







本篇源码解析主要来自于对overwrite覆盖写模式的好奇,想追踪下具体覆盖写的流程和如何进行的覆盖重写?
sparksql insertinto 主要功能是向已有表中插入数据,其有四种模式:
append:向已有数据源追加数据
overwrite:向已有数据源覆盖写入
ErrorIfExists:写入的数据源中如果已经有数据则抛异常
Ignore:如果数据源中数据以及存在则不作处理
四种模式中,后两种是对特殊情况的一种处理,本篇文章没有研究,这里主要看下前两种模式的写入逻辑,特别是overwrite的写入逻辑,因为我本地测试过,加入表中数据有4条,然后通过overwrite方式插入三条数据,那么最终数据只有三条,所以在overwrite的过程中应该是有个数据清除的操作存在的,只不过不知道这个清除是插入之前清,还是插入之后进行处理。因此写了本篇文章,想看下其中具体的源码逻辑。
1、全量表源码追踪
1.1、准备操作
分别创建全量表A、全量表B、以及通过sql向表A插入三条数据,后续写入就是通过sparksql查询表A的数据然后插入到表B中。
1)创建全量表A
CREATE TABLE IF NOT EXISTS wyt.test_insertinto_da_A(
`name` STRING COMMENT 'name',
`type` STRING COMMENT 'type',
`area` STRING COMMENT 'area',
`price` BIGINT COMMENT 'price',
`num` BIGINT COMMENT 'num',
`id` BIGINT COMMENT 'id'
) COMMENT '全量表A'
STORED AS parquet
2)创建全量表B
CREATE TABLE IF NOT EXISTS wyt.test_insertinto_da_B(
`name` STRING COMMENT 'name',
`type` STRING COMMENT 'type',
`area` STRING COMMENT 'area',
`price` BIGINT COMMENT 'price',
`num` BIGINT COMMENT 'num',
`id` BIGINT COMMENT 'id'
) COMMENT '全量表B'
STORED AS parquet
3)向全量表A插入数据
insert into table test_insertinto_da_A values('名称1','类型1','南京',100,10,1),('名称2','类型3','苏州',300,120,2),('名称3','类型2','南通',200,101,3);
编辑sparksql代码,这里我贴出我的demo供大家参考下:
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root");
val sparkSession = SparkSession.builder()
.appName("parquetTest")
