







Webserver详解
基础知识
什么是RAII机制?
Resource Acquisition is Initialization,即资源获取即初始化;在C++中可以理解为在构造函数中申请分配资源,在析构函数中释放资源;
C++中的语言机制:当一个对象创建的时候(new一个对象)自动调用构造函数;当对象超出作用域时,自动调用析构函数;
ThreadPool(size_t threads); // 线程池构造函数;
~ThreadPool(); // 线程池析构函数;
什么是信号量?
信号量可以看成一个整型计数器,只有两种操作(P和V),P代表获取资源,P之后信号量减1;V代表释放资源,V之后信号量加1;
信号量的取值可以是任何自然数,如果初始值设置为1,并且设置为二进制信号量(只有0和1两种模式),既可以实现互斥锁机制;
如果初始值设置为资源的数量,则可以实现条件变量;
注意信号量要设置为全局变量,确保每个线程都有申请信号量的权限;
C++中信号量的函数:
sem_init:初始化一个信号量
sem_destory:销毁信号量
sem_wait:P操作,当信号量为0时,sem_wait被阻塞
sem_post:V操作,并且信号量大于0时,唤醒被sem_wait阻塞的线程
什么是互斥量?
互斥量就是互斥锁,在多线程情况下,一个线程访问临界区资源时要加锁,确保可以独占式访问;在离开临界区时要解锁,并唤醒其他等待该互斥锁的线程;(受限制的信号量,信号量为二进制信号量,初始值为1,只有0和1两个状态,加锁相当于P操作,解锁相当于V操作)
C++中互斥锁实现函数:
pthread_mutex_init:初始化互斥锁;
pthread_mutex_destory:销毁互斥锁;
pthread_mutex_lock:原子方式加锁;
pthread_mutex_unlock:原子方式解锁;
什么是条件变量?
条件变量提供了一种线程之间通知的机制,当共享数据达到某个值时,唤醒等待这个共享数据的线程;(可以认为时资源的计数器,标识了资源的数量,条件变量的底层可以用信号量和P、V操作实现)
C++中条件变量函数:
pthread_cond_init:初始化条件变量;
pthread_cond_destory:销毁条件变量;
pthread_cond_broadcast:以广播的方式唤醒所有等待该条件变量的线程;
pthread_cond_wait:等待条件变量,并且该函数调用时会加互斥锁,因为条件变量也时临界区资源,要加锁确保独占式访问;
项目中如何实现封装的?
- 将锁的创建封装在构造函数,将锁的销毁封装在析构函数,实现
RAII机制;(线程池类中有成员变量互斥锁和条件变量,在构造函数时创建,在析构函数时自动销毁) - 将重复使用的代码封装为函数;
服务器的基本框架是什么?
主要由I/O单元、逻辑单元、存储单元构成;其中每个单元通过请求队列进行通信,协同完成任务;
I/O单元:负责处理客户端连接,读写网络数据(主线程);
逻辑单元:处理业务逻辑的线程(线程池的工作线程);
存储单元:存储本地数据库;

I/O模型有哪些?你使用了哪一个I/O模型?
五种I/O模型:
- 阻塞式I/O:当应用程序执行I/O操作时,程序会一直等待操作完成,期间无法做其他任务。
- 非阻塞式I/O:应用程序提交一个I/O请求后,可以立刻执行其他任务,然后定期查看I/O操作是否完成,避免一直等待。
- 信号驱动I/O:应用程序通过向内核注册信号处理函数,当I/O完成时,内核会发送一个信号通知应用程序。
- I/O复用:应用程序使用
select()、poll()或epoll等系统调用,可以同时监控多个文件描述符,当其中任何一个文件描述符就绪时,应用程序被通知。 - 异步I/O:应用程序通过
aio_系列函数发起I/O操作,然后可以继续执行其他任务。当I/O操作完成时,应用程序会收到通知。
前4种都是同步I/O,就是应用程序发起一个I/O操作后,会一直等待直到操作完成,期间程序无法做其他任务。并且需要一直检查I/O操作的状态或者一直等待系统的通知;异步I/O模型中,应用程序发起一个I/O 操作后,可以继续执行其他任务,无需等待I/O操作完成,当I/O 完成后系统会通知应用程序。
在本项目种使用了I/O多路复用中的epoll系统调用;
事件处理模式有几种?你使用了哪一种?
- reactor模式:主线程(I/O处理单元)只负责监听文件描述符组中是否有事件发生,如果监听到事件,立刻通知工作线程(逻辑处理单元),读写数据、接受新连接和处理客户请求都在工作线程上完成;(一般由同步I/O实现)
- proactor模式:主线程和内核负责处理读写数据、接受新连接等I/O操作,工作线程仅负责业务逻辑,比如处理客户请求。(一般由异步I/O实现)
- 主从reactor模式:结合了多个Reactor实例的优势,一个主Reactor模型负责监听事件,将事件分发给多个从Reactor模型;适用于处理大量并发连接的网络应用;
本项目使用了同步I/O(epoll实现I/O复用)实现proactor模式;(因为异步I/O不成熟)
同步I/O实现proactor模式的流程是什么样的?
主线程和工作线程的任务各自是什么。(epoll实现proactor模式)
- 主线程往**
epoll内核事件表注册socket上的读就绪事件**;(epoll监视socket的文件描述符) - 主线程调用
epoll_wait等待socket上有数据可读; socket上有数据可读时,epoll_wait通知主线程,主线程从socket循环读取数据,直到没有数据可读,将读取的数据加入到请求队列(IO单元和逻辑单元通过消息队列通信)- 睡眠在请求队列上的某个工作线程被唤醒,获取到请求对象并处理客户请求;
- 将处理的请求生成的响应放到请求队列上;
- 请求队列通知主线程有数据处理(就是请求队列往
epoll内核事件表上注册socket写就绪事件) - 主线程调用
epoll_wait等待socket上有数据可写;当请求队列注册了写就绪事件后,主线程往socket上写入服务器处理客户请求的结果;
工作线程负责业务逻辑,读和写由主线程完成;
采用了哪种并发编程模式?
并发编程模式有半同步/半异步模式,领导者/追随者模式;使用了半同步/半异步模式;
同步指的是业务逻辑完全按照代码顺序执行,异步指的是程序的执行需要系统事件驱动;同步线程用于执行业务逻辑,异步线程用于处理I/O事件;异步线程监听到I/O事件之后将事件请求封装好之后放在请求队列中,请求队列通知某个工作在同步模式的工作线程来读取并处理该请求对象;
- 主线程充当异步线程;主线程负责监听
socket上的事件; - 如果有新请求,主线程将新请求得到的新连接
socket的读事件注册到epoll内核事件表;(此时epoll就可以监听socket) - 如果
socket上有读就绪事件,主线程就从socket上接受数据并封装好之后加入请求队列; - 请求队列唤醒工作线程处理任务(工作线程一直在等待条件变量,请求队列用条件变量唤醒工作线程);
- 工作线程处理请求后将生成的响应放回请求队列;
- 请求队列将
socket写就绪事件注册到epoll内核事件表,工作线程调用epoll_wait监听到该写就绪事件; - 主线程从请求队列中获取到消息之后封装为请求消息的响应写
socket;
什么叫线程池?
- 线程池在服务器运行之前就完全创建好并初始化(是静态资源)
- 当服务器运行时,如果需要线程,就从线程池里取;如果线程处理完毕,就放回线程池;
- 无需频繁的创建和销毁线程;无需释放资源,只需要将使用过的资源放回池中;
- 本质就是空间换取时间;
什么是静态成员变量,静态资源有什么特点?
静态资源在程序运行前(编译阶段)就分配了空间,对象还没创建那就就分配了自己的空间,放在全局静态区;
静态成员变量声明为static,和一般的成员变量不同,无论申请多少对象,都只有一个静态成员变量的拷贝;
静态成员变量:
- 最好是类内声明,类外初始化;
- 无论公有,私有,静态成员都可以在类外定义,但私有成员仍有访问权限;
- 非静态成员类外不能初始化;
- 静态成员数据是共享的;
静态成员函数:
- 可以直接访问静态成员变量,但是不能直接访问普通成员变量,可以通过参数传递方式访问;
- 普通成员函数可以访问普通成员变量,也可以访问静态成员变量;
- 静态成员变量没有this指针;
#include <pthread.h>
int pthread_create (pthread_t *thread_tid, //返回新生成的线程的id
const pthread_attr_t *attr, //指向线程属性的指针,通常设置为NULL
void * (*start_routine) (void *), //处理线程函数的地址
void *arg);
注意处理线程函数地址要求是静态函数,所以必须设置为静态成员函数或者静态函数;因为第三个参数的传递参数是void*,如果使用普通成员函数,就会将this默认传入,和void*不能匹配,无法通过编译;
你的线程池的工作机制是什么?
线程池的设计模式是半同步/半反应堆模式,反应堆具体为Proactor事件处理模式;
主线程为异步线程,负责监听文件描述符,构建socket新连接,如果监听的socket有读写事件,则将任务插入到请求队列中,工作线程取出任务进行处理;工作线程为同步线程,工作线程处理完成之后将响应放回请求队列,请求队列通知主线程,主线程写到socket里;
请求队列实现方式?
使用list容器实现请求队列,在队列中添加时,通过互斥锁保证线程安全,添加完成之后用信号量通知工作线程或者主线程有任务要处理;(请求队列会通知工作线程和主线程)
template<typename T>
bool threadpool<T>::append(T* request)
{
m_queuelocker.lock();
//根据硬件,预先设置请求队列的最大值
if(m_workqueue.size() > m_max_requests)
{
m_queuelocker.unlock(); // 注意解锁,否则一直占据临界资源
return false;
}
// 添加任务(在请求队列某位添加节点)
m_workqueue.push_back(request);
m_queuelocker.unlock();
// 信号量提醒有任务要处理(通知主线程或工作线程)
m_queuestat.post();
return true;
}
工作线程的实现方式?
内部访问私有成员函数run(),完成线程处理要求;
run()实现了工作线程从请求队列中取出某个任务进行处理;
- 首先等待信号量,当信号量到达时,说明请求队列有任务需要处理;
- 获得信号量之后进行加锁,从请求队列队头获取到第一个任务,然后将任务从请求队列删除,之后解锁;(请求队列是多线程共享,所以修改请求队列要加锁解锁)
- 从数据库连接池中取出一个数据库连接;
run()调用process()函数来具体处理http请求;- 处理完成后,将数据库连接放回连接池;
// worker函数充当了线程的入口函数,实现了线程池中工作线程的功能
template<typename T>
void* threadpool<T>::worker(void* arg){
// 将参数强转为线程池类,调用成员方法run()
threadpool* pool=(threadpool*)arg;
pool->run();
return pool;
}
template<typename T>
void threadpool<T>::run()
{
// 使用while循环而不是if,一直等待信号量到达
while(!m_stop)
{
// 信号量等待
m_queuestat.wait();
// 被唤醒后先加互斥锁
m_queuelocker.lock();
if(m_workqueue.empty()) // 消息队列为空,则直接退出
{
m_queuelocker.unlock();
continue;
}
// 从请求队列中取出第一个任务
// 将任务从请求队列删除,删除之后才解锁
T* request=m_workqueue.front();
m_workqueue.pop_front();
m_queuelocker.unlock();
if(!request)
continue;
// 对请求队列中的HTTP请求做出响应
// 从连接池中取出一个数据库连接
request->mysql = m_connPool->GetConnection();
// process(模板类中的方法,这里是http类)进行处理
request->process();
// 将数据库连接放回连接池
m_connPool->ReleaseConnection(request->mysql);
}
}
线程入口函数是什么?
线程入口函数一般在多线程编程中必要使用:
- 执行环境的准备:线程入口函数提供了一个明确定义的执行起点,在该函数内部可以进行线程所需的初始化操作,如设置线程的优先级、分配栈空间、处理参数等。这样可以确保线程在正确的环境中执行。
- 操作系统和线程模型规范:操作系统和多线程库通常规定线程创建时需要指定一个入口函数,以确定线程的起始位置和执行逻辑。遵循这种规范有助于编写可移植且易维护的多线程代码。
- 隔离执行环境:线程入口函数可以将线程的执行环境隔离开来,确保线程独立运行。这种隔离可以提高代码的清晰度和可维护性,避免不同线程之间的干扰。
- 封装抽象:线程入口函数可以将具体的业务逻辑与线程创建和管理分离开来,实现任务逻辑的封装与抽象。这样可以让代码更具模块化和可重用性。
不使用线程入口函数,可以使用Lambda表达式作为线程入口函数;
Epoll是怎么使用的?
什么是epoll的内核事件表?epoll内核事件表是实现epoll的核心;
-
事件表:
epoll内核事件表是一个用于存储事件信息的数据结构。当应用程序通过epoll_create系统调用创建一个epoll实例时,内核会分配一个专门用于存储文件描述符和事件信息的内核事件表。 -
事件注册:应用程序通过
epoll_ctl系统调用向epoll内核事件表注册感兴趣的事件,包括读、写、异常等事件。注册事件时需要指定相关文件描述符和事件类型。 -
事件就绪检测:
epoll_wait系统调用用于检测内核事件表中哪些文件描述符上的事件已经就绪,可以进行读写操作。当epoll_wait返回时,应用程序可以获取到已就绪的文件描述符列表。 -
高效管理多个事件:
epoll内核事件表使用红黑树和双向链表来高效地管理大量文件描述符上的事件,确保快速查找和响应就绪事件。- 红黑树:
epoll内核事件表内文件描述符信息由红黑树组织; - 双向链表:就绪事件会被添加到双向链表中,不用遍历所有文件描述符;
- 红黑树:
-
边缘触发(Edge-Triggered,ET)和水平触发(Level-Triggered,LT)模式:
epoll可以在边缘触发或水平触发两种模式下工作。在边缘触发模式ET下,只有在事件状态发生变化时才会通知应用程序;而在水平触发模式LT下,只要文件描述符上有事件就绪,每次调用epoll_wait都会返回。
流程:创建epoll内核事件表、注册事件到内核事件表上、使用epoll_wait监听内核事件表、内核事件表中有事件就绪则epoll_wait返回,通知监听的线程;
通过epoll_create创建内核事件表:(返回内核事件表的文件描述符)
// 创建内核事件表,返回内核事件表的文件描述符
#include <sys/epoll.h>
int epoll_create(int size)
操作内核事件表监控的文件描述符上的事件:注册,修改,删除;
// 注册事件到内核事件表
include <sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)
// epfd:epoll内核事件表的文件描述符;
// op:操作类型,可选择注册、修改、删除事件;
// fd:需要操作的事件的文件描述符;
// epoll_event:描述事件类型的位掩码,和需要传递的相关数据;
监听文件描述符上的事件:
epoll_wait负责监听文件描述符上是否有事件产生;
#include <sys/epoll.h>
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
返回就绪的文件描述符个数,即有多少个文件描述符上有事件就绪了。如果没有文件描述符就绪,epoll_wait将会阻塞,直到有文件描述符就绪或者超时。
调用 epoll_wait函数时获得就绪事件的个数,再通过遍历事件数组来获取具体的文件描述符和事件类型。
3种I/O多路复用系统调用的区别是什么?
三种I/O多路复用:select/poll/epoll;
- 调用函数(系统调用函数):
select和poll都是一个函数,epoll是一组函数;
- 文件描述符数量:
select通过线性表描述文件描述符集合,文件描述符有上限,一般是1024,但可以修改源码,重新编译内核,不推荐;poll是链表描述,突破了文件描述符上限,最大可以打开文件的数目;epoll通过红黑树描述,最大可以打开文件的数目,可以通过命令ulimit -n number修改,仅对当前终端有效;
- 将文件描述符从用户传给内核:
select和poll通过将所有文件描述符从用户态拷贝到内核态,每次调用都需要拷贝;epoll通过epoll_create建立一棵红黑树,通过epoll_ctl将要监听的文件描述符注册到红黑树上;(不用拷贝全部文件描述符)
- 内核判断就绪的文件描述符:
select和poll通过遍历文件描述符集合,判断哪个文件描述符上有事件发生;epoll_create时,内核除了帮我们在epoll文件系统里建了个红黑树用于存储以后epoll_ctl传来的文件描述符fd外,还会再建立一个list链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可;epoll是根据每个fd上面的**回调函数(中断函数)**判断,只有发生了事件的socket才会主动的去调用callback函数,其他空闲状态socket则不会,若是就绪事件,插入list;
- 应用程序索引就绪文件描述符:
select/poll只返回发生了事件的文件描述符的个数,若知道是哪个发生了事件,同样需要遍历;epoll返回的发生了事件的个数和结构体数组,结构体包含socket的信息,因此直接处理返回的数组即可;
- 工作模式:
select和poll都只能工作在相对低效的LT模式下;epoll则可以工作在ET高效模式,并且epoll还支持EPOLLONESHOT事件,该事件能进一步减少可读、可写和异常事件被触发的次数;
- 应用场景
- 当所有的
fd都是活跃连接,使用epoll,需要建立文件系统,红黑树和链表对于此来说,效率反而不高,不如select和poll; - 当监测的
fd数目较小,且各个fd都比较活跃,建议使用select或者poll; - 当监测的
fd数目非常大,成千上万,且单位时间只有其中的一部分fd处于就绪状态,这个时候使用epoll能够明显提升性能;
- 当所有的
什么是触发模式?Epoll有几种触发模式?
在 I/O 多路复用机制中,触发模式是指当一个文件描述符上发生事件时,系统如何通知应用程序。
三种触发模式:LT、ET、EPOLLONESHOT;select和poll工作在低效的LT模式,epoll一般工作在高效的ET模式,并且可以选择EPOLLONESHOT模式;
LT水平触发模式:epoll_wait检测到文件描述符有事件发生,则将其通知给应用程序,应用程序可以不立即处理该事件;- 当下一次调用
epoll_wait时,epoll_wait还会再次向应用程序报告此事件,直至被处理; - 只要有就绪事件就报告应用程序,常用于普通的I/O事件处理;
ET边缘触发模式:epoll_wait检测到文件描述符有事件发生,则将其通知给应用程序,应用程序必须立即处理该事件;- 必须要一次性将数据读取完,如果应用程序没有处理完所有就绪事件,且文件描述符上的状态保持不变,下一次调用
epoll_wait将不会再次返回这个文件描述符; - 只有事件发生状态变化(比如从无数据到有数据)才通知应用程序,常用于非阻塞异步I/O事件处理;
EPOLLONESHOT:- 当一个文件描述符上的事件被设置为
EPOLLONESHOT时,文件描述符只会触发一次。 - 即使文件描述符上还有未处理的事件,在处理完当前事件后需要重新设置
EPOLLONESHOT并重新添加到epoll中才能继续监听文件描述符上的事件。 - 一个线程读取某个
socket上的数据后开始处理数据,在处理过程中该socket上又有新数据可读,此时另一个线程被唤醒读取,此时出现两个线程处理同一个socket; - 我们期望的是一个
socket连接在任一时刻都只被一个线程处理,通过epoll_ctl对该文件描述符注册epolloneshot事件,一个线程处理socket时,其他线程将无法处理; - 当该线程处理完后,需要通过
epoll_ctl重置epolloneshot事件,只有重置才能继续监听文件描述符上的事件;
- 当一个文件描述符上的事件被设置为
select和poll主要支持水平触发模式,而epoll则支持水平触发和边缘触发两种模式,同时还提供了EPOLLONESHOT特性,使得epoll更加灵活和高效。
具体代码中差异:
#ifdef connfdLT // 水平触发
bytes_read = recv(m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0);
if (bytes_read <= 0)
{
return false;
}
m_read_idx += bytes_read;
return true;
#endif
#ifdef connfdET // 边缘触发
while (true) // 边缘触发模式下,要用while一直读取数据,直到读取完毕或者遇到EAGAIN或EWOULDBLOCK错误为止
{
bytes_read = recv(m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0);
if (bytes_read == -1)
{
if (errno == EAGAIN || errno == EWOULDBLOCK)
break;
return false;
}
else if (bytes_read == 0)
{
return false;
}
m_read_idx += bytes_read;
}
return true;
#endif
- 读取数据的方式不同:
- 水平触发模式下,
recv()函数只需要读取一次数据即可,因为只要有数据可读,就会一直触发 I/O 事件。 - 边缘触发模式下,需要使用
while()循环不断读取数据,直到读取完毕或者遇到EAGAIN或EWOULDBLOCK错误为止。这是因为在边缘触发模式下,只有在状态发生变化时(有新的数据可读)才会触发 I/O 事件。
- 水平触发模式下,
- 错误处理不同:
- 水平触发模式下,如果
recv()返回值小于等于 0,则直接认为读取失败,返回false。 - 边缘触发模式下,需要判断
errno是否为EAGAIN或EWOULDBLOCK,这表示暂时没有数据可读,等待下次触发事件再读取。只有在其他错误情况下,才返回false。
- 水平触发模式下,如果
- 读取缓冲区的使用不同:
- 水平触发模式下,只需要将读取的数据累加到
m_read_idx即可。 - 边缘触发模式下,需要在
while()循环中不断读取数据,直到读取完毕或遇到错误。
- 水平触发模式下,只需要将读取的数据累加到
总的来说,水平触发模式下,只需要简单地读取一次数据即可,而边缘触发模式下需要使用 while() 循环来不断读取数据,直到遇到 EAGAIN 或 EWOULDBLOCK 错误。这种差异主要源于两种模式下 I/O 事件的触发机制不同。
HTTP报文的请求报文的格式是什么?
分为4个主要部分:请求行、请求头部、空行、请求数据;
请求行:使用的请求方法、URL、注明使用的HTTP版本;例如GET /1.jpg HTTP/1.1;
请求头部:以键值对的形式,说明服务器要使用的附加信息,比如服务器的域名用HOST字段指明;
空行:用于分隔请求头和请求数据;
请求数据:任意添加其他数据;
HTTP报文的响应报文的格式是什么?
分为4个主要部分:响应头、响应行、空行、响应数据;
响应体:HTTP的版本、返回的状态码、状态消息;例如:HTTP/1.1 200 OK;
响应行:以键值对的形式来说明客户端要使用的附加信息;
空行:用于分隔响应行和响应数据;
响应数据:返回给客户端的文件资源等,可以是HTML代码;
HTTP的常见状态码有哪些?
