与元信道类似 ,相关出错概率分析也类似。】
(1)元信道
同样, 章节三.贰 中已经证明了,元信道输出错误概率 P e ( t ) ≤ ϵ P_e(t)\leq\epsilon Pe(t)≤ϵ,其中
ϵ \epsilon ϵ 为任意小正数。
(2)结构编码
针对结构编码,由 假设4 可知,结构编码分路器设计足够简化,有两种情况:
(1)使其成为功能单一的物理器件如分光器,仅具备复制分发功能。于是因漏洞后门问题造成其异常错误概率 P e 1 = 0 P_{e1}=0 Pe1=0;
(2)使其有漏洞无后门,对于漏洞,因复制分发在多次操作之间无需共享与状态同步,可通过逻辑固化与存储初始化使得结构编码分路器记忆可消除。
在这种情况下,对于任意时刻 t t t,噪声成功造成结构编码分路器输出出错概率
P e 1 ( t ) = p 0 n , P_{e1}(t)=\frac{p_0}{n}, Pe1(t)=np0,
其中 p 0 p_0 p0 为单个分路器输出出错概率。
当可选异构纠错译码表决器数 n n n 足够大时,有:
∀ t ∈ ( 0 , ∞ ) , P e 1 ( t ) = p 0 n → ϵ 0 , \forall t\in(0,\infty),
P_{e1}(t)=\frac{p_0}{n}\rightarrow\epsilon_0, ∀t∈(0,∞),Pe1(t)=np0→ϵ0,
结构编码分路器输出出错概率 P e 1 ( t ) P_{e1}(t) Pe1(t) 任意小。
(3)纠错译码
由 假设5 可知,纠错译码表决器设计足够简化,使其有漏洞无后门,又通过逻辑固化与逐次存储初始化使得纠错译码表决器记忆可消除。由于
元信道失效概率随机化 ,于是针对触发纠错译码表决器漏洞的噪声或扰动具有随机性;此外,造成物理失效的噪声或扰动同样具有随机性。
【如上文 第(二)部分:基本定义 中的图中可以看到,纠错译码部分在元信道之后,所以元信道失效概率也会对其造成影响,因此在这里引入了一个
元信道失效概率随机化 的概念。不难理解,通过动态异构冗余(DHR)和反馈消记忆机制,噪声不是对整个系统永久造成影响的,因此失效概率是 随机化
的。】
对任意时刻 t t t,噪声成功造成纠错译码表决器输出出错的概率:
0 < P e 2 ( t ) = p 1 p 2 < 1 , 0<P_{e_2}(t)=p_1p_2<1, 0<Pe2(t)=p1p2<1,
其中 p 1 < 1 p_1<1 p1<1 为元信道失效造成的输出异常概率, p 2 < 1 p_2<1 p2<1
为由于元信道的触发致使纠错译码表决器漏洞触发失效的概率。
接下来的讨论将分为两个部分:(1)元信道修复速率 μ \mu μ 足够大;(2) μ \mu μ 一定,异构纠错译码表决器数 n n n 足够大。
先讨论 μ \mu μ 足够大的情况:
由上文 章节三.贰证明2)部分 中的结论,元信道在 t t t 时刻失效概率满足:
∀ t ∈ ( 0 , ∞ ) , P s i ( t ) ≤ e − μ t , \forall t\in(0,\infty),
P_{si}(t)\leq e^{-\mu t}, ∀t∈(0,∞),Psi(t)≤e−μt,
因此若元信道反馈修复速率 μ \mu μ 足够大,有:
∀ t ∈ ( 0 , ∞ ) , P e 2 ( t ) = p 1 p 2 = P s i ( t ) p 2 ≤ e − μ t p 2 → ϵ 1
, \forall t\in(0,\infty), P_{e_2}(t)=p_1p_2=P_{si}(t)p_2\leq e^{-\mu
t}p_2\rightarrow\epsilon_1, ∀t∈(0,∞),Pe2(t)=p1p2=Psi(t)p2≤e−μtp2→ϵ1,
P e 2 ( t ) P_{e_2}(t) Pe2(t) 足够小。