.master("local")
.enableHiveSupport()
.config("spark.sql.optimizer.planChangeLog.level", "WARN")
.getOrCreate()
sparkSession.sql("use wyt");
val data = sparkSession.sql("select * from test_insertinto_da_a")
data.show()
data.write.mode(SaveMode.Overwrite).insertInto("test_insertinto_da_b")
}1.2、源码追踪
这里我们直接到insertInto方法中进行查看:
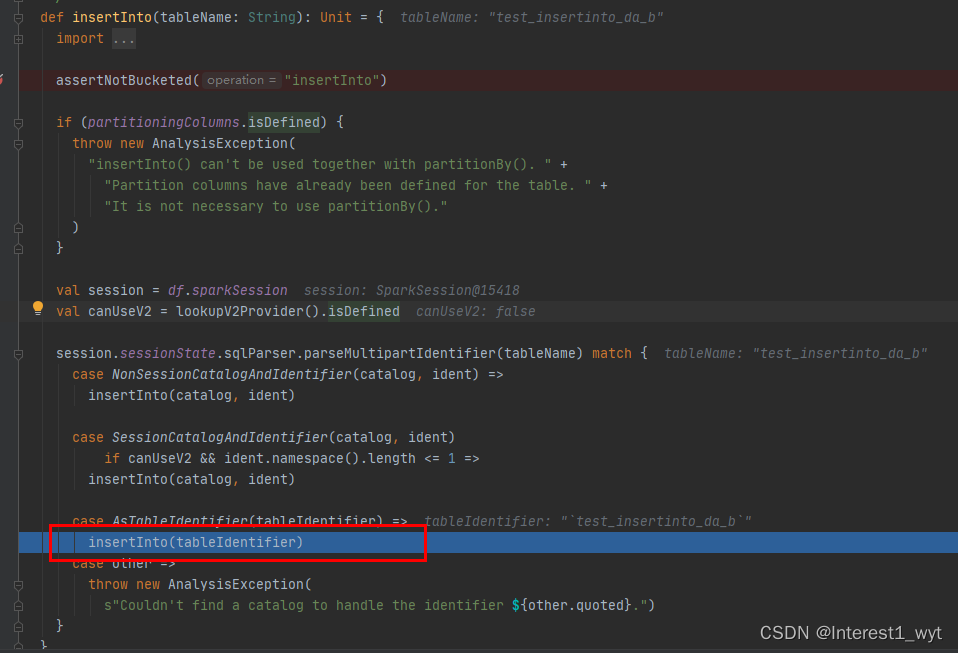
可以看到,insertInto方法中会根据我们要插入的表的情况选用不同的insertInto重载方法,我们根据debug流程接着看:
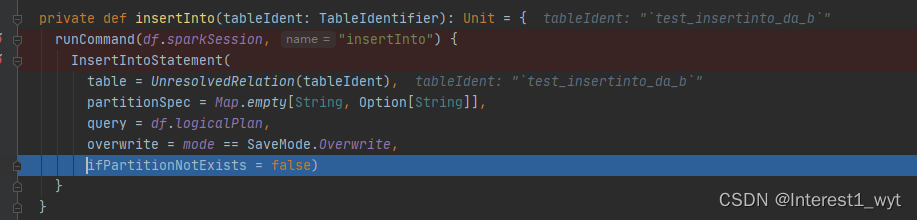
可以看到在insertInto内部是调用了runCommand方法,我们再接着看下:

在runCommand中将我们的InsertIntoStatement命令封装到了QueryExecution对象中,这里InsertIntoStatement是一种逻辑计划,而QueryExecution正是控制逻辑计划解析优化执行的重要对象。所以到此为止可以推测出插入命令最后还是要走逻辑计划到物理计划的转换步骤。而具体的执行操作肯定也是在物理计划中执行,所以中间的解析优化我们不要过多在意,主要看下最后的物理算子是如何执行的。那么如何定位物理算子呢,正常情况如果不知道那就接着向下走,但是这里其实给了提示,就是当前方法的第二行注释,说调用toRDD会触发整个命令的执行,所以在后续的时候可以再多留意下这块的执行。接着到withNewExecutionId方法看一下:
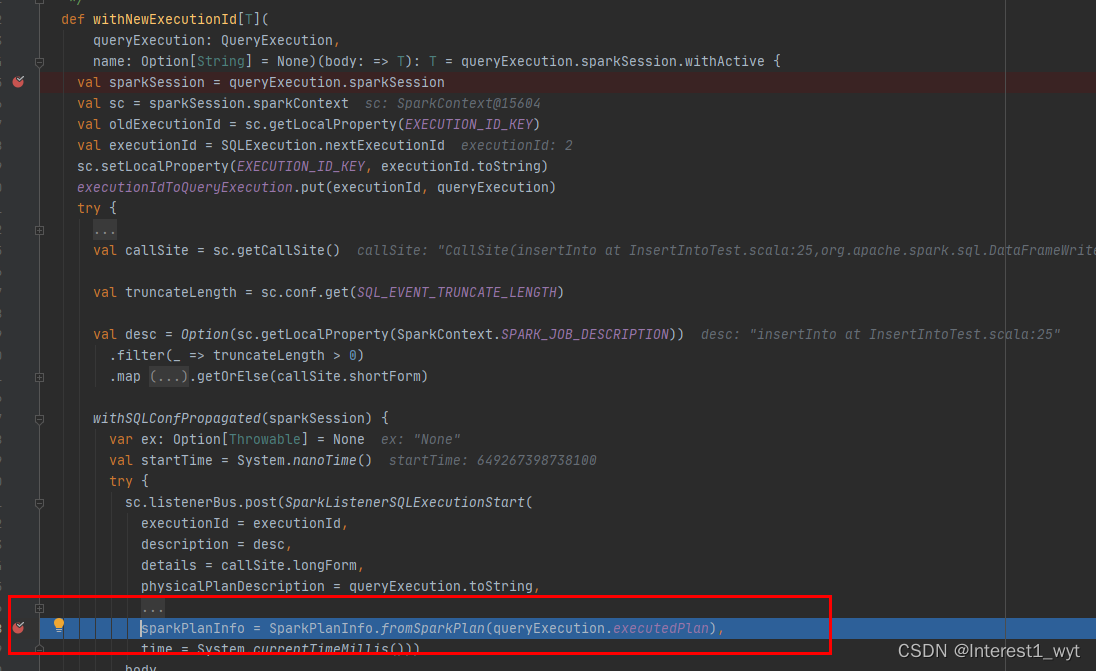
可以看到一个比较核心的信息,就是sparkplanInfo赋值的这一行,我们知道在spark中物理计划的生成中和sparkplan的关系很密切,所以我们可以进入看一下,根据代码执行顺序,首先看下queryExecution.executedPlan:
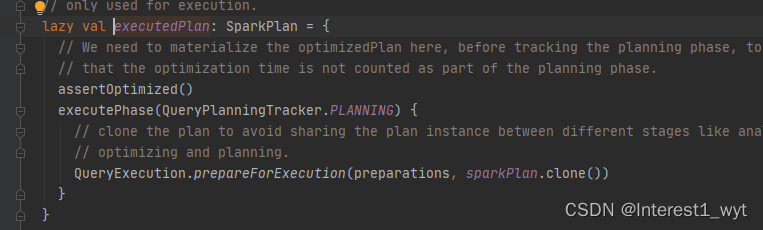
可以看到这是一个懒加载方法变量,只有在实际用到时才会执行,所以我们这里放开所有断点,只在我们的demo中和此处加断点,可以看到如下信息: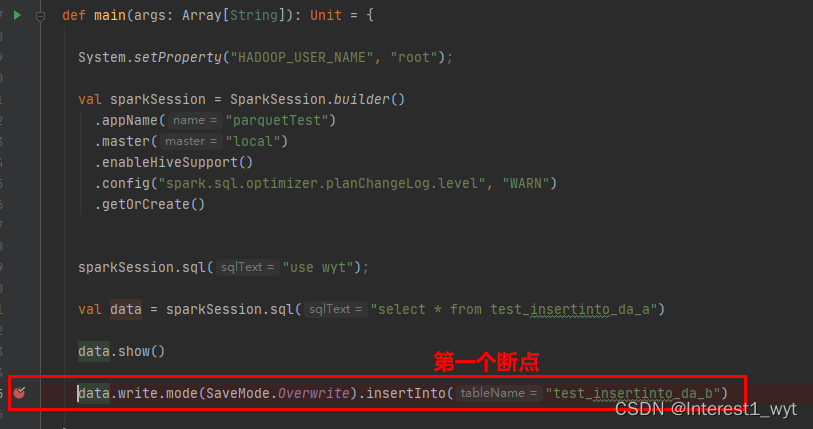

第一张图片没什么说的,加断点就行,第二张图片则比较重要,首先就是断点拦截的时候,如果没经过第一个断点,第二个断点不要加,其次当前插入逻辑的物理执行计划对象其实已经可以看到了,也就是InsertIntoHadoopFsRelationCommand,那什么时候调用该对象执行呢?