1XX:中间状态,请求已经接受,正在处理;2XX:请求成功;200 OK:客户端请求被正常处理;206 Partial content:服务端成功处理了客户端的范围请求,并返回了对应范围的部分内容,在下载多个部分时使用(视频分段加载);
3XX:资源重定向;301 Moved Permanetly:永久重定向;302 Found:临时重定向;(在可以使用本地缓存时返回,代表客户端可以使用本地缓存)
4XX:客户端错误;400:请求报文格式错误;403:请求被服务器拒绝(权限问题,没有登录)404 Not Found:请求不存在,服务器上找不到对应资源;
5XX:服务器端错误;500:服务器在执行请求时出现错误;
你使用了有限状态机控制流程,什么是有限状态机?
有限状态机,是一种抽象的理论模型,将有限个变量描述的状态变化过程,构成封闭的有向图呈现;
有限状态机可以通过if-else,switch-case和函数指针实现;
STATE_MACHINE(){
State cur_State = type_A;
while(cur_State != type_C){
Package _pack = getNewPackage();
switch(){
case type_A:
process_pkg_state_A(_pack);
cur_State = type_B;
break;
case type_B:
process_pkg_state_B(_pack);
cur_State = type_C;
break;
}
}
}
上述有限状态机有三种基本状态:type_A、type_B、type_C,状态机通过改变cur_State实现状态转变;
有限状态机是一种高效编程方法,服务器可以根据不同状态来进行相应的处理逻辑;
服务器如何处理HTTP报文的?
- 浏览器发出HTTP请求报文;
- 主线程监听Socket上的读就绪事件,主线程创建HTTP对象来从Socket上接收数据(一直读取,直到无数据可读),并将数据读入对应的Buffer;
- 主线程将HTTP对象插入到任务队列中(请求队列),工作线程从任务队列中拿出一个HTTP请求对象进行处理;
- 工作线程拿到HTTP对象之后,调用
process_read()读取请求(读出请求头、请求行、请求体,并校验报文的完整性),然后通过主、从状态机对报文的不同部分进行解析; - 解析完成后,工作线程调用
do_request()函数生成响应报文; - 调用
process_write()将响应报文写入Buffer;然后封装好之后挂到请求队列上; - 请求队列发送信号给主线程,主线程从请求队列中取出响应消息,写入Socket中;
如何用主从状态机来对请求报文进行解析的?

主状态机三种状态分别对应解析请求报文的三个不同部分:解析请求行、解析请求头、解析消息体;
从状态机三种状态分别代表解析一行数据的状态:LINE_OK成功读取一行,LINE_BAD报文语法错误,LINE_OPEN读取的行不完整;
工作线程报文解析和生成报文响应的过程?
工作线程通过process()函数来对从任务队列中获取的任务(HTTP请求)进行处理,分别调用process_read()和process_write()来完成报文解析和报文响应两个任务;
void http_conn::process()
{
HTTP_CODE read_ret=process_read(); // 解析请求报文
//NO_REQUEST,表示请求不完整,需要继续接收请求数据
if(read_ret==NO_REQUEST)
{
// 注册并监听读事件(继续监听,看是否有数据没有传输过来)
modfd(m_epollfd,m_sockfd,EPOLLIN);
return;
}
// 根据解析请求报文的结果,调用process_write完成报文响应(生成响应报文)
bool write_ret=process_write(read_ret);
if(!write_ret)
{
close_conn();
}
// 注册并监听写事件
modfd(m_epollfd,m_sockfd,EPOLLOUT);
}
工作线程调用process_read()来解析报文;(主从状态机,每一次只处理一行)
//m_start_line是行在buffer中的起始位置,将该位置后面的数据赋给text
//此时从状态机已提前将一行的末尾字符\r\n变为\0\0,所以text可以直接取出完整的行进行解析
char* get_line(){
return m_read_buf+m_start_line;
}
http_conn::HTTP_CODE http_conn::process_read()
{
//初始化从状态机状态、HTTP请求解析结果
LINE_STATUS line_status=LINE_OK;
HTTP_CODE ret=NO_REQUEST;
char* text=0;
//这里为什么要写两个判断条件?第一个判断条件为什么这样写?
//具体的在主状态机逻辑中会讲解。
//parse_line为从状态机的具体实现(在进入主状态机前,调用从状态机,对一行进行解析,检测一行是否符合格式)
//从状态机驱动主状态机
while((m_check_state==CHECK_STATE_CONTENT && line_status==LINE_OK)||((line_status=parse_line())==LINE_OK))
{
text=get_line(); // 一行一行解析
//m_start_line是每一个数据行在m_read_buf中的起始位置
//m_checked_idx表示从状态机在m_read_buf中读取的位置
m_start_line=m_checked_idx;
//主状态机的三种状态转移逻辑
switch(m_check_state)
{
case CHECK_STATE_REQUESTLINE:
{
//解析请求行
ret=parse_request_line(text); //主状态机:解析请求头,解析成功之后会有状态转变,即从CHECK_STATE_REQUESTLINE变为CHECK_STATE_HEADER
if(ret==BAD_REQUEST)
return BAD_REQUEST;
break;
}
case CHECK_STATE_HEADER:
{
//解析请求头
ret=parse_headers(text);
if(ret==BAD_REQUEST)
return BAD_REQUEST;
//完整解析GET请求后,跳转到报文响应函数
else if(ret==GET_REQUEST)
{
return do_request();
}
break;
}
case CHECK_STATE_CONTENT:
{
//解析消息体
ret=parse_content(text);
//完整解析POST请求后,跳转到报文响应函数
if(ret==GET_REQUEST)
return do_request();
//解析完消息体即完成报文解析,避免再次进入循环,更新line_status
//从状态机驱动主状态机,所以只需要切断从状态机即可停止主状态机的循环
line_status=LINE_OPEN;
break;
}
default:
return INTERNAL_ERROR;
}
}
return NO_REQUEST;
}
从状态机逻辑是什么?
从状态机:负责读取一行数据继续解析;在HTTP报文中每一行按照\r\n来作为结束字符,空行则直接是\r\n,所以可以根据\r\n来讲报文拆分为单独的行来处理;(确保每一行格式正确,即都由\r\n结尾)
parse_line(),从buffer中读取数据,并将每一行末尾的\r\n变成\0\0,同时负责校验报文是否完整;
状态转换过程:LINE_OK, LINE_BAD, LINE_OPEN
- 如果当前字符是
\r:- 如果没有下一个字符,说明
\n没有被读进来,读取报文不完整,返回LINR_OPEN继续读取; - 如果下一个字符是
\n,则找到了\r\n,将\r\n换成\0\0,然后返回LINE_OK,代表一行读取成功; - 如果下一个字符不是
\n,代表请求报文格式错误,返回LINE_BAD;
- 如果没有下一个字符,说明
- 如果当前字符是
\n:- 如果上一个字符是
\r,则找到了\r\n,将\r\n换成\0\0,然后返回LINE_OK,代表一行读取成功;- 为什么会出现这种情况,是因为一行数据被分两次读取,第一次读取到
\r结束,第二次读取从\n开始,所以接收到第二次数据时,没有处理\n就处理到了\r;
- 为什么会出现这种情况,是因为一行数据被分两次读取,第一次读取到
- 如果上一个字符不是
\r,代表请求报文格式错误,返回LINE_BAD;
- 如果上一个字符是
- 如果没有
\r也没有\n:- 说明读取数据不完整,可能读了半行就处理,所以返回
LINE_OPEN,继续监听;
- 说明读取数据不完整,可能读了半行就处理,所以返回
// 从状态机,用于分析出一行内容
// 返回值为行的读取状态,有 LINE_OK, LINE_BAD, LINE_OPEN
http_conn::LINE_STATUS http_conn::parse_line()
{
char temp;
for (; m_checked_idx < m_read_idx; ++m_checked_idx) // 逐字节分析
{
// temp 为将要分析的字节
temp = m_read_buf[m_checked_idx];
// 如果当前是\r字符,则有可能会读取到完整行
if (temp == '\r')
{
// 下一个字符达到了 buffer 结尾,则接收不完整,需要继续接收
if ((m_checked_idx + 1) == m_read_idx)
{
return LINE_OPEN;
}
// 下一个字符是\n,将\r\n改为\0\0
else if (m_read_buf[m_checked_idx + 1] == '\n')
{
m_read_buf[m_checked_idx++] = '\0';
m_read_buf[m_checked_idx++] = '\0';
return LINE_OK;
}
// 如果都不符合,则返回语法错误
return LINE_BAD;
}
// 如果当前字符是\n,也有可能读取到完整行
// 一般是上次读取到\r就到buffer末尾了,没有接收完整,再次接收时会出现这种情况
else if (temp == '\n')
{
// 前一个字符是\r,则接收完整
if (m_checked_idx > 1 && m_read_buf[m_checked_idx - 1] == '\r')
{
m_read_buf[m_checked_idx - 1] = '\0';
m_read_buf[m_checked_idx++] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
}
// 并没有找到\r\n,需要继续接收
return LINE_OPEN;
}
主状态机的逻辑是什么?
主状态机有三个不同的状态,分别对应解析请求行、解析请求头、解析消息体;
从状态机已经将报文中每一行末尾改为了\0\0,以便于主状态机可以直接取出对应的字符串进行处理;
三种状态对应解析请求报文的三个部分:
CHECK_STATE_REQUESTLINE:解析请求行;CHECK_STATE_HEADER:解析请求头;CHECK_STATE_CONTENT:解析消息体;
状态变化:
- 初始状态:
CHECK_STATE_REQUESTLINE; - 根据初始状态,进入解析请求行的逻辑;
- 解析请求行成功,
CHECK_STATE_REQUESTLINE转入CHECK_STATE_HEADER; CHECK_STATE_HEADER解析请求头;- 解析请求头成功之后,从解析结果中判断是GET方法还是POST方法;
- 如果是GET方法,直接进入响应报文生成函数;
- 如果是POST方法,状态从
CHECK_STATE_HEADER变成CHECK_STATE_CONTENT; CHECK_STATE_CONTENT解析消息体;- 解析消息体完成后,进入响应报文生成函数;
解析请求行:
// 解析http请求行,获得请求方法,目标url及http版本号
http_conn::HTTP_CODE http_conn::parse_request_line(char *text)
{
// 在HTTP报文中,请求行用来说明请求类型,要访问的资源以及所使用的HTTP版本号,其中各个部分之间通过\t或空格分隔。
// 请求行中最先含有空格和\t任一字符的位置并返回)
// 请求行的3个组成部分由空格或者\t间隔
m_url = strpbrk(text, " \t");
// 如果没有空格或\t,则报文格式有误
if (!m_url)
{
return BAD_REQUEST;
}
// 将该位置改为\0,用于将前面数据取出(结尾\r\n也变为\0\0,统一使用\0作为间隔)
*m_url++ = '\0';
// 取出数据,并通过与GET和POST比较,以确定请求方式
char *method = text;
if (strcasecmp(method, "GET") == 0)
{
m_method = GET;
}
else if (strcasecmp(method, "POST") == 0)
{
m_method = POST;
cgi = 1; // 标记为 POST 请求
}
else
{
return BAD_REQUEST;
}
// 指向请求资源的第一个字符
m_url += strspn(m_url, " \t");
// 判断HTTP版本号
m_version = strpbrk(m_url, " \t");
if (!m_version)
{
return BAD_REQUEST;
}
*m_version++ = '\0';
m_version += strspn(m_version, " \t");
// 仅支持HTTP/1.1
if (strcasecmp(m_version, "HTTP/1.1") != 0)
{
return BAD_REQUEST;
}
// 判断请求资源中是否有http://,https://,或只是单独的/
if (strncasecmp(m_url, "http://", 7) == 0)
{
m_url += 7;
m_url = strchr(m_url, '/');
}
else if (strncasecmp(m_url, "https://", 8) == 0)
{
m_url += 8;
m_url = strchr(m_url, '/');
}
else
{
// 如果不是以http://或https://开头,则直接检查是否以 / 开头
if (!m_url || m_url[0] != '/')
{
return BAD_REQUEST;
}
}
// 当url为/时,将默认资源设置为judge.html(默认主页)
if (strlen(m_url) == 1)
{
strcat(m_url, "judge.html");
}
// 请求行处理完毕,将主状态机转移处理请求头(主状态机状态转变)
m_check_state = CHECK_STATE_HEADER;
return NO_REQUEST;
}
解析请求头:(主要是提取出字符串中的键值对)
// 解析http请求的一个头部信息
http_conn::HTTP_CODE http_conn::parse_headers(char *text)
{
// 判断是空行还是请求头(空行以\0开头)
if (text[0] == '\0') // 如果是空行,说明没有请求头
{
// 判断是 GET 还是 POST 请求,GET请求没有请求体,可以直接生成响应报文
if (m_content_length != 0)
{
// POST 请求需要跳转到消息体处理状态
m_check_state = CHECK_STATE_CONTENT;
return NO_REQUEST;
}
return GET_REQUEST;
}
// 解析请求头部连接字段(键值对)
else if (strncasecmp(text, "Connection:", 11) == 0)
{ // Connection字段,看HTTP是Keep-Alive还是非长来连接
text += 11;
// 跳过空格和\t字符
text += strspn(text, " \t");
if (strcasecmp(text, "keep-alive") == 0)
{
// 如果是长连接,则将 linger 标志设置为 true
m_linger = true;
}
}
// 解析请求头部内容长度字段
else if (strncasecmp(text, "Content-length:", 15) == 0)
{
text += 15;
text += strspn(text, " \t");
m_content_length = atol(text); // 将内容长度转换为长整型
}
// 解析请求头部 HOST 字段
else if (strncasecmp(text, "Host:", 5) == 0)
{
text += 5;
text += strspn(text, " \t");
m_host = text; // 将 HOST 字段保存到 m_host 变量中
}
else
{
printf("oop! unknow header: %s\n", text); // 未知请求头部情况下打印错误信息
}
return NO_REQUEST;
}
解析请求体:
// 判断http请求是否被完整读入
http_conn::HTTP_CODE http_conn::parse_content(char *text)
{
// 判断 buffer 中是否读取了消息体(即是否以\0结尾)
if (m_read_idx >= (m_content_length + m_checked_idx))
{
text[m_content_length] = '\0';
// 在 POST 请求中,最后为输入的用户名和密码
m_string = text;
return GET_REQUEST;
}
return NO_REQUEST;
}
状态转移的循环条件:(体现从状态机驱使主状态机)
while((m_check_state==CHECK_STATE_CONTENT && line_status==LINE_OK)||((line_status=parse_line())==LINE_OK))
m_check_state==CHECK_STATE_CONTENT && line_status==LINE_OK:表示当前状态为消息体处理状态(CHECK_STATE_CONTENT),并且上一次解析行的状态为行解析成功(LINE_OK)。这部分条件用于判断是否需要继续处理消息体内容。
line_status=parse_line())==LINE_OK:表示调用 parse_line() 函数进行行解析,且行解析的状态为行解析成功(LINE_OK)。这部分条件用于继续解析 HTTP 报文的每一行内容。(从状态机驱使主状态机,只有从状态机返回LINE_OK,才会执行主状态机的状态判断,执行对应的解析)
主从状态机流程图:

HTTP_CODE有几种?
NO_REQUEST:请求不完整;GET_REQUEST:获取到了完整的HTTP请求;NO_RESOURCE:请求资源不存在;BAD_REQUEST:HTTP请求报文语法错误;FORBIDDEN_REQUEST:请求资源没有权限访问;FILE_REQUEST:请求资源可以正常访问,跳转生成响应报文;INERNAL_ERROR:服务器内部错误;
生成HTTP响应报文的过程:
do_request()函数负责生成响应报文;
获取请求资源的过程:
- 将网站根目录和URL进行拼接,获得资源所在路径;
- 根据
stat判断资源的属性(权限判断); - 将资源通过
mmap进行映射,将普通文件映射到内存逻辑地址,提高访问速度;(本来文件资源在磁盘中)
项目中解析后的m_url有8种情况:
- /
- GET请求,跳转到
judge.html,即欢迎访问页面
- GET请求,跳转到
- /0
- POST请求,跳转到
register.html,即注册页面
- POST请求,跳转到
- /1
- POST请求,跳转到
log.html,即登录页面
- POST请求,跳转到
- /2CGISQL.cgi
- POST请求,进行登录校验
- 验证成功跳转到
welcome.html,即资源请求成功页面 - 验证失败跳转到
logError.html,即登录失败页面
- /3CGISQL.cgi
- POST请求,进行注册校验
- 注册成功跳转到
log.html,即登录页面 - 注册失败跳转到
registerError.html,即注册失败页面
- /5
- POST请求,跳转到
picture.html,即图片请求页面
- POST请求,跳转到
- /6
- POST请求,跳转到
video.html,即视频请求页面
- POST请求,跳转到
- /7
- POST请求,跳转到
fans.html,即关注页面
- POST请求,跳转到
// 网站根目录,文件夹内存放请求的资源和跳转的html文件
// 根据自己的网站根目录地址改该字符串
const char* doc_root = "/home/qgy/github/ini_tinywebserver/root"; // 网站根目录
http_conn::HTTP_CODE http_conn::do_request()
{
// 将初始化的 m_real_file 赋值为网站根目录
strcpy(m_real_file, doc_root);
int len = strlen(doc_root);
// 找到 m_url 中 / 的位置
const char *p = strrchr(m_url, '/');
// 实现登录和注册校验(cgi为1,代表是POST请求,需要登录校验,POST请求的请求体中有用户名和密码)
if (cgi == 1 && (*(p + 1) == '2' || *(p + 1) == '3'))
{
// 根据标志判断是登录检测还是注册检测
// 同步线程登录校验
// CGI 多进程登录校验
}
// 如果请求资源为 /0,表示跳转注册界面
if (*(p + 1) == '0')
{
// 字符拼接,注意内存的申请和释放,malloc申请,free释放
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/register.html");
// 将网站目录和 /register.html 进行拼接,更新到 m_real_file 中
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
// 如果请求资源为 /1,表示跳转登录界面
else if (*(p + 1) == '1')
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/log.html");
// 将网站目录和 /log.html 进行拼接,更新到 m_real_file 中
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else
{
// 如果以上均不符合,即不是登录和注册,直接将 url 与网站目录拼接
// 这里的情况是 welcome 界面,请求服务器上的一个图片
strncpy(m_real_file + len, m_url, FILENAME_LEN - len - 1);
}
// 通过 stat 获取请求资源文件信息,成功则将信息更新到 m_file_stat 结构体
// 失败返回 NO_RESOURCE 状态,表示资源不存在
if (stat(m_real_file, &m_file_stat) < 0)
{
return NO_RESOURCE;
}
// 判断文件的权限,是否可读,不可读则返回 FORBIDDEN_REQUEST 状态
if (!(m_file_stat.st_mode & S_IROTH))
{
return FORBIDDEN_REQUEST;
}
// 判断文件类型,如果是目录,则返回 BAD_REQUEST,表示请求报文有误
if (S_ISDIR(m_file_stat.st_mode))
{
return BAD_REQUEST;
}
// 以只读方式获取文件描述符,通过 mmap 将该文件映射到内存中
int fd = open(m_real_file, O_RDONLY);
m_file_address = (char *)mmap(0, m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
// 避免文件描述符的浪费和占用
close(fd);
// 表示请求文件存在,且可以访问
return FILE_REQUEST;
}
根据do_request()返回的HTTP_CODE,可以判断出如何返回响应报文;
process_write()来具体向Buffer中写入响应报文;(依次写入:响应行、响应头、空行、响应体)
// 为 HTTP 响应添加内容,使用可变参数列表方式(写入响应报文中)
bool http_conn::add_response(const char* format, ...)
{
// 如果写入内容超出 m_write_buf 大小则报错
if (m_write_idx >= WRITE_BUFFER_SIZE)
return false;
// 定义可变参数列表
va_list arg_list;
// 将变量 arg_list 初始化为传入参数
va_start(arg_list, format);
// 将数据 format 从可变参数列表写入缓冲区,返回写入数据的长度
int len = vsnprintf(m_write_buf + m_write_idx, WRITE_BUFFER_SIZE - 1 - m_write_idx, format, arg_list);
// 如果写入的数据长度超过缓冲区剩余空间,则报错
if (len >= (WRITE_BUFFER_SIZE - 1 - m_write_idx))
{
va_end(arg_list);
return false;
}
// 更新 m_write_idx 位置
m_write_idx += len;
// 清空可变参列表
va_end(arg_list);
return true;
}
// 添加状态行
bool http_conn::add_status_line(int status, const char* title)
{
return add_response("%s %d %s\r\n", "HTTP/1.1", status, title);
}
// 添加消息报头,具体的添加文本长度、连接状态和空行
bool http_conn::add_headers(int content_len)
{
add_content_length(content_len);
add_linger();
add_blank_line();
}
// 添加 Content-Length,表示响应报文的长度
bool http_conn::add_content_length(int content_len)
{
return add_response("Content-Length:%d\r\n", content_len);
}
// 添加文本类型,这里是 html
bool http_conn::add_content_type()
{
return add_response("Content-Type:%s\r\n", "text/html");
}
// 添加连接状态,通知浏览器端是保持连接还是关闭
bool http_conn::add_linger()
{
return add_response("Connection:%s\r\n", (m_linger == true) ? "keep-alive" : "close");
}
// 添加空行
bool http_conn::add_blank_line()
{
return add_response("%s", "\r\n");
}
// 添加文本 content
bool http_conn::add_content(const char* content)
{
return add_response("%s", content);
}
添加的内容:
- 状态行(响应行)
- HTTP的版本
- 根据HTTP_CODE添加响应码和响应信息;
- 响应头(键值对)
Content-Length:报文长度Conten-Type:文本类型(比如HTML、CSS)Connection:连接状态(keep-alive或者close)
- 空行
- 响应体(文本content,直接将资源文件内容写入)
// 处理写入响应
bool http_conn::process_write(HTTP_CODE ret)
{
// 根据不同的HTTP_CODE写入不同状态码和状态信息;
switch(ret)
{
// 内部错误,500
case INTERNAL_ERROR:
{
// 状态行
add_status_line(500, error_500_title);
// 消息报头
add_headers(strlen(error_500_form));
if(!add_content(error_500_form))
return false;
break;
}
// 报文语法有误,404
case BAD_REQUEST:
{
add_status_line(404, error_404_title);
add_headers(strlen(error_404_form));
if(!add_content(error_404_form))
return false;
break;
}
// 资源没有访问权限,403
case FORBIDDEN_REQUEST:
{
add_status_line(403, error_403_title);
add_headers(strlen(error_403_form));
if(!add_content(error_403_form))
return false;
break;
}
// 文件存在,200
case FILE_REQUEST:
{
add_status_line(200, ok_200_title);
// 如果请求的资源存在
if(m_file_stat.st_size != 0)
{
add_headers(m_file_stat.st_size);
// 第一个iovec指针指向响应报文缓冲区,长度指向m_write_idx
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
// 第二个iovec指针指向mmap返回的文件指针,长度指向文件大小
m_iv[1].iov_base = m_file_address;
m_iv[1].iov_len = m_file_stat.st_size;
m_iv_count = 2;
// 发送的全部数据为响应报文头部信息和文件大小
bytes_to_send = m_write_idx + m_file_stat.st_size;
return true;
}
else
{
// 如果请求的资源大小为0,则返回空白html文件
const char* ok_string = "<html><body></body></html>";
add_headers(strlen(ok_string));
if(!add_content(ok_string))
return false;
}
}
default:
return false;
}
// 除 FILE_REQUEST 状态外,其余状态只申请一个iovec,指向响应报文缓冲区
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
m_iv_count = 1;
return true;
}
响应报文分为两种:
- 一种是请求文件的存在,通过
io向量机制iovec,声明两个iovec,第一个指向m_write_buf,第二个指向mmap的地址m_file_address; - 一种是请求出错,这时候只申请一个
iovec,指向m_write_buf。
报文最终被写入了m_write_buf中;
IO向量机制iovec是什么?