然后讨论 μ \mu μ 一定, n n n 足够大的情况:
∀ t ∈ ( 0 , ∞ ) , P e 2 ( t ) = p 1 p 2 n ≤ e − μ t p 2 n → ϵ 1 , \forall
t\in(0,\infty), P_{e_2}(t)=\frac{p_1p_2}{n}\leq\frac{e^{-\mu
t}p_2}{n}\rightarrow\epsilon_1, ∀t∈(0,∞),Pe2(t)=np1p2≤ne−μtp2→ϵ1,
P e 2 ( t ) P_{e_2}(t) Pe2(t) 足够小。
因此,当 元信道修复速率 μ \mu μ 足够大或异构纠错译码表决器数 n n n
足够大时,结合章节三.贰中的编码信道第二定理,整个过程系统错误概率为:
∀ t ∈ ( 0 , ∞ ) , P E ( t ) = P e 1 ( t ) + P e ( t ) + P e 2 ( t ) = ϵ 0 +
ϵ + ϵ 1 = ϵ ′ , \forall t\in(0,\infty),
P_E(t)=P_{e_1}(t)+P_{e}(t)+P_{e_2}(t)=\epsilon_0+\epsilon+\epsilon_1=\epsilon’,
∀t∈(0,∞),PE(t)=Pe1(t)+Pe(t)+Pe2(t)=ϵ0+ϵ+ϵ1=ϵ′,
其中 ϵ ′ \epsilon’ ϵ′ 可以为任意小正数。
【 P e 1 ( t ) P_{e_1}(t) Pe1(t) 为结构编码(简单结构)的出错概率, P e ( t ) P_{e}(t) Pe(t)
为元信道的出错概率, P e 2 ( t ) P_{e_2}(t) Pe2(t) 为纠错译码(简单结构)的出错概率。】
【证毕】
三个定理冗长的证明过程终于结束了,如果最终有一个take home message的话那就是:
当 元信道修复速率 μ \mu μ 足够大或异构纠错译码表决器数 n n n 足够大时,整个系统的出错概率可以任意小,这里面的 μ \mu μ
足够大对应着DHR架构的动态性D, n n n 足够大对应着DHR架构的异构性H和冗余性R。
(四)总结
在这片博文的最后,我们再次强调一下,上面那么多的符号、公式、推论、定理等等都只是为了这一个结论服务的:
DHR架构可以作为实现内生安全的一种方法 。
它给出了DHR架构保证内生安全的一种充分性(但可能非必要),通俗来说就是,想要保证内生安全性质,DHR架构可行(但是DHR不一定是唯一的方法)。在诸如工程实践等不要求掌握原理的领域中,知道这一点其实已经足够让大家放心去用DHR架构了。
此外,对于书中所给出的“ 有记忆元信道随机性引理 ”以及定理证明中所用到的“ 联合典型序列
”等相关概念,本文为了行文连贯性并未着墨讨论,感兴趣的朋友们可以自行研究~
如果本文中某些表述或理解有误,欢迎各位大神批评指正。
谢谢!
学习计划安排
我一共划分了六个阶段,但并不是说你得学完全部才能上手工作,对于一些初级岗位,学到第三四个阶段就足矣~
这里我整合并且整理成了一份【282G】的网络安全从零基础入门到进阶资料包,需要的小伙伴可以扫描下方CSDN官方合作二维码免费领取哦,无偿分享!!!
如果你对网络安全入门感兴趣,那么你需要的话可以
点击这里👉网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!
①网络安全学习路线
②上百份渗透测试电子书
③安全攻防357页笔记
④50份安全攻防面试指南
⑤安全红队渗透工具包
⑥HW护网行动经验总结
⑦100个漏洞实战案例
⑧安全大厂内部视频资源
⑨历年CTF夺旗赛题解析
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