还记得我们再runCommand中看到的方法注释吗,当我们调用toRdd的时候开始触发执行,接下来我们放开断点接着看下:
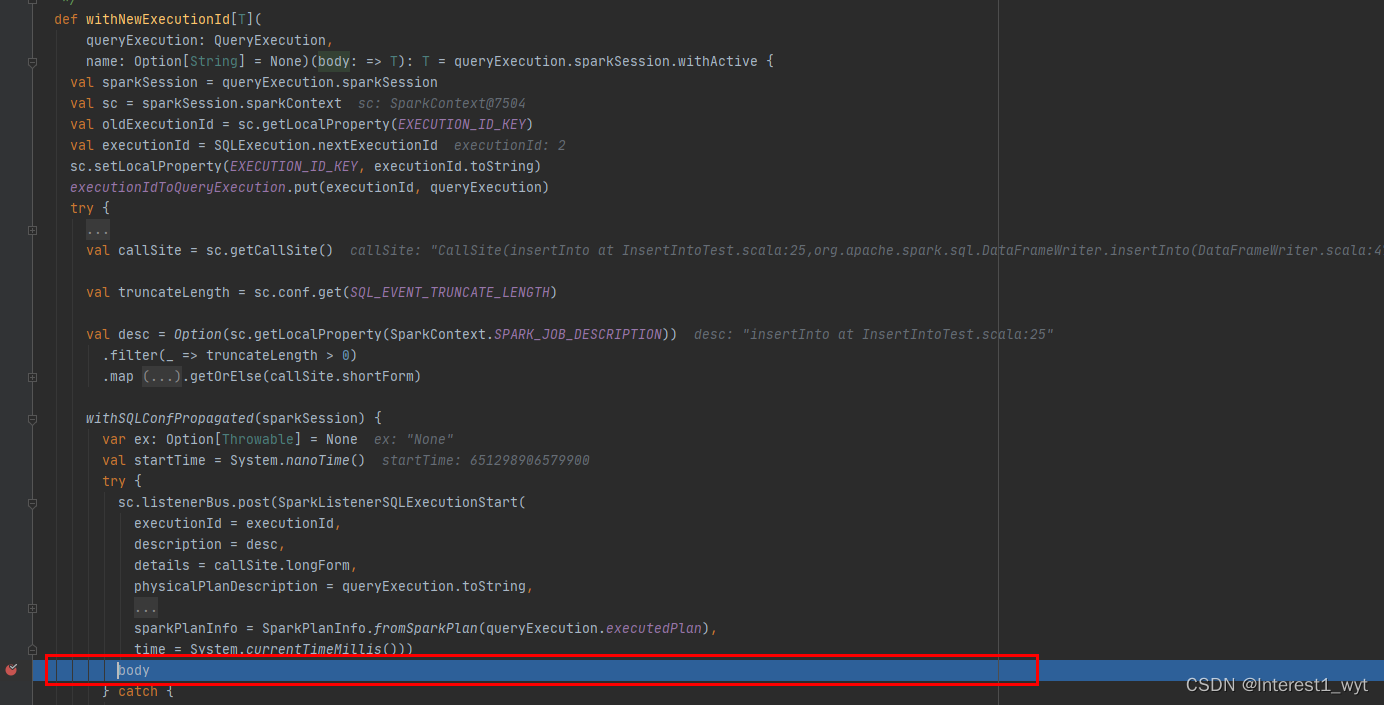
可以看到执行到了withNewExecutionId方法的body处,而查看方法的入参可以知道,这个body就是toRdd方法的返回,所以执行到body时开始触发插入的执行。
body触发执行后中间其实会有一系列高阶函数的封装调用,最后会调用到具体的插入处理类InsertIntoHadoopFsRelationCommand中,因为高阶函数的调用比较复杂而且比较绕,这里不过多叙述,我们直接在具体的处理类中加上断点进行查看:
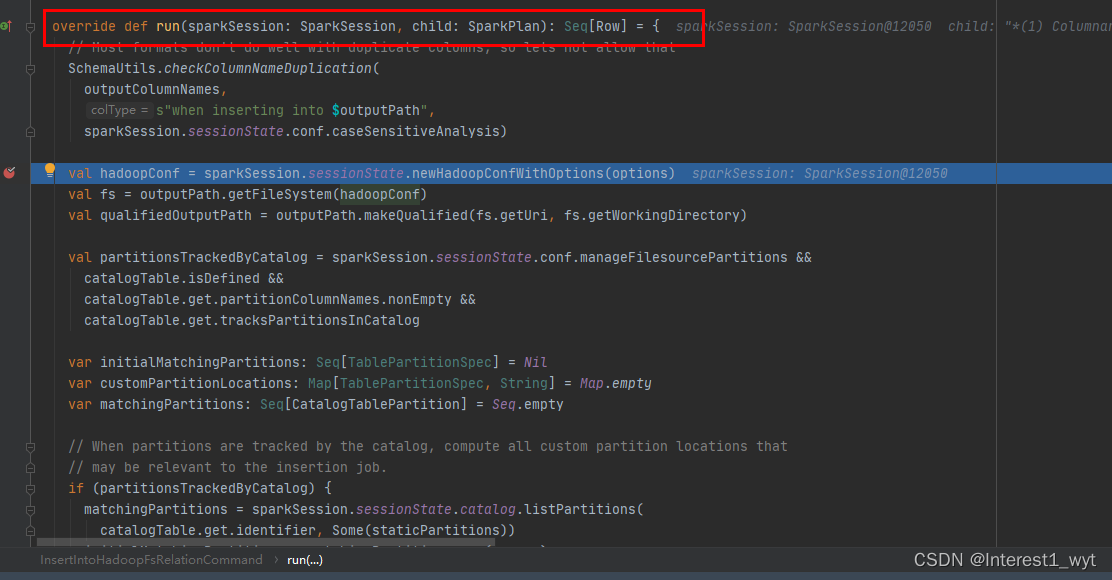
处理对象的方法一般是定义在run方法中,所以我们在该方法中加入断点来查看,现在我们已经进入该方法,下面来一步步看下:
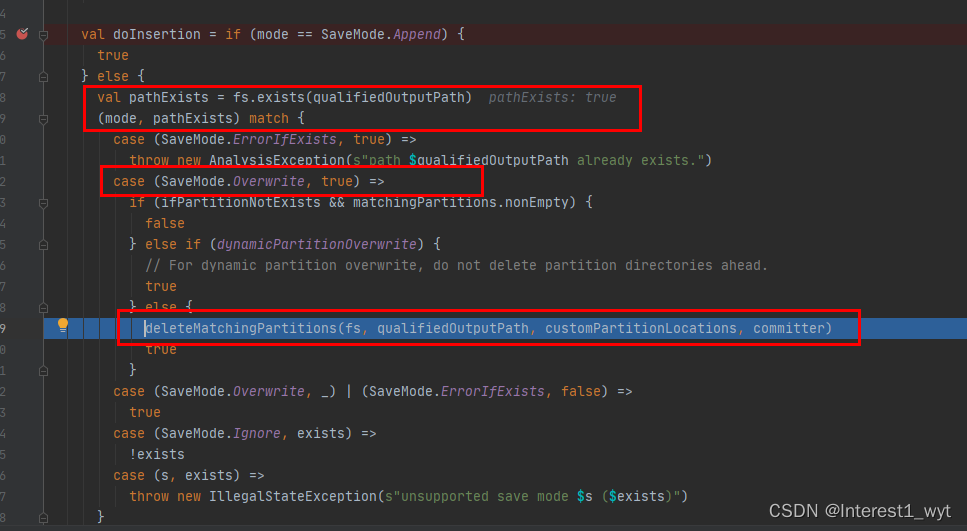
可以看到有个很关键的一步,就是根据文件路径是否存在以及存储类型是否为overwrite来判断是否要删除匹配的分区数据。而我们使用的是覆盖写的插入方式,所以需要清除分区信息。执行完这一行代码后我们来到hdfs上看下效果

可以看到hdfs上文件的信息被删除了。我们再接着看下后续的代码:
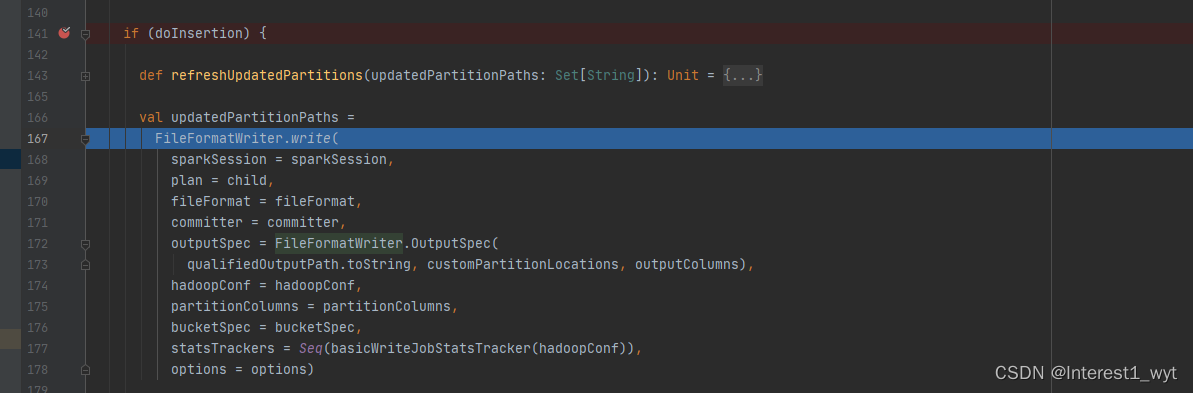
可以看到,再执行完上述的删除操作后,表中的数据又恢复了