I/O 向量(IOV)机制是一种用于在一次系统调用中进行多个数据块的读取或写入的方法。
定义:
struct iovec {
void *iov_base; // 数据块的起始地址
size_t iov_len; // 数据块的长度
};
使用方法:
// 读取数据:
#include <sys/uio.h>
#include <unistd.h>
#include <iostream>
int main() {
struct iovec iov[2];
char buffer1[10];
char buffer2[10];
iov[0].iov_base = buffer1;
iov[0].iov_len = sizeof(buffer1);
iov[1].iov_base = buffer2;
iov[1].iov_len = sizeof(buffer2);
ssize_t bytesRead = readv(STDIN_FILENO, iov, 2);
if (bytesRead == -1) {
perror("readv");
return 1;
}
std::cout << "Read " << bytesRead << " bytes." << std::endl;
return 0;
}
// 写入数据:
#include <sys/uio.h>
#include <unistd.h>
#include <iostream>
int main() {
struct iovec iov[2];
char buffer1[10] = "Hello, ";
char buffer2[10] = "world!";
iov[0].iov_base = buffer1;
iov[0].iov_len = sizeof(buffer1);
iov[1].iov_base = buffer2;
iov[1].iov_len = sizeof(buffer2);
ssize_t bytesWritten = writev(STDOUT_FILENO, iov, 2);
if (bytesWritten == -1) {
perror("writev");
return 1;
}
std::cout << "Written " << bytesWritten << " bytes." << std::endl;
return 0;
}
如果不使用iovec,则需要写入2次,一次写入buffer1,一次写入buffer2,要两次系统调用,增加开销;
响应报文生成之后还要做什么才能到浏览器?
- 服务器工作线程调用
process_write()生成响应报文,将报文挂载到请求队列上; - 请求队列注册
socket写就绪事件到epoll内核事件表; - 服务器主线程
epoll_wait到写就绪事件,并调用http_conn::write()函数将响应报文写到socket中,发送给浏览器端;
发送数据到客户端:
// 发送响应数据到客户端
bool http_conn::write()
{
int temp = 0;
int newadd = 0;
// 如果要发送的数据长度为0,表示响应报文为空,一般不会出现这种情况
if (bytes_to_send == 0)
{
modfd(m_epollfd, m_sockfd, EPOLLIN); // 重新注册 EPOLLIN 事件
init(); // 重置 HTTP 连接对象
return true;
}
while (1) // 字节流,按照字节发送,循环发送,直到数据都发送完
{
// 将响应报文的状态行、消息头、空行和响应正文发送给浏览器端(写socket,传入socket的文件描述符m_sockfd)
temp = writev(m_sockfd, m_iv, m_iv_count);
// 正常发送,temp 为发送的字节数
if (temp > 0)
{
bytes_have_send += temp; // 更新已发送字节数
newadd = bytes_have_send - m_write_idx; // 偏移文件 iovec 的指针
}
if (temp <= -1)
{
if (errno == EAGAIN)
{
// 判断缓冲区是否满了
if (bytes_have_send >= m_iv[0].iov_len)
{
// 不再继续发送头部信息,发送第二个 iovec 数据
m_iv[0].iov_len = 0;
m_iv[1].iov_base = m_file_address + newadd;
m_iv[1].iov_len = bytes_to_send;
}
else
{
// 继续发送第一个 iovec 头部信息的数据
m_iv[0].iov_base = m_write_buf + bytes_have_send;
m_iv[0].iov_len = m_iv[0].iov_len - bytes_have_send;
}
// 重新注册写事件
modfd(m_epollfd, m_sockfd, EPOLLOUT);
return true;
}
// 如果发送失败,但不是缓冲区问题,取消映射
unmap();
return false;
}
// 更新已发送字节数
bytes_to_send -= temp;
// 数据已全部发送完
if (bytes_to_send <= 0)
{
unmap(); // 取消映射
// 在 epoll 树上重置 EPOLLONESHOT 事件
modfd(m_epollfd, m_sockfd, EPOLLIN);
// 如果浏览器的请求为长连接
if (m_linger)
{
// 重新初始化HTTP对象
init();
return true;
}
else
{
return false;
}
}
}
}
对于非活跃连接如何处理?
非活跃连接就是建立了连接之后,长时间不发送数据,一直占用服务器资源;(占用服务器的文件描述符,epoll监视多个文件描述符,如果文件描述符数量少,监测效率高)
通过定时器处理非活跃连接;
定时事件:指固定一段时间之后触发某段代码,由该段代码处理一个事件,如从内核事件表删除事件,并关闭文件描述符,释放连接资源;
定时器:指利用结构体或其他形式,将多种定时事件进行封装。具体的,这里只是涉及一种定时事件,即定期检测非活跃连接,这里将该定时事件与连接资源封装为一个结构体定时器;
定时器容器:是指使用某种容器类数据结构,将上述多个定时器组合起来,便于对定时事件统一管理。具体的,项目中使用升序链表将所有定时器串联组织起来。
本项目中,服务器主循环为每一个连接创建一个定时器,并对每个连接定时,使用SIGALRM信号实现定时;利用升序链表将所有定时器串联起来,若主循环接收到定时通知,则在链表中依次执行定时任务;
利用alarm函数周期性地触发SIGALRM信号,信号处理函数利用管道通知主循环,主循环接收到该信号后对升序链表上所有定时器进行处理,若该段时间内没有交换数据,则将该连接关闭,释放所占用的资源。
定时器的实现过程?
使用SIGALRM信号实现定时器:
- 利用
alarm函数周期性地触发SIGALRM信号; - 信号处理函数利用管道通知主循环;
- 主循环接收到该信号后对升序链表上所有定时器进行处理;
- 若该段时间内没有交换数据,则将该连接关闭,释放所占用的资源。
定时容器:利用升序链表将所有定时器串联起来,若主循环接收到定时通知,则在链表中依次执行定时任务;
信号处理函数:信号处理函数和当前进程是两条不同的执行路线;当进程收到信号之后,操作系统就会中断进程当前执行的正常流程,转而进入信号处理函数执行操作,完成之后再返回中断的地方继续执行;
产生的问题:如果信号处理函数过于复杂,执行时间长,而信号处理函数本质就是中断处理函数,会屏蔽中断,所以信号处理函数执行时间长会导致屏蔽中断事件过长,导致有些信号可能丢失;
解决方法:将信号处理函数的逻辑写进主循环里,将信号处理函数只发送信号通知主循环;
如何监测信号事件?
对于Socket读就绪事件,我们采用了I/O多路复用,用epoll来监听Socket的文件描述符;而此时,信号处理函数利用管道通知主循环,我们也可以使用epoll来监听管道的读端的可读事件,这样epoll就可以一起监测信号事件和其他文件描述符,实现同一处理。(统一事件源)
信号处理机制:

每个进程中,都存在一张表示各种信号含义的表,内核通过设置表项中的每一个位来标识对应的信号类型;
- 信号接收:
- 内核接收到信号,将信号放进对应进程的信号队列中;
- 内核向进程发送一个中断;
- 进程接收到中断,从用户态进入内核态;
- 信号检测:
- 进程从内核态返回用户态前会进行信号检测(避免刚出去又发现信号队列中还有信号没处理,又进入内核态)
- 进程在内核态中,从睡眠状态被唤醒会进行信号检测;
- 进程陷入内核态之后,会进行信号检测;
- 检测到新信号之后,就会进入信号处理;
- 信号处理:
- (内核态)信号处理函数运行在用户态(将处理函数主逻辑写在主循环里,中断仅通知进程有信号到来),内核将内核栈的内容拷贝在用户栈上,然后修改指令寄存器将其指向信号处理函数;
- (用户态)进程返回用户态执行信号处理函数;
- (内核态)信号处理函数执行完成后,返回内核态,检查信号队列中是否还有其他信号没有处理;
- (用户态)如果所有信号处理完成,恢复内核栈,将指令寄存器执行之前中断的位置,返回用户态继续执行主进程;
如果有多个信号,就会加入信号队列中,一直被信号处理的过程循环处理;
// 信号处理函数
void sig_handler(int sig)
{
// 为保证函数的可重入性,保存原来的 errno
int save_errno = errno;
int msg = sig;
// 将信号值写入管道的写端,传输字符类型,而非整型
send(pipefd[1], (char *)&msg, 1, 0);
// 将原来的 errno 恢复
errno = save_errno;
}
// 设置信号处理函数
void addsig(int sig, void(handler)(int), bool restart = true)
{
struct sigaction sa;
memset(&sa, '\0', sizeof(sa));
// 设置信号处理函数为 handler
sa.sa_handler = handler;
if (restart)
sa.sa_flags |= SA_RESTART;
// 将所有信号添加到信号集中
sigfillset(&sa.sa_mask);
// 执行 sigaction 函数
assert(sigaction(sig, &sa, NULL) != -1);
}
// 创建管道套接字
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, pipefd);
assert(ret != -1);
// 设置管道写端为非阻塞
setnonblocking(pipefd[1]);
// 设置管道读端为 ET 非阻塞
addfd(epollfd, pipefd[0], false);
// 传递给主循环的信号值,这里只关注 SIGALRM 和 SIGTERM
addsig(SIGALRM, sig_handler, false);
addsig(SIGTERM, sig_handler, false);
// 主循环条件
bool stop_server = false;
// 超时标志
bool timeout = false;
// 每隔 TIMESLOT 时间触发 SIGALRM 信号
alarm(TIMESLOT);
// 主循环
while (!stop_server)
{
// 监测发生事件的文件描述符
int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if (number < 0 && errno != EINTR)
{
break;
}
// 轮询文件描述符
for (int i = 0; i < number; i++)
{
int sockfd = events[i].data.fd;
// 管道读端对应文件描述符发生读事件
if ((sockfd == pipefd[0]) && (events[i].events & EPOLLIN))
{
int sig;
char signals[1024];
// 从管道读端读出信号值,成功返回字节数,失败返回 -1
ret = recv(pipefd[0], signals, sizeof(signals), 0);
if (ret == -1)
{
// 处理错误
continue;
}
else if (ret == 0)
{
continue;
}
else
{
// 处理信号对应的逻辑
for (int i = 0; i < ret; ++i)
{
switch (signals[i])
{
case SIGALRM:
{
timeout = true;
break;
}
case SIGTERM:
{
stop_server = true;
break;
}
}
}
}
}
}
}
项目中设置信号函数,仅关注SIGTERM和SIGALRM两个信号。
信号通知逻辑:
- 创建管道,其中管道写端写入信号值,管道读端通过I/O复用系统监测读事件
设置信号处理函数SIGALRM(时间到了触发)和SIGTERM(kill会触发,Ctrl+C); - 通过
struct sigaction结构体和sigaction函数注册信号捕捉函数
在结构体的handler参数设置信号处理函数,具体的,从管道写端写入信号的名字; - 利用I/O复用系统监听管道读端文件描述符的可读事件;
- 信息值传递给主循环,主循环再根据接收到的信号值执行目标信号对应的逻辑代码;
为什么管道写端要非阻塞?
- 管道的写端要设置为非阻塞的原因是为了避免在写入数据时因为管道写缓冲区已满而阻塞。如果写端是阻塞的,当管道写缓冲区已满时,写操作会被阻塞,直到缓冲区有足够的空间才能继续写入。这会导致发送进程一直等待,可能导致其他操作无法进行。
阻塞会增加信号处理函数的执行时间,为什么要修改为非阻塞?
- 将管道写端设置为非阻塞可以确保发送操作不会因缓冲区满而阻塞,避免了信号处理函数的延迟执行。在处理信号时,通常希望尽快地将信号传递给接收方,而不希望因为管道写入阻塞而延迟处理。因此,将管道写端设置为非阻塞可以提高信号传递的实时性和响应性。
如果阻塞会导致定时事件失效,但是否可以容许这种情况发生?
- 是的,对于定时事件来说,有时候偶尔的一次失效并不会对整体系统造成严重影响。由于定时事件通常属于非紧急任务,一次定时事件的失效并不会导致系统运行出现严重问题。可以容忍偶尔的定时事件失效,重要的是确保系统的正常运行和其他关键操作的及时响应。
管道传递的是什么类型?switch-case 的变量冲突?
- 管道传递的是数据,具体来说是字节流。在代码中使用
send()和recv()函数通过管道进行数据传输,传输的是字节数据。 - 在
switch-case语句中,switch的变量类型一般为整型或字符型。当switch的变量为字符型时,case中可以是字符,也可以是字符对应的 ASCII 码值。因此,在处理信号传递过程中,需要根据 ASCII 码值来匹配对应的信号。确保switch-case中的值类型匹配,避免变量类型冲突。
怎么设计定时器的?
将连接资源、定时事件、超时时间封装位定时器类:
- 连接资源:客户端套接字地址、文件描述符、定时器(用于释放连接的资源)
- 定时事件:回调函数,删除非活动Socket上的注册事件,关闭Socket;
- 超时时间:设置为
定时器超时时间 = 浏览器和服务器连接时刻 + 固定时间(TIMESLOT);使用绝对时间当成超时值,alarm设置为5秒,连接超时为15秒;
// 前向声明,声明定时器类,确保在结构体中可以使用
class util_timer;
// 连接资源结构体
struct client_data
{
// 客户端socket地址
sockaddr_in address;
// socket文件描述符
int sockfd;
// 定时器
util_timer* timer;
};
// 定时器类(用链表实现定时器容器,所以设置了前后指针指向邻近的定时器)
class util_timer
{
public:
util_timer() : prev(NULL), next(NULL) {}
public:
// 超时时间
time_t expire;
// 回调函数,用于定时器超时时执行的回调操作
void (*cb_func)(client_data*);
// 连接资源,指向对应的client_data结构体
client_data* user_data;
// 前向定时器,指向前一个定时器
util_timer* prev;
// 后继定时器,指向后一个定时器
util_timer* next;
};
定时事件:当定时器超时之后,要执行的流程;从内核事件表中删除事件,关闭文件描述符,释放连接资源;
// 定时器回调函数,处理定时器超时时的操作
void cb_func(client_data *user_data)
{
// 删除非活动连接在 epoll 实例中的注册事件
epoll_ctl(epollfd, EPOLL_CTL_DEL, user_data->sockfd, 0);
assert(user_data);
// 关闭文件描述符
close(user_data->sockfd);
// 减少连接数,表明一个连接已关闭
http_conn::m_user_count--;
}
定时器容器如何设计?
用带头尾结点的升序双向链表实现,为每个连接创建一个定时器,并将其添加到链表中,并安装超时时间升序排列。执行定时任务时,将到期的定时器从链表中删除;
// 定时器容器类,用于管理定时器链表
class sort_timer_lst
{
public:
sort_timer_lst() : head(NULL), tail(NULL) {}
// 常规销毁链表
~sort_timer_lst()
{
util_timer* tmp = head;
while (tmp)
{
head = tmp->next;
delete tmp;
tmp = head;
}
}
// 添加定时器,内部调用私有成员 add_timer
/* 将目标定时器添加到链表中,添加时按照升序添加
若当前链表中只有头尾节点,直接插入
否则,将定时器按升序插入
*/
void add_timer(util_timer* timer)
{
if (!timer)
{
return;
}
if (!head)
{
head = tail = timer;
return;
}
if (timer->expire < head->expire) // 升序插入
{
timer->next = head;
head->prev = timer;
head = timer;
return;
}
add_timer(timer, head);
}
// 调整定时器,任务发生变化时,调整定时器在链表中的位置
/* 当定时任务发生变化,调整对应定时器在链表中的位置
客户端在设定时间内有数据收发,则当前时刻对该定时器重新设定时间,这里只是往后延长超时时间
被调整的目标定时器在尾部,或定时器新的超时值仍然小于下一个定时器的超时,不用调整
否则先将定时器从链表取出,重新插入链表
*/
void adjust_timer(util_timer* timer)
{
if (!timer)
{
return;
}
util_timer* tmp = timer->next;
if (!tmp || (timer->expire < tmp->expire))
{
return;
}
if (timer == head)
{
head = head->next;
head->prev = NULL;
timer->next = NULL;
add_timer(timer, head);
}
else
{
timer->prev->next = timer->next;
timer->next->prev = timer->prev;
add_timer(timer, timer->next);
}
}
// 删除定时器:将超时的定时器从链表中删除,常规双向链表删除结点
void del_timer(util_timer* timer)
{
if (!timer)
{
return;
}
if ((timer == head) && (timer == tail))
{
delete timer;
head = NULL;
tail = NULL;
return;
}
if (timer == head)
{
head = head->next;
head->prev = NULL;
delete timer;
return;
}
if (timer == tail)
{
tail = tail->prev;
tail->next = NULL;
delete timer;
return;
}
timer->prev->next = timer->next;
timer->next->prev = timer->prev;
delete timer;
}
private:
// 私有成员,被公有成员 add_timer 和 adjust_timer 调用
// 主要用于调整链表内部结点
void add_timer(util_timer* timer, util_timer* lst_head)
{
util_timer* prev = lst_head;
util_timer* tmp = prev->next;
while (tmp)
{
if (timer->expire < tmp->expire)
{
prev->next = timer;
timer->next = tmp;
tmp->prev = timer;
timer->prev = prev;
break;
}
prev = tmp;
tmp = tmp->next;
}
if (!tmp)
{
prev->next = timer;
timer->prev = prev;
timer->next = NULL;
tail = timer;
}
}
private:
// 头尾结点
util_timer* head;
util_timer* tail;
};
使用统一事件源,即文件描述符读写事件和信号事件都由epoll监听;
SIGALRM信号每次被触发,主循环中调用一次定时任务处理函数,处理链表容器中到期的定时器;
具体逻辑:
- 遍历定时器升序链表容器,从头结点开始依次处理每个定时器,直到遇到尚未到期的定时器;
- 若当前时间小于定时器超时时间,跳出循环,即未找到到期的定时器;
- 若当前时间大于定时器超时时间,即找到了到期的定时器,执行回调函数,然后将它从链表中删除,然后继续遍历;
// 定时任务处理函数,处理到期的定时器事件
void tick()
{
if (!head)
{
return;
}
// 获取当前时间
time_t cur = time(NULL);
util_timer* tmp = head;
// 遍历定时器链表
while (tmp)
{
// 链表容器为升序排列,当前时间小于定时器的超时时间,后面的定时器也没有到期
if (cur < tmp->expire)
{
break;
}
// 当前定时器到期,则调用回调函数,执行定时事件
tmp->cb_func(tmp->user_data);
// 将处理后的定时器从链表容器中删除,并重置头结点
head = tmp->next;
if (head)
{
head->prev = NULL;
}
delete tmp;
tmp = head;
}
}
具体逻辑:
- 浏览器与服务器连接时,创建该连接对应的定时器,并将该定时器添加到链表上;
- 处理异常事件时,执行定时事件,服务器关闭连接,从链表上移除对应定时器;
- 处理定时信号时,将定时标志设置为true;
- 处理读事件时,若某连接上发生读事件,将对应定时器向后移动,否则,执行定时事件;
- 处理写事件时,若服务器通过某连接给浏览器发送数据,将对应定时器向后移动,否则,执行定时事件;
// 定时处理任务函数,用于不断触发 SIGALRM 信号
void timer_handler()
{
// 处理定时器链表中到期的定时器事件
timer_lst.tick();
// 重新设置定时器,以不断触发 SIGALRM 信号
alarm(TIMESLOT);
}
// 创建排序的定时器链表
static sort_timer_lst timer_lst;
// 创建连接资源数组
client_data *users_timer = new client_data[MAX_FD];
// 超时默认为False
bool timeout = false;
// 设置定时器,定时触发 SIGALRM 信号
alarm(TIMESLOT);
while (!stop_server)
{
// 监测发生事件的文件描述符
int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if (number < 0 && errno != EINTR)
{
break;
}
for (int i = 0; i < number; i++)
{
int sockfd = events[i].data.fd;
// 处理新到的客户连接
if (sockfd == listenfd)
{
// 初始化客户端连接地址
// 接受新连接
// 创建定时器,设置超时时间
// 将定时器加入定时器链表
}
// 处理异常事件
else if (events[i].events & (EPOLLRDHUP | EPOLLHUP | EPOLLERR))
{
// 服务器端关闭连接,移除对应的定时器
}
// 处理定时器信号
else if ((sockfd == pipefd[0]) && (events[i].events & EPOLLIN))
{
// 接收到 SIGALRM 信号,标记 timeout 为 True
}
// 处理客户连接上接收到的数据
else if (events[i].events & EPOLLIN)
{
// 处理读事件,将事件放入请求队列
// 调整定时器的超时时间
}
// 处理客户连接上发送的数据
else if (events[i].events & EPOLLOUT)
{
// 处理写事件
// 调整定时器的超时时间
}
}
// 处理定时器事件,并重置 alarm 定时器以继续触发 SIGALRM 信号
if (timeout)
{
timer_handler();
timeout = false;
}
}
日志实现方式有几种?
日志:由服务器自动创建,并记录运行状态,错误信息,访问数据的文件;
同步日志:日志写入和工作线程串行执行;如果单条日志很大,会导致整个处理流程阻塞,服务器能处理的并发能力下降,在峰值时,写日志可能成为系统的瓶颈;
生产者-消费者模型:工作线程和日志线程共享一个缓冲区,工作线程往缓存区中Push消息,日志线程从缓存区中Pop消息;
阻塞队列:将生产者-消费者模型进行封装,使用循环数组实现队列,作为二者的共享缓冲区;
异步日志:将所写的日志内容先存入阻塞队列,写线程从阻塞队列中取出内容,写入日志;
单例模式:保证一个类只创建一个实例,同时提供全局访问的方法;
如何实现日志系统?
本项目使用单例模式创建日志系统,对服务器运行状态、错误信息、访问数据记录,并使用异步写入,将生产者-消费者模型封装为阻塞队列,创建一个写线程,工作线程将要写的内容Push进阻塞队列,写线程从阻塞队列中Pop出数据,写入日志文件;
日志系统分为两部分,一是单例模式和阻塞队列的定义,二是日志类的定义和使用;
单例模式有几种实现方式,你使用了哪一种?为什么?
单例模式:保证一个类仅有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。
两种经典的模式:懒汉模式和饿汉模式;懒汉模式是不用的时候就不去初始化,即只有在第一次被使用时才会被初始化,饿汉模式是迫不及待进行初始化,即在程序运行时立即初始化;
懒汉模式的实现方式?
线程安全懒汉模式——双检测锁模式:
// 单例模式类
class single {
private:
// 私有静态指针变量指向唯一实例
static single *p;
// 静态锁,用于保证线程安全
static pthread_mutex_t lock;
// 私有化构造函数
single() {
pthread_mutex_init(&lock, NULL);
}
~single() {}
public:
// 公有静态方法获取实例
static single* getinstance();
};
// 初始化静态锁(在类外初始化静态变量)
pthread_mutex_t single::lock;
// 初始化静态指针(在类外初始化静态变量)
single* single::p = NULL;
// 获取单例实例的静态方法(静态方法也在类外初始化,构造方法为私有,在类外不能被调用)
single* single::getinstance() {
if (NULL == p) {
pthread_mutex_lock(&lock); // 加锁
if (NULL == p) {
// 构造函数调用时也加锁,所以是双检测锁
p = new single; // 实例化对象(getinstance方法在类内,可以调用构造函数)
}
pthread_mutex_unlock(&lock); // 解锁
}
return p;
}
什么是双检测锁?
- 先检查是否创建了实例,如果创建,则返回;
- 如果没有实例,则加锁;
- 加锁之后,再检查是否创建了实例,如果创建,则释放锁后返回;
- 如果没有创建,则创建实例后释放锁,然后返回;
为什么要用双检测,只检测一次不行吗?
- 性能消耗大:如果只检测一次,在每次调用获取实例的方法时,都需要加锁,这将严重影响程序性能。双层检测可以有效避免这种情况,仅在第一次创建单例的时候加锁,其他时候都不再符合NULL == p的情况,直接返回已创建好的实例。
- 线程安全:如果在加锁之后不进行第二次检测,可能在加锁的过程中,已经有线程创建了实例,导致加锁之后直接又创建了实例,程序中有两个实例,不符合单例模式;
线程安全懒汉模式——局部静态变量:
// C++11之前的版本:
class single {
private:
static pthread_mutex_t lock; // 静态互斥锁,确保多线程安全
single() {
pthread_mutex_init(&lock, NULL);
}
~single() {}
public:
static single* getinstance(); // 静态方法,返回单例对象指针
};
pthread_mutex_t single::lock; // 静态变量定义锁
// 获取单例实例的静态方法
single* single::getinstance() {
pthread_mutex_lock(&lock); // 加锁
static single obj; // 静态局部变量,避免了多线程竞争
pthread_mutex_unlock(&lock); // 解锁
return &obj; // 返回单例对象的指针
}
// C++11之后的版本
class single {
private:
single() {} // 私有化构造函数
~single() {} // 私有化析构函数
public:
static single* getinstance(); // 静态方法,返回单例对象指针
};
single* single::getinstance() {
static single obj; // 静态局部变量,避免了多线程竞争
return &obj; // 返回单例对象的指针
}
饿汉模式的实现方式?
饿汉模式不需要锁就可以实现线程安全,因为在程序运行时就定义了对象,并对其初始化(静态指针成员变量,指向唯一实例)。之后不论哪个线程调用成员函数getinstance()都返回的是一个对象的指针(不会有创建对象过程),所以线程是安全的(只是获取指针,不会创建对象)
class single {
private:
static single* p; // 静态指针成员变量,指向唯一的实例
single() {} // 私有构造函数,防止外部实例化对象
~single() {} // 私有析构函数
public:
static single* getinstance(); // 静态方法,返回单例实例指针
};
single* single::p = new single(); // 在类外部定义并初始化静态指针成员变量p
single* single::getinstance() {
return p; // 返回单例实例指针
}
// 测试方法
int main(){
single *p1 = single::getinstance(); // 获取单例实例指针
single *p2 = single::getinstance(); // 再次获取单例实例指针
if (p1 == p2) {
cout << "same" << endl; // 如果两个指针相同,则输出 "same",表示是同一个实例
}
system("pause"); // 暂停屏幕显示,等待用户输入后才会退出
return 0;
}
饿汉模式虽好,但其存在隐藏的问题,在于非静态对象(函数外的static对象)在不同编译单元中的初始化顺序是未定义的。如果在初始化完成之前调用 getInstance() 方法会返回一个未定义的实例。
为什么选择单例模式实现日志?
- 全局单一实例:日志模块要被多个模块共享和调用,如果系统中有多个日志实例,会导致多个模块创建和管理的日志对象不是一个,导致混乱和不一致;(日志写入重复、日志级别不一致、日志输出格式不一致、日志存储位置不一致、日志配置不一致)
- 易于访问:全局只有一个日志实例,任何模块都可以根据单例模式提供的全局访问点来获取日志实例,不会产生混乱;
- 节省资源:日志对象的创建和销毁需要消耗一定的资源,通过单例模式可以在程序运行期间只创建一个日志实例,节省了资源开销;
- 避免重复设置:日志对象通常要进行初始化操作,比如设置日志级别、输出文件路径等,通过单例模式可以保证这些初始化只在第一次创建日志对象时进行;
- 线程安全:在多线程环境下,如果多个线程同时尝试创建对象,可能发生竞态条件,导致对象状态不一致或者数据错乱;
什么是线程安全?
- 线程安全:多线程环境下,当多个线程同时访问某个类或对象时,如果该类在不需要额外同步措施的情况下能够保持数据一致性和正确性,那么该类就是线程安全的。
- 线程不安全:在多线程环境下,如果多个线程访问某个类或对象时,缺乏适当的同步机制或者竞态条件,导致数据状态异常、逻辑错误或者内存泄漏等问题,那么该类就是线程不安全的。
生产者-消费者模式实现?
- 条件变量实现线程之间的通知机制;当共享数据达到某个值时,唤醒等待这个共享数据的线程;
- 使用条件变量之前要加锁:多线程访问,条件变量是共享资源,所以要加锁,使得每个线程互斥访问共享资源;
条件变量API:
pthread_cond_init函数:用于初始化条件变量;pthread_cond_destory函数:销毁条件变量;pthread_cond_broadcast函数:以广播的方式唤醒所有等待目标条件变量的线程;pthread_cond_wait函数:- 用于等待目标条件变量。该函数调用时需要传入
mutex参数(加锁的互斥锁) ; - 函数执行时,先把调用线程放入条件变量的请求队列,然后将互斥锁
mutex解锁; - 当函数成功返回为0时,表示重新抢到了互斥锁,互斥锁会再次被锁上, 也就是说函数内部会有一次解锁和加锁操作.
- 用于等待目标条件变量。该函数调用时需要传入
pthread _mutex_lock(&mutex) // 使用条件变量时加锁
while(线程执行的条件是否成立){
pthread_cond_wait(&cond, &mutex); // 等待某个条件变量通知
}
pthread_mutex_unlock(&mutex);
pthread_cond_wait执行后的内部操作分为以下几步:
- 将线程放在条件变量的请求队列后,内部解锁;
- 线程等待被
pthread_cond_broadcast信号唤醒或者pthread_cond_signal信号唤醒,唤醒后去竞争锁; - 若竞争到互斥锁,内部再次加锁;
为什么pthread_cond_wait()内部有一次解锁和加锁操作?
- 如果被条件变量阻塞,阻塞之后依旧还是持有锁,要解锁来使得其他线程可以访问,不解锁,其他线程无法访问公有资源
为什么要把调用线程放入条件变量的请求队列后再解锁?
- 请求队列是共享资源,所以插入线程时要在锁内,所以要放入条件变量的请求队列之后再解锁;
为什么要解锁之后还加锁?
- 将线程放在条件变量的请求队列后,将其解锁,此时等待被唤醒,若成功竞争到互斥锁,再次加锁;
为什么判断线程执行的条件用while而不是if?
- 一般来说,在多线程资源竞争的时候,在一个使用资源的线程里面(消费者)判断资源是否可用,不可用,便调用
pthread_cond_wait; - 在另一个线程里面(生产者)如果判断资源可用的话,则调用
pthread_cond_signal发送一个资源可用信号。
在wait成功之后,资源就一定可以被使用么?为什么要使用while而不是if?
- 答案是否定的,如果同时有两个或者两个以上的线程正在等待此资源,wait返回后,资源可能已经被使用了。
- 可能很多个线程一直竞争该资源,而信号发出只有一个资源可用,只有速度快的线程才能竞争获胜,获得互斥锁,然后加锁,消耗资源,解锁;
- 而其他没有竞争成功的线程,只能继续等待,继续等待,所以要使用
while,确保竞争失败不回去访问不存在的资源;
while(resource == FALSE)
pthread_cond_wait(&cond, &mutex);
生产者消费者模型:
process_msg相当于消费者,enqueue_msg相当于生产者,struct msg* workq作为缓冲队列。
生产者和消费者是互斥关系,两者对缓冲区访问互斥,同时生产者和消费者又是一个相互协作与同步的关系,只有生产者生产之后,消费者才能消费。
#include <pthread.h>
struct msg {
struct msg *m_next;
/* value...*/
};
struct msg* workq;
pthread_cond_t qready = PTHREAD_COND_INITIALIZER;
pthread_mutex_t qlock = PTHREAD_MUTEX_INITIALIZER;
void process_msg() {
struct msg* mp;
for (;;) {
pthread_mutex_lock(&qlock);
// 这里需要用while,而不是if,因为条件变量可能出现虚假唤醒,即唤醒之后没有竞争过其他线程,还要重新阻塞睡眠等待
while (workq == NULL) {
pthread_cond_wait(&qready, &qlock);
}
mp = workq;
workq = mp->m_next;
pthread_mutex_unlock(&qlock);
/* 现在处理消息 mp */
}
}
void enqueue_msg(struct msg* mp) {
pthread_mutex_lock(&qlock);
mp->m_next = workq;
workq = mp;
pthread_mutex_unlock(&qlock);
/**
* 在另一个线程在 signal 之前,执行了 process_msg,刚好把 mp 元素拿走
*/
pthread_cond_signal(&qready);
/**
* 现在执行 signal,在 pthread_cond_wait 等待的线程被唤醒,
* 但是 mp 元素已经被另一个线程拿走,所以 workq 变为 NULL,
* 因此需要继续等待
*/
}
阻塞队列如何实现?
阻塞队列类中封装了生产者-消费者模型;使用循环数组实现了队列,作为生产者和消费者的缓存区;
class block_queue {
private:
int m_max_size; // 队列最大大小
T *m_array; // 存放数据的数组
int m_size; // 当前队列大小
int m_front; // 队列前指针
int m_back; // 队列后指针
pthread_mutex_t *m_mutex; // 互斥锁
pthread_cond_t *m_cond; // 条件变量
public:
// 初始化队列
block_queue(int max_size = 1000) {
if (max_size <= 0) {
exit(-1);
}
// 创建循环数组及初始化相关变量
m_max_size = max_size;
m_array = new T[max_size];
m_size = 0;
m_front = -1;
m_back = -1;
// 创建互斥锁和条件变量
m_mutex = new pthread_mutex_t;
m_cond = new pthread_cond_t;
pthread_mutex_init(m_mutex, NULL);
pthread_cond_init(m_cond, NULL);
}
// 添加元素到队列
bool push(const T &item) {
pthread_mutex_lock(m_mutex);
if (m_size >= m_max_size) {
pthread_cond_broadcast(m_cond); // 唤醒所有在条件变量上等待的线程
pthread_mutex_unlock(m_mutex);
return false;
}
// 放入循环数组对应位置
m_back = (m_back + 1) % m_max_size;
m_array[m_back] = item;
m_size++;
pthread_cond_broadcast(m_cond); // 唤醒所有在条件变量上等待的线程
pthread_mutex_unlock(m_mutex);
return true;
}
// 从队列中取出元素
bool pop(T &item) {
pthread_mutex_lock(m_mutex);
while (m_size <= 0) {
// 等待条件变量,多个消费者时应使用 while
if (0 != pthread_cond_wait(m_cond, m_mutex)) {
pthread_mutex_unlock(m_mutex);
return false;
}
}
m_front = (m_front + 1) % m_max_size;
item = m_array[m_front];
m_size--;
pthread_mutex_unlock(m_mutex);
return true;
}
// 增加了超时处理,未使用到
bool pop(T &item, int ms_timeout) {
struct timespec t = {0, 0};
struct timeval now = {0, 0};
gettimeofday(&now, NULL);
pthread_mutex_lock(m_mutex);
if (m_size <= 0) {
// 设置超时时间
t.tv_sec = now.tv_sec + ms_timeout / 1000;
t.tv_nsec = (ms_timeout % 1000) * 1000;
if (0 != pthread_cond_timedwait(m_cond, m_mutex, &t)) {
pthread_mutex_unlock(m_mutex);
return false;
}
}
if (m_size <= 0) {
pthread_mutex_unlock(m_mutex);
return false;
}
m_front = (m_front + 1) % m_max_size;
item = m_array[m_front];
m_size--;
pthread_mutex_unlock(m_mutex);
return true;
}
};
#endif
日志的流程是什么样的?

日志文件:
- 局部变量的懒汉模式获取实例;
- 生成日志文件,并判断同步和异步写入方式;
- 同步
- 判断是否分文件
- 直接格式化输出内容,将信息写入日志文件(同步,直接写入日志)
- 异步
- 判断是否分文件
- 格式化输出内容,将内容写入阻塞队列,创建一个写线程,从阻塞队列取出内容写入日志文件(异步,先写入阻塞队列)
- 同步
日志类的实现?
通过局部变量的懒汉单例模式创建日志实例,对其进行初始化生成日志文件后,格式化输出内容,并根据不同的写入方式,完成对应逻辑,写入日志文件。
日志类的方法:
- 公有的实例获取方法
- 初始化日志文件方法
- 异步日志写入方法,内部调用私有异步方法
- 内容格式化方法
- 刷新缓冲区
- …
class Log {
public:
// 获取日志类的实例,使用局部静态变量实现懒汉单例模式(C++11无需额外加锁)
static Log *get_instance() {
static Log instance;
return &instance;
}
// 初始化日志模块,设置日志文件名、日志缓冲区大小、切分行数、最大队列大小等参数
bool init(const char *file_name, int log_buf_size = 8192, int split_lines = 5000000, int max_queue_size = 0);
// 异步写日志的公有方法,调用私有方法 async_write_log
static void *flush_log_thread(void *args) {
Log::get_instance()->async_write_log();
}
// 写入日志,参数包括日志级别和格式化字符串
void write_log(int level, const char *format, ...);
// 强制刷新缓冲区
void flush(void);
private:
Log();
virtual ~Log();
// 异步写日志方法,从阻塞队列中取出日志内容写入文件
void *async_write_log() {
string single_log;
// 从阻塞队列中取出一条日志内容,写入文件
while (m_log_queue->pop(single_log)) {
m_mutex.lock();
fputs(single_log.c_str(), m_fp);
m_mutex.unlock();
}
}
private:
char dir_name[128]; // 路径名
char log_name[128]; // log文件名
int m_split_lines; // 日志最大行数
int m_log_buf_size; // 日志缓冲区大小
long long m_count; // 日志行数记录
int m_today; // 按天分文件,记录当前时间是那一天
FILE *m_fp; // 打开 log 的文件指针
char *m_buf; // 要输出的内容
block_queue<string> *m_log_queue; // 阻塞队列
bool m_is_async; // 是否异步标志位
locker m_mutex; // 同步类
};
// 宏定义用于其他文件中输出不同级别的日志
#define LOG_DEBUG(format, ...) Log::get_instance()->write_log(0, format, __VA_ARGS__)
#define LOG_INFO(format, ...) Log::get_instance()->write_log(1, format, __VA_ARGS__)
#define LOG_WARN(format, ...) Log::get_instance()->write_log(2, format, __VA_ARGS__)
#define LOG_ERROR(format, ...) Log::get_instance()->write_log(3, format, __VA_ARGS__)
#endif
日志类中的方法都不会被其他程序直接调用,末尾的四个可变参数宏提供了其他程序的调用方法。
前述方法对日志等级进行分类,包括DEBUG,INFO,WARN和ERROR四种级别的日志。
当使用单例模式获取唯一的日志类时,可以通过调用初始化函数(例如init()函数)来生成日志文件。在初始化函数中,根据队列大小是否设置来确定写入方式是同步还是异步:
- 如果队列大小为0,表示同步写入方式。在这种情况下,日志会立即被写入文件,这可能会带来一定的性能开销,因为写入文件是一个相对较慢的操作,但是可以保证日志的实时性和有序性。
- 如果队列大小不为0,表示异步写入方式。这种方式下,日志会被先写入到一个队列中,然后异步的从队列中取出日志并写入文件,相比同步方式可以提高程序的性能,因为日志的写入不会阻塞主线程,但可能会导致日志的顺序和实时性变差。
// 异步需要设置阻塞队列的长度,同步不需要设置
bool Log::init(const char *file_name, int log_buf_size, int split_lines, int max_queue_size) {
// 如果设置了 max_queue_size,则设置为异步写日志
if (max_queue_size >= 1) {
// 设置为异步写日志模式
m_is_async = true;
// 创建并设置阻塞队列的长度
m_log_queue = new block_queue<string>(max_queue_size);
pthread_t tid;
// 创建线程异步写日志,使用 flush_log_thread 作为回调函数
pthread_create(&tid, NULL, flush_log_thread, NULL);
}
// 设置日志的缓冲区大小
m_log_buf_size = log_buf_size;
m_buf = new char[m_log_buf_size];
memset(m_buf, '\0', sizeof(m_buf));
// 设置日志的最大行数
m_split_lines = split_lines;
// 获取当前时间
time_t t = time(NULL);
struct tm *sys_tm = localtime(&t);
struct tm my_tm = *sys_tm;
// 根据 file_name 构建完整的 log 文件名
const char *p = strrchr(file_name, '/');
char log_full_name[256] = {0};
// 若 file_name 中没有路径分隔符 '/', 直接以时间+文件名作为日志名
if (p == NULL) {
snprintf(log_full_name, 255, "%d_%02d_%02d_%s", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, file_name);
} else {
// 获取文件名和文件夹路径
strcpy(log_name, p + 1);
strncpy(dir_name, file_name, p - file_name + 1);
// 构建完整的日志文件路径及文件名
snprintf(log_full_name, 255, "%s%d_%02d_%02d_%s", dir_name, my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, log_name);
}
m_today = my_tm.tm_mday;
// 打开日志文件
m_fp = fopen(log_full_name, "a");
if (m_fp == NULL) {
return false; // 打开文件失败
}
return true; // 初始化成功
}
日志如何分级,如何分文件逻辑?
日志的分级:(实际使用了Debug,Info和Error三种)
Debug,调试代码时的输出,在系统实际运行时,一般不使用。Warn,这种警告与调试时终端的warning类似,同样是调试代码时使用。Info,报告系统当前的状态,当前执行的流程或接收的信息等。Error和Fatal,输出系统的错误信息。
超行、按天分文件逻辑:
- 日志写入前会判断当前
day是否为创建日志的时间,行数是否超过最大行限制- 若为创建日志时间,写入日志,否则按当前时间创建新日志文件
log,更新创建时间和行数; - 若行数超过最大行限制,在当前日志的末尾加
count/max_lines为后缀创建新日志文件log;
- 若为创建日志时间,写入日志,否则按当前时间创建新日志文件
格式化时间+格式化内容:
void Log::write_log(int level, const char *format, ...) {
struct timeval now = {0, 0};
gettimeofday(&now, NULL);
time_t t = now.tv_sec;
struct tm *sys_tm = localtime(&t);
struct tm my_tm = *sys_tm;
char s[16] = {0};
// 根据日志级别设置日志前缀
switch (level) {
case 0:
strcpy(s, "[debug]:");
break;
case 1:
strcpy(s, "[info]:");
break;
case 2:
strcpy(s, "[warn]:");
break;
case 3:
strcpy(s, "[error]:");
break;
default:
strcpy(s, "[info]:");
break;
}
m_mutex.lock();
// 更新日志行数
m_count++;
// 如果是新的一天或者超过最大行数限制
if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0) {
char new_log[256] = {0};
fflush(m_fp);
fclose(m_fp);
char tail[16] = {0};
// 格式化日期部分的日志名
snprintf(tail, 16, "%d_%02d_%02d_", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday);
// 如果不是今天,则创建新的日志文件,更新日期和行数计数器
if (m_today != my_tm.tm_mday) {
snprintf(new_log, 255, "%s%s%s", dir_name, tail, log_name);
m_today = my_tm.tm_mday;
m_count = 0;
} else {
// 超过最大行数限制,在原日志名后加后缀
snprintf(new_log, 255, "%s%s%s.%lld", dir_name, tail, log_name, m_count / m_split_lines);
}
m_fp = fopen(new_log, "a");
}
m_mutex.unlock();
va_list valst;
va_start(valst, format);
string log_str;
m_mutex.lock();
// 格式化时间和内容
int n = snprintf(m_buf, 48, "%d-%02d-%02d %02d:%02d:%02d.%06ld %s ",
my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday,
my_tm.tm_hour, my_tm.tm_min, my_tm.tm_sec, now.tv_usec, s);
int m = vsnprintf(m_buf + n, m_log_buf_size - 1, format, valst);
m_buf[n + m] = '\n';
m_buf[n + m + 1] = '\0';
log_str = m_buf;
m_mutex.unlock();
if (m_is_async && !m_log_queue->full()) {
m_log_queue->push(log_str);
} else {
m_mutex.lock();
fputs(log_str.c_str(), m_fp);
m_mutex.unlock();
}
va_end(valst);
}
数据库连接池如何实现的?