至此我们的全量表的覆盖写逻辑已经清楚了,其实对于追加写我们再改类中也可以看出来一点东西来,因为对于Append模式没有任何的清除或者抛异常处理,所以后面都是直接执行数据追加到文件中。
SaveMode.OverWrite模式InsertInto hive中全量表,会先删除hdfs上的文件和表路径信息,随后在重新写入。
2、分区表源码追踪
2.1、准备操作
分别创建分区表A、分区表B、以及通过sql向表A插入三条数据,后续写入就是通过sparksql查询表A的“2022-09-02”分区数据然后插入到表B中。
1)创建分区表A
CREATE TABLE IF NOT EXISTS wyt.test_insertinto_de_A(
`name` STRING COMMENT 'name',
`type` STRING COMMENT 'type',
`area` STRING COMMENT 'area',
`price` BIGINT COMMENT 'price',
`num` BIGINT COMMENT 'num',
`id` BIGINT COMMENT 'id'
) COMMENT 'olap测试分区事实表'
PARTITIONED BY (`dt` STRING comment 'dt')
STORED AS parquet
2)创建分区表B
CREATE TABLE IF NOT EXISTS wyt.test_insertinto_de_B(
`name` STRING COMMENT 'name',
`type` STRING COMMENT 'type',
`area` STRING COMMENT 'area',