系统访问数据库的流程:系统创建数据库连接,完成数据库操作,然后系统断开数据库连接。
如果不使用池,每一个HTTP连接都要创建和销毁数据库连接,开销大,耗时长,并且对数据库造成安全隐患;
如果在程序初始化时,就集中创建多个数据库连接,将它们集中管理,供程序使用,可以保证较快的数据库读写速度,更加安全可靠;
使用单例模式和链表创建数据库连接池,实现对数据库连接资源的复用;
项目中的数据库模块分为两部分:
- 数据库连接池的定义,使用单例模式和链表创建数据库连接池;
- 利用连接池完成登录和注册的校验功能:具体的,工作线程从数据库连接池取得一个连接,访问数据库中的数据,访问完毕后将连接交还连接池。
利用单例模式(懒汉模式)创建数据库连接池:
class connection_pool {
public:
// 获取唯一实例的静态方法
static connection_pool *GetInstance();
private:
// 私有构造函数和析构函数,确保无法在外部实例化和销毁对象
connection_pool();
~connection_pool();
};
// 实现获取唯一实例的静态方法
connection_pool* connection_pool::GetInstance() {
static connection_pool connPool; // 在首次调用时创建唯一实例
return &connPool; // 返回指向唯一实例的指针
}
确保程序运行时,只有一个数据库连接池的实例;
连接池的代码实现:
连接池的功能:初始化连接池、获取连接池中的连接、释放连接到连接池中、销毁连接池;(销毁连接池通过RAII机制来自动释放)
初始化连接池:
// 构造函数
connection_pool::connection_pool() {
this->CurConn = 0; // 当前连接数初始化为0
this->FreeConn = 0; // 空闲连接数初始化为0
}
// 析构函数,使用RAII机制销毁连接池
connection_pool::~connection_pool() {
DestroyPool(); // 销毁连接池
}
// 初始化连接池
void connection_pool::init(string url, string User, string PassWord, string DBName, int Port, unsigned int MaxConn) {
// 初始化数据库连接信息
this->url = url;
this->Port = Port;
this->User = User;
this->PassWord = PassWord;
this->DatabaseName = DBName;
// 创建 MaxConn 条数据库连接
for (int i = 0; i < MaxConn; i++) {
MYSQL *con = NULL;
con = mysql_init(con); // 初始化 MySQL 连接
if (con == NULL) {
cout << "Error: " << mysql_error(con);
exit(1);
}
con = mysql_real_connect(con, url.c_str(), User.c_str(), PassWord.c_str(), DBName.c_str(), Port, NULL, 0);
if (con == NULL) {
cout << "Error: " << mysql_error(con);
exit(1);
}
// 更新连接池和空闲连接数量
connList.push_back(con); // 将连接加入连接池
++FreeConn; // 空闲连接数加1
}
// 将信号量初始化为最大连接次数
reserve = sem(FreeConn); // 信号量初始化为当前空闲连接数
this->MaxConn = FreeConn; // 最大连接数设置为当前空闲连接数
}
获取、释放连接:
线程数量大于数据库连接数量时,使用信号量进行同步,每次取出连接,信号量原子减1,释放连接原子加1,若连接池内没有连接了,则阻塞等待。
// 从数据库连接池中获取一个可用连接,更新使用和空闲连接数
MYSQL* connection_pool::GetConnection() {
MYSQL *con = NULL;
if (connList.empty()) { // 如果连接池为空,则返回空
return NULL;
}
reserve.wait(); // 此处的 reserve 是一个信号量,原子减1,为0则等待
lock.lock(); // 加锁
con = connList.front(); // 取出连接池中的第一个连接
connList.pop_front(); // 移除已取出的连接
//--FreeConn; // 鸡肋,没有起到实质作用
//++CurConn; // 鸡肋,没有起到实质作用
lock.unlock(); // 解锁
return con; // 返回获取的连接
}
// 释放当前使用的连接
bool connection_pool::ReleaseConnection(MYSQL *con) {
if (NULL == con) {
return false;
}
lock.lock(); // 加锁
connList.push_back(con); // 将连接放回连接池中
++FreeConn; // 空闲连接数加1
//--CurConn; // 当前连接数减1
lock.unlock(); // 解锁
reserve.post(); // 释放连接,信号量原子加1
return true; // 释放成功返回 true
}
销毁连接池:
通过迭代器遍历连接池链表,关闭对应数据库连接,清空链表并重置空闲连接和现有连接数量。
// 销毁数据库连接池
void connection_pool::DestroyPool() {
lock.lock(); // 加锁
if (connList.size() > 0) { // 检查连接池是否非空
// 通过迭代器遍历连接池,关闭数据库连接
list<MYSQL*>::iterator it;
for (it = connList.begin(); it != connList.end(); ++it) {
MYSQL *con = *it;
mysql_close(con); // 关闭数据库连接
}
CurConn = 0; // 当前连接数置为0
FreeConn = 0; // 空闲连接数置为0
connList.clear(); // 清空连接池
lock.unlock(); // 解锁
} else {
lock.unlock(); // 如果连接池为空,直接解锁
}
}
利用RAII机制释放数据库连接:
class connectionRAII {
public:
// 构造函数,接受一个指向 MYSQL 指针的指针和连接池实例作为参数
connectionRAII(MYSQL **con, connection_pool *connPool);
// 析构函数,用于释放数据库连接
~connectionRAII();
private:
MYSQL *conRAII; // 指向数据库连接的指针
connection_pool *poolRAII; // 指向连接池实例的指针
};
// 构造函数实现
connectionRAII::connectionRAII(MYSQL **SQL, connection_pool *connPool) {
*SQL = connPool->GetConnection(); // 从连接池中获取一个连接,并传递给传入的指针
conRAII = *SQL; // 存储获取的连接指针
poolRAII = connPool; // 存储连接池实例指针
}
// 析构函数实现
connectionRAII::~connectionRAII() {
poolRAII->ReleaseConnection(conRAII); // 释放连接,将连接返回到连接池中
}
不直接调用获取和释放连接的接口,将其封装起来,通过RAII机制进行获取和释放。
什么是池?
池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化。
程序动态地对池中的连接进行使用,释放。当系统开始处理客户请求的时候,如果它需要相关的资源,可以直接从池中获取,无需动态分配;
当服务器处理完一个客户连接后,可以把相关的资源放回池中,无需执行系统调用释放资源。
池可以看做资源的容器,所以多种实现方法,比如数组、链表、队列等。可以使用单例模式和链表建立池,保证池为静态资源。
注册和登录功能如何实现?
流程图:(GET和POST请求的流程图)

载入数据库表:(将数据库中用户名和密码载入到服务器的map中,map中key为用户名,value为密码)
// 用于存储用户名和密码的 map
map<string, string> users;
// 初始化数据库查询结果
void http_conn::initmysql_result(connection_pool *connPool) {
// 从连接池中获取一个连接并用 connectionRAII 来管理数据库连接的生命周期
MYSQL *mysql = NULL;
connectionRAII mysqlcon(&mysql, connPool);
// 在 user 表中检索 username、passwd 数据,此处是示例的 SELECT 查询语句
if (mysql_query(mysql, "SELECT username, passwd FROM user")) {
LOG_ERROR("SELECT error: %s\n", mysql_error(mysql)); // 输出错误日志
}
// 从连接获取查询结果集
MYSQL_RES *result = mysql_store_result(mysql);
// 获取结果集中的列数
int num_fields = mysql_num_fields(result);
// 获取结果集中所有字段结构的数组
MYSQL_FIELD *fields = mysql_fetch_fields(result);
// 遍历结果集,将用户名和密码存入 users map 中
while (MYSQL_ROW row = mysql_fetch_row(result)) {
// 获取当前行的用户名和密码
string temp1(row[0]); // 以字符串形式获取用户名
string temp2(row[1]); // 以字符串形式获取密码
users[temp1] = temp2; // 将用户名和密码存入 map 中
}
}
提取用户名和密码
服务器端解析浏览器的请求报文,当解析为POST请求时,cgi标志位设置为1,并将请求报文的消息体赋值给m_string,进而提取出用户名和密码。
// 判断http请求是否被完整读入
http_conn::HTTP_CODE http_conn::parse_content(char *text) {
if (m_read_idx >= (m_content_length + m_checked_idx)) {
text[m_content_length] = '\0';
// 在 POST 请求中,最后为输入的用户名和密码
m_string = text;
return GET_REQUEST;
}
return NO_REQUEST;
}
// 根据标志判断是登录检测还是注册检测
char flag = m_url[1]; // flag 用于标识是登录检测还是注册检测,从请求中的特定位置获取
// 动态分配内存以存储处理后的 URL
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/");
strcat(m_url_real, m_url + 2);
strncpy(m_real_file + len, m_url_real, FILENAME_LEN - len - 1);
free(m_url_real);
// 从 m_string 中提取用户名和密码
char name[100], password[100];
int i;
// 以 & 为分隔符,前面的部分是用户名
for (i = 5; m_string[i] != '&'; ++i) {
name[i - 5] = m_string[i];
}
name[i - 5] = '\0';
// 以 & 为分隔符,后面的部分是密码
int j = 0;
for (i = i + 10; m_string[i] != '\0'; ++i, ++j) {
password[j] = m_string[i];
}
password[j] = '\0';
同步线程登录注册
通过m_url定位/所在位置,根据/后的第一个字符判断是登录还是注册校验。
- 2
- 登录校验
- 3
- 注册校验
根据校验结果,跳转对应页面。另外,对数据库进行操作时,需要通过锁来同步。
// 在 URL 中找到最后一个 '/' 的位置
const char *p = strrchr(m_url, '/');
// 如果 m_SQLVerify 为 0,即需要进行数据库验证
if (0 == m_SQLVerify) {
if (*(p + 1) == '3') {
// 如果是注册操作,先检查数据库中是否有重名
// 没有重名则插入数据
char *sql_insert = (char *)malloc(sizeof(char) * 200);
strcpy(sql_insert, "INSERT INTO user(username, passwd) VALUES('");
strcat(sql_insert, name);
strcat(sql_insert, "', '");
strcat(sql_insert, password);
strcat(sql_insert, "')");
// 判断 map 中是否存在重复的用户名
if (users.find(name) == users.end()) {
// 在向数据库插入数据时,需要使用锁来同步数据
m_lock.lock();
int res = mysql_query(mysql, sql_insert); // 执行 SQL 插入语句
users.insert(pair<string, string>(name, password)); // 将用户名和密码插入到 map 中
m_lock.unlock();
// 如果插入成功,则跳转到登录页面
if (!res) {
strcpy(m_url, "/log.html");
} else { // 否则跳转注册失败页面
strcpy(m_url, "/registerError.html");
}
} else { // 如果存在重名,跳转注册失败页面
strcpy(m_url, "/registerError.html");
}
} else if (*(p + 1) == '2') {
// 如果是登录操作,直接进行用户名和密码验证
// 如果用户名和密码能在表中查找到,则跳转到欢迎页面,否则跳转登录失败页面
if (users.find(name) != users.end() && users[name] == password) {
strcpy(m_url, "/welcome.html");
} else {
strcpy(m_url, "/logError.html");
}
}
}
页面跳转
通过m_url定位/所在位置,根据/后的第一个字符,使用分支语句实现页面跳转。具体的,
- 0
- 跳转注册页面,GET
- 1
- 跳转登录页面,GET
- 5
- 显示图片页面,POST
- 6
- 显示视频页面,POST
- 7
- 显示关注页面,POST
// 找到 URL 中最后一个 '/' 的位置
const char *p = strrchr(m_url, '/');
// 注册页面
if (*(p + 1) == '0') {
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/register.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
// 登录页面
else if (*(p + 1) == '1') {
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/log.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
// 图片页面
else if (*(p + 1) == '5') {
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/picture.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
// 视频页面
else if (*(p + 1) == '6') {
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/video.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
// 关注页面
else if (*(p + 1) == '7') {
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/fans.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
// 否则发送 URL 实际请求的文件
else {
strncpy(m_real_file + len, m_url, FILENAME_LEN - len - 1);
}
面试题
为什么要做这样一个项目?
做这个WebServer项目的主要原因,是它能很好地串联我的计算机基础知识,包括编程语言、操作系统、网络编程等。通过实际开发一个WebServer系统,我不仅系统地复习和巩固了这些基础知识,还培养了解决复杂问题的能力。
在开发过程中,我特别关注掌握一些关键技术,如socket编程、I/O多路复用等。这些都对提高系统性能和并发处理能力很有帮助。同时,我还设计实现了一些模块,像路由、日志等,这锻炼了我的系统设计和架构能力。
介绍下你的项目。
这个WebServer项目是我在学习计算机网络和Linux socket编程时独立开发的。作为一个轻量级的Web服务器,它采用了Proactor模式加线程池的网络架构,使用了非阻塞I/O和EPOLL的I/O多路复用技术。这样的设计不仅能够高效地处理多个客户端的HTTP请求,还能提升整体的并发性能。
项目的主要工作可以分为两大部分:一是搭建服务器的核心网络框架,包括报文解析、响应生成等基本功能,以及日志系统等辅助模块;二是针对性能优化做的一些补充,比如线程池管理、数据库连接池等。
为了验证系统的功能和性能,我使用了webbench进行了测试。在短连接场景下,QPS达到了1.8万;在长连接场景下,QPS则高达5.2万。这些测试结果表明,我的WebServer设计是比较合理和高效的。
在开发过程中,我会先对不同的实现方案进行分析,权衡它们的适用场景和性能,然后选择最合适的方案。通过这个项目,我不仅学习了两种Linux下的高性能网络模式,还深入了解了Linux环境下的编程技巧,以及一些服务端性能调优的方法。
项目难点。
这个WebServer项目的主要难点可以分为两个方面:
- 服务器网络框架、日志系统等基本系统的搭建。这部分的难点主要在于技术的理解和选型,需要将一些开源框架合理地调整和应用到自己的项目中。要确保各个模块之间的协作配合,并达到预期的功能要求。
- 为了提高服务器性能而进行的优化工作。这包括线程池、数据库连接池以及设置定时器等额外的系统设计。这部分的难点在于准确地识别服务器的性能瓶颈,然后根据自己的分析和创意,去设计并实现合适的优化方案。需要对系统的各个层面都有深入的了解。
项目中遇到的困难?是如何解决的?
- 对不同技术的理解和选型问题
- 由于这个项目涉及的技术范围比较广,包括网络编程、并发处理、性能优化等,我在理解和选择合适的技术框架时存在一些困难。
- 为了解决这个问题,我仔细阅读了项目作者在GitHub上提供的技术文档,并搜索了一些技术对比的文章,来更好地理解各种技术方案的优缺点。
- 在实在找不到相关资料的情况下,我也尝试联系了项目作者,请教他们的选型考虑和建议。
- 编码过程中出现的bug
- 由于工程经验有限,在具体编码过程中偶尔会出现一些bug,影响程序的正常运行。
- 我首先会仔细查看日志,定位问题的症状和出现位置,然后根据自己的分析尝试修复。
- 如果自己无法解决,我会到网上查找是否有同类问题的解决方案,并向同学或者StackOverflow等社区寻求帮助。
- 通过这种方式,我不仅解决了眼前的问题,也学会了更好的调试和问题解决方法。
项目优化
针对一般的Webserver服务器的基础功能之外,项目还做了以下优化:
- 减少程序等待I/O事件的时间
- 使用非阻塞I/O和I/O多路复用技术(如EPOLL),避免因同步I/O操作而导致的性能瓶颈。
- 设计高性能的网络框架
- 采用Proactor异步I/O模式,提升整体的并发处理能力。
- 减少系统调用开销
- 使用线程池和数据库连接池,避免频繁申请/释放内存资源。
- 尽量减少锁的使用,缩小临界区范围,例如日志系统和线程池的实现。
之后可以的优化(没有实现)
- 引入缓存机制:为热点数据设计合理的缓存策略,降低数据库访问压力,提升响应速度。
- 引入内存池机制:将内存分配也用池实现,避免内存分配和回收带来的资源消耗;
- 对数据库查询进行优化:引入跳表机制,有利于增加查询效率;
手写线程池
【源码剖析】threadpool —— 基于 pthread 实现的简单线程池
线程池是在服务器启动之初就建立好并完全初始化,如果需要线程,则从线程池里取;如果线程处理完毕,就放回线程池;优点在于无需频繁创建和销毁线程,无需申请和释放资源,减轻系统负担;
线程池的设计模式:半同步/半反应堆模式,反应堆为Proactor事件处理模式;

- 任务到达系统时,并不直接交由线程处理,而是先添加到任务队列中(异步处理)
- 管理者从任务队列中取出一个任务,然后调度线程池中的一个线程去处理该任务;
- 线程处理完任务之后回到线程池;
- 优化思路:
- 任务队列要不要增加优先级;
- 在一个时刻,只有一个Socket内的消息只能由一个线程来处理,在分发任务时要注意;
- 管理者要不要动态增加或减少线程池内线程的数量;
自定义的数据结构:
// 保存一个等待执行的任务。一个任务需要指明:要运行的对应函数及函数的参数(处理任务就是执行对应的函数)
typedef struct {
void (*function)(void *);
void *argument;
} threadpool_task_t;
// 一个线程池的结构,任务队列设置为数组
struct threadpool_t {
pthread_mutex_t lock; /* 互斥锁 */
pthread_cond_t notify; /* 条件变量 */
pthread_t *threads; /* 线程数组的起始指针 */
threadpool_task_t *queue; /* 任务队列数组的起始指针 */
int thread_count; /* 线程数量 */
int queue_size; /* 任务队列长度 */
int head; /* 当前任务队列头 */
int tail; /* 当前任务队列尾 */
int count; /* 当前待运行的任务数 */
int shutdown; /* 线程池当前状态是否关闭 */
int started; /* 正在运行的线程数 */
};
函数:
// 创建线程池,thread_count为线程池线程数量,queue_size为任务队列长度,flags为保留参数
threadpool_t *threadpool_create(int thread_count, int queue_size, int flags);
// 添加任务,pool指定线程池,第二个参数指定任务运行的函数指针,arg为函数参数列表,flags为保留参数
int threadpool_add(threadpool_t *pool, void (*routine)(void *),void *arg, int flags);
// 销毁线程池
int threadpool_destroy(threadpool_t *pool, int flags);
源码分析:
threadpool.h:
#ifndef _THREADPOOL_H_
#define _THREADPOOL_H_
#ifdef __cplusplus
/* 对于 C++ 编译器,指定用 C 的语法编译 */
extern "C" {
#endif
#define MAX_THREADS 64
#define MAX_QUEUE 65536
/* 简化变量定义 */
typedef struct threadpool_t threadpool_t;
/* 定义错误码 */
typedef enum {
threadpool_invalid = -1,
threadpool_lock_failure = -2,
threadpool_queue_full = -3,
threadpool_shutdown = -4,
threadpool_thread_failure = -5
} threadpool_error_t;
typedef enum {
threadpool_graceful = 1
} threadpool_destroy_flags_t;
/* 以下是线程池三个对外 API */
/**
* 创建线程池,有 thread_count 个线程,容纳 queue_size 个的任务队列,flags 参数没有使用
*/
threadpool_t *threadpool_create(int thread_count, int queue_size, int flags);
/**
* 添加任务到线程池, pool 为线程池指针,routine 为函数指针, arg 为函数参数, flags 未使用
*/
int threadpool_add(threadpool_t *pool, void (*routine)(void *),
void *arg, int flags);
/**
* 销毁线程池,flags 可以用来指定关闭的方式
*/
int threadpool_destroy(threadpool_t *pool, int flags);
#ifdef __cplusplus
}
#endif
#endif /* _THREADPOOL_H_ */
threadpool.c:
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include "threadpool.h"
/**
* 线程池关闭的方式
*/
typedef enum { // typedef为enum定义了一个新名字threadpool_shutdown_t,enum是一个枚举类
immediate_shutdown = 1,
graceful_shutdown = 2
} threadpool_shutdown_t;
/**
* 线程池一个任务的定义(包括任务处理函数的指针,任务处理函数的参数)
*/
typedef struct {
void (*function)(void *);
void *argument;
} threadpool_task_t;
/**
* 线程池的结构定义
* @var lock 用于内部工作的互斥锁
* @var notify 线程间通知的条件变量
* @var threads 线程数组,这里用指针来表示,数组名 = 首元素指针
* @var thread_count 线程数量
* @var queue 存储任务的数组,即任务队列
* @var queue_size 任务队列大小
* @var head 任务队列中首个任务位置(注:任务队列中所有任务都是未开始运行的)
* @var tail 任务队列中最后一个任务的下一个位置(注:队列以数组存储,head 和 tail 指示队列位置)
* @var count 任务队列里的任务数量,即等待运行的任务数
* @var shutdown 表示线程池是否关闭
* @var started 开始的线程数
*/
struct threadpool_t {
pthread_mutex_t lock;
pthread_cond_t notify;
pthread_t *threads;
threadpool_task_t *queue;
int thread_count;
int queue_size;
int head;
int tail;
int count;
int shutdown;
int started;
};
/**
* 线程池里每个线程在跑的函数
* 声明 static 应该只为了使函数只在本文件内有效
*/
static void *threadpool_thread(void *threadpool);
// 释放线程池资源
int threadpool_free(threadpool_t *pool);
// 创造线程池
threadpool_t *threadpool_create(int thread_count, int queue_size, int flags)
{
// 检测线程数量是否合理,任务队列长度是否合理
if(thread_count <= 0 || thread_count > MAX_THREADS || queue_size <= 0 || queue_size > MAX_QUEUE) {
return NULL;
}
threadpool_t *pool;
int i;
/* 申请内存创建内存池对象,pool此时指向线程池 */
if((pool = (threadpool_t *)malloc(sizeof(threadpool_t))) == NULL) {
goto err;
}
/* 线程池初始化,线程数量开始为0 */
pool->thread_count = 0;
pool->queue_size = queue_size;
pool->head = pool->tail = pool->count = 0;
pool->shutdown = pool->started = 0;
/* Allocate thread and task queue */
/* 申请线程数组和任务队列所需的内存 */
pool->threads = (pthread_t *)malloc(sizeof(pthread_t) * thread_count);
pool->queue = (threadpool_task_t *)malloc
(sizeof(threadpool_task_t) * queue_size);
/* Initialize mutex and conditional variable first */
/* 初始化互斥锁和条件变量,访问线程池要加锁,任务队列通知系统用条件变量 */
if((pthread_mutex_init(&(pool->lock), NULL) != 0) ||
(pthread_cond_init(&(pool->notify), NULL) != 0) ||
(pool->threads == NULL) ||
(pool->queue == NULL)) {
goto err;
}
/* Start worker threads */
/* 创建指定数量的线程开始运行 */
for(i = 0; i < thread_count; i++) {
if(pthread_create(&(pool->threads[i]), NULL,
threadpool_thread, (void*)pool) != 0) {
threadpool_destroy(pool, 0);
return NULL;
}
pool->thread_count++;
pool->started++;
}
return pool;
err: // 错误处理,释放线程池资源
if(pool) {
threadpool_free(pool);
}
return NULL;
}
// 添加任务到线程池的任务队列
int threadpool_add(threadpool_t *pool, void (*function)(void *),
void *argument, int flags)
{
int err = 0;
int next;
if(pool == NULL || function == NULL) {
return threadpool_invalid;
}
/* 必须先取得互斥锁所有权,添加任务到线程池要加锁,线程池时共享资源 */
if(pthread_mutex_lock(&(pool->lock)) != 0) {
return threadpool_lock_failure;
}
/* 计算下一个可以存储 task 的位置 */
next = pool->tail + 1;
next = (next == pool->queue_size) ? 0 : next; // 相当于满了之后从头开始(循环数组)
do {
/* Are we full ? */
/* 检查是否任务队列满 */
if(pool->count == pool->queue_size) {
err = threadpool_queue_full;
break;
}
/* Are we shutting down ? */
/* 检查当前线程池状态是否关闭 */
if(pool->shutdown) {
err = threadpool_shutdown;
break;
}
/* Add task to queue */
/* 在 tail 的位置放置函数指针和参数,添加到任务队列 */
pool->queue[pool->tail].function = function;
pool->queue[pool->tail].argument = argument;
/* 更新 tail 和 count */
pool->tail = next;
pool->count += 1;
/* pthread_cond_broadcast */
/*
* 发出 signal,表示有 task 被添加进来了
* 如果由因为任务队列空阻塞的线程,此时会有一个被唤醒
* 如果没有则什么都不做
*/
if(pthread_cond_signal(&(pool->notify)) != 0) {
err = threadpool_lock_failure;
break;
}
/*
* 这里用的是 do { ... } while(0) 结构
* 保证过程最多被执行一次,但在中间方便因为异常而跳出执行块
*/
} while(0);
/* 释放互斥锁资源 */
if(pthread_mutex_unlock(&pool->lock) != 0) {
err = threadpool_lock_failure;
}
return err;
}
// 销毁线程池
int threadpool_destroy(threadpool_t *pool, int flags)
{
int i, err = 0;
if(pool == NULL) {
return threadpool_invalid;
}
/* 取得互斥锁资源 */
if(pthread_mutex_lock(&(pool->lock)) != 0) {
return threadpool_lock_failure;
}
do {
/* Already shutting down */
/* 判断是否已在其他地方关闭 */
if(pool->shutdown) {
err = threadpool_shutdown;
break;
}
/* 获取指定的关闭方式 */
pool->shutdown = (flags & threadpool_graceful) ?
graceful_shutdown : immediate_shutdown;
/* Wake up all worker threads */
/* 唤醒所有因条件变量阻塞的线程,并释放互斥锁 */
if((pthread_cond_broadcast(&(pool->notify)) != 0) ||
(pthread_mutex_unlock(&(pool->lock)) != 0)) {
err = threadpool_lock_failure;
break;
}
/* Join all worker thread */
/* 等待所有线程结束 */
for(i = 0; i < pool->thread_count; i++) {
if(pthread_join(pool->threads[i], NULL) != 0) {
err = threadpool_thread_failure;
}
}
/* 同样是 do{...} while(0) 结构*/
} while(0);
/* Only if everything went well do we deallocate the pool */
if(!err) {
/* 释放内存资源 */
threadpool_free(pool);
}
return err;
}
// 释放线程资源
int threadpool_free(threadpool_t *pool)
{
if(pool == NULL || pool->started > 0) {
return -1;
}
/* Did we manage to allocate ? */
/* 释放线程 任务队列 互斥锁 条件变量 线程池所占内存资源 */
if(pool->threads) {
free(pool->threads);
free(pool->queue);
/* Because we allocate pool->threads after initializing the
mutex and condition variable, we're sure they're
initialized. Let's lock the mutex just in case. */
pthread_mutex_lock(&(pool->lock));
pthread_mutex_destroy(&(pool->lock));
pthread_cond_destroy(&(pool->notify));
}
free(pool);
return 0;
}
// 指定线程执行的函数(即将任务分配给线程执行)
static void *threadpool_thread(void *threadpool)
{
threadpool_t *pool = (threadpool_t *)threadpool;
threadpool_task_t task;
for(;;) { // 也可以while(true),必须循环获取,因为是竞争获取资源
/* Lock must be taken to wait on conditional variable */
/* 取得互斥锁资源 */
pthread_mutex_lock(&(pool->lock));
/* Wait on condition variable, check for spurious wakeups.
When returning from pthread_cond_wait(), we own the lock. */
/* 用 while 是为了在唤醒时重新检查条件 */
while((pool->count == 0) && (!pool->shutdown)) {
/* 任务队列为空,且线程池没有关闭时阻塞在这里 */
pthread_cond_wait(&(pool->notify), &(pool->lock));
}
/* 关闭的处理 */
if((pool->shutdown == immediate_shutdown) ||
((pool->shutdown == graceful_shutdown) &&
(pool->count == 0))) {
break;
}
/* Grab our task */
/* 取得任务队列的第一个任务(顺序从任务队列中取任务) */
task.function = pool->queue[pool->head].function;
task.argument = pool->queue[pool->head].argument;
/* 更新 head 和 count */
pool->head += 1;
pool->head = (pool->head == pool->queue_size) ? 0 : pool->head;
pool->count -= 1;
/* Unlock */
/* 释放互斥锁 */
pthread_mutex_unlock(&(pool->lock));
/* Get to work */
/* 开始运行任务 */
(*(task.function))(task.argument);
/* 这里一个任务运行结束 */
}
/* 线程将结束,更新运行线程数 */
pool->started--;
pthread_mutex_unlock(&(pool->lock));
pthread_exit(NULL);
return(NULL);
}
实现方法2:
#pragma once
#include <vector>
#include <queue>
#include <memory>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <future>
#include <functional>
#include <stdexcept>
class ThreadPool {
public:
ThreadPool(size_t threads); // RAII机制管理,构造函数新建线程池,析构函数自动回收资源
~ThreadPool();
// 函数模板
template<typename F, typename... Args>
auto enqueue(F&& f, Args&&... args)
-> std::future<std::result_of_t<F(Args...)>>;
private:
std::vector<std::thread> _workers; // 使用线程向量(线程数组)实现线程池;
std::queue<std::function<void()>> _tasks; // 任务队列
std::mutex _queueMutex; // 互斥锁
std::condition_variable _condition; // 条件变量
bool _stop;
};
#pragma once 是一种预处理指令,它的作用是防止同一个头文件被包含多次。工作原理是:
- 当编译器遇到 #pragma once 指令时,会为该头文件生成一个唯一的标识符。
- 在后续包含该头文件时,编译器会检查是否已经包含过该文件,如果是,则会跳过该头文件的内容,不会重复编译。
函数模板:
-
template<typename F, typename... Args>:函数模板的两个参数的类型分别是F和Args; -
auto enqueue(F&& f, Args&&... args):- 使用
auto返回类型,后面的->指定了具体的返回类型; - 完美转发:使用
$$引用折叠,即F&& f和Args&&... args;利用了C++11中的”右值引用“特性,可以完美地转发参数,保持参数地原始类型和值;
- 使用
-
-> std::future<std::result_of_t<F(Args...)>>:-
std::future<...>: 函数返回一个std::future对象;std::result_of_t<F(Args...)>使用std::result_of_t类型特性获取F(Args...)的返回类型;
-
// Inline,使用内联函数,size_t threads指定线程数量,设置_stop标志为false,表示线程池的初始化未停止
inline ThreadPool::ThreadPool(size_t threads) : _stop(false) {
/* 创建线程池,并对线*/
}
/*
循环建立threads个工作线程
emplace_back相当于在_workers中添加一个新的 std::thread 对象,即创建了新线程
使用lambda表达式当成线程入口函数,避免了单独定义一个函数当函数入口
*/
for(size_t i = 0; i < threads; ++i) {
_workers.emplace_back([this] {
/* 工作线程的具体实现 */
});
}
/*
工作线程的具体实现:
加互斥锁:工作线程从任务队列中获取任务,任务队列是共享资源,访问加锁;
等待条件变量:如果任务队列不为空(有任务)或不在创建线程池过程中;
注意_condition.wait()要传入互斥锁,因为条件变量也是共享资源;
如果线程池不工作并且任务队列为空:跳出while(true)循环;
取出任务,将任务队列中对应任务删除;
执行任务;
在线程池创建阶段,会循环创建threads个线程;
在线程池工作阶段,会从任务队列中取出任务然后完成任务;
*/
while(true) { // 每一个工作线程都会不断从任务队列中取出任务
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(this->_queueMutex);
this->_condition.wait(lock,
[this]{ return this->_stop || !this->_tasks.empty(); });
if(this->_stop && this->_tasks.empty())
return; // 会退出while(true)循环,继续创建下一个线程,保证在程序执行前就创建好线程池
task = std::move(this->_tasks.front()); // 从任务队列队头取出任务
this->_tasks.pop(); // 取出任务后,从任务队列中删除
}
task(); // 执行取出的任务
}
/*
将任务执行函数和对应参数绑定到任务上,将任务添加到任务队列中;
用条件变量通知所有工作线程,竞争抢夺任务队列上的任务去执行;
*/
// 函数模板,加入任务到任务队列,加入任务时,要将任务的执行函数和对应参数绑定到任务上;
template<typename F, typename... Args>
auto ThreadPool::enqueue(F&& f, Args&&... args)
-> std::future<std::result_of_t<F(Args...)>>
{
// 使用 std::result_of_t 获取函数调用 F(Args...) 的返回类型
using return_type = std::result_of_t<F(Args...)>;
// 创建一个 std::packaged_task,将传入的函数 f 和参数 args 绑定起来
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<F>(f), std::forward<Args>(args)...)
);
// 从 packaged_task 获取对应的 future 对象
std::future<return_type> res = task->get_future();
{
// 获取 _queueMutex 互斥锁,保护对任务队列的访问
std::unique_lock<std::mutex> lock(_queueMutex);
// 如果线程池已停止,抛出异常
if(_stop)
throw std::runtime_error("enqueue on stopped ThreadPool");
// 将打包好的任务函数放入任务队列
_tasks.emplace([task]() {
(*task)();
});
}
// 通知所有等待的工作线程,有新任务加入(用信号量通知)
_condition.notify_all();
// 返回 future 对象,用于获取任务的执行结果
return res;
}
// 内联函数,析构函数,销毁线程池,释放线程池资源
inline ThreadPool::~ThreadPool() {
{
std::unique_lock<std::mutex> lock(_queueMutex);
_stop = true;
}
_condition.notify_all(); // 唤醒所有线程,清空任务
for(std::thread& worker : _workers) { // 从线程向量数组中逐个销毁线程
worker.join();
}
}
完整代码:
#pragma once
#include <vector>
#include <queue>
#include <memory>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <future>
#include <functional>
#include <stdexcept>
class ThreadPool {
public:
ThreadPool(size_t threads); // RAII机制管理,构造函数新建线程池,析构函数自动回收资源
~ThreadPool();
// 函数模板
template<typename F, typename... Args>
auto enqueue(F&& f, Args&&... args)
-> std::future<std::result_of_t<F(Args...)>>;
private:
std::vector<std::thread> _workers; // 使用线程向量(线程数组)实现线程池;
std::queue<std::function<void()>> _tasks; // 任务队列
std::mutex _queueMutex; // 互斥锁
std::condition_variable _condition; // 条件变量
bool _stop;
};
// Inline,使用内联函数,size_t threads指定线程数量,设置_stop标志为false,表示线程池的初始化未停止
inline ThreadPool::ThreadPool(size_t threads) : _stop(false) {
for(size_t i = 0; i < threads; ++i) { // 循环创建threads个工作线程
// emplace_back相当于在_workers中添加一个新的 std::thread 对象,即创建了新线程
_workers.emplace_back([this] { // 向线程向量_workers中添加向量(emplace_back和push_back的异同),用lamda表达式当成线程入口函数?
while(true) { // 每一个工作线程都会不断从任务队列中取出任务
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(this->_queueMutex);
this->_condition.wait(lock,
[this]{ return this->_stop || !this->_tasks.empty(); });
if(this->_stop && this->_tasks.empty())
return; // 会退出while(true)循环,继续创建下一个线程,保证在程序执行前就创建好线程池
task = std::move(this->_tasks.front()); // 从任务队列队头取出任务
this->_tasks.pop(); // 取出任务后,从任务队列中删除
}
task(); // 执行取出的任务
}
});
}
}
// 函数模板,加入任务到任务队列,加入任务时,要将任务的执行函数和对应参数绑定到任务上;
template<typename F, typename... Args>
auto ThreadPool::enqueue(F&& f, Args&&... args)
-> std::future<std::result_of_t<F(Args...)>>
{
// 使用 std::result_of_t 获取函数调用 F(Args...) 的返回类型
using return_type = std::result_of_t<F(Args...)>;
// 创建一个 std::packaged_task,将传入的函数 f 和参数 args 绑定起来
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<F>(f), std::forward<Args>(args)...)
);
// 从 packaged_task 获取对应的 future 对象
std::future<return_type> res = task->get_future();
{
// 获取 _queueMutex 互斥锁,保护对任务队列的访问
std::unique_lock<std::mutex> lock(_queueMutex);
// 如果线程池已停止,抛出异常
if(_stop)
throw std::runtime_error("enqueue on stopped ThreadPool");
// 将打包好的任务函数放入任务队列
_tasks.emplace([task]() {
(*task)();
});
}
// 通知所有等待的工作线程,有新任务加入(用信号量通知)
_condition.notify_all();
// 返回 future 对象,用于获取任务的执行结果
return res;
}
// 内联函数,析构函数,销毁线程池,释放线程池资源
inline ThreadPool::~ThreadPool() {
{
std::unique_lock<std::mutex> lock(_queueMutex);
_stop = true;
}
_condition.notify_all(); // 唤醒所有线程,清空任务
for(std::thread& worker : _workers) { // 从线程向量数组中逐个销毁线程
worker.join();
}
}
线程的同步机制有哪些?
- 互斥量(Mutex):(二进制的信号量)
- 互斥量(Mutex)是一种用于实现线程间互斥访问共享资源的同步机制。
- 通过在临界区(对共享资源进行访问的代码段)周围加锁和解锁互斥量来确保同一时刻只有一个线程访问临界资源,从而避免多个线程同时访问造成的数据竞争和不一致性。
- 当一个线程尝试加锁一个已被其他线程锁定的互斥量时,该线程会被阻塞,直到其他线程释放锁。
- 条件变量(Condition Variable):
- 条件变量是一种用于线程间等待和通知的同步机制,在互斥量的基础上扩展出的机制。
- 条件变量允许线程在等待某个条件发生时阻塞,直到其他线程通知条件满足后解除阻塞。
- 通常和互斥量一起使用,等待线程在获得互斥锁后检查条件,如果条件不满足则通过条件变量等待,直到其他线程改变条件并通知。
- 信号量(Semaphore):
- 信号量是一种更为通用的同步机制,用于控制对共享资源的访问权限。
- 信号量维护一个计数器,当计数器大于等于0时,允许访问资源;当小于0时,线程会被阻塞直到计数器大于等于0。
- 信号量可以用于实现资源的有限共享、进程间的同步等场景。
线程池中的工作线程是一直等待吗?
不是一直等待的,而是通过条件变量来控制工作线程的行为。
- 工作线程等待任务:初始状态下,工作线程会通过条件变量等待任务的到来。当任务队列中有新的任务被提交时,主线程会通知空闲的工作线程,工作线程被唤醒。
- 任务调度执行:被唤醒的工作线程会从任务队列中获取任务,并执行任务的相应代码。
- 任务执行完毕:任务执行完毕后,工作线程将结果返回给主线程,并再次通过条件变量等待新的任务。
- 循环执行:工作线程会不断循环执行上述步骤,等待任务、执行任务、等待任务,保持线程池中的工作线程处于可用状态。
你的线程池工作线程处理完一个任务后的状态是什么?
这⾥要分两种情况考虑:
-
当处理完任务后如果请求队列为空时,则这个线程重新回到阻塞等待的状态;
-
当处理完任务后如果请求队列不为空时,那么这个线程将处于与其他线程竞争资源的状态,谁获得锁谁就获得了处理事件的资格;
while(true) { // 每一个工作线程都会不断从任务队列中取出任务
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(this->_queueMutex);
this->_condition.wait(lock,
[this]{ return this->_stop || !this->_tasks.empty(); });
if(this->_stop && this->_tasks.empty())
return; // 会退出while(true)循环,继续创建下一个线程,保证在程序执行前就创建好线程池
task = std::move(this->_tasks.front()); // 从任务队列队头取出任务
this->_tasks.pop(); // 取出任务后,从任务队列中删除
}
task(); // 执行取出的任务
}
可以看出,工作线程在建立之后一直在while(true)中等待条件变量通知;
如果同时1000个客户端进行访问请求,线程数不多,怎么能及时响应处理每一个呢?
线程池管理:
- 使用线程池管理线程资源,减少线程的频繁创建和销毁开销,提高线程的复用率。
- 根据系统的负载情况,动态调整线程池的大小,以平衡资源利用率和响应速度。
异步非阻塞模型:
- 采用Proactor模式,主线程负责监视文件描述符组和读写I/O,工作线程负责业务逻辑处理。
- 使用非阻塞I/O操作,确保I/O操作不会阻塞线程,提高并发处理能力。
消息队列缓冲机制:
- 将客户端请求先挂载到消息队列上,而不是立即处理,消息队列通知工作线程取出请求进行处理。
- 这样可以利用消息队列的缓冲效果,平滑处理突发的大量请求。
异步I/O处理机制:
- 主线程负责读写I/O操作,工作线程负责处理读取的HTTP报文,生成要写的HTTP响应报文。
- 这样可以充分利用I/O操作的异步性,提高系统的并发处理能力。
负载均衡策略:
- 将客户端的请求挂载到任务队列上,根据工作线程的负载情况合理分发任务。
- 这样可以有效避免某些工作线程的任务队列堆积过多,导致响应延迟。
Epoll I/O多路复用机制:
- 使用边缘触发模式(ET),确保每个事件只会触发一次,需要处理完整个事件之后才能继续监听该事件,有效避免事件重复触发。
- 合理设置
epoll_wait的超时时间,确保在给定时间内处理就绪事件。 - 使用非阻塞I/O操作,确保I/O操作不会阻塞线程。
- 将客户端请求先挂载到任务队列上,根据工作线程的负载情况合理分发任务,避免任务全部堵在某个线程的任务队列上。
⾸先这种问法就相当于问服务器如何处理高并发的问题。
⾸先我项⽬中使⽤了I/O多路复⽤技术,每个线程中管理⼀定数量的连接,只有线程池中的连接有请求, epoll就会返回请求的连接列表,管理该连接的线程获取活动列表,然后依次处理各个连接的请求。
如果该线程没有任务,就会等待主线程分配任务。这样就能达到服务器高并发的要求,同⼀时刻,每个线程都在处理自己所管理连接的请求。
- 有连接请求,
epoll就返回连接请求,将请求挂载到阻塞队列上;通知线程池中的工作线程去抢夺执行任务; - 没有请求任务,线程就会一直阻塞,等待主线程分配任务;
如果一个客户请求需要占用线程很久的时间,会不会影响接下来的客户请求呢,有什么好的策略呢?
非活跃连接使用定时器处理;非活跃连接就是建立了连接之后,长时间不发送数据,一直占用服务器资源的连接;
使用定时器策略;使用信号实现定时器;在创建连接时就创建一个定时器,将该定时器加入到定时器链表中,定时器链表是一个按照超时时间升序排列的链表;
- 利用
alarm函数周期性地触发SIGALRM信号; - 内核接受到信号之后,将信号放进对应进程的信号队列中;并向进程发起中断;进程收到中断之后从用户态进入内核态;
- 进程调用信号处理函数,信号处理函数只负责通知进程有信号要处理,具体的处理逻辑在用户态处理;
- 从内核态进入用户态,处理信号(主循环调用定时任务处理函数,处理到期的定时器):
- 遍历定时器升序链表,从头结点开始遍历;
- 若当前时间小于定时器超时时间,跳出循环,即找到未到期的定时器;
- 若当前时间大于定时器超时时间,即找到了到期的定时器,执行回调函数,然后将它从链表中删除,然后继续向后遍历;
- 信号处理完成,重新进入内核态,然后检测信号队列中是否有信号没有被处理;
如果一个连接请求的资源非常大,在发送响应报文时可能会造成延迟响应其他连接的请求,可以怎么优化?
- 异步处理:收到请求之后, 将请求报文放入任务队列,不立即响应,交给工作线程异步执行文件传输;
- 文件缓存:对于热点资源将其缓存在内存中,减少磁盘读取开销;
- 断点传输:设置响应报⽂的大小上限,当响应报文超出上限时,可以记录已经发送的位置,之后可以选择继续由该线程进⾏发送,也可以转交给其他线程进⾏发送;
简单说一下服务器使用的并发模型?