`price` BIGINT COMMENT 'price',
`num` BIGINT COMMENT 'num',
`id` BIGINT COMMENT 'id'
) COMMENT 'olap测试分区事实表'
PARTITIONED BY (`dt` STRING comment 'dt')
STORED AS parquet
3)向分区表A插入数据
insert into table test_insertinto_de_a partition(dt='2022-09-01') values('名称1','类型1','南京',100,10,1);
insert into table test_insertinto_de_a partition(dt='2022-09-02') values('名称2','类型3','苏州',300,120,2);
insert into table test_insertinto_de_a partition(dt='2022-09-03') values('名称3','类型2','南通',200,101,3); 编辑sparksql代码,这里我贴出我的demo供大家参考下:
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root");
val sparkSession = SparkSession.builder()
.appName("parquetTest")
.master("local")
.enableHiveSupport()
.config("spark.sql.optimizer.planChangeLog.level", "WARN")
.getOrCreate()
sparkSession.sql("use wyt");
val data = sparkSession.sql("select * from test_insertinto_de_a where dt = '2022-09-02'")
data.show()
data.write.mode(SaveMode.Overwrite).insertInto("test_insertinto_de_b")
}2.2、源码追踪
测试demo和源码追踪流程类型,而且核心处理类也是InsertIntoHadoopFsRelationCommand。前面的源码追踪流程这里就不贴,这里直接从InsertIntoHadoopFsRelationCommand开始看:
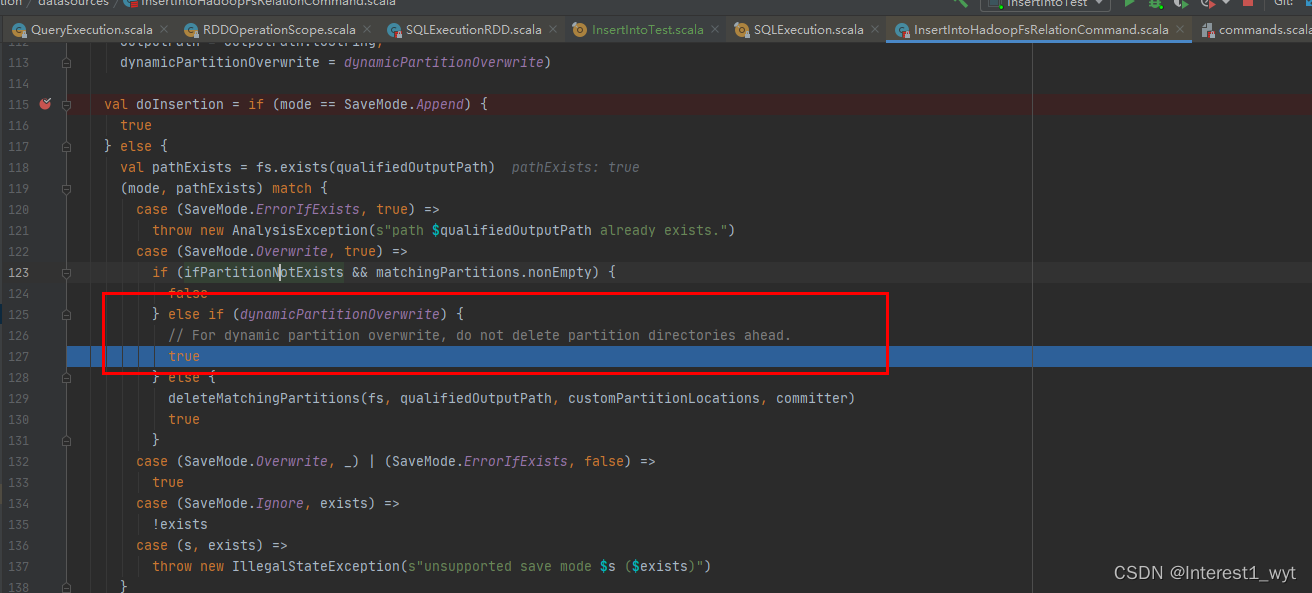
可以看到全量表和分区表insertInto一个比较大的差异是,在处理阶段不会直接删除文件了。接着我们跟随debug流程看下:

首先是调用write方法,在write方法内部会发起一个写task的执行:
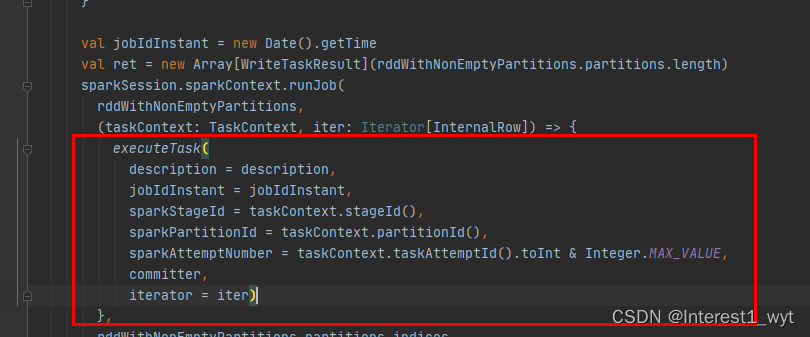
而在executeTask中又会根据写入的场景,创建支持动态分区写入的对象DynamicPartitionDataWriter,如下:

接下来就是调用该对象进行分区数据的写入:

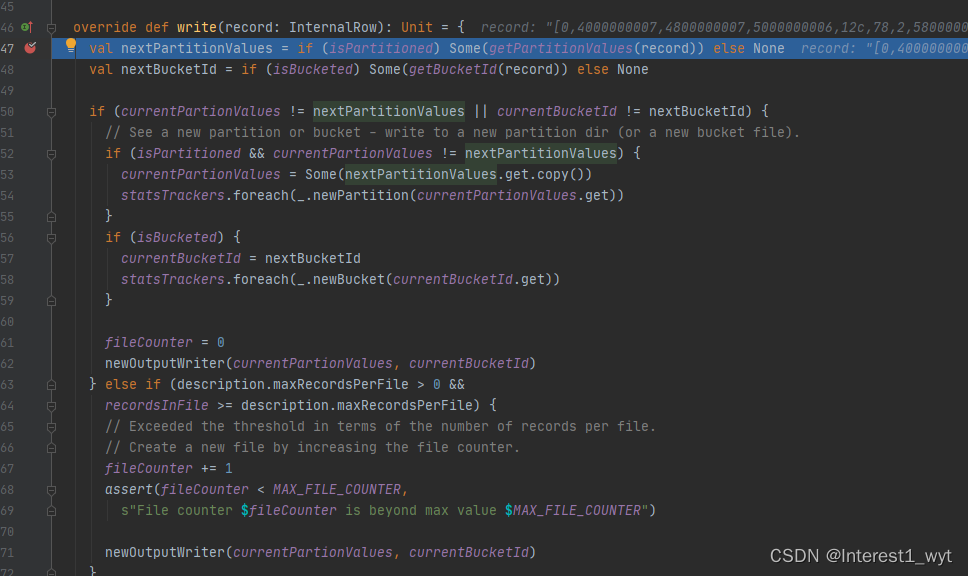