并发编程模式有半同步/半异步模式,领导者/追随者模式;使用了半同步/半异步模式;
- 主线程充当异步线程,负责监听文件描述符组和I/O操作(读写数据、建立新连接);
- 工作线程充当同步线程,负责处理请求,生成响应报文;
- 当客户端请求到达服务器,主线程将新请求得到的新连接的Socket的读写事件注册到Epoll内核事件表;
- 主线程监听文件描述符组,如果有读就绪事件,则从对应的Socket上接受数据并封装好之后加入请求队列;
- 请求队列使用信号量通知工作线程处理任务;
- 工作线程拿到请求队列的请求数据之后,生成响应报文,放回请求队列;
- 请求队列使用信号量通知主线程,主线程从请求队列中获取到消息后封装为请求信息的响应报文写Socket;
reactor、proactor、主从reactor模型的区别?
事件驱动编程中,Reactor模式、Proactor模式和主从Reactor模型是常见的设计模式,用于处理并发I/O操作。
Reactor模式:
- 主线程仅负责监视文件描述符组中是否有就绪事件,如果监听到有事件发生,则通知工作线程,工作线程负责读写I/O和业务逻辑(读写数据、接受新连接和处理客户端请求、生成响应报文)
- I/O操作由应用程序完成,而不是操作系统;
- 适用于单线程处理多个事件的场景;
Proactor模式:
- 主线程除了负责监视Socket,而且还读写数据、接受新连接等I/O操作;工作线程仅负责业务逻辑,比如根据客户端请求生成响应;
- I/O操作由操作系统完成,而不是应用程序;
- 应用程序发起异步操作请求,然后继续执行其他任务;操作系统完成异步操作时通知应用程序进行处理;
- 适用于高性能I/O操作的场景
主从Reactor模式:
- 结合了多个Reactor实例的优势,一个主Reactor模型负责监听事件,将事件分发给多个从Reactor模型;
- 适用于处理大量并发连接的网络应用;
Reactor模式和Proactor模式都是用于处理并发I/O操作的设计模式,它们在处理事件和I/O操作的方式上有所不同。主从Reactor模型则是一种更加复杂的模型,结合了多个Reactor实例来处理并发事件,适用于需要处理大量并发连接的情况。
你用了epoll,说一下为什么用epoll,还有其他复用方式吗?区别是什么?
Epoll更好应对连接多,但是只有部分连接活跃的情况;其余IO多路复用方式还有select和poll;
- Select底层是线性表,可以监视的文件描述符数量有上限,一般是1024;每次调用都用将所有文件描述符从内核态拷贝到用户态;需要遍历文件描述符组才能判断哪个文件描述符上有事件发生;
- Poll底层是链表,可以监视的文件描述符数量突破了Select的上限,但是每次调用也需要将所有文件描述符从内核态拷贝到用户态,需要遍历文件描述符组才能判断哪个文件描述符上有事件发生;效率会随着文件描述符数量的增加而急剧下降;
- Epoll:
- 底层是红黑树和双链表;最大可以打开文件的数目可以修改指定;
- 红黑树:用来存储需要监听的文件描述符和对应的事件信息。红黑树的每个节点都包含一个文件描述符和它所关注的事件。
- 双链表:用来存储活跃的事件(就绪事件)集合,即已经就绪的文件描述符和事件信息。
- 就绪链表(双链表):内核会将就绪事件放在双链表中,当
epoll_wait()等待时,内核只会返回处于就绪链表中的事件,不用遍历所有文件描述符找到就绪事件;
- 就绪链表(双链表):内核会将就绪事件放在双链表中,当
- 事件驱动:当应用程序向内核注册文件描述符(文件、套接字等)时,内核会将该文件描述符的I/O事件与回调函数关联起来。
- 事件发生时,内核会通知应用程序并调用回调函数;
- 当注册的文件描述符上有事件发生时,内核会把这些事件加入到就绪队列中,并唤醒处于阻塞状态的应用程序。
- 应用程序被唤醒之后,可以获取到就绪事件的文件描述符,并获取相应的事件信息;应用程序可以处理数据,并执行回调函数;
- 事件被处理完毕之后,更新红黑树和双链表;
- 底层是红黑树和双链表;最大可以打开文件的数目可以修改指定;
适用情况:
- 对于都是活跃连接:使用select和poll,因为连接都活跃,Epoll的红黑树和就绪链表没有优势,而且还要建立文件系统,消耗资源;
- 对于数量少,连接比较活跃:使用select和poll;
- 对于数量非常大,只有一部分连接活跃:使用Epoll明显性能更好;
使用过程:
- 创建事件表:线程使用
epoll_create()创建Epoll内核表,获得Epoll内核表的文件描述符; - 注册事件表:线程使用
epoll_ctl()将事件注册到Epoll内核表中; - 事件就绪检测:线程使用
epoll_wait()函数检测是否有事件发生,即检测Epoll内核表中哪些文件描述符就绪; - 触发模式:分为3种,水平触发LT、 边缘触发ET、EPOLLONESHOT三种模式;可在
epoll_wait()中选择;- 水平触发模式LT:只要有事件就绪,
epoll_wait()就会返回就绪事件个数并通知应用程序,应用程序可以不立即处理,如果不处理之后下一次还会报告该事件就绪; - 边缘触发模式ET:只有事件状态发生变化,
epoll_wait()才会返回并通知应用程序,应用程序需要立刻处理,此时即使事件处于就绪,也不会再次报告; - EPOLLONESHOT模式:文件描述符只会被触发一次,即可以实现一个Socket上的请求在任一时刻只由一个线程进行处理(否则在处理Socket请求时,可能Socket上又来了请求,此时不应该由其他线程处理,而是等待Socket上其余请求处理完),当线程处理完时,需要重置EPOLLONESHOT事件(只有重置才能继续监听该Socket);
- 水平触发模式LT:只要有事件就绪,
用了状态机啊,为什么要用状态机?
有限状态机是一种高效编程方法,服务器可以根据不同状态来进行相应的处理逻辑;
主从状态机:
主状态机做了什么:
- 主状态机有三种状态,分别对应:解析请求行,解析请求头,解析请求体;
- 状态转变:
- CHECK_STATE_REQUESTLINE解析请求行,解析完成后状态变为解析请求头;
- 解析请求头完成后,判断是GET还是POST请求;
- GET请求不再解析请求体,之间退出状态机,执行生成响应报文操作;
- POST请求,则状态转为解析请求体;
- 解析请求体完成之后执行生成响应报文操作;
从状态做了什么:
- 三种状态,LINE_OK,LINE_OPEN,LINE_BAD,分别是解析一行成功,数据读取不完整,行内语法错误;
- 如果当前字符是
\r:- 如果没有下一个字符,说明
\n没有被读进来,读取报文不完整,返回LINR_OPEN继续读取; - 如果下一个字符是
\n,则找到了\r\n,将\r\n换成\0\0,然后返回LINE_OK,代表一行读取成功; - 如果下一个字符不是
\n,代表请求报文格式错误,返回LINE_BAD;
- 如果没有下一个字符,说明
- 如果当前字符是
\n:- 如果上一个字符是
\r,则找到了\r\n,将\r\n换成\0\0,然后返回LINE_OK,代表一行读取成功;- 为什么会出现这种情况,是因为一行数据被分两次读取,第一次读取到
\r结束,第二次读取从\n开始,所以接收到第二次数据时,没有处理\n就处理到了\r;
- 为什么会出现这种情况,是因为一行数据被分两次读取,第一次读取到
- 如果上一个字符不是
\r,代表请求报文格式错误,返回LINE_BAD;
- 如果上一个字符是
- 如果没有
\r也没有\n:- 说明读取数据不完整,可能读了半行就处理,所以返回
LINE_OPEN,继续监听;
- 说明读取数据不完整,可能读了半行就处理,所以返回
状态机的好处:
主从状态机将报文解析的整个过程分解为多个清晰的状态,每个状态对应不同的处理逻辑,使得整个解析过程更易于理解和维护。
主从状态机模式将状态转移和处理逻辑分离,使代码结构更清晰、模块化,易于扩展和维护。每个状态都有清晰的入口和出口,便于定位和分析问题。
主从状态机支持状态的扩展和定制化,可以通过添加新的状态来扩展解析功能,而不会对现有的状态机逻辑产生影响,保持了解耦和高内聚的设计原则。
主从状态机模式能够避免在代码中重复实现状态的判断和处理逻辑,提高了代码复用性和可维护性,降低了代码的冗余度。
状态机的转移图画一下
主状态转移,从状态转移;从状态驱动主状态;

https协议为什么安全?
使用了对称加密和非对称加密,对称加密虽然效率高,但是会话密钥如果泄露,所有消息都会泄露;非对称加密虽然安全,但是效率低;所以使用非对称加密同步会话密钥,用对称加密实现数据传输;
3个随机数
- 服务器向数字权威机构注册自己的数字证书,服务器发送信息包括服务器的公钥,服务器信息;
- 数字权威机构CA将服务器发送的信息用自己的私钥加密,生成数字证书,发送给服务器;
- 服务器生成一个随机数,和数字证书一起发送给客户端(不加密);
- 客户端收到数字证书,向权威机构验证数字证书的有效性;然后用CA在本机中的保存的公钥解密,获得服务器公钥;
- 客户端生成第二个随机数,用服务器公钥进行加密发送给服务器;
- 服务器用私钥解密,生成第三个随机数,然后将第三个随机数用私钥加密后发送到客户端;
- 客户端用服务器公钥解密,获得第三个随机数;
- 此时,双方都直到3个相同的随机数,用这3个随机数生成相同的会话密钥;
- 整个过程,只有3个随机数的同步,没有会话密钥的传输;
- 服务器和客户端可以直接使用会话密钥加密,实现对称加密传输;
https的ssl连接过程
SSL握手是在生成对称密钥,建立TCP连接之后(生成对称密钥的过程顺便也建立了TCP连接);
- 客户端发起SSL连接请求:
- 客户端向服务器发起HTTPS连接请求,服务器会返回自己的SSL证书,其中包含公钥等信息。
- 客户端验证服务器证书:
- 客户端接收服务器的SSL证书后,会验证证书的有效性,包括验证证书的颁发机构是否受信任、证书是否过期、是否匹配等。如果验证通过,客户端将继续SSL握手过程。
- 生成对称密钥:
- 在SSL握手阶段,客户端和服务器之间会通过协商过程生成对称密钥,用于加密和解密通信过程中的数据。
- 加密通信:
- 一旦对称密钥生成,客户端和服务器之间的通信将采用对称加密算法进行加密和解密,保证传输数据的安全性。
- SSL握手:(3次握手)
- 通过SSL握手过程,客户端和服务器会交换用于加密通信的参数,并验证彼此身份。握手过程包括以下步骤:
- 客户端发送ClientHello报文:包含支持的SSL/TLS版本、加密算法等信息。
- 服务器返回ServerHello报文:确认协商的SSL/TLS版本、选择加密算法等。
- 服务器发送证书报文:将服务器的SSL证书发送给客户端。
- 客户端验证证书:客户端验证服务器证书的有效性。
- 客户端发送Finished报文:用于验证握手过程的完整性。
- 服务器发送Finished报文:同样用于验证握手过程的完整性。
- 通过SSL握手过程,客户端和服务器会交换用于加密通信的参数,并验证彼此身份。握手过程包括以下步骤:
- 建立安全传输通道:
- 一旦SSL握手成功完成,客户端和服务器之间就建立了安全传输通道,可以开始加密通信。
- 传输数据:
- 客户端和服务器之间的HTTP通信会通过SSL传输数据,数据在传输过程中受到加密保护,可以有效防止中间人攻击和窃听等安全问题。
GET和POST的区别
GET通过URL传递参数,数据直接附在URL后面,以键值对的形式呈现,对于敏感信息不安全,URL会直接保存在浏览器记录中,所以数据也会以明文的形式保存在浏览器记录中;并且GET的请求报文可以没有请求体;
POSR的数据在封装在请求体中传输,不会保存在URL中,可以传输比GET大得多的数据,适合大量数据传输;
GET请求的数据会被放在浏览器缓存中,而POST请求的数据默认不会放在缓存中,每次请求都需要向浏览器重新发送数据;
登录说一下?

- 从数据库池中取出一个数据库连接,在数据库
users表中检索username和passwd,使用SELECT语句SELECT username, passwd FROM user将所有username和passwd都保存在服务器的map中; - 从POST请求报文的消息体中提取出来用户名
username和密码passwd键值对; - 根据标志位判断是登录检测还是注册检测;
- 注册:
- 在map中检测是否有username重名;
- 如果没有重名,则加锁,然后在数据库中插入注册的用户名和密码;
INSERT INTO user(username, passwd) VALUES('name', 'passward') - 插入成功,则跳转登录页面;
- 插入失败,则跳转注册失败页面;
- 重名,也跳转注册失败页面;
- 登录:
- 直接在本地的map中检测username和passwd是否匹配;
- 匹配则跳转欢迎页面;
- 不匹配则跳转登录失败页面;
// SQL语句,插入用户名和密码进行注册
char *sql_insert = (char *)malloc(sizeof(char) * 200);
strcpy(sql_insert, "INSERT INTO user(username, passwd) VALUES('");
strcat(sql_insert, name);
strcat(sql_insert, "', '");
strcat(sql_insert, password);
strcat(sql_insert, "')");
每次处理POST报文都会取出数据库连接,然后map数据库内容到本地;
你这个保存状态了吗?如果要保存,你会怎么做?(cookie和session)
没有保存
使用cookie和session:
- 服务器端设置Cookie:
- 服务器在响应客户端的请求时,可以通过设置Set-Cookie字段(在请求头中)来向客户端发送Cookie信息。可以使用服务器端的后端语言(如PHP、Node.js、Java)来设置Cookie,比如设置Cookie的名称、值、过期时间、路径、域等。
- 客户端接收Cookie:
- 客户端在接收到包含Set-Cookie字段的服务器响应后,会将Cookie信息存储在本地。Cookie通常会以键值对的形式存储在客户端的浏览器中。
- 客户端发送Cookie:
- 在之后的HTTP请求中,客户端会自动在请求头中携带之前存储的Cookie信息,以便服务器能够识别客户端的状态并作出相应的处理。
- 服务器端读取Cookie:
- 服务器在接收到客户端的请求时,可以通过读取请求头中的Cookie字段来获取客户端传递的Cookie信息,并根据其中的内容进行逻辑处理。
- Cookie与Session的关系:
- 在实际应用中,通常会使用Session来跟踪用户的会话状态。Session是在服务器端保存的用户会话信息,而Cookie主要用于在客户端和服务器之间传递会话标识(如Session ID)。
- 当用户第一次访问服务器时,服务器会创建一个Session,并将该Session的标识以Cookie的形式发送给客户端保存。客户端之后的每次请求都会携带这个Session ID,从而服务器可以识别客户端的会话状态。
- 通过结合使用Cookie和Session,可以实现用户登录状态的保持、会话管理、权限控制等功能。
当服务器要设置Cookie时,需要计算出一个字符串,包含了Cookie的各种属性(如名称、值、过期时间、域、路径等),并将这个字符串设置在HTTP响应的Set-Cookie头部中发送给客户端。客户端接收到这个Cookie后会保存在本地并在后续的请求中发送回服务器。
具体来说,一个Cookie字符串一般由以下部分组成:
- 名称(name): Cookie的名称,用于唯一标识Cookie。
- 值(value): Cookie的值,即存储的数据内容。
- 过期时间(expires或Max-Age): Cookie的过期时间,用于指定Cookie的有效期,过了这个时间后Cookie将被删除。
- 域(domain): Cookie所属的域名,指定了哪些域名可以访问这个Cookie。
- 路径(path): Cookie生效的路径,指定了哪些路径下的请求可以包含这个Cookie。
- 安全标志(secure): 如果设置了该标志,则只有在HTTPS安全连接中才会将Cookie发送给服务器。
- HTTPOnly标志(HttpOnly): 如果设置了该标志,则JavaScript无法通过document.cookie来访问Cookie,可以防止跨站脚本攻击。
当服务器设置Cookie时,需要将上述信息按照一定的格式拼接成一个字符串,并发送给客户端,客户端会将这个字符串解析并保存在本地。当客户端将该Cookie发送回服务器时,服务器可以通过解析Cookie字符串来获取其中的信息,从而实现对用户会话状态的跟踪和管理。
登录中的用户名和密码你是load到本地,然后使用map匹配的,如果有10亿数据,即使load到本地后hash,也是很耗时的,你要怎么优化?
缓存技术:使用缓存技术(如Redis)来存储部分用户信息。可以将热门用户或频繁访问的用户信息缓存到内存中,减少数据库查询次数和提高响应速度。
数据分片:使用缓存技术(如Redis)来存储部分用户信息。可以将热门用户或频繁访问的用户信息缓存到内存中,减少数据库查询次数和提高响应速度。
异步加载:在系统启动时异步加载部分用户信息到本地内存中,随后根据登录请求再增量加载其他用户信息,避免一次性加载导致性能问题。
用的mysql啊,redis了解吗?用过吗?
Redis是一种开源的内存数据结构存储系统,它可以用作数据库、缓存和消息中间件。它与传统的关系型数据库(如MySQL)有以下几个主要区别:
- 数据存储形式:
- MySQL是关系型数据库,数据以表格的形式存储,遵循ACID特性。
- Redis是NoSQL数据库,数据以键值对的形式存储,支持多种数据结构,包括字符串、哈希表、列表、集合、有序集合等。
- 数据持久化:
- MySQL是磁盘数据库,数据默认存储在磁盘上,具有良好的持久化能力。
- Redis是内存数据库,数据默认存储在内存中,提供了两种持久化机制(RDB和AOF)来实现数据的持久化。
- 访问速度:
- MySQL作为关系型数据库,需要处理复杂的关系操作,访问速度相对较慢。
- Redis作为内存数据库,访问数据的速度非常快,可以达到亚毫秒级别。
- 使用场景:
- MySQL擅长处理结构化数据,适用于需要复杂查询和事务处理的场景,如电商、金融等。
- Redis擅长处理高并发、低延迟的场景,如缓存、计数器、消息队列、实时应用等。
- 数据一致性:
- MySQL遵循ACID特性,能够提供强一致性保证。
- Redis的一致性相对较弱,需要根据业务需求进行权衡。
总的来说,Redis和MySQL各有优缺点,适用于不同的应用场景。在实际应用中,常常将两者结合使用,利用Redis的高性能缓存来提高整体系统的性能,同时使用MySQL来保证数据的持久性和强一致性。
作为一个内存数据库,Redis的主要优势在于其高性能和多样的数据结构支持。它可以用作以下场景:
- 缓存: 利用Redis的快速访问特性,可以作为应用层的缓存,加快数据访问速度。
- 消息队列: Redis的List数据结构可以用于构建消息队列,支持发布/订阅的消息模式。
- 实时应用: Redis丰富的数据类型可以支持计数器、排行榜等实时应用场景。
- 会话缓存: 可以利用Redis存储用户会话信息,提高Web应用的响应速度。
- 分布式锁: Redis的原子操作可以实现分布式环境下的锁机制。
为什么要用定时器?
处理非活跃连接;如果一个连接长时间不发送消息,系统还要为这个连接保留资源(监视连接的Socket,连接的相关信息),这就会造成新的连接没办法及时处理;
在建立连接时,为每个连接创建一个定时器,如果定时器超时,则触发定时事件,断开连接,清空连接所占据的资源。
说一下定时器的工作原理
使用信号实现定时器;
- 在每一个连接建立时,创建一个定时器,并将该定时器加入到定时器有序链表中;
- 利用
alarm函数周期性地触发SIGALRM信号; - 内核接受到信号之后,将信号放进对应进程的信号队列中;并向进程发起中断;进程收到中断之后从用户态进入内核态;
- 收到信号,进行定时事件处理,定时标志位设置为true,保证处理定时事件时不会被信号中断;
- 进程调用信号处理函数,信号处理函数只负责通知进程有信号要处理,具体的处理逻辑在用户态处理;
- 从内核态进入用户态,处理信号(主循环调用定时任务处理函数,处理到期的定时器):
- 遍历定时器升序链表,从头结点开始遍历;
- 若当前时间小于定时器超时时间,跳出循环,即找到未到期的定时器(此处未到期,后面更都未到期);
- 若当前时间大于定时器超时时间,即找到了到期的定时器,执行回调函数(断开连接,删除对应的资源),然后将它从链表中删除,然后继续向后遍历;
- 信号处理完成,重新进入内核态,然后检测信号队列中是否有信号没有被处理;(回到第四步循环处理信号队列中的信号)
- 如果某连接上发生读、写事件,则对应的定时器在链表中的位置向后移动(有序链表,向后移动就是修改超时事件);
- 如果连接上发生异常,连接被关闭,则从定时器链表中删除该定时器;
双向链表啊,删除和添加的时间复杂度说一下?还可以优化吗?
定时器链表使用了有序双向链表实现;删除节点时间复杂度为O(1),添加节点的时间复杂度为O(n)(需要保证有序,所以插入位置要遍历得到);
为什么使用双向链表而不是单向链表?
- 插入效率:单向链表即使找到插入位置,还要遍历到插入位置的前一个结点才能插入;(可以使用双指针优化),双向链表可以直接插入;
- 定时器更新超时时间时,不需要从头遍历,而是从结点出发,往后遍历即可;
- 删除效率:双向链表删除效率为
O(1),单向链表删除要遍历到被删除节点的前一个结点,所以时间复杂度为O(n);(定时器删除更方便)
定时遍历定时器链表,比较当前时间和定时器时间,设定一个绝对超时时间,如果定时器超时时间小于当前时间,则删除定时器;
优化思路:
- 高效数据结构:
- 平衡二叉搜索树(AVL树、红黑树)来存储定时器节点,插入效率可以降低到 O ( l o g n ) O(log_n) O(logn);
- 跳表存储定时器节点,插入效率也降低到 O ( l o g n ) O(log_n) O(logn);
- 用堆来存储定时器节点,插入效率降低到 O ( l o g n ) O(log_n) O(logn);
- 惰性删除:对于频繁插入和删除定时器的场景,可以考虑惰性删除;在要删除时,并不立即删除,而是先标记为无效,然后定期清理无效的定时器,减少删除操作的频率;
最小堆优化?说一下时间复杂度和工作原理。
定时器链表可以用最小堆进行优化;
工作原理:
- 将所有定时器节点存储在最小堆中,堆的键值为定时器的超时时间。
- 插入定时器节点时,将新节点插入到堆中,并执行向上调整操作以维护堆的性质。
- 删除超时节点时,比较堆顶节点(最小超时时间)与当前时间:
- 如果堆顶节点的超时时间小于等于当前时间,则将堆顶节点删除,并执行向下调整操作以维护堆的性质。
- 重复步骤3,直到堆顶节点的超时时间大于当前时间或堆为空。
- 当需要触发定时器时,可以通过步骤3的方式删除并触发所有超时的定时器节点。
时间复杂度:
- 插入定时器节点:
- 将新节点插入到堆的末尾,时间复杂度为 O ( 1 ) O(1) O(1)。
- 执行向上调整操作以维护堆的性质,调整的次数不超过堆的高度,时间复杂度为 O ( l o g n ) O(log n) O(logn),其中n为堆中节点的数量。
- 因此,插入操作的总时间复杂度为 O ( l o g n ) O(log n) O(logn)。
- 删除超时节点:
- 比较堆顶节点与当前时间,时间复杂度为 O ( 1 ) O(1) O(1)。
- 如果需要删除堆顶节点,将其与堆的最后一个节点交换,并执行向下调整操作以维护堆的性质,调整的次数不超过堆的高度,时间复杂度为 O ( l o g n ) O(log n) O(logn)。
- 在最坏情况下,如果所有节点都超时,则需要删除所有节点,总时间复杂度为 O ( n l o g n ) O(n log n) O(nlogn)。
- 但在实际应用中,通常只有一部分节点会超时,删除操作的平均时间复杂度接近 O ( l o g n ) O(log n) O(logn)。
与使用有序双向链表相比,使用最小堆优化后:
- 插入操作的时间复杂度从 O ( n ) O(n) O(n)降低到 O ( l o g n ) O(log n) O(logn)。
- 删除超时节点的时间复杂度从 O ( n ) O(n) O(n)降低到平均 O ( l o g n ) O(log n) O(logn)。
使用最小堆优化后,我们牺牲了定时器节点的有序性,因为堆中节点的顺序并不完全按照超时时间排序。
说下你的日志系统的运行机制?
使用单例模式创建日志系统,对服务器运行状态、错误信息、访问数据等进行记录;将生产者-消费者模型封装为阻塞队列,创建一个写线程,工作线程将要写的内容Push进阻塞队列,写线程从阻塞队列中Pop出数据,写入日志文件;
单例模式:保证了日志类在全局中只有一个实例;日志模块要被多个模块共享和调用,如果系统中有多个日志实例,会导致多个模块创建和管理的日志对象不是一个,导致混乱和不一致;(日志写入重复、日志级别不一致、日志输出格式不一致、日志存储位置不一致、日志配置不一致)
生产者消费者模型:工作线程和日志线程共享一个缓冲区,工作线程往缓存区中Push消息,日志线程从缓存区中Pop消息;使用条件变量实现线程之间的通知机制;
阻塞队列:用循环数组实现;(循环数组就是普通的数组,在添加元素时取余数组容量。保证添加元素不会越界)

使用了懒汉模式(第一次获取才初始化实例),生成日志文件,如果阻塞队列大小设置为1,即表示同步日志,如果阻塞队列大小不设置为1,即表示异步日志;
- 分文件判断:根据Day日期来判断,如果存在同一天创建的日志文件,则写入该文件,如果不存在,则创建;如果日志文件超出最大行数,则将文件名+
count/max_lines后缀新创建文件(超行、按天分文件逻辑) - 格式化输出:格式化时间+格式化内容
- 日志级别:Debug, Warn, Info, Error, Fatal
- 日志行数(加入最大行数判断)
- 格式化时间和内容,2024-04-26 12:47:30
为什么要异步?和同步的区别是什么?
在同步日志中,每次写日志时都需要等待写入操作完成后才返回,阻塞当前线程或进程的执行,直到日志写入完毕才能继续执行后续操作。
异步日志不需要等待日志写入完毕之后才继续执行后续操作,而是将日志要写入的内容挂载到阻塞队列上,日志写入由单独的线程来处理,不会阻塞当前线程或进程的进行。
异步日志的好处:
- 提高程序性能:
- 异步日志将日志写入操作和业务逻辑分离,使得程序在写日志时能够继续执行其他操作,不会因为等待日志写入而阻塞程序的执行,提高了程序的性能。
- 降低日志对程序的影响:
- 异步日志能够避免由于频繁的日志输出而对程序性能产生较大影响,保证程序的稳定性和可靠性。
- 日志写入效率高:
- 异步日志将日志写入操作交给后台线程异步处理,可以利用缓冲区、批量写入等技术提高日志写入效率,减少频繁的磁盘IO操作。
- 提升系统响应速度:
- 异步日志能够快速记录日志信息,有助于快速定位问题、分析系统状态,提高系统的响应速度和可维护性。
现在你要监控一台服务器的状态,输出监控日志,请问如何将该日志分发到不同的机器上?(消息队列)
- 设置消息队列:
- 在系统中搭建消息队列服务,比如使用RabbitMQ、Kafka、Redis等消息中间件作为消息队列,确保各节点的消息队列服务正常运行。
- 编写日志分发程序:
- 在监控服务器上编写一个日志分发程序,该程序负责将监控日志发送到消息队列中。在程序中,将监控日志封装成消息,然后发送到消息队列中。
- 编写消费者程序:
- 在需要接收监控日志的机器上编写消费者程序,用于从消息队列中获取日志消息并处理。消费者程序可以订阅消息队列中的指定主题或队列,接收来自监控服务器的日志消息。
- 配置消息队列:
- 配置消息队列的主题或队列,确保监控服务器的日志消息可以被正确路由到需要接收日志的机器上。
- 启动程序:
- 在监控服务器和接收日志的机器上分别启动编写的日志分发程序和消费者程序,确保消息队列中的日志能够正常传输和处理。
服务器并发量测试过吗?怎么测试的?
使用Webbench测试;
// 10个并发连接,测试5秒,对 http://43.139.65.13:9007/ 进行GET请求
webbench -c 10 -t 5 http://43.139.65.13:9007/
// 使用1000个并发连接,每个连接发送100次请求,对 http://43.139.65.13:9007/ 进行POST请求
webbench -c 1000 -r 100 -f POST http://43.139.65.13:9007/0
// 输出冗长的调试信息,对 https://api.example.com进行HEAD请求
webbench -v --head http://43.139.65.13:9007/
-f指定使用的HTTP请求方法,默认为GET,可选POST-c设置并发连接数,即模拟多少个并发客户端-t设置测试运行的总时间,单位为秒-r每个客户端执行的请求次数-H添加HTTP头信息-p使用代理服务器,后接代理服务器的地址和端口号-v输出冗长的运行信息--get/--head/--post指定HTTP方法
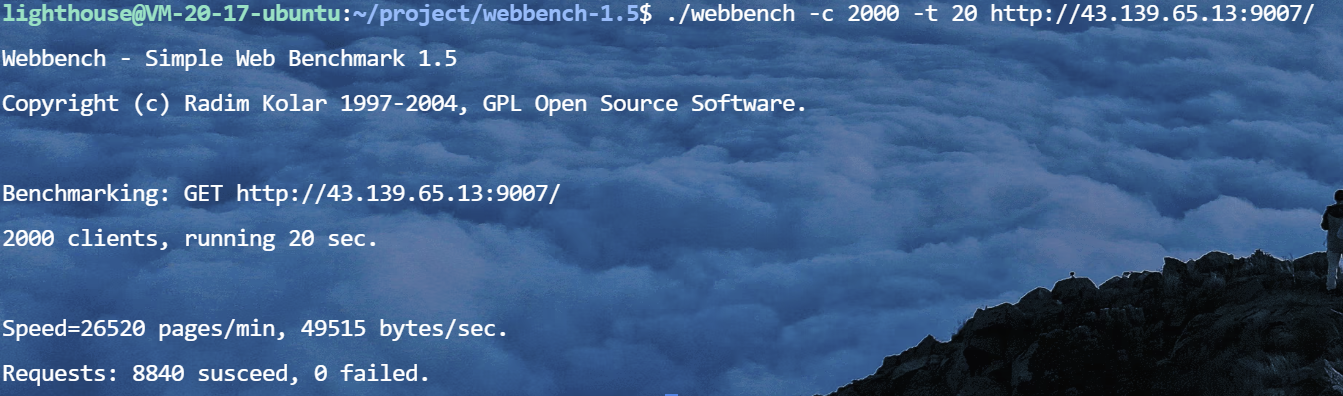
-
测试参数:(增加并发量或直接测试时长来看服务器反应)
-
并发客户端数: 2000;
-
测试时长: 20 秒;
-
-
测试结果:
-
访问速度: 26520 页面/分钟;
-
吞吐量: 49515 bytes/秒;
-
成功请求数: 8840;
-
失败请求数: 0;
-
- 响应速度非常快,达到每分钟26520页面,说明服务器的处理能力很强。
- 吞吐量也非常高,每秒约49.5KB,说明网络带宽也足够支撑高并发访问。
- 所有2000个并发请求都得到了成功响应,没有任何失败,表明服务器的稳定性也很好。
这个服务器在高并发压力下的表现非常优秀,可以满足绝大部分应用场景的需求。
受限于服务器本身的资源限制(内存、系统进程限制等),所以没办法增加并发客户端数量来测试;
设置测试参数:并发客户端4000和测试时间50秒;

基本没有变化,访问速度和吞吐量基本接近,说明高并发下稳定性也很不错;
webbench是什么?介绍一下原理。
- 主进程启动后,会根据命令行参数指定的并发连接数
fork出相应数量的子进程。 - 每个子进程中会循环发起HTTP请求到目标Web服务器,模拟并发连接。子进程会统计自身的请求数据,包括发出的请求数、接收的字节数等。
- 子进程通过**管道(pipe)**将统计数据发送给父进程。
- 父进程则汇总并统计所有子进程的数据,包括总请求数、总数据传输量、每秒请求数(QPS)等,最后输出统计结果。
- 测试完成后,父进程会等待子进程退出,再结束自身。
(父进程fork()出足量子进程,子进程发出HTTP请求,子进程将结果用管道发送给父进程,父进程统计汇总子进程的数据)
测试的时候有没有遇到问题?
Webbench压力测试时,我发现并发连接数到达3000时,第2194个连接会失败。
查看服务器日志:
The requested file was not found on this server.
2024-05-13 16:31:51.464279 [info]: adjust timer once
2024-05-13 16:31:51.464309 [info]: close fd 22
2024-05-13 16:31:51.483207 [info]: deal with the client(43.139.65.13)
2024-05-13 16:31:51.483286 [info]: GET / HTTP/1.0
2024-05-13 16:31:51.483303 [info]: request:HTTP/1.1 404 Not Found
2024-05-13 16:31:51.483315 [info]: request:HTTP/1.1 404 Not Found
Content-Length:49
2024-05-13 16:31:51.483325 [info]: request:HTTP/1.1 404 Not Found
Content-Length:49
Connection:close
2024-05-13 16:31:51.483335 [info]: request:HTTP/1.1 404 Not Found
Content-Length:49
Connection:close
2024-05-13 16:31:51.483340 [info]: request:HTTP/1.1 404 Not Found
Content-Length:49
Connection:close
The requested file was not found on this server.
2024-05-13 16:31:51.483360 [info]: adjust timer once
2024-05-13 16:31:51.483398 [info]: close fd 18
2024-05-13 16:31:51.749051 [info]: close fd 28
2024-05-13 16:31:51.748844 [erro]: accept error:errno is:11
2024-05-13 16:31:51.748936 [info]: close fd 20
2024-05-13 16:31:51.748967 [info]: close fd 24
2024-05-13 16:31:51.748983 [info]: close fd 19
2024-05-13 16:31:51.748998 [info]: close fd 21
2024-05-13 16:31:51.749012 [info]: close fd 23
2024-05-13 16:31:51.749030 [info]: close fd 22
2024-05-13 16:31:51.749040 [info]: close fd 27
2024-05-13 16:31:51.758114 [info]: close fd 26
2024-05-13 16:31:51.776166 [erro]: accept error:errno is:11
2024-05-13 16:31:51.779423 [info]: close fd 18
2024-05-13 16:31:51.784707 [info]: close fd 19
2024-05-13 16:31:51.790641 [info]: close fd 25
2024-05-13 16:31:51.839220 [erro]: accept error:errno is:11
2024-05-13 16:31:51.839279 [info]: close fd 18
2024-05-13 16:31:54.171286 [erro]: accept error:errno is:11
2024-05-13 16:31:54.171350 [info]: close fd 18
2024-05-13 16:31:54.171405 [info]: close fd 19
2024-05-13 16:32:02.363271 [erro]: accept error:errno is:11
2024-05-13 16:32:02.363347 [info]: close fd 18
2024-05-13 16:32:02.363393 [info]: close fd 19
2024-05-13 16:32:02.363416 [info]: close fd 20
2024-05-13 16:32:02.363586 [erro]: accept error:errno is:11
分析日志:
accept error: errno is 11- 多次出现 “
accept error: errno is 11” 的错误,这是一个关键线索。 errno 11通常对应于EAGAIN或EWOULDBLOCK错误,表示资源暂时不可用。- 在这种情况下,通常意味着服务器的连接队列已满,无法接受新的连接请求。
- 多次出现 “
- 频繁关闭文件描述符
- 日志中频繁出现 “
close fd” 的信息,表示服务器在不断关闭客户端连接。 - 这可能是因为服务器无法及时处理所有请求,导致连接超时或被强制关闭。
- 日志中频繁出现 “
优化思路:
- 增加连接队列大小,以容纳更多的并发连接。
- 优化服务器程序,提高请求处理效率,减少处理时间。
- 检查服务器的文档根目录配置,确保请求的资源存在。
- 增加服务器的硬件资源,如 CPU、内存、网络带宽等,以应对更高的并发压力。
可能是由于服务器系统限制,对于最大进程数量和最大文件描述符数量有限制,普通用户无法修改最大进程数量到很大的数值,所以先进入root用户;
#进入root用户
sudo su -
#查看最大进程数量
ulimit -u
#修改最大进程数量
ulimit -u 20000
#修改最大文件描述符数量
ulimit -n 20000
#扩大并发数量到7000
./webbench -c 7000 -t 5 http://43.139.65.13:9007/
在第4879个子进程创建时错误,说明提高最大进程数量有效果;继续增加最大进程数量,但是实际并发数量没有增加;
增大测试时间,发现产生以下信息:
/root/.orca_term/orca-data.sh: fork: retry: Resource temporarily unavailable
说明一个进程尝试用fork()创建一个子进程时,遇到了资源暂时不可用的情况,这个错误信息表示无法创建子进程,且正在尝试重新执行fork系统调用以创建子进程;一般是由于系统资源不足;
你的项目解决了哪些其他同类项目没有解决的问题?
特点:线程池、数据库连接池、定时器
说一下前端发送请求后,服务器处理的过程,中间涉及哪些协议?
-
建立TCP/IP连接(TCP/IP协议)
- 客户端创建一个Socket套接字用于和服务器通信;
- 设置Socket套接字的服务器的IP地址和端口号;并通过connect函数和服务器建立连接;
- 客户端向服务器发送连接请求(第一次握手);
- 服务器收到连接请求,也建立一个新的Socket用于和该客户端通信;
- 服务器发送ACK响应,客户端收到之后也会发送一个ACK响应,服务器收到客户端的ACK响应;
- 三次握手完毕,连接建立,可以通信;
- Socket的文件描述符加入EPOLL监视的文件描述符组中;
-
客户端发送HTTP请求报文;
-
服务器EPOLL监视到Socket上有读就绪事件;
-
服务器取出Socket上的HTTP请求报文,然后创建一个HTTP请求对象,将其挂载到消息队列上;
-
消息队列利用信号量唤醒工作线程,工作线程取出消息队列上的任务进行处理;
-
利用主从状态机分别处理请求行、请求头、请求体:
- 从状态机(3种状态,LINE_OK,LINE_OPEN,LINE_BAD)
- 将报文中的
\r\n替换为\0\0,并返回LINE_OK;
- 将报文中的
- 主状态机(分别解析请求行、请求头、请求体)
- 解析请求行
- 解析请求头
- 解析请求体
- 解析完成之后,从数据库连接池中取出一个连接,然后执行生成响应报文;
- 从状态机(3种状态,LINE_OK,LINE_OPEN,LINE_BAD)
-
生成响应报文:
- 响应行:HTTP协议、状态码、状态信息;
- 响应头;
- 响应体(包括注册和登录校验,以及页面跳转逻辑);
-
将响应报文挂载到消息队列上;
-
消息队列通知主线程取出消息封装为响应报文写Socket;
数据库连接池如何实现?
如果不使用池,每一个HTTP连接都要创建和销毁数据库连接,开销大,耗时长,并且对数据库造成安全隐患;
使用单例模式和链表创建数据库连接池,实现对数据库连接资源的复用;
池是静态资源,所以使用单例模式,让全局只有一个实例;
项目中的数据库模块分为两部分:
- 数据库连接池的定义,使用单例模式和链表创建数据库连接池;
- 利用连接池完成登录和注册的校验功能:具体的,工作线程从数据库连接池取得一个连接,访问数据库中的数据,访问完毕后将连接交还连接池。
整个项目的流程图是什么样的?

如果服务器在运行的过程中,实际存储的文件被其他用户修改了,会发生什么?
导致的问题:
- 数据不一致:如果被篡改的文件也正在被服务器读,则可能导致数据不一致;
- 程序奔溃或终止:如果服务器运行依赖于某些文件,这些文件被篡改之后会导致程序崩溃;
- 安全漏洞或未授权访问:用户通过修改配置文件或注入恶意代码等方式,获取到服务器的未授权访问或控制权限;
- 日志记录不准确:篡改日志文件导致日志记录不准确;
- 服务器行为的不可预测:篡改文件之后,可能导致服务器执行不可预测的任务,使得出现异常行为;
防止问题的方式:
- 严格控制文件的访问权限;只允许授权用户或进程对文件进行读写操作;
- 定期监控文件的完整性:利用数字签名和校验等技术检测文件是否被篡改;
- 对关键文件进行备份和版本控制;
- 对文件的修改操作进行审计和日志记录,跟踪文件的变更历史和操作人;
- 使用访问控制和安全机制:对文件加密、访问控制列表ACL等进一步保护文件的安全性;
如果服务器崩溃的话,你的日志系统会发生什么?
日志系统是异步实现的,所以在奔溃时,阻塞队列中的日志可能没有被写入日志文件,所以未写入日志文件的日志都会丢失,并且最后一条日志记录的时间可能早于奔溃时间;奔溃事件并不会被记录到日志文件中;
优化:尽量记录重要日志,减少奔溃损失;记录奔溃时间,方便找到奔溃原因;
这个问题应该怎么解决?
- 增加日志优先级:
- 对于重要的日志(比如错误日志),设置更高的日志级别,确保其优先被写入(但是这么一来,日志写入顺序就不是时间戳顺序了,只能在最后按照时间戳排序,在日志的可靠性和日志的顺序性权衡)
- 记录关键事件的事件戳:
- 对于服务器启动、关闭等关键事件,直接写入日志文件,不先存入阻塞队列异步写入;
- 即使发生奔溃,也可以通过时间戳推测出事件发生的时间,便于故障分析;
- 服务器虽然没办法在奔溃时写入时间戳;但是可以用其他方式来获取服务器崩溃的大致时间:
- 外部监控系统:外部监控系统在服务器崩溃时,发现服务器无法响应,记录下时间戳,作为服务器崩溃的时间;
- 操作系统的事件日志,如果服务器奔溃,通常会在操作系统中留下一些线索,比如内核奔溃日志、应用程序错误日志等,通过分析这些日志,推断出服务器奔溃的大致时间;
- 对比崩溃前最后一条日志的时间戳和崩溃后第一条日志的时间戳,可以缩小崩溃事件的时间范围;
- 利用文件系统的元数据消息,如果奔溃时正在写入日志文件,则写入时间和奔溃时间大致相近;
- 使用多个日志文件(分优先级日志文件),减少单个文件的写入压力(如果只有一个日志文件,则线程写该文件加锁,其他线程就不能写该日志文件)
将整个数据库中的用户名和密码复制到内存中保存为map,相比直接使用SELECT语句查找用户名和密码的优点和缺点?
优点:
- 查询速度快: 将数据加载到内存中的map结构,可以实现O(1)时间复杂度的快速查找。相比之下,使用SELECT语句需要与数据库进行交互,查询速度相对较慢。
- 减轻数据库压力: 如果频繁地进行用户名和密码的查询,直接从内存中获取数据可以减少对数据库的访问,降低数据库的负载。
- 提高并发性能: 内存访问的速度远快于磁盘I/O,在高并发场景下,从内存中获取数据可以提供更好的并发性能。
缺点:
- 内存占用: 将整个用户名和密码数据加载到内存中,会占用一定的内存空间。如果数据量很大,可能会对内存资源造成压力。
- 数据一致性问题: 内存中的数据与数据库中的数据可能存在不一致的情况。如果在加载数据到内存后,数据库中的用户名和密码发生了变化,内存中的数据就会与数据库不一致。
- 数据安全性: 将用户名和密码明文存储在内存中,存在一定的安全隐患。如果程序存在漏洞或者服务器被入侵,攻击者可能会直接获取到内存中的敏感数据。
- 启动时间: 在应用程序启动时,需要花费一定的时间将数据从数据库加载到内存中,这会影响应用的启动速度。
总的来说,将用户名和密码数据加载到内存中作为缓存,可以提高查询性能和并发能力,但同时也引入了内存占用、数据一致性和安全性等问题。在实际应用中,需要根据具体的需求和场景,权衡利弊,选择合适的方案。如果数据量不大、并发要求高、数据变化不频繁,使用内存缓存可能是一个不错的选择。但如果数据量很大、数据变化频繁,或者对数据一致性和安全性要求很高,则需要谨慎评估使用内存缓存的风险和成本。


















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