中间还会根据场景重新创建writer,在重新创建writer时有个比较关键的点千万不要忽略,就是动态分区写入的并不是直接写入分区目录,而是先写入一个临时目录,如下:
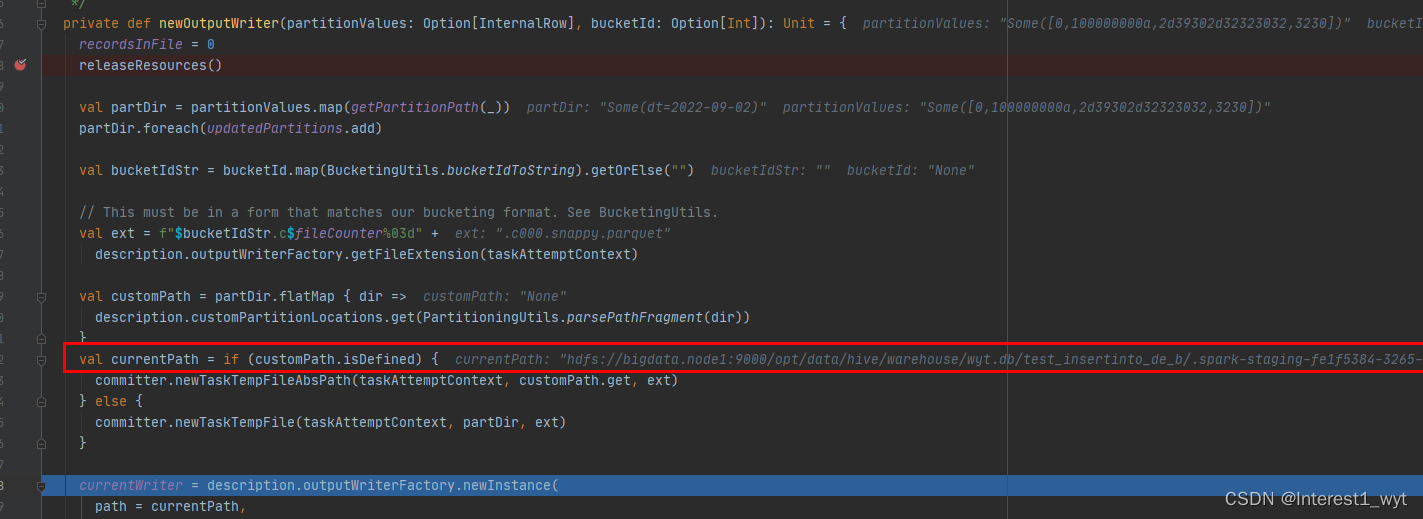
所以可以推测出在在动态分区数据导入的过程中是不影响之前已有数据的使用的,而在动态分区临时目录中文件写入结束后,肯定还有一个文件移动替换或者删除替换的操作。所以下面我们对于写入不在深入追踪,而是看下其写完之后的处理逻辑:
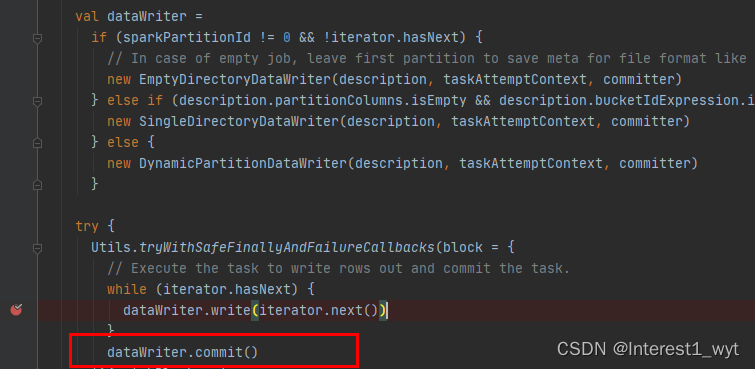
写结束之后是一个提交操作,接下来我们再看下commit的逻辑:
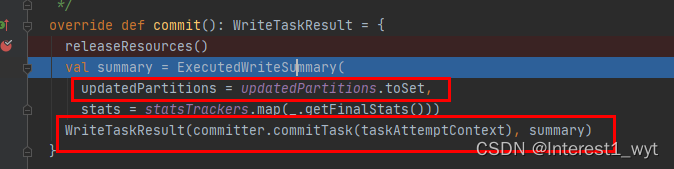
在commit方法中,将要更新的分区以及分区更新的状态封装到了一个对象中,然后再封装到一个task中,然后就返回了,剩下则是task执行的内容,到这我们并没有看到临时目录下的文件如何移动或者替换到分区内,于是我在该task执行结束的地方又加了个断点继续追踪:
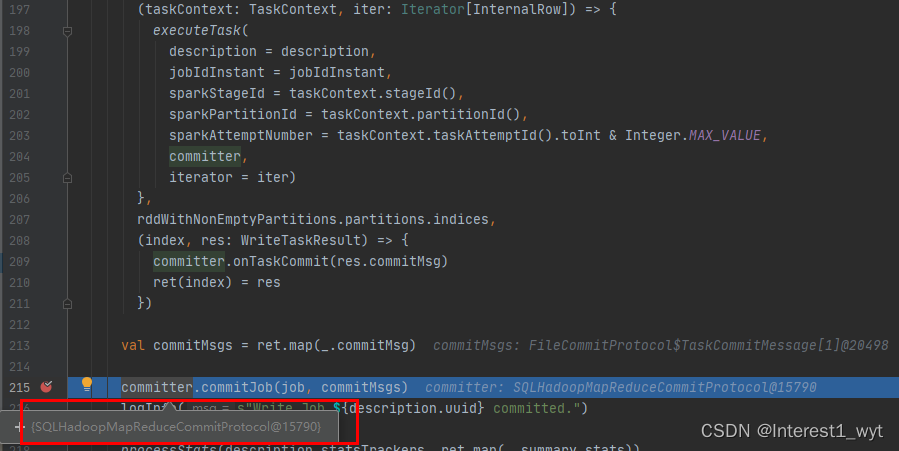
接着到SQLHadoopMapReduceCommitProtocol中查看,commitJob是当前类继承其父类的方法,所以我们直接到其父类中查看:
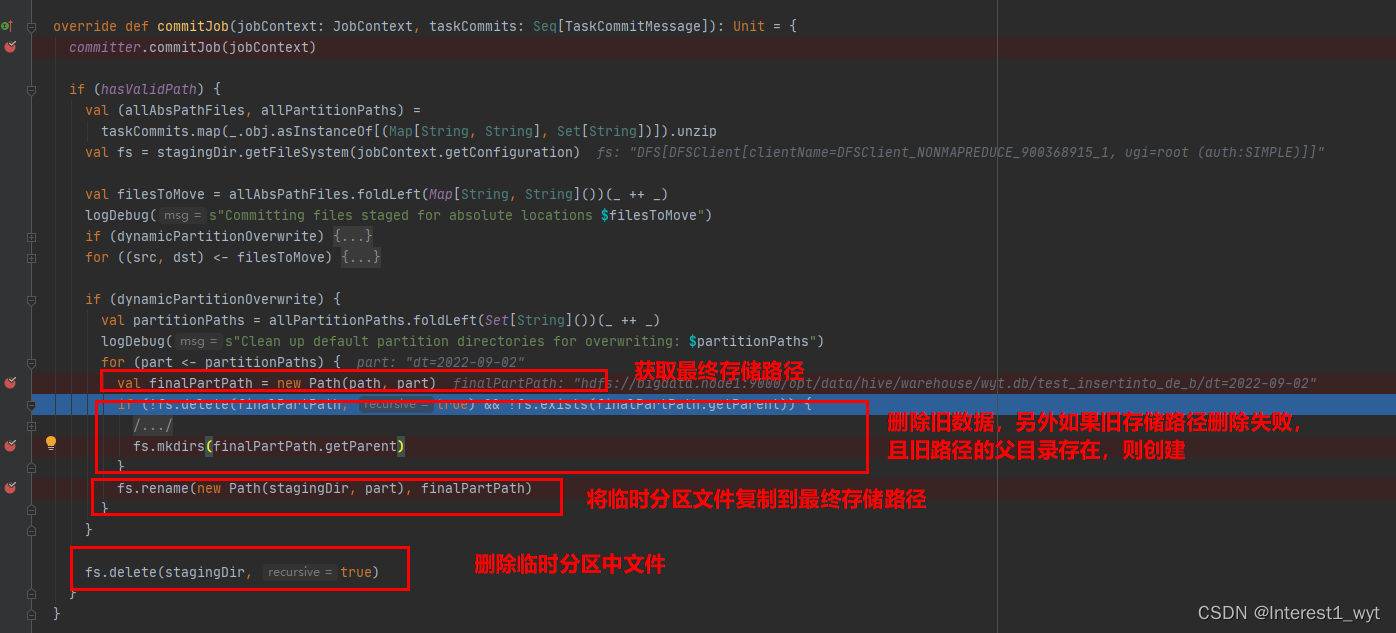
在该方法中我们终于查看到了分区表的数据覆盖写的最终逻辑,也就是先删除待插入分区的数据,然后复制临时数据到目标分区(这里虽然用的是rename方法,但是实际上执行完rename后目标分区数据和临时数据一起并存,所以这块原理上更像复制),最后删除临时数据。
3、总结
1)本次源码阅读解析我只关注了问题点,并且主要参考debug流程,所以整体的代码注释率很低,不过大家在一开始阅读源码时也可以尝试这样只追踪自己感兴趣的主线,不要看面,面可以从框架层次看,源码层次最好是从点开始看。
2)insertInto覆盖写(overWrite)hive中的全量表的时候,具体的执行逻辑在InsertIntoHadoopFsRelationCommand类中,首先会删除指定路径下的所有数据,随后会再将数据写入到文件中。
3)insertInto覆盖写(overWrite)hive中的分区表的时候,具体的执行逻辑在InsertIntoHadoopFsRelationCommand类中,首先会将数据写入一个临时文件中,随后删除目标分区数据,然后复制临时数据到目标分区路径(方法名为rename,有一定误导性),最后删除临时数据。
4)注意上述insertInto源码追踪的流程是通用的,但是具体的处理对象InsertIntoHadoopFsRelationCommand目前是适用于hive表,对于其它JDBC数据库比如mysql等我没有探查过,不过肯定不是现在的处理类,因为mysql等大多数jdbc数据库都有单独的一套存储系统,当前的InsertIntoHadoopFsRelationCommand只针对hdfs上文件数据的插入。

















 1341
1341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









